Microsoft MAI-Transcribe-1 vs BibiGPT ASR: 25-Language SOTA STT Has Arrived (2026)
Microsoft MAI-Transcribe-1 vs BibiGPT ASR: 25-Language SOTA STT Has Arrived (2026)
As of 2026-04-28 | Based on Microsoft Foundry’s 2026-04-02 release
TL;DR: Microsoft shipped MAI-Transcribe-1 on Foundry on 2026-04-02, pushing the 25-language FLEURS WER below Whisper-large-v3. It’s the most consequential multilingual STT release in two years. But for BibiGPT users this isn’t a “switch ASR yes/no” question — BibiGPT already treats OpenAI Whisper, ElevenLabs Scribe, and SenseVoice as swappable engines, and we’ll keep adding new SOTA models like MAI-Transcribe-1 under the same “best engine per language” routing rule. What actually decides the user experience is the LLM summarization, visual analysis, and knowledge-management layer sitting on top.
1. Background: What is MAI-Transcribe-1?
Event: Microsoft launched MAI-Transcribe-1 on Microsoft Foundry on 2026-04-02 (official changelog), positioned as a “professional-grade multilingual STT foundation model.”
| Date | Event |
|---|---|
| 2026-04-02 | Microsoft releases MAI-Transcribe-1 + companion MAI-Voice-1 on Foundry |
| 2026-04-02 ~ 2026-04-15 | Independent FLEURS / Common Voice tests confirm MAI-Transcribe-1 beats Whisper-large-v3 on average |
| 2026-04-27 | BibiGPT marks the event as a P1 trending hotspot for blog + feature consumption |
Key facts: 25 languages, FLEURS average WER below Whisper-large-v3. Same product slot as Whisper-large-v3, ElevenLabs Scribe, or Cohere Transcribe — what’s new is the multilingual average gain.
Important caveat: SOTA average ≠ best in every language. The reality of multilingual ASR is that “Engine A is best for Chinese, B for English, C for Japanese/Korean.” BibiGPT’s strategy has always been “route per language to whichever ASR is best,” and that won’t change because of one new model.
2. Deep Analysis: Tech, Market, Ecosystem
2.1 Tech — Where the real gain lives
- Multilingual average WER drops: FLEURS is the de-facto multilingual benchmark, and MAI-Transcribe-1 lifts most of the 25 languages simultaneously, not just English.
- Unified architecture + bigger data: Microsoft went the “bigger model + broader data” route. Long-tail languages (Southeast Asian, Eastern European) benefit most.
- Latency & throughput: This release targets professional batch transcription, not real-time streaming captions. Streaming-first engines still have headroom.
2.2 Market — Pro-grade ASR enters a four-horse race
| Engine | Strengths | Typical weakness |
|---|---|---|
| OpenAI Whisper-large-v3 | Open-source, robust English, biggest ecosystem | Long-form alignment, small-language WER |
| ElevenLabs Scribe | Top-tier accuracy & diarization | Premium pricing |
| Cohere Transcribe | 14 languages, enterprise free tier | Noisy/video scenes still need tuning |
| MAI-Transcribe-1 (new) | 25-language average SOTA, Microsoft ecosystem | Pricing, regions, latency TBD |
A four-horse race punishes products that bet on a single ASR — and rewards products with a pluggable ASR layer.
2.3 Ecosystem — “ASR is no longer scarce; consumption speed is”
The closer ASR gets to SOTA, the closer the value of raw transcripts gets to zero — anyone can extract a transcript from a 1-hour YouTube video. What’s actually scarce:
- Turning transcripts into structured knowledge (chapters, key points, timestamps, mind maps)
- Cross-video / collection-level semantic search and chat
- Multimodal analysis combining transcript + visual frames (slides, diagrams, whiteboards)
- The knowledge-graph link to Notion / Obsidian / Readwise
That’s the dividing line between consumer products like BibiGPT and ASR foundation models.
3. What This Means for BibiGPT Users
3.1 Content creators
Lower WER directly benefits multilingual creators:
- Bilingual podcasts, multilingual documentaries, cross-language captions all see lower review cost.
- Through BibiGPT’s custom transcription engine, MAI-Transcribe-1 can be added as a candidate and auto-routed by language.
3.2 Students & researchers
Cross-language learning (English MOOCs, Japanese/Korean interviews, EU conference videos) is the biggest beneficiary. Stack it with BibiGPT’s AI video chat + mind map and the entire “understand → digest → save” loop improves.
3.3 Enterprise & API customers
- Every 1pp gain in meeting/training/customer-support ASR accuracy compounds into real cost savings on review and translation.
- BibiGPT API users get transparent engine upgrades — no business-side code changes when we swap underlying ASR.
4. The BibiGPT Stack: Putting SOTA ASR to Work Today
This workflow holds whether the underlying engine is Whisper, Scribe, or MAI-Transcribe-1.
Step A — Pick your input
- YouTube / Bilibili / podcasts → paste into BibiGPT, routing into Bilibili video-to-text, YouTube transcript generator, or podcast transcript.
- Local meetings / lectures → upload via local video-to-text or free online speech-to-text. For sensitive material, enable Local Privacy Mode.
Step B — Turn transcripts into structure
BibiGPT layers on top of any transcript:
- Chapter summaries with timestamps
- One-click mind maps
- Video chat with source-cited answers
- Visual frame analysis (slides, diagrams, whiteboards)
Step C — Settle into your second brain
| Goal | Workflow |
|---|---|
| Newsletter / blog | Video-to-article → polish → export |
| Academic research | Export Markdown → Obsidian / Notion |
| Team retros | Export PPT / mind map → share |
Step D — Engine switching for power users
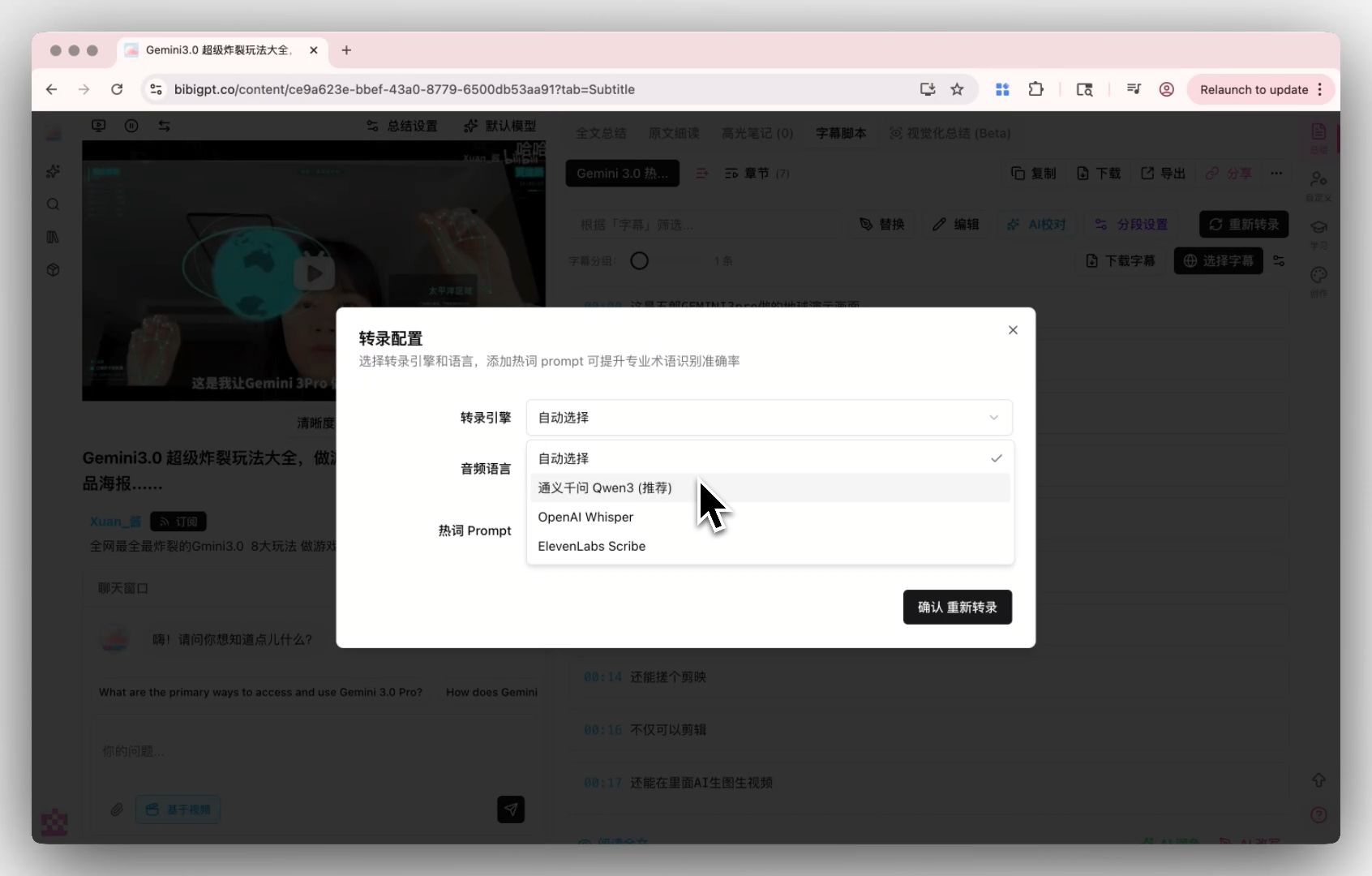
In the transcript view, click “Re-transcribe” to choose ElevenLabs Scribe / Whisper / (MAI-Transcribe-1 once integrated). This switch is how BibiGPT differentiates from “single-ASR-locked” products.
If you’re building on the BibiGPT API, you’ll inherit SOTA upgrades without code changes.
5. Outlook: Three Trends for the Next 6-12 Months
- ASR commoditization accelerates — gaps between Microsoft / OpenAI / Anthropic / Alibaba / Cohere narrow; “best-WER” alone stops being a moat.
- Multimodal ASR becomes default — pure transcripts give way to “transcript + frames + speakers + emotion” structured outputs. BibiGPT’s visual content analysis is exactly this direction.
- Long-tail languages become the real battleground — Cantonese, Hokkien, Indonesian, Vietnamese coverage will decide the next round.
6. FAQ
Q1: What ASR does BibiGPT use today?
A: Auto-routed by language and scenario (OpenAI Whisper / ElevenLabs Scribe / on-device SenseVoice). Power users can switch manually in the transcript view and even bring their own API key.
Q2: Will MAI-Transcribe-1 become BibiGPT’s default once integrated?
A: Our policy is “best engine per language.” MAI-Transcribe-1 leads the FLEURS average, but per-language ranking still varies. It will join the auto-routing pool, not flat-replace Whisper.
Q3: Can I use MAI-Transcribe-1 inside BibiGPT today?
A: Not yet, as of 2026-04-28. We’re tracking it as a candidate engine pending Foundry API pricing, regions, and rate limits. Watch the release notes.
Q4: If ASRs all approach SOTA, what’s BibiGPT’s value?
A: Transcripts are 1% of the work. The other 99% is turning them into consumable knowledge — structured summaries, mind maps, AI chat, visual analysis, knowledge-tool integration. BibiGPT is a consumer-layer product, not an ASR foundation model.
Q5: What about privacy-sensitive material?
A: Use Local Privacy Mode: in-browser ASR via Whisper / SenseVoice, nothing uploaded.
7. Closing: Models Aren’t Scarce — Consumption Speed Is
MAI-Transcribe-1 is a real step forward, but it doesn’t make raw transcripts more valuable — it just intensifies the competition on the layer above. BibiGPT’s long-term positioning is simple: make consuming audio/video as fast as consuming text. That holds regardless of which ASR is currently SOTA.
Try BibiGPT now:
- Web: https://bibigpt.co/en/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=microsoft-mai-transcribe-1-vs-bibigpt-asr-2026
- Desktop: https://bibigpt.co/download/desktop
- Mobile: https://bibigpt.co/app
- Browser extension: https://bibigpt.co/apps/browser
BibiGPT Team