Netflix Goes TikTok: In the 2026 Long-Video-Goes-Short Wave, BibiGPT Restores Information Density
Netflix launches a TikTok-style vertical video feed with AI recommendations this month, with Disney+ following. As long-video platforms collectively go short-form, where does the depth go? BibiGPT restores the information density that platforms strip away — timestamped summaries, interactive mindmaps, and two-host podcasts that let you actually learn in the short-video tsunami.
Netflix Goes TikTok: In the 2026 Long-Video-Goes-Short Wave, BibiGPT Restores Information Density
In April 2026, Netflix announced a TikTok-style vertical video feed launching this month (TechCrunch), with Disney+ already confirmed to follow in 2026 (Dexerto). As long-video platforms collectively pivot to short-form, the information density you can pull from any single piece of content is being compressed. BibiGPT solves the opposite problem: restore the information density platforms strip away. Paste any video URL — in 30 seconds you get a timestamped structured deep summary, a toggleable mindmap, and a two-host podcast for commuting — so you can actually learn in the short-video tsunami.
This isn't an anti-short-video article — it's a "where the platforms are going vs what you actually want" tool guide. If you're unwinding, Netflix's vertical feed is fine. If you want to learn from videos, BibiGPT is your knowledge-density restorer.
What Exactly Did Netflix Announce?
According to TechCrunch's April 17 report:
- TikTok-style vertical feed launching this month (April 2026): In testing since 2025, users can swipe through clips from shows, films, and video podcasts
- AI takes over recommendations: Co-CEO Gregory Peters said new AI recommendation systems "iterate and improve more quickly" and support different content types more efficiently
- ChatGPT-powered search is already live; more AI models to refine recommendations next
- Disney+ confirmed to follow in 2026 (Dexerto source)
The narrative is clear: streaming platforms are collectively panicking about TikTok stealing attention — so they chop their own content into short feeds as a defensive move. For "learn something, not just scroll" users, this is an information-density downgrade.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
The Cost of Short-Form: Information Density Cut Three Times
When a 90-minute documentary gets chopped into 30-second "highlight clips", you lose more than just minutes — you lose three layers of information:
- Context vanishes: No setup, no payoff — just the peak. Opinions stripped of context get misread
- Structure shatters: The chapter logic, argumentative chain, and cumulative cases — gone. Only emotional points remain
- Re-traceability drops to zero: Short clips have no timestamps, no table of contents, no quotable transcript. Want to "re-watch that part"? Basically impossible
For entertainment consumption, none of this matters. For learning, research, and content creation, it means you scrolled for hours and retained almost nothing.
BibiGPT's Differentiated Value: Restoring All Three Layers
BibiGPT has always done the reverse — preserve long-video information density, not chop it. As of April 2026, with Netflix going short-form, that differentiation matters more. How it works:
1. Restore "Context": Deep Summaries with Chapters and Timestamps
Paste any YouTube / Bilibili / podcast link — the AI video deep summary feature generates a structured report: core summary, highlights, deep-thinking Q&A, terminology explanations. Not clips — a compressed-but-structured concentrate.
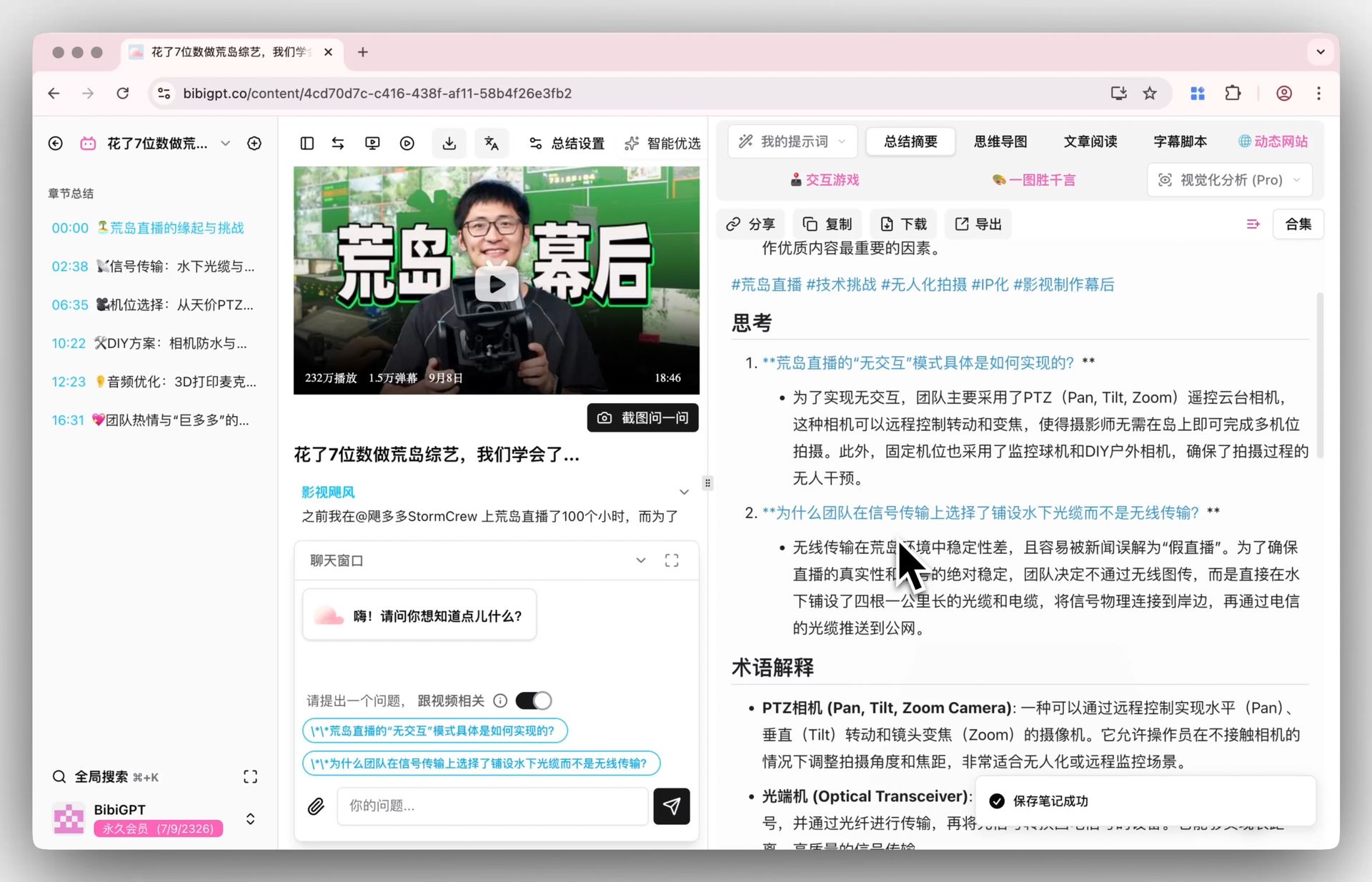 BibiGPT smart deep summary: Q&A example
BibiGPT smart deep summary: Q&A example
Compared to "emotional peaks" in Netflix's feed, BibiGPT gives you a "knowledge map compressed 80% but preserving all logic."
2. Restore "Structure": One-Click Mindmap View
Chapter logic chopped by short-form gets reassembled in an interactive mindmap (XMind / Markmap formats), making the overall argument visible at a glance. For downstream workflows, see the Bilibili-to-Notion knowledge base workflow.
3. Restore "Re-traceability": Timestamp Jumps + Quotable Subtitles
Every AI summary segment carries a timestamp — click to jump back to the exact second in the source video. The subtitle download feature exports SRT so you can quote precisely in papers or notes. Short-form feeds literally cannot do this.
Scenario Comparison: Same 90-Minute Content, Two Experiences
Say you watched a 90-minute "AI frontier research documentary" on Netflix or YouTube:
Netflix short-form experience (post-April 2026):
- System-generated 3 "highlight clips" in the vertical feed
- You see a few striking visuals, a few quotable lines
- 10 minutes later, you close the app — vaguely recall "something was said"
BibiGPT deep-reading experience:
- Paste the full URL into BibiGPT
- 30-second chapter-based deep summary (with thinking questions)
- Switch to mindmap view — the argument is visible at a glance
- Listen to a two-host podcast version on your commute
- Use flashcards for 10 minutes of spaced repetition
- Sync key terms to Notion for weekly review
Same 90 minutes of source content — the latter puts information into your long-term knowledge system; the former stops at short-term memory.
Three Actions to Hold On to Long-Form Content
See BibiGPT's AI Summary in Action
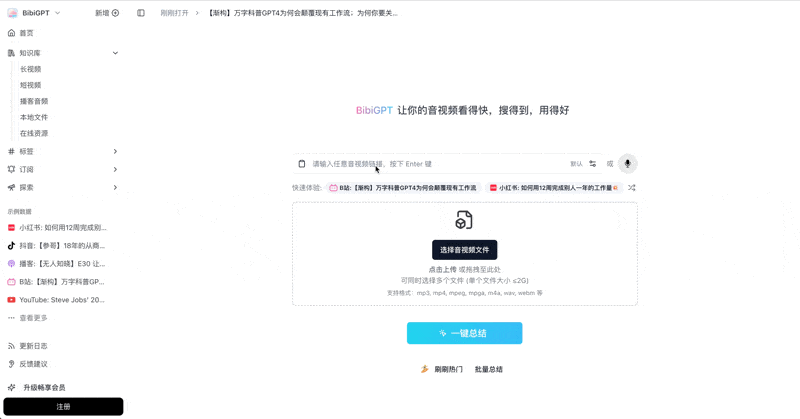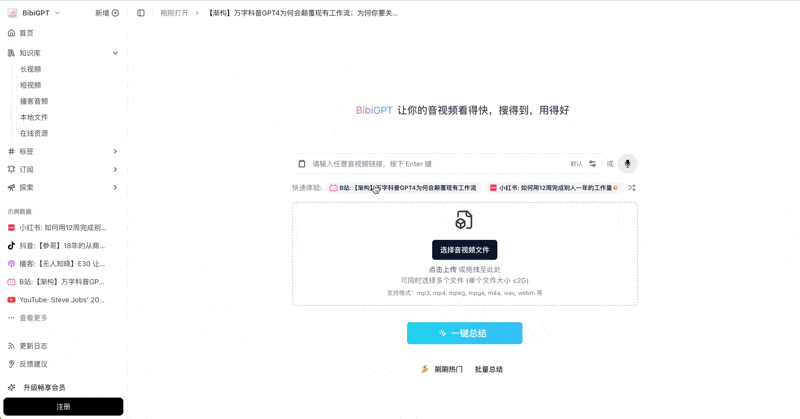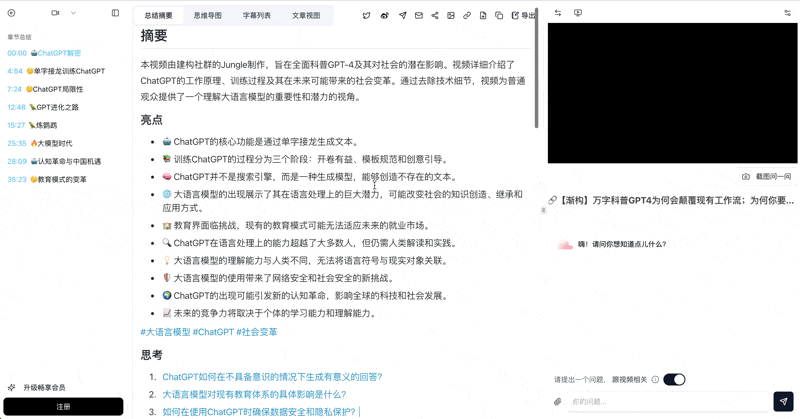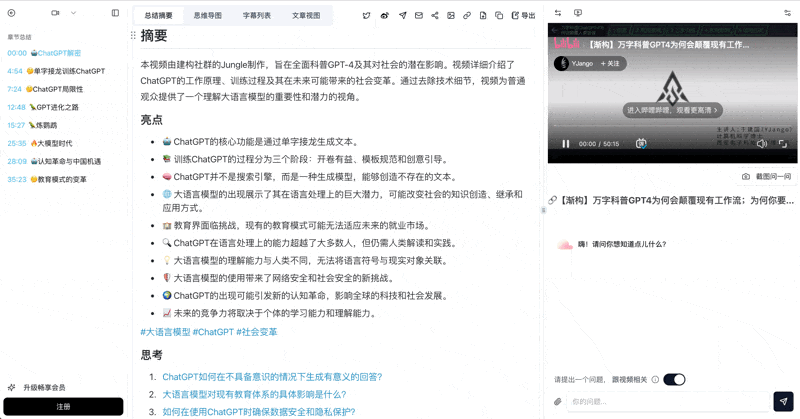
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeAction 1: Save a deep summary before you forget
Wherever you found it — YouTube, Bilibili, podcast apps — copy the URL into aitodo.co. 30-second timestamped deep summary + mindmap. Re-findable forever.
Action 2: Use two-host podcasts for commute "catch-up"
For long interviews, lectures, or documentaries, generate a two-host podcast version for commuting, walking, or cooking. This is jiu-jitsu — the short-video age trained users to love audio snacks, so we package your long-form as listenable.
Action 3: Sync to your knowledge system
Auto-sync to Notion, Obsidian, Readwise and 10+ other note tools. Short-form creates "information overload, memory scarcity" — a knowledge system is the only cure.
Who Should Use What
| User Type | Netflix Vertical Feed Is Good For... | BibiGPT Is Good For... |
|---|---|---|
| Casual viewers | Nighttime unwind, finding new shows | Deep-digesting shows you really care about |
| Students | Entertainment breaks | Turning professor-assigned lectures, docs, MOOCs into reviewable study material |
| Content creators | Watching algorithm trends | Breaking down competitor long videos into structured analysis for topic/script reference |
| Researchers | Rarely useful | Turning interviews, keynotes, industry docs into citable transcripts + timestamp revisits |
Platforms have fully split "entertainment consumption" from "knowledge consumption." Netflix's vertical feed solves the former; BibiGPT solves the latter. They don't conflict — they serve different needs.
A Note for Content Creators: Short-Form Pivot ≠ Abandon Long-Form
If you create content, seeing Netflix and Disney+ collectively pivot to short-form might make you worry "should I abandon long-form?" The answer: do the opposite.
Long-form content is now scarcer — because most platforms are devaluing information density, the few creators still making depth become easier to identify, subscribe to, and monetize. BibiGPT helps you:
- Turn your long videos into blog posts for WeChat / blogs
- Turn videos into two-host podcasts for Spotify / Apple Podcasts
- Turn video highlights into social-ready images to reach short-form audiences
- One long video → 5 distribution formats, see the AI video content repurposing workflow
The short-form wave actually makes "can make long-form + uses AI for multi-format distribution" creators more valuable.
FAQ
Q1: Can Netflix's AI search replace BibiGPT?
A: Completely different roles. Netflix's ChatGPT-powered search helps you "find what to watch"; BibiGPT helps you "turn what you watched into usable knowledge." Former is discovery layer, latter is retention layer.
Q2: I have YouTube Premium — do I still need BibiGPT?
A: YouTube Premium solves "watch without ads or lag"; BibiGPT solves "keep something after watching." Former improves consumption UX; latter turns consumption into learning. Complementary, not competing.
Q3: Does BibiGPT support Netflix videos?
A: Netflix's DRM-protected content isn't supported — that's a licensing decision. But Netflix's publicly released interviews, press events, and documentary clips typically land on YouTube and other platforms, and those are BibiGPT's home turf. YouTube summaries, Bilibili, TikTok, and 30+ platforms are all one-click supported.
Q4: With AI recommendations getting stronger, do I still need to actively save and summarize?
A: The stronger AI recommendations get, the more important active retention becomes. AI recs are "what it thinks you'll like"; your notes are "what you actually consider important." Completely different objective functions. Only the latter becomes long-term knowledge capital.
Conclusion
Netflix and Disney+ going TikTok-style is the inevitable result of "entertainment consumption time" as a north-star KPI — more short clips = more swipes = more ad impressions. But user needs have bifurcated: entertainment is entertainment, learning is learning. BibiGPT's reason for existing is to hold the line on "long-form videos can teach you something" while platforms go short-form — with chapter-based deep summaries, toggleable mindmaps, timestamp revisits, and syncable notes.
Scroll your vertical feed. We'll help you keep the content that actually matters.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team