Do You Still Need BibiGPT After NotebookLM Integrates Into Gemini App? 2026 Deep Comparison
NotebookLM 2026 major update: Gemini App integration, Cinematic Video Overviews, three-column layout, EPUB support. Head-to-head with BibiGPT for YouTube/Bilibili/podcast one-click AI summaries. Selection matrix included.
Do You Still Need BibiGPT After NotebookLM Integrates Into Gemini App? 2026 Deep Comparison
Table of Contents
- Quick Answer: One-Line Picker
- What NotebookLM 2026 Actually Changed
- Why BibiGPT Is Not Replaced
- Scenarios: Who Picks NotebookLM, Who Picks BibiGPT
- Hands-On: Same Video In Both Tools
- Decision Matrix
- FAQ: NotebookLM Gemini Integration
Quick Answer: One-Line Picker
After NotebookLM moves into the Gemini App, pick NotebookLM if you live in Google Workspace and organize personal PDFs, Google Docs, and long-term research notebooks; pick BibiGPT if you process YouTube, Bilibili, TikTok, Xiaohongshu, and podcasts every day and want to paste a link and get an AI summary in 30 seconds, plus export to Anki flashcards or blog posts. They are not replacements — they are two different tracks: research-first notebooks vs. audio-video consumption.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
What NotebookLM 2026 Actually Changed
Core answer: According to Teachercast's April 2026 coverage and TechRepublic's Gemini Notebooks update brief, NotebookLM's April 2026 release focuses on four things: deep Gemini App integration (personal notebooks become chat sources), Cinematic Video Overviews (slide-video generation from sources), EPUB support, and a three-column layout. The headline signal: NotebookLM is no longer a standalone product, it is the center of the Gemini ecosystem.
1. Deep Gemini App Integration: Chat IS Source, Source IS Chat
Gemini App users can now invoke their personal NotebookLM notebooks directly inside chat as context, and Gemini chat history can flow back into NotebookLM as a source. The implication is that every question you ask Gemini feeds your private knowledge base — a clear push from "generic assistant" to "personalized assistant".
2. Cinematic Video Overviews + Slide Revisions
Auto-generates slides and info-graphic video from sources. This is essentially "PDF / Docs → explainer video". Education use cases are already being tested — Case Western Reserve University adopted it for faculty training.
3. EPUB Support + Three-Column Layout
EPUB means you can drop a whole book in for research Q&A; the three-column layout separates source, chat, and outputs into fixed panels, which feels closer to Notion or Obsidian.
4. Doubled Education Free Tier
Google also announced a May 13 AI training push for 6 million US educators, bundled with doubled NotebookLM quotas. The signal matters: Google is using the education channel to build brand habit, so students and teachers will be the cohort that absorbs NotebookLM's workflow first.
Why BibiGPT Is Not Replaced
Core answer: BibiGPT's differentiation is not "AI notes" itself — it is "audio-video URL in, digest out" as a single track. NotebookLM's sources still require you to move the content in first (URL source is YouTube-only), while BibiGPT natively accepts YouTube, Bilibili, TikTok, Xiaohongshu, podcasts (Apple Podcasts, Spotify, Xiaoyuzhou), and cloud-drive recordings — a paste-and-summarize flow on 30+ platforms.
1. Platform Coverage: 30+ Audio-Video Platforms
Supports YouTube, Bilibili, Douyin, TikTok, Xiaohongshu, podcasts, and cloud drives (Google Drive, Baidu Cloud, Alibaba Drive, Zoom recordings). NotebookLM's URL source today is YouTube-only. That is a hard gap.
2. Zero Install: Open aitodo.co and Paste
No auth wall before you see the product working. Paste a YouTube link and see the summary. NotebookLM requires a Google account, entering notebooklm.google.com, creating a notebook, and uploading or pasting a source — a longer path.
3. Deep Summary + Flashcards + Mind Map Trio
BibiGPT's smart deep summary produces structured outputs with highlights, reflective Q&A, and key term glossary. Flashcard export pushes CSV directly into Anki for spaced repetition. This trio is tailored for "watch the video, actually learn the content" — a closed loop NotebookLM's note-first model does not cover.
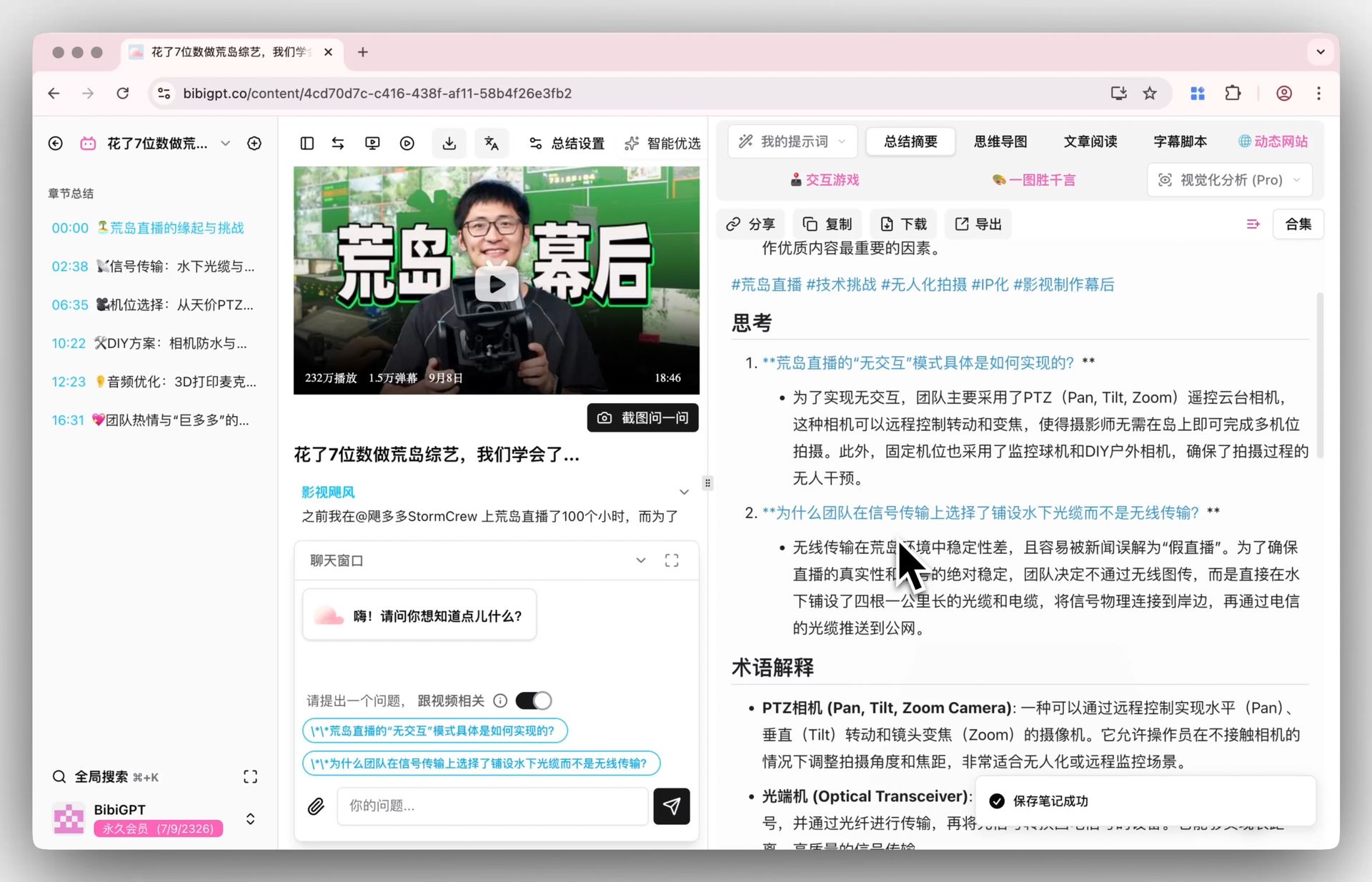 BibiGPT smart deep summary generating Q&A
BibiGPT smart deep summary generating Q&A
4. Multilingual Output + Frictionless Access
BibiGPT outputs in Chinese / English / Japanese / Korean natively. For users in mainland China, aitodo.co / bibigpt.co works without a VPN. NotebookLM requires a VPN for that audience, which is the first drop-off point for many students and professionals.
5. Creator-Oriented Outputs: Articles, Subtitles, Images
BibiGPT turns a video into Chinese public-account articles, Xiaohongshu image cards, short-video scripts, and translated embedded subtitles. NotebookLM's Cinematic Video Overviews is "content → video", which is a different direction.
Scenarios: Who Picks NotebookLM, Who Picks BibiGPT
Core answer: The decision isn't "which is better" — it's "what do you process every day?" PDFs, Docs, long-term research → NotebookLM. YouTube, Bilibili, podcasts, TikTok links → BibiGPT. Both can coexist when needed.
Scenario A: PhD Writing A Paper From 50 PDFs
NotebookLM wins. EPUB + PDF + three-column layout is designed for long-term research. BibiGPT is not the right fit for pure document workflows.
Scenario B: Daily YouTube / Bilibili Tutorial Digestion
BibiGPT wins. Paste a link, get timestamped summary + chapter split + keyword search. NotebookLM requires you to add each video to a notebook first — slower than a paste-and-go flow.
Scenario C: Podcast Listener Wants Searchable Notes After Commute
BibiGPT wins. Supports Apple Podcasts, Spotify, Xiaoyuzhou one-click summary + timestamped transcript export. NotebookLM's podcast support is limited to YouTube-hosted podcasts.
Scenario D: Student Turning Course Videos Into Flashcards
BibiGPT wins. Flashcard feature exports Anki CSV directly. NotebookLM has no equivalent export — see our AI student study workflow: MS Study Agent + BibiGPT 2026 for the end-to-end flow.
Scenario E: Content Creator Turning Videos Into Articles
BibiGPT wins. The article / Xiaohongshu / short-video script output pipeline is not NotebookLM's positioning.
Scenario F: Personal Knowledge Base Fed By Gemini History
NotebookLM wins. That is the native advantage of Gemini App integration, and BibiGPT does not compete on that axis.
See BibiGPT's AI Summary in Action
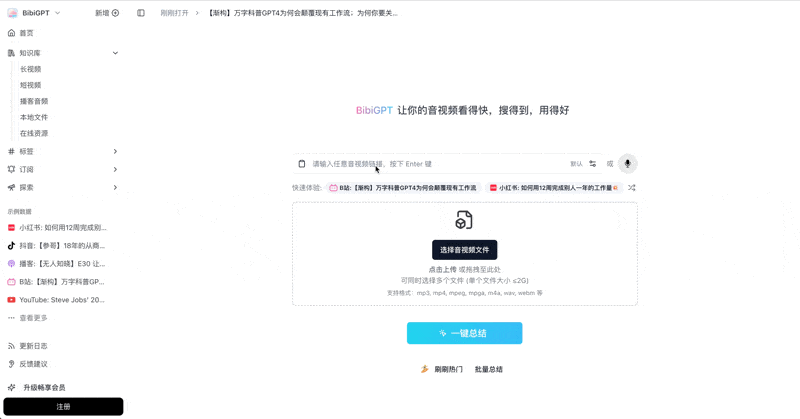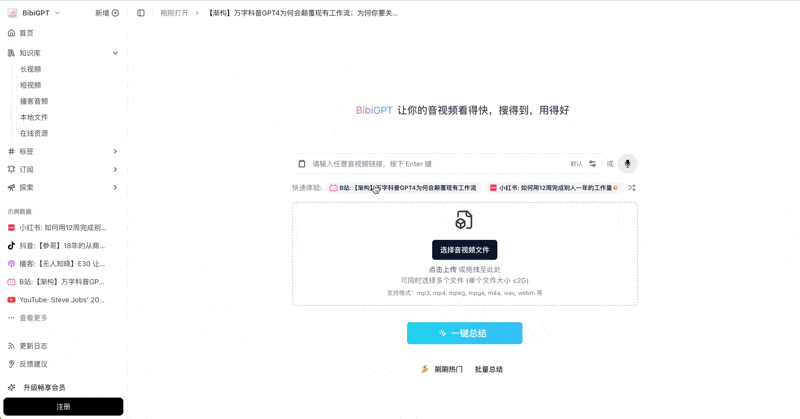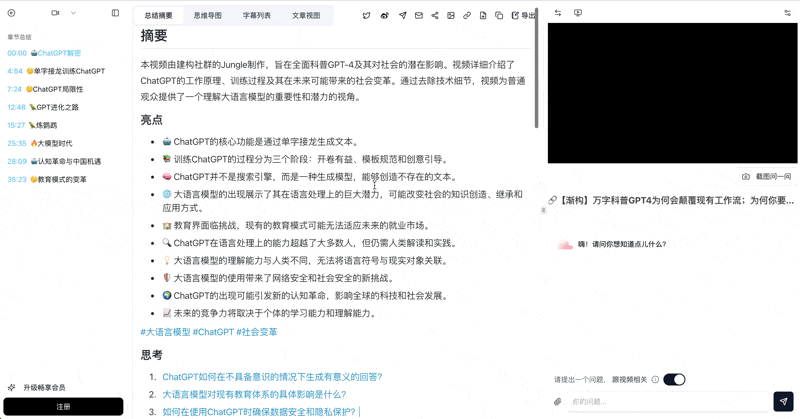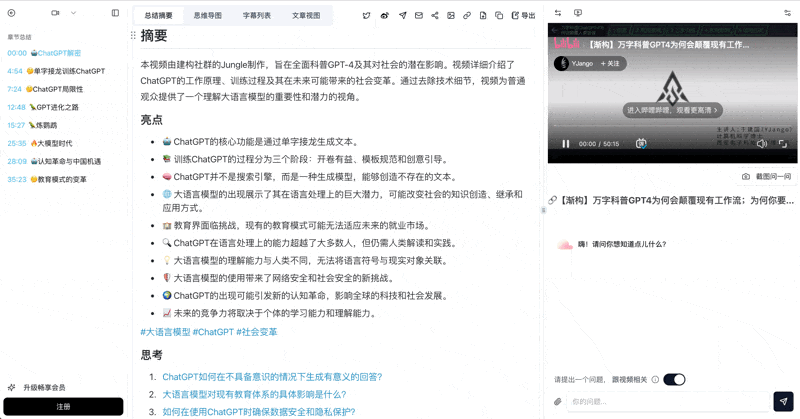
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeHands-On: Same Video In Both Tools
Core answer: We ran the same 1-hour YouTube tutorial through both. BibiGPT produced a structured summary with 12 timestamped segments, highlights, reflective questions, and glossary in 29 seconds, ready to paste into Notion. NotebookLM required creating a notebook, adding the source, and waiting ~2 minutes for indexing before Q&A could start. The outputs differ in shape — BibiGPT returns a "finished note"; NotebookLM returns a "queryable document knowledge base".
Decision Matrix
| Your Primary Scenario | First Pick | Complement |
|---|---|---|
| Paper / long-term research / PDF stack | NotebookLM | BibiGPT for video citations |
| Daily YouTube / Bilibili / podcasts | BibiGPT | NotebookLM for semester archive |
| Course video → Anki flashcards | BibiGPT | — |
| Content creation (articles / Xiaohongshu / shorts) | BibiGPT | — |
| Gemini chat history personalization | NotebookLM | — |
| China access, 4-language output | BibiGPT | — |
Related Reading
- Trend piece on AI video generation race: xAI Imagine Video + Grok vs BibiGPT 2026
- Student learning workflow: AI Student Study Workflow MS Study Agent + BibiGPT 2026
- Competitor roundup: 2026 Best AI Video Summary Tools
FAQ
Q1: Can I use NotebookLM directly inside Gemini App now?
A: Yes. Starting April 2026, Gemini App users can invoke personal NotebookLM notebooks as chat context, and Gemini chat content can flow back into NotebookLM as a source. The two surfaces are connected — no more switching apps.
Q2: Does NotebookLM support pasting Bilibili or TikTok links?
A: No. NotebookLM's URL-type source is YouTube-only. Bilibili, TikTok, Xiaohongshu, podcasts must be converted to PDFs or transcripts before import. BibiGPT natively supports paste-and-summarize for 30+ platforms.
Q3: Is Cinematic Video Overviews the same as BibiGPT's video summary?
A: No. Cinematic Video Overviews generates slide videos from sources (PDF / Docs) — "content → video". BibiGPT extracts text summaries from videos and exports downstream artifacts — "video → content". They are complementary directions, not replacements.
Q4: What does doubled Education Plus quota mean for students?
A: More free notebooks and source uploads. It does not change the "YouTube-only" URL limitation. Course recordings (Zoom, LMS videos) still need a tool like BibiGPT that supports cloud-drive videos.
Q5: Will using BibiGPT and NotebookLM together feel redundant?
A: No. The recommended combo is: BibiGPT pastes YouTube / Bilibili / podcast links daily to produce structured summaries and flashcards, exports best notes as Markdown; NotebookLM ingests those Markdown files plus PDFs and Docs as a semester- or project-level Q&A notebook. Clear division of labor.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team