AI PPT Generator Tools Comparison 2026: Qwen vs Gamma vs BibiGPT vs Tome — Which Is Right for You?
Head-to-head of four mainstream AI PPT tools — Qwen AI PPT Agent, Gamma, BibiGPT, Tome. Compared across source fidelity, generation speed, editability, language coverage, and free tier.
AI PPT Generator Tools Comparison 2026: Qwen vs Gamma vs BibiGPT vs Tome — Which Is Right for You?
Quick answer: In 2026 AI PPT tools have diverged into four distinct product lines — Qwen focuses on "generic text-to-PPT," Gamma on "design-first," Tome on "narrative-driven," and BibiGPT on "source-faithful video-to-PPT." Picking the wrong tool is running the wrong race. This post helps you match the tool to your actual input.
Every time I see a "Top 10 AI PPT tools" comparison post, my reaction is: none of these 10 actually match my workflow. The reason is simple — these aren't different brands of the same product. They solve completely different problems. This post ranks four mainstream tools across five hard metrics and maps them to three real-world scenarios.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
Four AI PPT Tools — Four Product Lines
First, let's de-confuse a common mistake: Qwen, Gamma, BibiGPT, and Tome are not direct substitutes. Their positioning is:
| Tool | Core positioning | Strongest use case |
|---|---|---|
| Qwen AI PPT Agent | Generic text-to-PPT | Long text or outline → fast report deck |
| Gamma | Design-first AI presentations | Externally-shared branded decks |
| BibiGPT | Source-faithful video-to-PPT | Video / podcast / meeting recording → deck |
| Tome | Narrative-driven product pitches | Story arc decks (VC pitches, launches) |
The real selection question is: what's your input? Text → Qwen / Gamma; Video → BibiGPT; Product pitch with a story → Tome. Once this is clear, the comparison dimensions below actually mean something.
Five Comparison Dimensions
Dimension 1: Source-content fidelity (most underrated axis)
"Source fidelity" means: does the generated PPT faithfully reflect the core structure and information of the original input? This is where the four tools differ the most.
| Tool | Source fidelity | Notes |
|---|---|---|
| Qwen | 3/5 | Decent on text → PPT, with noticeable restructuring |
| Gamma | 2/5 | Design-first; content gets "beautified" or trimmed |
| BibiGPT | 5/5 | Native video chapter structure maps 1-to-1 to slides |
| Tome | 2/5 | Narrative-first; original meaning often reshaped to fit the story arc |
Why is BibiGPT leading here? Because its input is already a video with native chapter structure (timestamp-driven). The AI doesn't need to "restructure" — only to "translate" the video structure into slide structure. Qwen / Gamma / Tome receive text and have to "figure out how to organize," so fidelity drops by design.
Dimension 2: Generation speed
| Tool | Typical time | Notes |
|---|---|---|
| Qwen | 30-60s | Fast thanks to Qwen's long-context model |
| Gamma | 1-2 min | Heavier design rendering |
| BibiGPT | 20-40s | Fastest post-subtitle-cache |
| Tome | 1-3 min | Slower due to narrative generation |
Speed doesn't matter much day-to-day, but shows up in batch runs (10 decks at once).
Dimension 3: Editability
| Tool | Editor | Exports |
|---|---|---|
| Qwen | Qwen Doc in-app editor | PPT, PDF |
| Gamma | Gamma in-app editor | PPT, PDF, Web |
| BibiGPT | Markdown export | Markdown, HTML, PPT (Beta) |
| Tome | Tome in-app editor | PDF, Web |
Gamma has the most polished editor, Tome second. BibiGPT leans toward "generate structured content, hand off to a specialized tool for final polish."
Dimension 4: Language coverage
| Tool | Primary languages | Chinese quality |
|---|---|---|
| Qwen | ZH / EN | Excellent (native Chinese in Tongyi) |
| Gamma | EN-first | Average (noticeable translation voice) |
| BibiGPT | ZH / EN / KO / JA | Excellent (China-based native Chinese team) |
| Tome | EN-first | Poor |
Chinese users pick Qwen or BibiGPT; Japanese/Korean users should pick BibiGPT (only native support); English users can pick any.
Dimension 5: Free tier
| Tool | Free tier | Starting price |
|---|---|---|
| Qwen | Generous (Tongyi ecosystem) | Per Qwen Max pricing |
| Gamma | 400 credits starter | $8/month starter |
| BibiGPT | Daily free quota | Plus/Pro subscription |
| Tome | Limited | $16/month starter |
For free trialing, Qwen and BibiGPT are the friendliest.
Three Real Scenarios: Which Tool to Pick
Scenario A: Knowledge worker — watched a video, needs a report deck
Pick: BibiGPT
Your input is a video (industry talk, meeting recording, podcast); your target is a readable PPT for your boss. In this scenario:
- Qwen / Gamma / Tome all require you to transcribe the video first — extra step
- BibiGPT accepts the video link directly; generates a structured PPT in 20-40 seconds
- Follow up with PPT keyframe extraction to add real video frames as visual evidence
Related reading: Meeting Video to PPT Report AI Tool 2026 | Video to Slides AI PPT Generator Guide 2026
Scenario B: Content creator — redistribute a video as a visual deck
Pick: BibiGPT + Gamma combo
One tool doesn't cover this. BibiGPT converts the video into structured content (with keyframe images); Gamma renders the structured content into a visually strong presentation. Division of labor: BibiGPT for content quality, Gamma for visual polish.
Scenario C: Founder — pitching a product to investors
Pick: Tome (for English pitches) or Gamma (general business)
VC pitches are a classic "narrative-first" scenario — structure precedes content. Tome is best at this; its templates come with a native "hook → problem → solution → market → business model" story arc. For Chinese pitches, use Gamma plus manual tuning; Tome's Chinese is not strong enough yet.
Scenario D: Teacher / trainer — course video to standardized training deck
Pick: BibiGPT
Course videos are high-density and structure-critical. BibiGPT's chapter splitting + PPT keyframe extraction is a perfect fit — students see slides that map frame-by-frame to the video, maximizing teaching consistency.
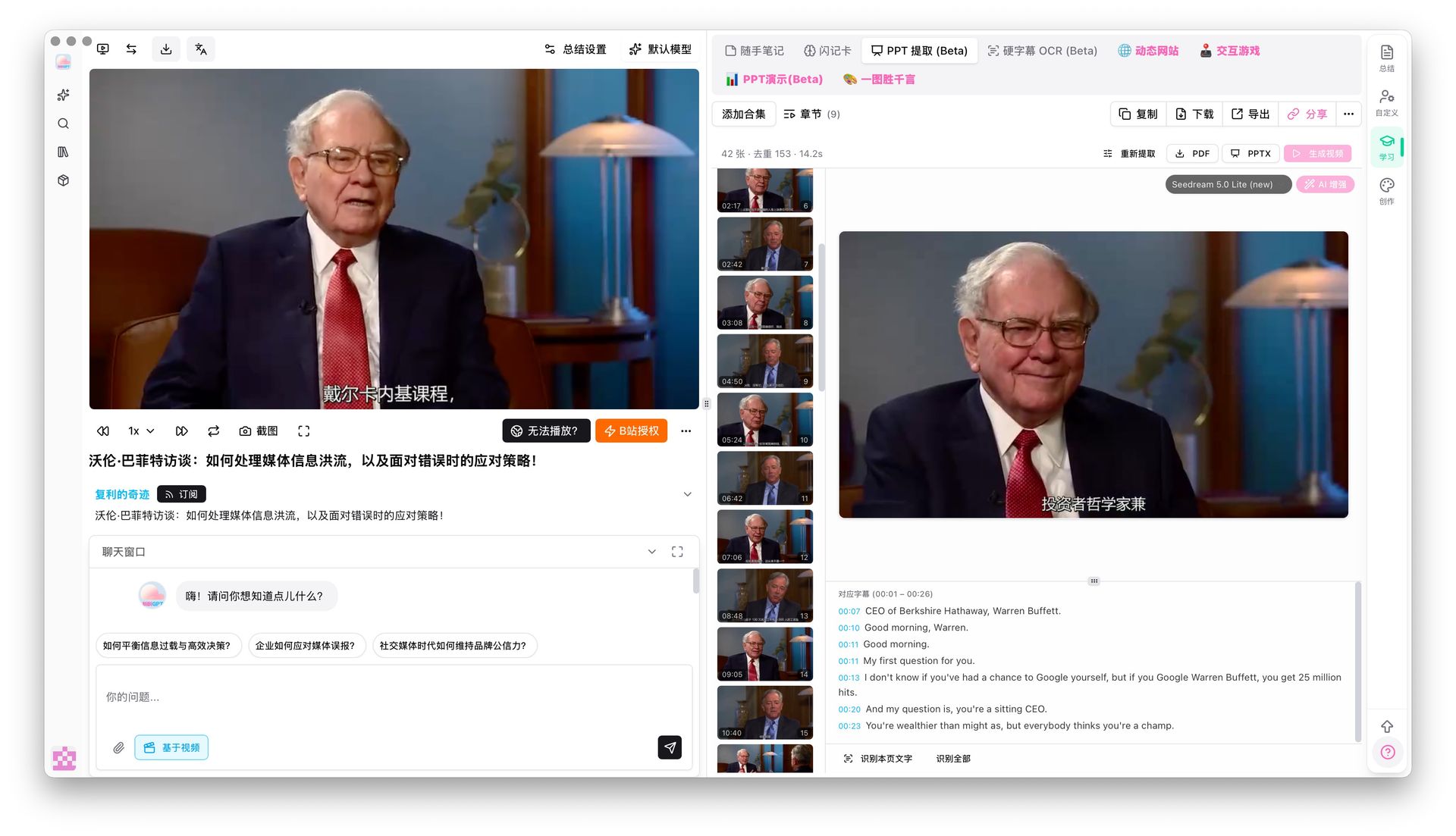 PPT keyframe extraction result
PPT keyframe extraction result
BibiGPT's Differentiator: Full Multimodal Pipeline From Source Video
Of the four, BibiGPT is the only one starting from video. That means beyond PPT generation, it produces, around the same video source:
- AI video-to-article (for blog / WeChat public accounts)
- Mindmaps (knowledge structure)
- Full subtitles (quotation / study)
- Visual analysis (Xiaohongshu / short-video scripts)
- Flashcards (Anki CSV export)
One video → 5-6 different output forms in BibiGPT. Qwen / Gamma / Tome only produce the PPT form. For creators and learners who work deeply with video, the efficiency difference is an order of magnitude.
Related: AI Video to PPT Complete Guide | NotebookLM April 2026 Update vs BibiGPT
FAQ
Q1: I only have a long text (meeting notes / article). Which tool?
A: Qwen or Gamma. Both excel at text → PPT. For Chinese, Qwen (native ecosystem); for English + design-heavy, Gamma.
Q2: My deck is for investors. Which looks best?
A: Gamma. Strongest template design and brand polish — ideal for external sharing. If it's a narrative-driven pitch, also consider Tome.
Q3: I have both video and text sources — how to combine?
A: Use BibiGPT for the video, Qwen for the text, then merge into one deck. BibiGPT's Markdown export makes it easy to splice with other sources.
Q4: Which free tier is actually usable for real work?
A: Empirically, Qwen and BibiGPT have the most usable free tiers for daily work. Gamma's 400-credit starter is exhausted within 3-5 decks.
Q5: PPT Presentation vs PPT Keyframe Extraction in BibiGPT — difference?
A: PPT Presentation is an AI-generated dynamic deck from the video summary (structured abstract). PPT Keyframe Extraction pulls real keyframes from the original video with matching subtitles (visual evidence). They're complementary — lecture-style videos → keyframe extraction (fidelity), monologue-style videos → PPT Presentation (polish).
Closing: Pick the Right AI PPT Tool, 10x Your Productivity
The AI PPT market looks crowded but is actually four distinct product lines. Picking the wrong tool is running the wrong race — it's like eating noodles with a fork. Not a bad fork, just a mismatch.
If your work centers on video sources (courses, industry talks, podcasts, meeting recordings), BibiGPT is the only tool that pushes source-content fidelity to the limit. Trusted by over 1 million users, over 5 million AI summaries generated, supports 30+ platforms — with an end-to-end pipeline from video to PPT to article to mindmap to flashcards.
See BibiGPT's AI Summary in Action
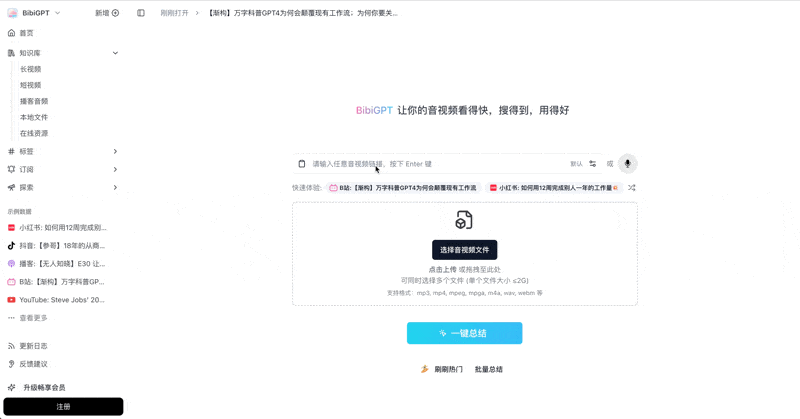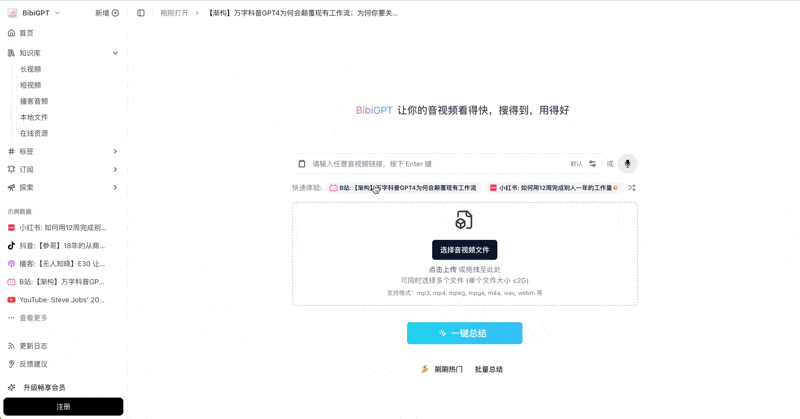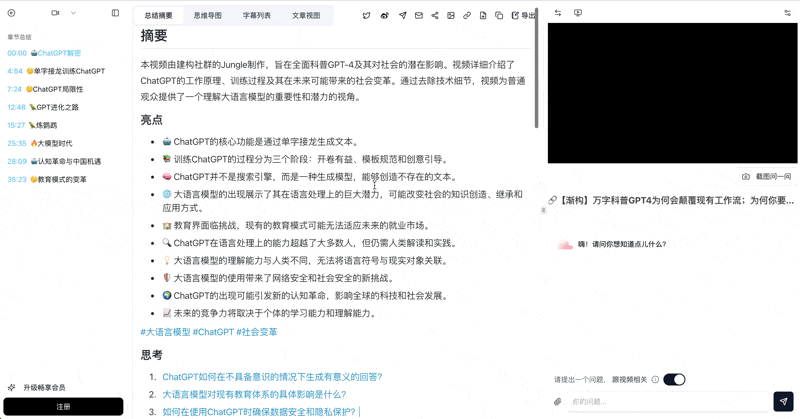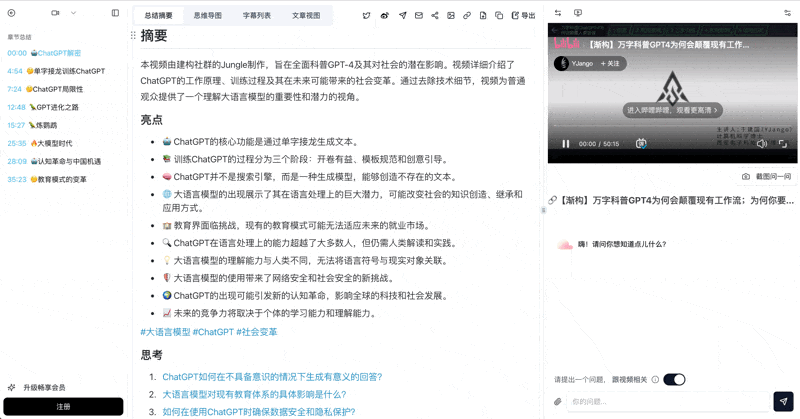
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeStart your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team