BibiGPT AI Video Summary Tool: 7 Features You Can Try Right Now
Hands-on interactive demos of BibiGPT's 7 core AI video features — paste a link to try video recognition, AI summaries, subtitle extraction, chapters, mind maps, AI rewrite, and visual storytelling.
BibiGPT AI Video Summary Tool: 7 Features You Can Try Right Now
You bookmarked dozens of YouTube tutorials, podcast episodes, and online courses. How many have you actually gone back to? If the answer is "not many," the problem isn't your willpower — it's that video content is trapped in a format that's hard to search, skim, or reuse.
BibiGPT isn't just another "video summarizer." It can perform 7 different types of AI processing on a single video — from subtitle extraction to infographic generation — covering the entire journey from consuming content to creating with it.
Every module below is a live interactive demo powered by real video data. No signup required — just scroll and try.
1. Paste a Link, Instant Recognition
Ever found the perfect video, only to discover your tool doesn't support that platform?
BibiGPT works with YouTube, Bilibili, TikTok, Xiaohongshu, podcasts, Twitter/X, and 30+ platforms. Paste a link, and it instantly identifies the platform, pulls the title, thumbnail, and duration — usually within 1 second.
Try it with your own link:
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
2. AI Smart Summary
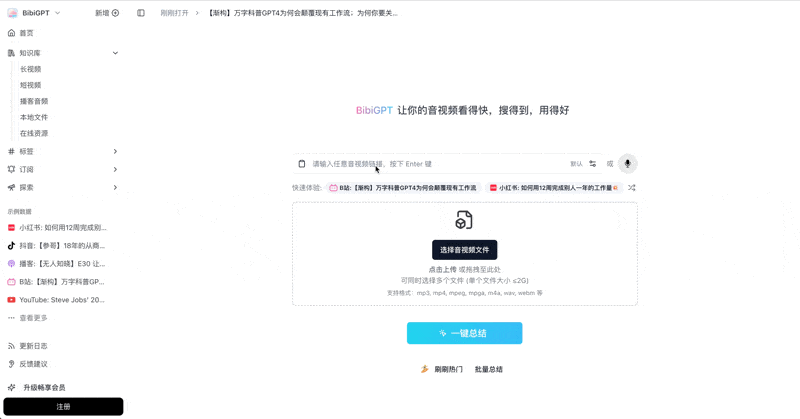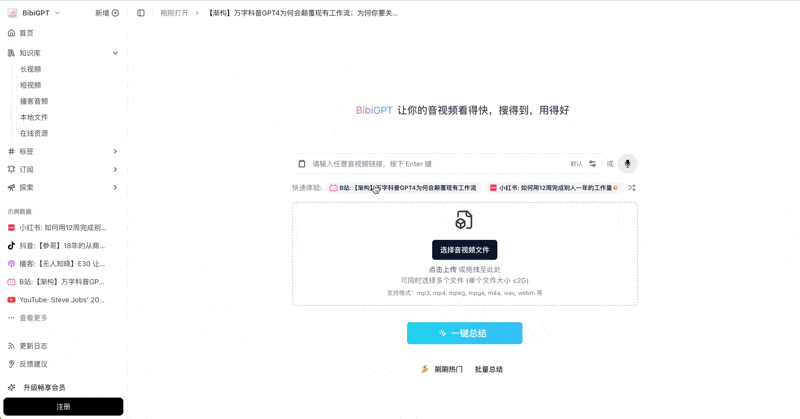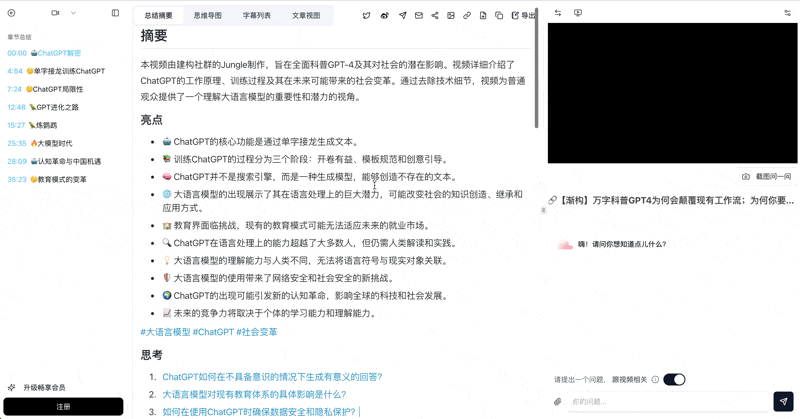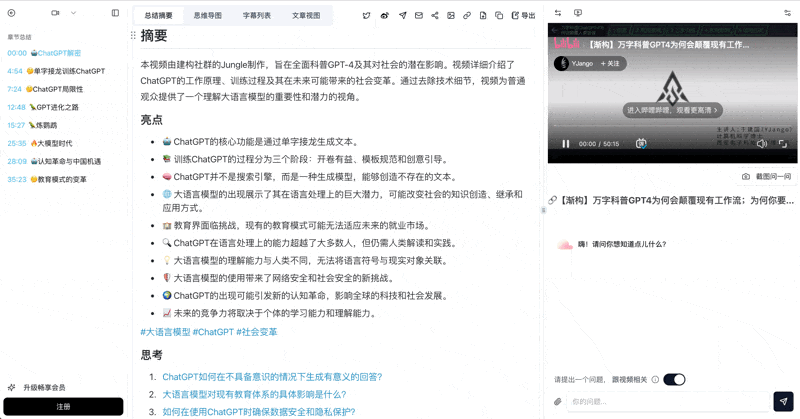
This is what most people try first: turning a 30-minute video into a structured summary you can read in 30 seconds.
The AI identifies core arguments and generates key takeaways, highlighted insights, and suggested follow-up questions. Different content types — tech reviews, lectures, podcast interviews — get tailored summary styles.
Switch between the examples below to see how summaries work across different platforms:
See BibiGPT's AI Summary in Action
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT Free3. Subtitle Extraction with Timestamps
Writing a paper and need to cite exactly what someone said at minute 14:32? Taking notes and want to know when a specific concept was mentioned?
BibiGPT extracts full transcripts with per-line timestamps. It's not limited to YouTube's built-in captions — even if the original video has no subtitles, AI-powered speech recognition generates them automatically.
AI Subtitle Extraction Preview
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeEvery line is clickable to jump to that exact moment in the video. No more scrubbing back and forth through a progress bar when you're doing research or compiling notes.
4. Intelligent Chapter Segmentation
A 40-minute video where the first 10 minutes are small talk, and the part you care about starts at minute 23 — but there's no way to know that upfront.
BibiGPT's intelligent chapter segmentation automatically splits videos into logical sections, each with its own summary. Think of it as a table of contents — see the full structure in 3 seconds, then jump straight to the section you need:
AI Chapter Summary Preview
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeFor meeting recordings, online courses, and long podcasts that run over an hour, this feature alone can save you significant time.
5. Mind Maps
Read a summary and felt like you understood it, only to forget everything two days later?
Mind maps transform video content into visual knowledge structures, revealing hierarchical relationships and logical connections. One diagram captures the entire knowledge framework of a video:
AI Mind Map Preview
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeThe full version supports interactive expand/collapse, image export, and syncing to Notion, Obsidian, and other note-taking tools — turning videos into a real part of your second brain.
6. AI Rewrite
Summarizing compresses information. Rewriting creates something new — they're fundamentally different.
BibiGPT's AI Rewrite transforms video content into narrative, structured articles with section headings, transitions, and complete arguments. Ready to publish as blog posts, newsletters, or study notes:
AI Rewrite Preview
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeContent creators use this to turn a 10-minute video into a written article in under a minute. That's not a metaphor — it's a genuine 10x efficiency gain.
7. Visual Storytelling
This is BibiGPT's most delightful surprise: AI analyzes the video's core insights and automatically generates SVG infographics — one image per concept:
Visual Storytelling Preview
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
No visualization data available
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeThese aren't simple text screenshots — they're properly designed visual content you can use directly in presentations, social media posts, or as visual memory anchors for learning.
Summary: One Link, Seven AI Powers
| Feature | Your Pain Point | How BibiGPT Helps |
|---|---|---|
| Link Recognition | Not sure if the tool supports this platform | 30+ platforms, auto-detected |
| AI Summary | No time to watch a 30-min video | Structured summary in 30 seconds |
| Subtitle Extraction | Need to quote a specific line but can't find the timestamp | Full transcript + timestamps, click to jump |
| Chapter Segmentation | Long video, no idea which part covers what | Auto-chapters with individual summaries |
| Mind Maps | Watched it, understood it, forgot it | Visual knowledge structure, syncs to note tools |
| AI Rewrite | Want to turn a video into an article but no time to write | Structured article in under a minute |
| Visual Storytelling | Need a visual for a presentation but can't design | AI-generated SVG infographics |
All seven capabilities are triggered by pasting a single link.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team