如何用 BibiGPT + Obsidian 构建个人视频知识库(2026 PKM 工作流三步法)
手把手方法论:用 BibiGPT 处理 B 站/YouTube/播客视频,Obsidian 本地自动入库,三步建立可持续生长的个人视频知识库 PKM 系统。附笔记模板和标签体系。
如何用 BibiGPT + Obsidian 构建个人视频知识库(2026 PKM 工作流三步法)
80 字直答:把 BibiGPT 当视频的 AI 阅读器,Obsidian 当长期沉淀的笔记库。BibiGPT 桌面端开启 "总结完成后自动保存到 Obsidian",每看一个视频就自动入库,配合标签 + 反链结构,三个月就能形成一个可搜索、可追问的私人知识网络。
这是一篇写给知识工作者、学习者、自媒体创作者的方法论文章。不是工具评测,而是一个经过实战验证的 PKM(Personal Knowledge Management)工作流。
一、为什么传统笔记软件不适合视频知识库
试过用原生 Notion / Obsidian / 印象笔记建视频笔记库的人,大概都踩过这几个坑:
- 视频字幕复制不来:大部分平台不开放字幕导出。
- 时间戳断裂:手动记 "10:24 讲到 XX" 下次找不到。
- 搜索无效:视频关键词不在笔记文字里,全文搜索搜不到。
- 入库门槛太高:看完视频还要花 20 分钟整理笔记,最后放弃。
解决这些问题的核心是"让 AI 先把视频解构成可搜索的文本,再交给笔记库做长期管理"。BibiGPT 负责前者,Obsidian 负责后者。
二、三步搭建:从 0 到可生长的 PKM 系统
步骤 1:BibiGPT 桌面端配置 Obsidian 自动保存
打开 BibiGPT 桌面客户端 → 设置 → 笔记集成 → 配置 Obsidian Vault 本地路径(比如 /Users/你/Obsidian Vault/BibiGPT)→ 打开"总结完成后自动保存到 Obsidian"开关。
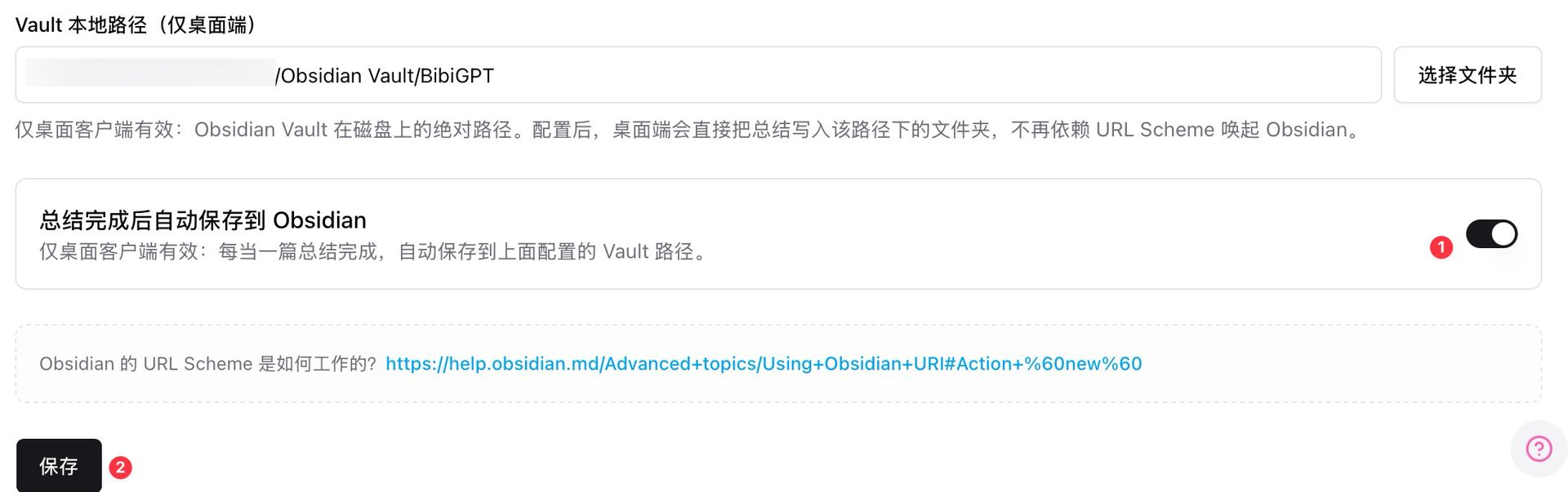 Obsidian Vault 本地路径设置
Obsidian Vault 本地路径设置
配置好之后,你在 BibiGPT 处理的每个视频(B 站、YouTube、小红书、小宇宙播客、本地文件)都会自动生成一份结构化笔记文件写入本地 Obsidian Vault。不再依赖 URL Scheme 唤起,流程稳定。
步骤 2:设计笔记结构(Frontmatter + 章节 + 追问区)
建议每份 BibiGPT 导出的笔记带以下结构:
---
source: https://bilibili.com/video/xxx
platform: bilibili
author: UP主名字
duration: 12:34
processed_at: 2026-04-24
tags: [学习, AI, 产品设计]
---
# 视频标题
## AI 总结
(BibiGPT 自动填)
## 章节时间戳
- 00:00 - 引言
- 02:15 - 核心论点
- 07:40 - 案例拆解
- 11:20 - 结论
## 原始字幕(折叠)
(BibiGPT 自动填)
## 我的追问
(看完之后手动记几条待追的问题,便于后续继续 AI 对话)
## 反链
(Obsidian 自动生成)
这套结构的关键是**"AI 生成的部分"和"人类补充的部分"分开存放**。AI 部分可再生成覆盖,人类部分永不被覆盖。
步骤 3:标签体系 + 合集对话形成知识网络
在 Obsidian 里用三层标签:
- 第一层(主题):
#AI#产品设计#商业 - 第二层(来源类型):
#视频#访谈#课程 - 第三层(处理状态):
#已追问#待深挖#已归纳
配合 BibiGPT 的「合集 AI 对话」能力,把同主题视频放进一个合集,当你的笔记库攒到 50+ 视频后,可以直接在 BibiGPT 合集里跨视频提问——这是 Obsidian 本地库做不到的深度检索。
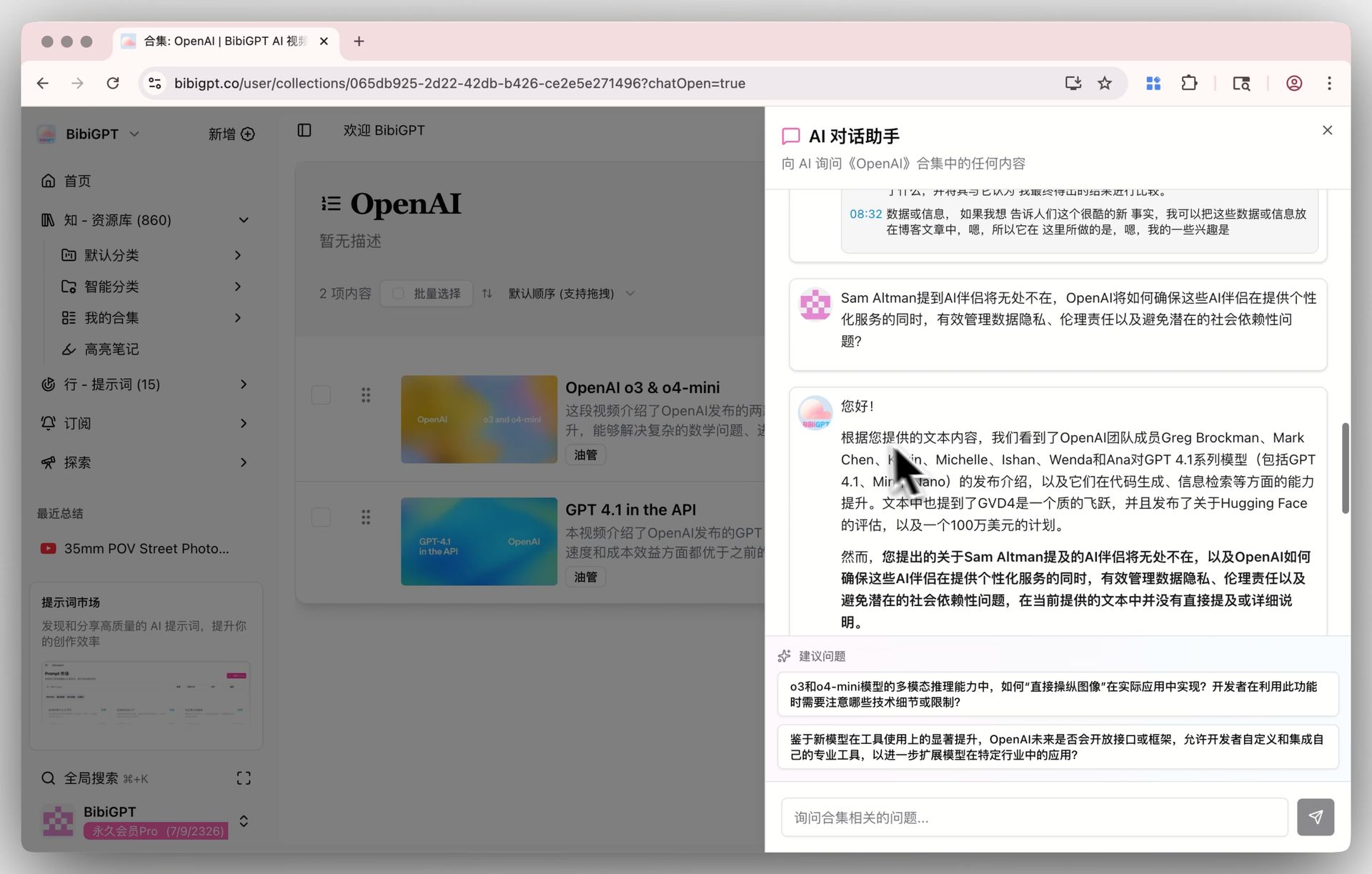 合集 AI 对话
合集 AI 对话
Obsidian 存底 + BibiGPT 查询的双层结构,是这套方法论的核心。
三、进阶技巧:让知识库能"追问"不只是"保存"
自定义提示词按角色再加工
BibiGPT 的自定义提示词功能,让你可以用自己的视角二次解构视频。比如"用费曼技巧简化这段讲解"、"抽取所有可落地的行动项"、"按金字塔原理重组论点"。
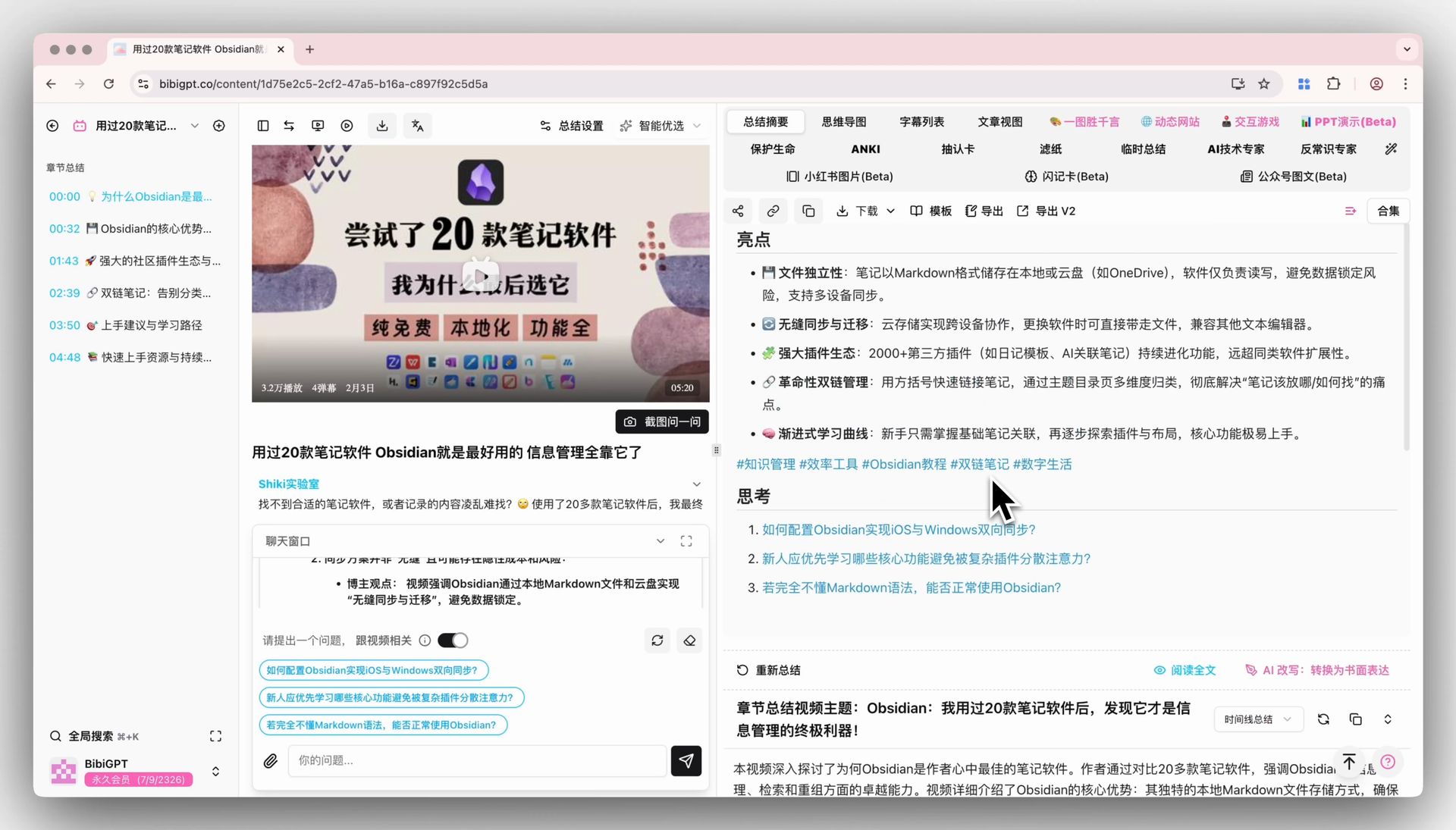 自定义提示词总结
自定义提示词总结
重新生成的总结也会同步到 Obsidian,形成"同一视频,多个角度"的笔记卡片,Obsidian 反链图会自然把它们连起来。
Dataview 查询构建主题视图
在 Obsidian 用 Dataview 插件写一行查询:
TABLE platform, duration, processed_at
FROM #AI AND #视频
WHERE processed_at > date("2026-01-01")
SORT processed_at DESC
瞬间得到一份"2026 年看过的 AI 主题视频清单"——传统笔记软件要手工维护的东西,自动化了。
同步到飞书/语雀做团队共享
BibiGPT 也支持导出到飞书、语雀、Notion——团队项目可以把"共读视频 → BibiGPT 处理 → 飞书共享"变成日常习惯。
四、常见使用节奏(学习者 / 创作者 / 研究者)
学习者(学生、职场进修)
每天 30 分钟看 1-2 条知识类视频 → BibiGPT 自动入库 → 周末回看 Dataview 视图 → 用合集 AI 对话追问不清楚的概念。三个月后你会有 50-100 份结构化视频笔记。
自媒体创作者
粘贴竞品/同赛道视频链接 → 用"爆款公式"自定义提示词再加工 → 笔记自动入库 → 需要写稿时 Dataview 筛选过去 30 天选题库。内容产出效率成倍提升。
研究者 / 产品经理
把一个主题(比如"AI Agent 趋势")的所有访谈、发布会、课程视频批量拉进一个合集 → 合集 AI 对话让你 20 分钟梳理出这个领域的共识与分歧。这是调研阶段的复利工具。
五、FAQ
Q1:为什么不直接用 Notion?
Notion 是云端数据库,搜索依赖云端,且没有像 Obsidian 那样的反链图谱和 Dataview 查询。本地知识库用 Obsidian,云端分发用 Notion,两者并不冲突——BibiGPT 支持同时导出两边。
Q2:Obsidian 自动保存必须用桌面客户端吗?
是的。Obsidian Vault 本地路径访问是桌面客户端独有能力。网页版 BibiGPT 只能通过 URL Scheme 唤起 Obsidian,稳定性较低。下载 BibiGPT 桌面版。
Q3:如果我的视频来源是本地文件(会议录像)呢?
桌面端支持本地文件上传 + 拖拽上传。会议录像、课程录播都可以处理,自动转字幕 + AI 总结 + 入库。
Q4:入库的笔记太多后,Obsidian 会卡吗?
Obsidian 本地引擎对 Markdown 文件数量非常宽容,5 千份以内基本无压力。超过后可以按年分 Vault 或用 Dataview 聚合视图替代实时检索。
Q5:这套工作流能不能做多人协作?
协作层交给云端(飞书/Notion/语雀)。BibiGPT 支持导出到这些平台,Obsidian 只做你的私人长期库。公私分离是 PKM 的黄金原则。
Q6:需要付费吗?
Obsidian 个人使用免费。BibiGPT 有免费额度,Plus/Pro 订阅解锁桌面端高级功能包括 Obsidian 自动保存、自定义提示词库等。
立即试用:把你上周看过的视频一键入库
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
看个已入库案例:一段 B 站课程视频处理后的结构长什么样?
See BibiGPT's AI Summary in Action
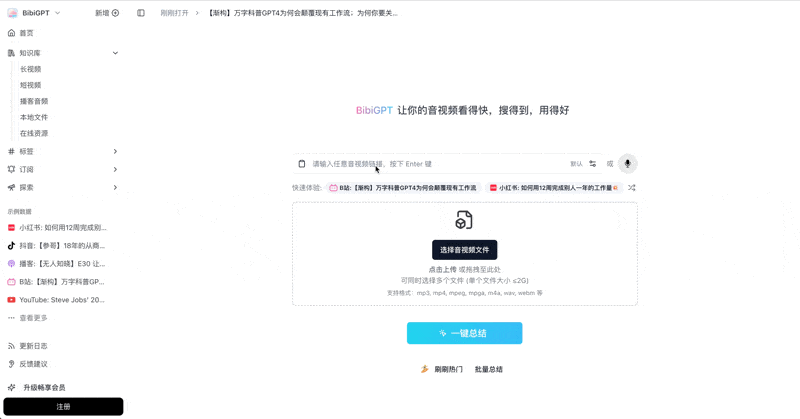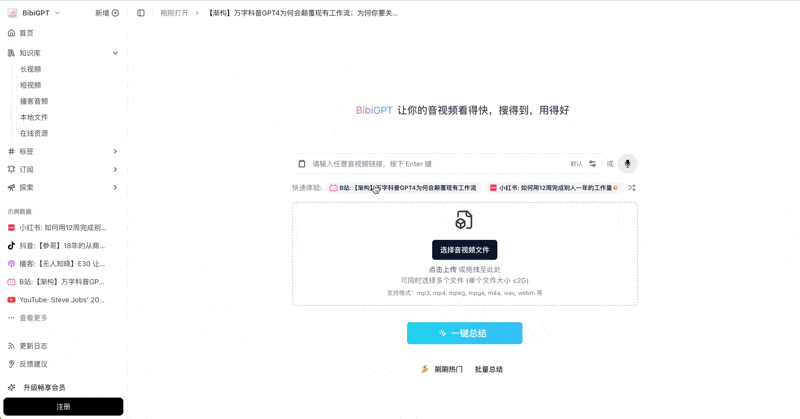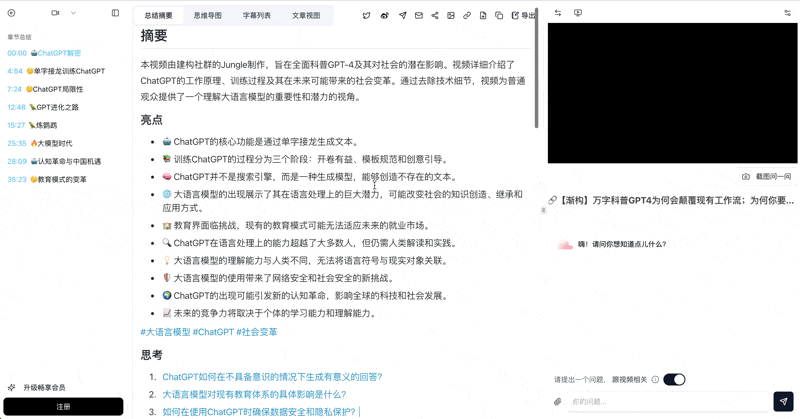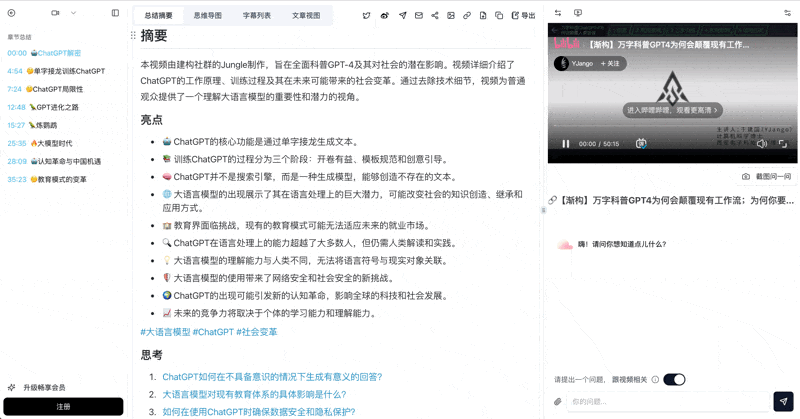
Bilibili: GPT-4 & Workflow Revolution
A deep-dive explainer on how GPT-4 transforms work, covering model internals, training stages, and the societal shift ahead.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free相关阅读:
核心功能:Obsidian 自动保存、自定义提示词总结、合集 AI 对话。
BibiGPT 团队