2024 LLM Summary Tool Showdown: GPT-4o, Claude 3.5, Gemini Pro, and More
A head-to-head review of today’s leading large language models—GPT-4o, GPT-4o mini, Claude 3.5 Sonnet, Google Gemini Pro 1.5, and other contenders—for summarizing audio and video content.
2024 LLM Summary Tool Showdown: GPT-4o, Claude 3.5, Gemini Pro, and More
Why LLM Summaries Matter
Video and podcast libraries are exploding. Bilibili, YouTube, and Spotify upload volumes make manual review impossible, so creators and knowledge workers are turning to large language models (LLMs) to condense long-form content into actionable notes.
This guide compares ten prominent models across cost, context window, multimodal support, and real-world summary quality. Whether you produce content or binge tutorials, you’ll know which model to trust for lightning-fast recaps.
What Drives Summary Quality?
Five factors determine whether an LLM delivers coherent, accurate summaries:
- Instruction tuning – Has the model been aligned for summarization tasks?
- Evaluation metrics – Benchmarks like ROUGE, METEOR, and BERTScore expose weak spots.
- Chunking strategy – How you slice transcripts affects recall and relevance.
- Preprocessing – Tokenization and cleaning influence how much context the model understands.
- Context length – Longer windows reduce “lost detail” on multi-hour media.
Keep these levers in mind as you pick a model or design your workflow.
The Lineup
We evaluated the following models inside BibiGPT’s summarization pipeline:
| Model | Context Window | Multimodal | Notes |
|---|---|---|---|
| GPT-3.5 Turbo / Instruct | 16K / 4K | ❌ | Fast and cheap; solid for text-only tasks. |
| GPT-4o mini | 128K | ✅ | Great balance of price, performance, and latency. |
| GPT-4o | 128K | ✅ | Flagship multimodal model with premium output fidelity. |
| Claude 3.5 Sonnet | 200K | ❌ | Excels at reasoning and long-form documents. |
| Google Gemini Pro 1.5 | 1M | ✅ | Handles huge contexts and mixed media inputs. |
| Gemma 2 9B | 8K | ❌ | Open-source option tuned for lightweight deployments. |
| DeepSeek-V2 | 65K | ❌ | Chinese-developed model with competitive accuracy. |
| Qwen 2 72B | 128K | ✅ (beta) | High accuracy in Chinese + English domains. |
| Meta Llama 3 8B | 8K | ❌ | Community favorite for on-prem setups. |
| Mistral 7B | 8K | ❌ | Efficient, open, and easy to fine-tune. |
GPT-3.5
- Strengths: Reliable, low-cost, ideal for lightweight text-only summaries.
- Limits: No multimodal input; smaller context makes it less ideal for multi-hour transcripts.
GPT-4o mini vs. GPT-4o
- 4o mini: Our go-to inside BibiGPT—fast, affordable, and surprisingly coherent.
- 4o: Adds premium reasoning, image/audio support, and higher accuracy for complex workloads.
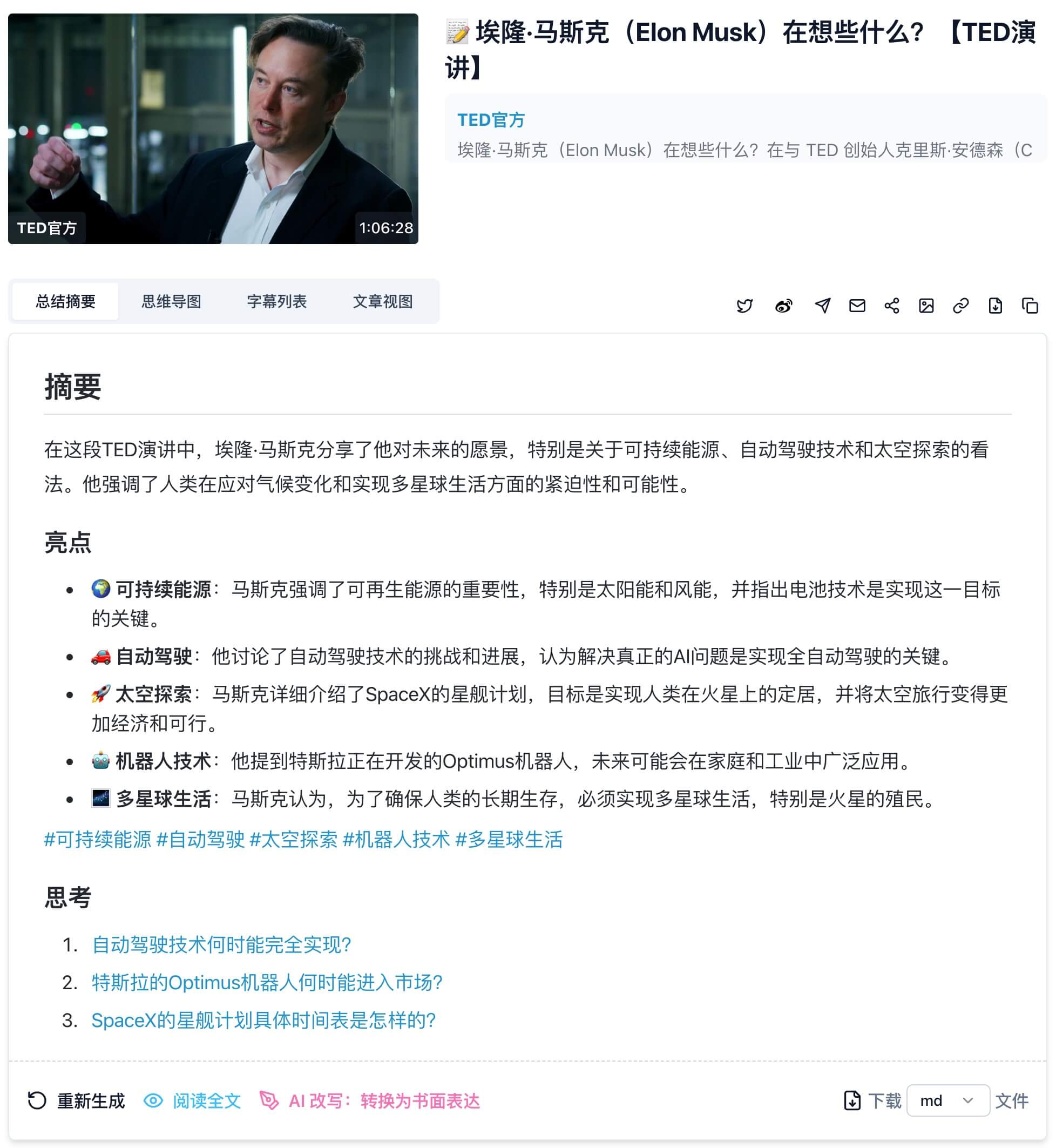 GPT-4o summary screenshot
GPT-4o summary screenshot
Claude 3.5 Sonnet
- 200K context makes it a champion for research papers, technical talks, and multi-chapter series.
- Lacks multimodal input but shines in reasoning and well-structured prose.
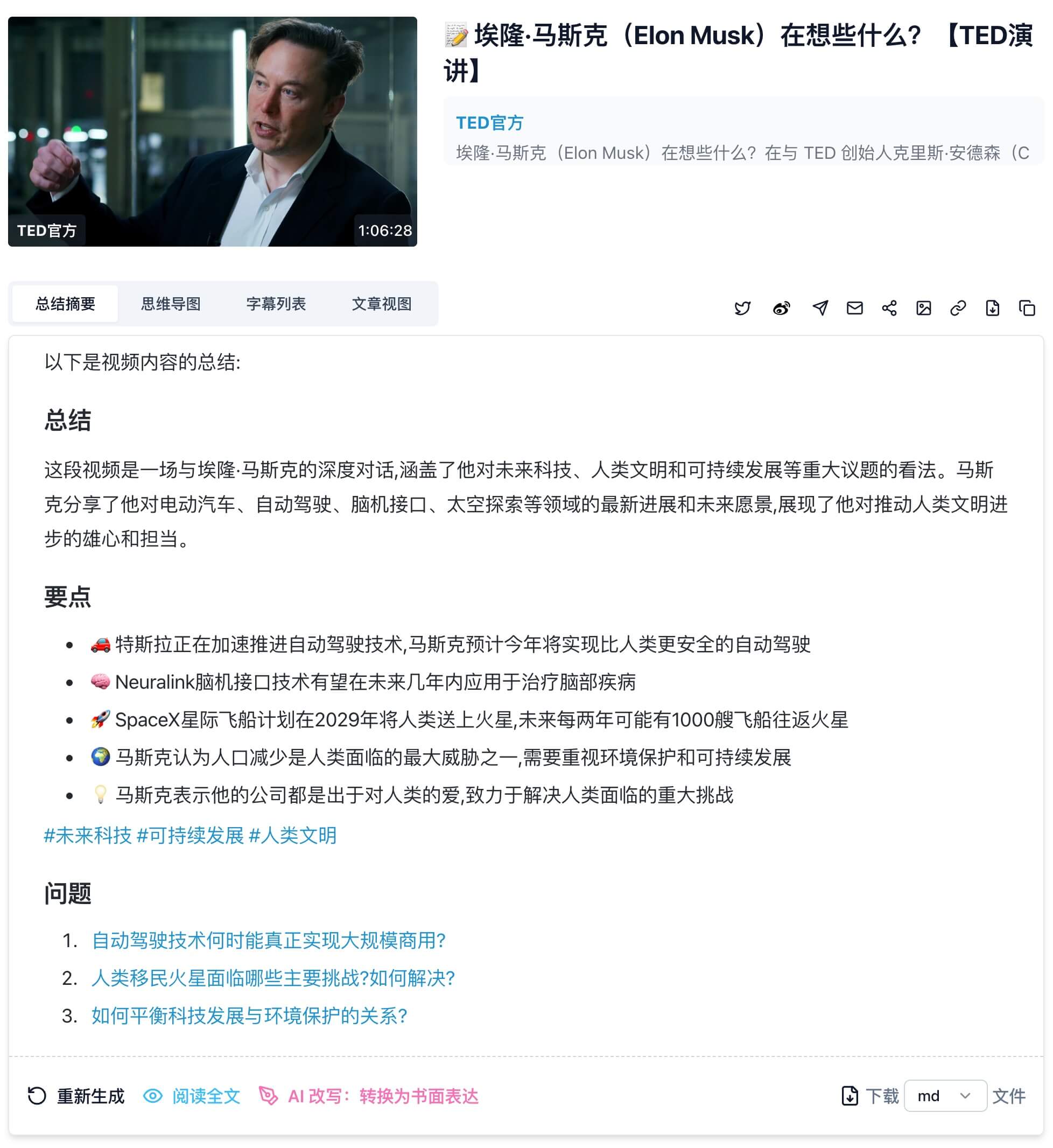 Claude 3.5 summary screenshot
Claude 3.5 summary screenshot
Google Gemini Pro 1.5
- 1M token window handles marathon transcripts and mixed media effortlessly.
- Multimodal support plus solid multilingual output; costs more but fits enterprise media pipelines.
Other Contenders
- Gemma 2 9B & Mistral 7B – Open-source models suited for self-hosted or GPU-constrained setups.
- DeepSeek-V2 & Qwen 2 72B – Strong Chinese support with competitive benchmarks.
- Llama 3 8B – Flexible licensing; results improve with prompt engineering.
Choosing the Right Model
| Scenario | Recommended Model |
|---|---|
| Short social clips or meeting notes | GPT-3.5 Turbo |
| Daily summaries in BibiGPT | GPT-4o mini |
| Premium podcasts, technical docs | GPT-4o or Claude 3.5 Sonnet |
| Massive lecture archives | Google Gemini Pro 1.5 |
| On-premises or low-cost deployments | Gemma 2, Mistral 7B, or Llama 3 |
Final Thoughts
No single LLM wins every category. Match the model to your transcript length, budget, multimodal needs, and deployment environment. Inside BibiGPT we default to GPT-4o mini for balanced performance, but offer GPT-4o, Claude 3.5, Gemini Pro, and more when you need extra muscle.
Want hands-on comparisons with screenshots and latency stats? Explore the full report inside BibiGPT’s summary settings—or reach out to our team for custom evaluations.