Microsoft MAI-Transcribe-1 vs Cohere Open-Source ASR: What It Means for AI Video Summarization (2026)
Microsoft launched MAI-Transcribe-1, the most accurate AI transcription model supporting 25 languages at $0.36/hr. Cohere released open-source Transcribe with 2B params and WER 5.42. How BibiGPT benefits from this AI transcription revolution.
Microsoft MAI-Transcribe-1 vs Cohere Open-Source ASR: What It Means for AI Video Summarization (2026)
Last updated: April 2026
In April 2026, the AI transcription landscape shifted dramatically with two major launches. Microsoft released MAI-Transcribe-1 — claiming the title of the world's most accurate AI transcription model with 25-language support, 2.5x faster inference, and just $0.36/hour pricing. Simultaneously, Cohere launched its open-source ASR model Transcribe — a 2B-parameter model achieving WER 5.42 that runs on consumer GPUs. For products like BibiGPT, trusted by over 1 million users for AI audio-video summarization, better transcription engines mean better summaries, better knowledge extraction, and a better user experience across 30+ supported platforms.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
MAI-Transcribe-1: Microsoft's Most Accurate Transcription Model
MAI-Transcribe-1 is Microsoft's April 2026 release that claims the lowest word error rate among commercial transcription models. Supporting 25 languages with 2.5x faster inference and $0.36/hour API pricing, it sets a new benchmark for enterprise-grade speech-to-text accuracy and cost-efficiency.
25-Language Coverage
MAI-Transcribe-1 is not just an English breakthrough. It natively supports 25 languages including Chinese, Japanese, Korean, Spanish, Arabic, and other major global languages. For scenarios involving multilingual audio-video content — international conference recordings, multilingual podcasts, cross-border training videos — a single model can handle most language needs without deploying separate transcription engines per language.
2.5x Inference Acceleration
Speed is a critical factor in real-world transcription experience. MAI-Transcribe-1 processes audio 2.5x faster than its predecessor, meaning a one-hour video gets transcribed in significantly less time. For users who need to batch-process audio and video content, this speed gain translates directly into productivity gains.
$0.36/Hour Cost Advantage
In the commercial transcription API market, pricing has always been a key consideration. MAI-Transcribe-1 brings costs down to $0.36 per hour — a significant reduction compared to previous mainstream solutions. Lower underlying transcription costs give downstream products more room to offer cost-effective speech-to-text services to end users.
Precision Leadership
According to Microsoft's official benchmarks, MAI-Transcribe-1 achieves the lowest word error rate (WER) across multiple standard benchmarks, with particular strength in noisy environments, multi-speaker scenarios, and content dense with professional terminology. High-precision transcription is the foundation of AI summary quality — if the underlying subtitles contain errors, downstream AI podcast summaries and knowledge extraction will suffer as well.
Cohere Transcribe: The Open-Source Breakthrough
Cohere Transcribe is an open-source ASR model released in April 2026, achieving WER 5.42 with just 2B parameters while running on consumer GPUs. It represents the most significant open-source speech recognition breakthrough in years, democratizing high-quality transcription for individual developers and small teams.
Lightweight 2B-Parameter Design
Unlike large language models with tens of billions of parameters, Cohere Transcribe uses only 2B parameters yet delivers impressive performance on speech recognition tasks. This lightweight design means lower deployment barriers, faster inference speeds, and less compute resource consumption.
WER 5.42: A New Open-Source Benchmark
Word Error Rate (WER) is the core metric for transcription accuracy. Cohere Transcribe achieves 5.42 WER, a leading result among open-source ASR models. This means roughly 5.4 words per 100 are incorrectly recognized — more than accurate enough for most audio-video subtitle extraction and summarization needs.
Runs on Consumer GPUs
This is Cohere Transcribe's most disruptive feature. No expensive A100 or H100 required — a consumer-grade GPU like the RTX 4090 can run it smoothly. This means:
- Individual developers can build high-quality transcription services locally
- Enterprises can deploy in private environments to ensure data privacy
- The open-source community can rapidly iterate and customize based on the model
Catalyst for the Open-Source Ecosystem
By choosing to open-source Transcribe, Cohere is accelerating the evolution of the entire AI transcription ecosystem. More developers can fine-tune the model for specific industry terminology, dialect accents, or professional domains. This open-source-driven innovation cycle often moves faster than proprietary commercial models.
AI Subtitle Extraction Preview
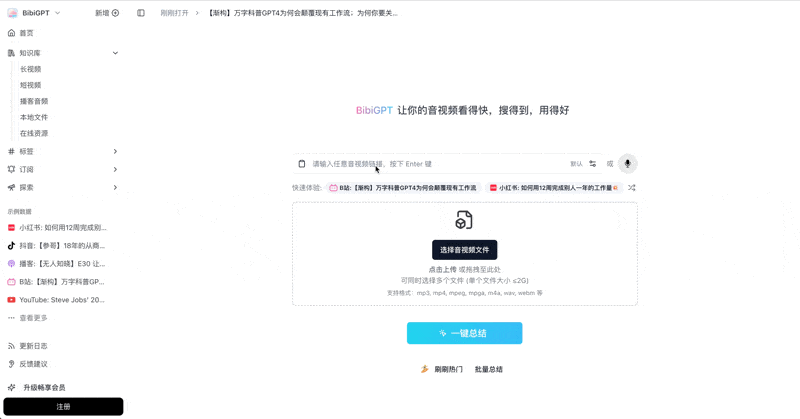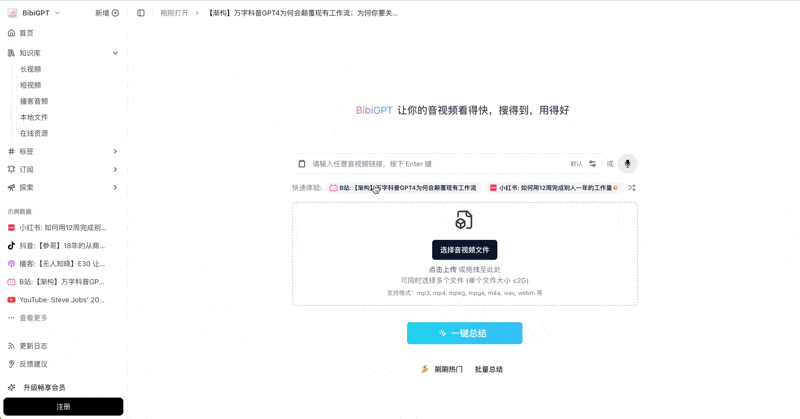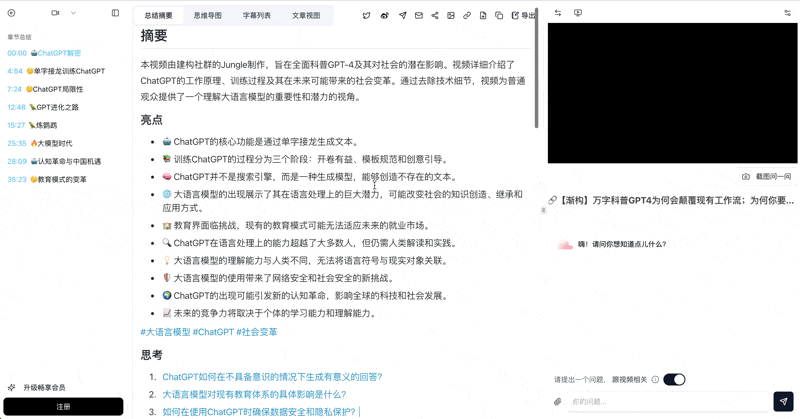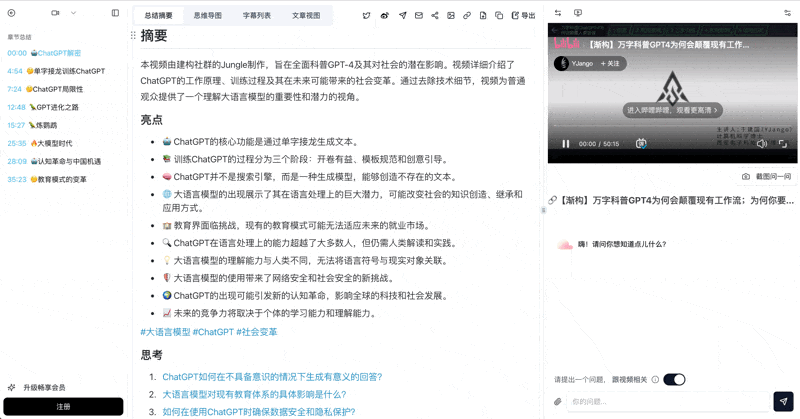
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeHead-to-Head: Microsoft vs Open Source — Which Is Right for You?
MAI-Transcribe-1 and Cohere Transcribe represent the latest peaks on the proprietary and open-source paths respectively. Your choice depends on your specific needs: choose Microsoft for maximum accuracy and multilingual coverage, or Cohere's open-source solution for local deployment and cost control.
| Dimension | MAI-Transcribe-1 (Microsoft) | Cohere Transcribe (Open Source) |
|---|---|---|
| Model Type | Proprietary commercial API | Open source (self-deployable) |
| Parameters | Undisclosed | 2B |
| Language Support | 25 languages | Major languages (expanding) |
| Accuracy (WER) | Lowest in industry (official claim) | 5.42 (best open-source) |
| Inference Speed | 2.5x acceleration | Real-time on consumer GPU |
| Cost | $0.36/hour (API) | Hardware cost only (self-hosted) |
| Deployment | Cloud API | Local / private cloud / cloud |
| Data Privacy | Data passes through Microsoft cloud | Fully local control |
| Best For | Enterprise-scale transcription | Developers / privacy-sensitive use |
Key insight: These two are complementary, not competing. Commercial APIs suit enterprises needing out-of-the-box, multilingual transcription at scale. Open-source solutions suit teams needing deep customization, data privacy, and cost control. For a platform like BibiGPT, both paths can serve as candidate underlying transcription engines, dynamically selected based on each use case.
How BibiGPT Benefits: Better Transcription Means Better Summaries
Every percentage point improvement in transcription accuracy is directly reflected in BibiGPT's AI summary quality. As an AI audio-video assistant that has generated over 5 million AI summaries across 30+ platforms, BibiGPT's core advantage lies in deeply integrating underlying transcription with upper-layer AI summarization.
Transcription Is the Foundation of AI Summaries
The quality ceiling of any AI summary is determined by the quality of its input text. If the transcription stage produces significant errors — professional terminology misrecognized, speakers confused, accents mishandled — every downstream feature suffers: summaries, mind maps, AI chat with sources, and more. The accuracy improvements from MAI-Transcribe-1 and Cohere Transcribe mean BibiGPT users receive more accurate subtitle text, and AI summary quality rises accordingly.
Multi-Engine Flexible Routing
BibiGPT already supports custom transcription engines, allowing users to choose different transcription solutions based on their needs. As next-generation models like MAI-Transcribe-1 mature, BibiGPT can seamlessly integrate superior transcription engines on the backend — users benefit from accuracy improvements without any additional steps.
Cost Reduction Benefits Users
MAI-Transcribe-1 brings commercial transcription costs down to $0.36/hour. Cohere Transcribe eliminates API fees entirely through open source. Lower underlying costs give BibiGPT more room to offer better value — longer free transcription quotas, more language support, and higher-accuracy meeting transcription experiences.
The Complete Pipeline: From Transcription to Knowledge
Unlike standalone transcription tools, BibiGPT provides a complete pipeline from transcription to summarization to knowledge creation. Paste a video link, and BibiGPT automatically handles subtitle extraction, AI summary generation, mind map construction, and multilingual translation. Transcription is just the starting point; knowledge output is the destination. This is the core value that separates BibiGPT from bare transcription APIs.
Frequently Asked Questions
What is MAI-Transcribe-1?
MAI-Transcribe-1 is Microsoft's advanced AI transcription model released in April 2026. It supports 25 languages, runs 2.5x faster than its predecessor, and costs just $0.36/hour via API. It achieves the lowest word error rate on multiple standard benchmarks, representing the state of the art in commercial speech-to-text technology.
What is the difference between Cohere Transcribe and MAI-Transcribe-1?
The core difference is open source vs proprietary. Cohere Transcribe is an open-source model (2B parameters) that runs on consumer GPUs locally, ideal for privacy-sensitive and customization-heavy use cases. MAI-Transcribe-1 is Microsoft's proprietary API with the advantage of 25-language coverage and peak accuracy, suited for enterprise-scale transcription.
What do these new transcription models mean for BibiGPT users?
Better transcription accuracy directly improves AI summary quality. BibiGPT's speech-to-text capability can integrate superior underlying engines, meaning users get more accurate subtitles and higher-quality AI summaries without any extra effort.
Can Cohere Transcribe really run on a regular GPU?
Yes. With only 2B parameters, Cohere Transcribe has been optimized to run in real-time on consumer GPUs like the RTX 4090. This is one of its biggest advantages over large commercial models — high-quality transcription no longer requires expensive server infrastructure.
How can I experience high-accuracy AI transcription and summarization?
Three simple steps: visit aitodo.co, paste any audio or video link (30+ platforms supported), and click generate to receive high-accuracy subtitles and an AI summary. BibiGPT automatically selects the optimal transcription engine to ensure the most accurate results.
Conclusion
The simultaneous release of MAI-Transcribe-1 and Cohere Transcribe in April 2026 marks a new era for AI transcription — proprietary and open-source solutions are both breaking through, with accuracy and accessibility advancing in tandem. For BibiGPT users, this means more accurate subtitles, higher-quality AI summaries, and richer language support.
Advances in underlying technology ultimately flow through to user experience. BibiGPT will continue integrating the most advanced transcription technologies so every user can access the highest-quality audio-video knowledge extraction at the lowest possible barrier.
Try BibiGPT's AI audio-video summarization now: aitodo.co