Xiaohongshu Open-Sources REDSearcher + FireRed: Where Does BibiGPT Fit?
Xiaohongshu (RedNote) just open-sourced REDSearcher (30B search Agent beating Gemini-2.5-pro) and the FireRed multimodal video-creation suite. Here's what it means for creators and how BibiGPT complements the new creation Agent stack.
Xiaohongshu Open-Sources REDSearcher + FireRed: Where Does BibiGPT Fit?
Last updated: April 17, 2026
In April 2026, Xiaohongshu (RedNote) open-sourced three major models in quick succession: REDSearcher (a 30B search Agent that outperforms Gemini-2.5-pro on Xiaohongshu's domain), FireRed-Image-Edit (multimodal image editing), and FireRed-OpenStoryline (a video-creation Agent). With this move, Xiaohongshu officially upgrades from "content platform" to "content creation hub" — the production side of image and video work that used to require human operators is now Agent-driven. For creators, this is a step-change drop in creation cost. For consumption-side tools like BibiGPT, it's the right moment to clarify the complementary positioning.
This article explains what REDSearcher and FireRed actually are and why they matter, then maps a pragmatic "BibiGPT (consume / learn) + Xiaohongshu AI (create / distribute)" workflow.
What are REDSearcher and FireRed?
💡 Want to feel how Xiaohongshu + BibiGPT collaborate? Paste a Xiaohongshu video link below and watch BibiGPT turn it into reusable structured content in 30 seconds.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
Per Zhihu's tech column (article) and GeekPark coverage (article):
- REDSearcher — 30B-parameter search Agent fine-tuned end-to-end for the Xiaohongshu content ecosystem. Open-sourced for self-hosting. Beats Gemini-2.5-pro on in-domain search quality.
- FireRed-Image-Edit — Multimodal image-editing model. Supports instruction-driven edits ("swap the background to sunset"), making it easy for creators to mass-produce Xiaohongshu-style covers.
- FireRed-OpenStoryline — Video-creation Agent. End-to-end script → storyboard → cut, optimized for Xiaohongshu's algorithm.
The product narrative is unmistakable: Xiaohongshu wants creators to spend more time on selection and authentic expression, and let AI take over the production layer.
What this means for creators
In the short term it's a tooling upgrade. In the long term it's a re-division of labor. Three direct implications:
- Marginal cost of producing image / video content drops to near-zero — what used to require a model shoot, color grading, and a copywriter can now be batched out from one prompt
- Algorithmic preferences get internalized by the Agent — REDSearcher already understands Xiaohongshu's discovery logic, so Agent-generated content is naturally easier to surface
- The truly scarce resource becomes "real experience + topic judgment" — production isn't the bottleneck anymore, "having something worth saying" is
Which is exactly why the consumption side (learning, research, information aggregation) becomes more important, not less. The ceiling on output is being lifted, but the ceiling on absorbing input isn't. If your input can't keep up with your output, AI just helps you mass-produce empty content.
BibiGPT's complementary position: consumption + topic discovery
BibiGPT has always focused on the consumption side — turning videos, podcasts, and livestreams produced by others into structured knowledge you can absorb, cite, and remix. That's exactly the upstream layer the Xiaohongshu AI creation chain doesn't address.
💡 Here's what a finished BibiGPT summary looks like — chapters, mind map, highlight notes:
See BibiGPT's AI Summary in Action
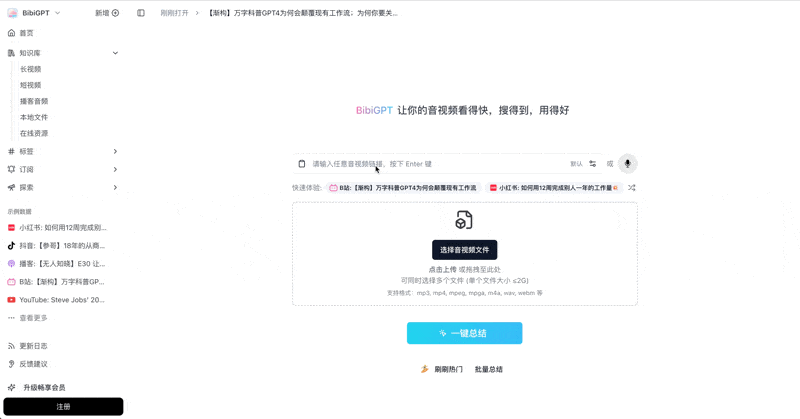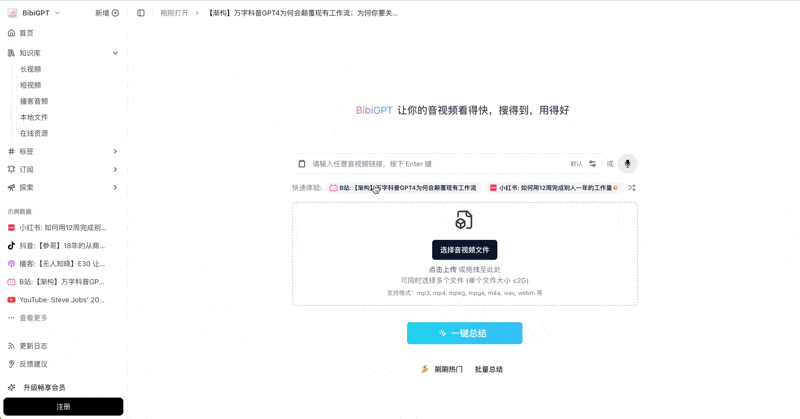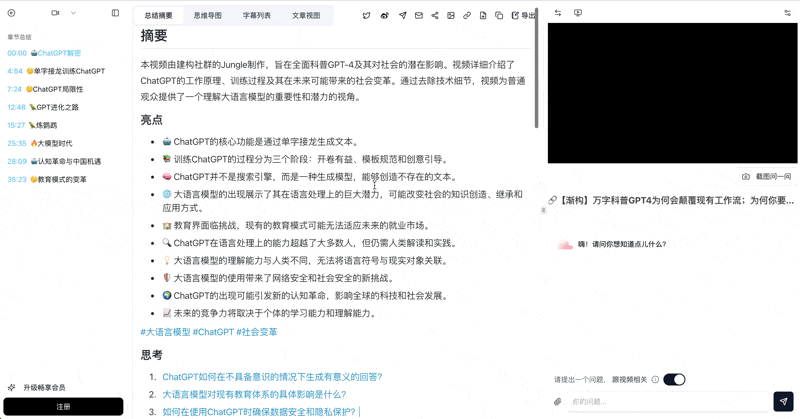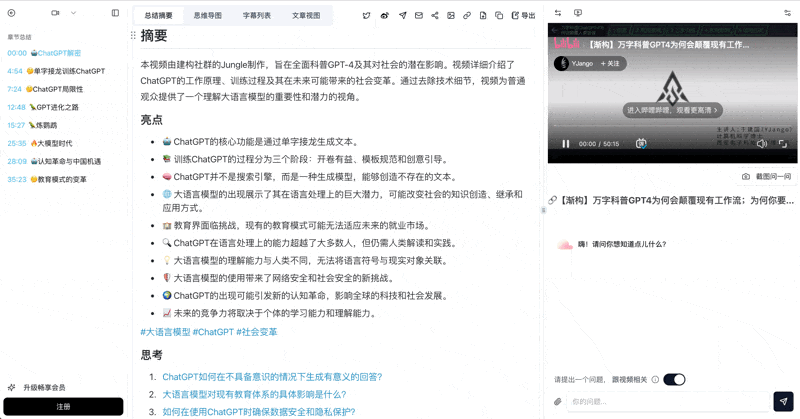
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeConcrete workflow split:
| Stage | Tool | Output |
|---|---|---|
| Topic input | BibiGPT Xiaohongshu Video-to-Text | Convert a target account's videos into structured notes; identify topic patterns |
| Learning input | BibiGPT Deep Search + Collection Summary | Cross-platform aggregation of industry signal |
| Image creation | Xiaohongshu FireRed-Image-Edit | AI-generated covers and inline images in Xiaohongshu style |
| Video creation | Xiaohongshu FireRed-OpenStoryline | Script → storyboard → cut |
| Cross-platform repurposing | BibiGPT AI Video to Xiaohongshu Post | Convert existing Bilibili / YouTube videos into Xiaohongshu posts |
| Trend validation | Xiaohongshu REDSearcher | Cross-check trending topics and search intent |
Three concrete scenarios
Scenario 1: Cross-platform distribution for knowledge creators
If you already have content on Bilibili / YouTube, the highest-ROI expansion path is to repurpose those videos into Xiaohongshu posts via AI Video to Xiaohongshu Post, then mass-generate platform-native covers with FireRed-Image-Edit. Original content + native distribution = cold-start acceleration.
 Xiaohongshu image generation entry
Xiaohongshu image generation entry
Scenario 2: Competitive monitoring for industry researchers
Use BibiGPT to batch-process a target account's last 30 days of videos into structured notes (Xiaohongshu Video-to-Text + Collection Summary). Identify topic patterns, common viral elements, pacing. Then validate via REDSearcher's actual search-domain performance, closing the loop on "is this niche worth entering."
Scenario 3: Content repackaging for educators and trainers
Lectures and course recordings → BibiGPT structured lesson plans (Chapter Deep Reading + Smart Deep Summary). Then FireRed-OpenStoryline cuts those plans into 1-minute hooks. Finally Xiaohongshu Image (Seedream 4.0) generates promotional graphics.
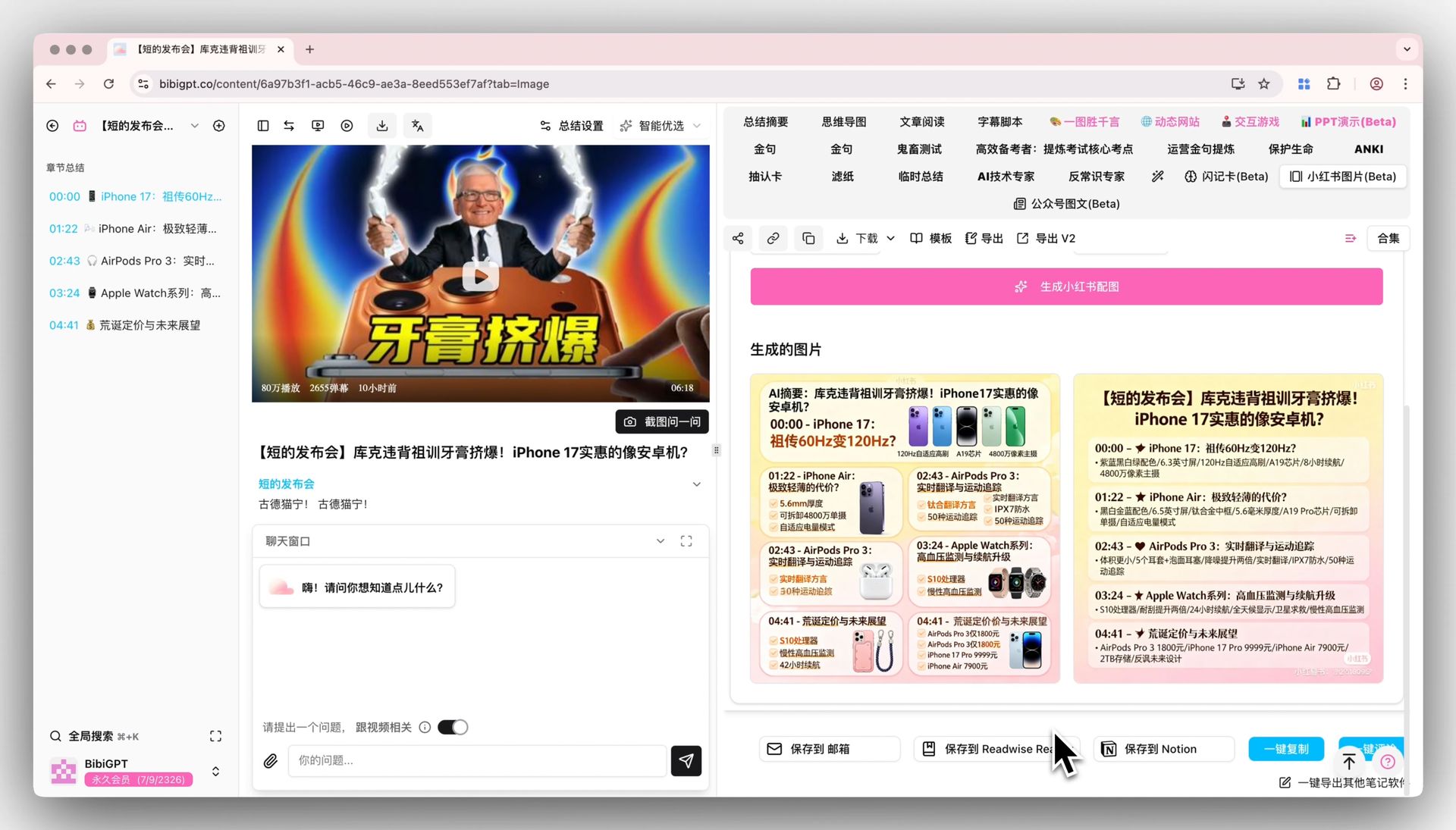 Xiaohongshu image generation showcase
Xiaohongshu image generation showcase
A common misread: open-source ≠ free-to-use
REDSearcher and FireRed open the model weights, but running them requires:
- At least one A100/H100-class GPU (30B inference floor)
- Solid ML deployment experience (vLLM, quantization, streaming)
- Ongoing fine-tuning and evaluation capability
For most individual creators, the realistic path is to wait for Xiaohongshu to ship the Agents inside the app (already in gradual rollout), or use a SaaS like BibiGPT to bridge consumption and creation without touching weights.
After the Xiaohongshu AI inflection: BibiGPT's product POV
Our take: creation tools converge, consumption tools become more scarce.
- Xiaohongshu FireRed, ByteDance Jimeng (Seedance 2.0), Runway Gen 4.5 are all racing on the creation side
- But "tools that help you understand what others created, extract value, transform it into your own knowledge" remain rare
- BibiGPT focuses on "content understanding + knowledge structuring + cross-tool integration"
If you're a creator, the pragmatic strategy isn't betting on which creation AI wins — it's making sure your input pipeline always runs ahead of your output pipeline. That's also the rationale behind bibigpt-skill letting Claude / Cursor "watch videos" — Agent-ifying the consumption side, complementary to Xiaohongshu's creation Agents.
FAQ
Q: Does BibiGPT overlap with REDSearcher? A: No. REDSearcher is "intelligent search inside Xiaohongshu." BibiGPT is "turn any video / audio / livestream into structured knowledge." One is in-platform search, the other is a cross-platform understanding layer.
Q: Will Xiaohongshu's native AI tools eventually replace third parties? A: Inside Xiaohongshu's posting flow, yes. But what creators actually lack is the "cross-platform input → distill → output" loop, and platform-native tools won't optimize for that (the platform wants you to do everything inside it).
Q: What kind of creators does FireRed-OpenStoryline fit? A: Niches with standardized output formats — food, fashion, travel vlogs. Knowledge creators, deep interviews, and analytical content still need editorial judgment that AI video gen can only assist with.
Q: Should I use BibiGPT or FireRed-Image-Edit for Xiaohongshu images? A: BibiGPT's Xiaohongshu Image fits "from existing video / notes → image" (consumption → creation). FireRed-Image-Edit fits "from scratch via instructions" (pure creation). They stack.
Q: Can I summarize native Xiaohongshu videos with BibiGPT? A: Yes — paste a Xiaohongshu link into aitodo.co and BibiGPT auto-routes through Xiaohongshu Video-to-Text to produce a structured summary.
Further reading
- Xiaohongshu Video Summary Skill: Help Claude understand content · Xiaohongshu DianDian AI Creation Hub
- Complete AI Video Summary Guide 2026 · Bilibili → WeChat 5-Step Workflow
- bibigpt-skill: let Agents watch videos
Pair these BibiGPT features with Xiaohongshu's AI
Open the feature pages and start free
Closing
Xiaohongshu's REDSearcher + FireRed open-source push marks the real inflection point of "content creation goes Agent." But more abundance on the creation side just makes intelligent consumption scarcer — the more you can mass-produce, the more you need solid input and judgment.
Place BibiGPT on the "consume + topic discovery" side, place Xiaohongshu AI on the "create + distribute" side. That's the most pragmatic creator workflow for 2026.
→ Try BibiGPT Free — paste any Xiaohongshu / Bilibili / YouTube link, get a structured summary in 30 seconds.
Or install bibigpt-skill so Claude / Cursor / Codex can watch videos directly.
BibiGPT Team