動画と対話する:全部見ずに AI へ質問して答えを引き出す方法(2026)
動画と対話する:全部見ずに AI へ質問して答えを引き出す方法(2026)
最終更新:2026 年 6 月
手早い答え: 動画から 1 つの情報を得るために、もう全部を見る必要はありません。リンクを貼り、AI が動画内の発話を検索可能なテキストに変換したら、ふつうの言葉で質問するだけ——AI が答えを返し、該当するタイムスタンプまで示してくれます。BibiGPT の AI 動画要約拡張機能を使えば、YouTube・ニコニコ・ポッドキャストなど 30 以上のプラットフォームでこれができます。
「X の話の部分が神」と言われて 90 分の講義を開いた。でも X の部分はどこ? シークバーを 20 分ドラッグしても、まだ見つからない。情報はそこにあるのに、全部を見ない限りたどり着けない。
これがこのガイドが解決する核心の悩みです。2026 年には、任意の動画を「対話できるドキュメント」のように扱えます。質問を投げ、答えを受け取り、その発言が出てきた瞬間へワンクリックで飛ぶ。以下では「動画と対話する」が実際どう動くのか、それぞれの方法をいつ使うのか、そして一度きりの疑問を再利用できる構造化された答えに変える方法を解説します。
1. 「全部見る」がなぜ誤ったデフォルトなのか
動画は線形です。47 分目に何を言っているか知るには、旧来のやり方では 47 分目まで再生するしかありません。テキストは逆で、Ctrl+F 一発でどんな語も瞬時に見つかります。動画が重く感じるのは内容のせいではなく、重要な数秒を見つけるために、あなたが持っていない時間そのものを消費させられるからです。
解決策は、動画を「見るもの」として扱うのをやめ、「問いかけるもの」として扱うこと。発話がテキストになった瞬間、動画全体が質問可能になります。シークバーをドラッグする受け身の視聴者から、内容を直接尋問する側へ変わるのです。
実用ルール: 動画から答えが 1 つ欲しいだけなら、見ないこと——まずテキスト化し、それから質問する。
下の講義はまさに好例です。1 時間超の硬派な技術トークで、ほとんどの人は最後まで見ません。それでも、毎分を追わずにその答えを引き出せます。
出典:YouTube · 「全部見ずに AI へ質問する」ための長尺講義
2. 動画との対話は実際どう実現されるのか
魔法ではありません。「動画と対話する」は、はっきり思い描ける 3 層のプロセスです。
- 文字起こし——動画の発話をタイムスタンプ付きテキストに変える。これが動画から文字への工程で、下流のすべてはこれに依存します。
- インデックス化——そのテキストを整理し、AI が逐語ではなく「意味」で照合できるようにする。
- 回答——質問すると、AI が該当箇所を見つけ、直接的な答えを書き、出典のタイムスタンプを添える。
答えが常に出典に紐づいているため、「とにかく AI を信じて」と言われることはありません。どの回答にも、クリックして検証できる場所が付いています。これが「あいまいな要約」と「行動の根拠になる本物の Q&A」の違いです。
実用ルール: 良い動画の答えは必ず出典を伴う。確認できるタイムスタンプのない答えを返すツールは、警戒して扱うこと。
3. 動画に「正しい問い」を投げる
答えの質はあなたの問いの質で決まります。動画との対話では、発言された原文を覚えている必要はありません——欲しいものを自分の言葉で説明すればよいのです。
役立つ問いの形:
- 事実の確認——「話者が 2026 年の成長率として挙げた数字は?」
- 定義の確認——「ここでホストは『プロダクトマーケットフィット』をどう定義している?」
- 比較——「このゲストは定説に賛成か反対か、その理由は?」
- 行動——「彼らが勧める手順を、順番どおりに正確に教えて」
追問もできます。1 つ質問し、答えを読み、さらに掘る——「では、最も多い失敗は何だと言っていた?」。対話は積み上がり、これがあいまいな記憶を正確で出典付きの答えに変える方法です。
下のインタラクティブなデモで、動画への追問と、出典の瞬間付きの答えを体験できます:
動画に質問する
見たけどまだ疑問が?追加で質問すると、動画の内容に基づいた答えが出典時間つきで返ります。
質問をタップ:
デモ:BibiGPT AI 追問機能
4. タイムスタンプへ直接ジャンプする
答えは良い。ワンクリックで検証できる答えはもっと良い。動画との対話の肝は、AI が「話者は X と言った」と告げるだけでなく、どこかを示し、ワンクリックで動画のその一秒へ落とすところにあります。
正確さに妥協が許されない場面でこれが効きます。金融の数字、医療の主張、引用された統計、法的な論点。AI の答えを読み、タイムスタンプをクリックし、文脈の中で話者本人の言葉として聞く。1 つの行を確認するために 10 分を見直すことは、もうありません。
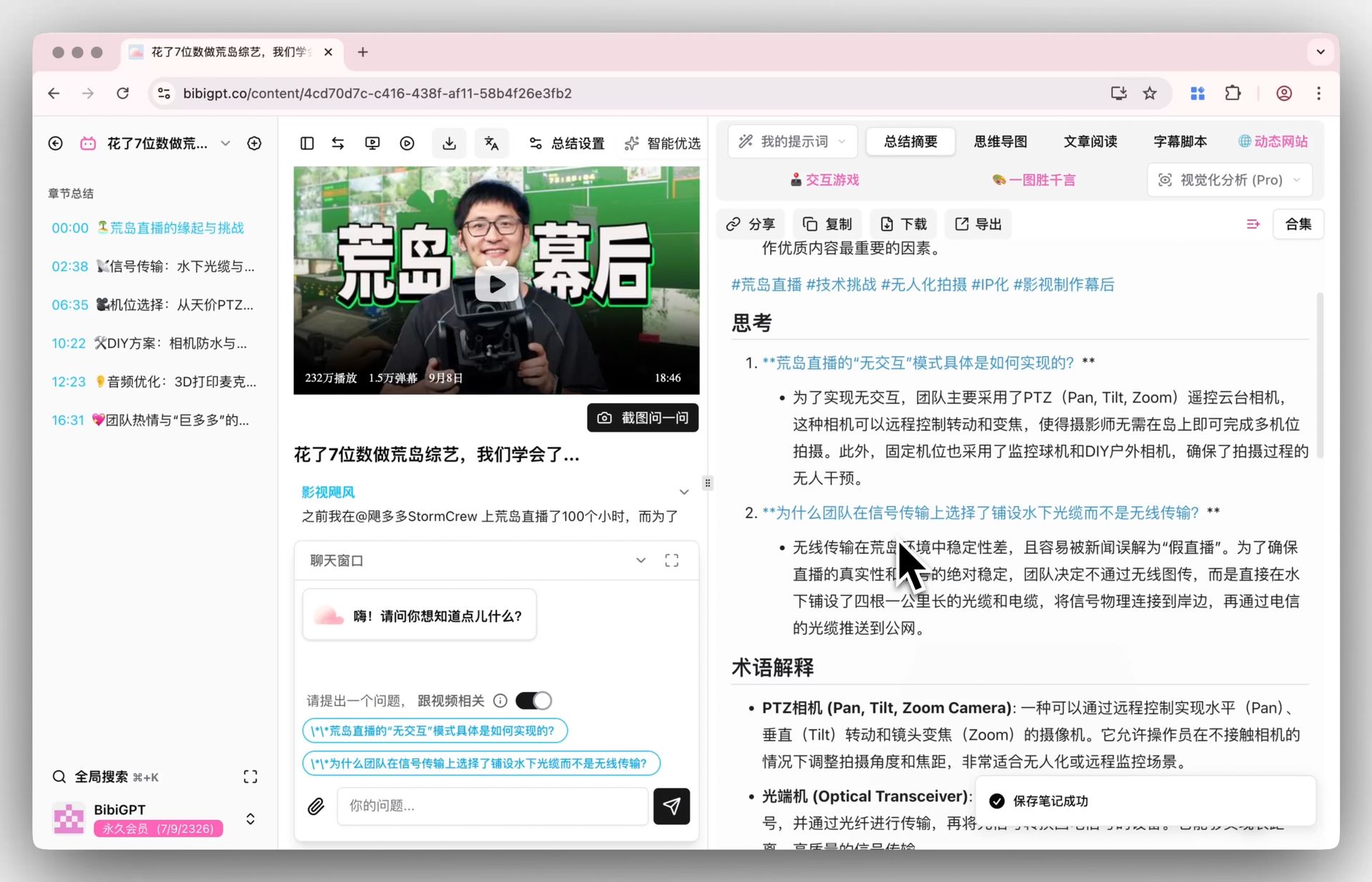
スクリーンショット:BibiGPT · 追問付きの AI 要約
実用ルール: 引用したり判断の根拠にする内容は、必ずタイムスタンプまでクリックする——答えを読み、出典で確認する。
5. 複数の動画へ同時に質問する
1 本の動画は簡単なケースです。本当の調査は「複数の間」に宿ります。同じテーマの動画を 10 本以上見たとき、難しい問いは「これは何を言ったか」ではなく「これらの出典は一致するのか、どこで矛盾するのか」です。
ここで横断質問がルールを書き換えます。関連動画を 1 つのコレクションにまとめ、コレクション全体へ質問する。AI はその集合の各動画を読み通し、比較・合意点・矛盾を添えて答えます——それぞれがどの動画に由来するかを明示して。
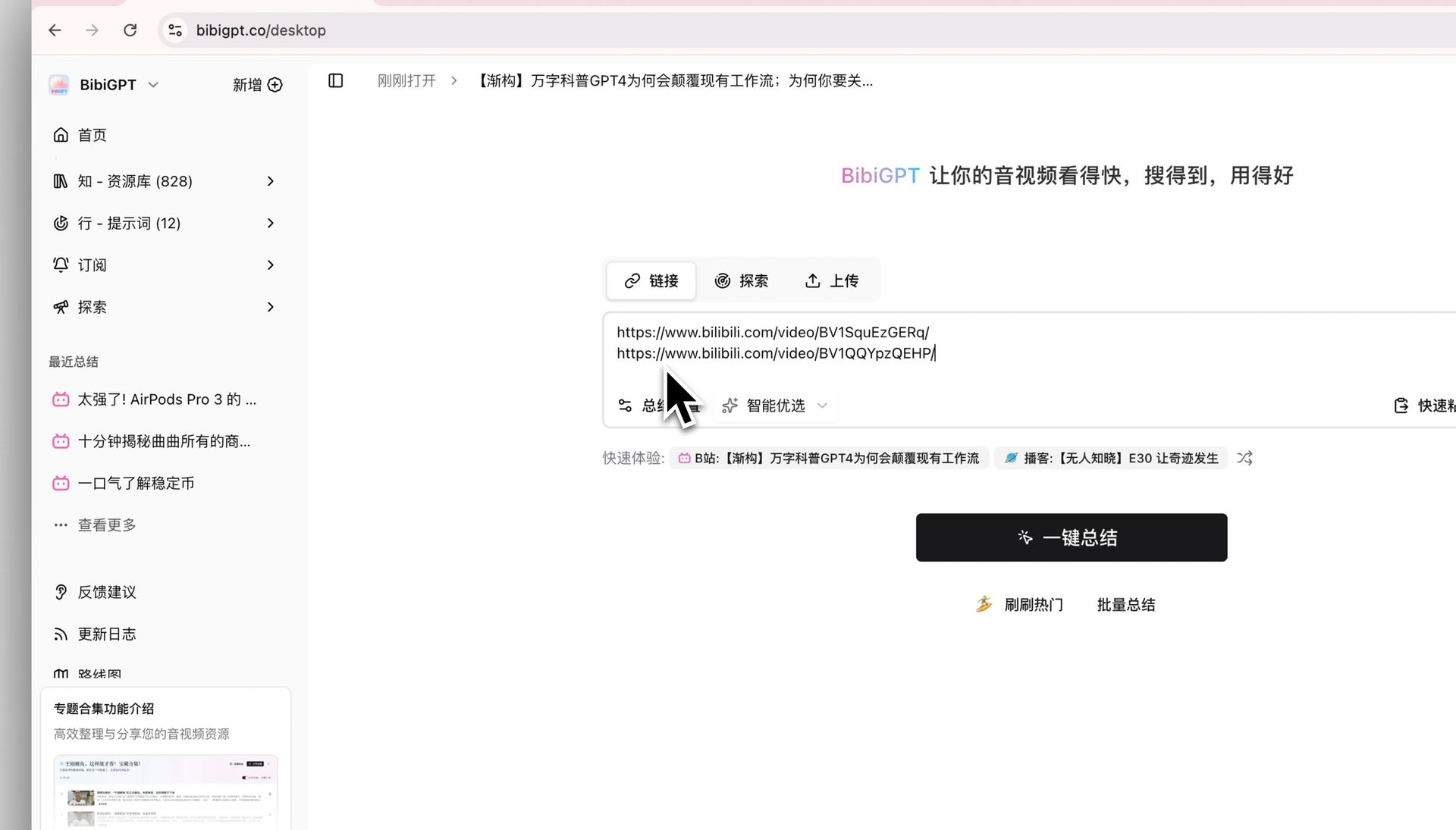
スクリーンショット:BibiGPT · バッチ要約機能
まず単一リンクを貼り、「リンクを入れる → 読める要点が出る」流れを体験してから、コレクションへ拡張することもできます。下のインタラクティブなデモが直接見せてくれます:
どんな動画も数秒で要約
サンプルを選ぶと AI 要約が表示——結論ひとこと、要点リスト、ジャンプできるタイムスタンプ。
ひとこと: Karpathy が GPT 風の言語モデルをコードでゼロから構築。小さな文字レベルモデルから完全な Transformer まで、各パーツを丁寧に解説。
要点
- まず bigram モデル、次に自己注意を加えてトークン同士を"対話"させる
- Transformer ブロック = マルチヘッド注意 + 順伝播 + 残差接続 + 層正規化
- 学習は「次のトークン予測」だけ。あとは規模とデータ次第
- nanoGPT の背後の構造を拡大したものが ChatGPT
ジャンプ
- 00:07 なぜゼロから作るのか
- 08:23 自己注意を直感的に
- 1:00:00 Transformer ブロックの組み立て
- 1:35:00 nanoGPT から ChatGPT へ
デモ:BibiGPT 動画要約機能
実用ルール: 1 本なら直接問う。1 つのテーマが複数の動画に散らばるなら、コレクションにまとめ、全体へ一度に問う。
6. 1 つの問いを構造化された知識に変える
単一の答えはその場で役立ちます。けれど動画から最も多くを得る人は「答えが手に入った」で止まりません——一回ごとのセッションを再利用できる何かに変えます。Q&A の連なりはノートになり、ノートはアウトラインになり、アウトラインはひと目で読める思考マップになります。
流れはこうです:
- 質問し、出典付きの答えを集める。
- タイムスタンプを残し、すべての主張を検証可能に保つ。
- 答えを構造化されたアウトラインや思考マップへ整形する。
- コレクションに保存し、次の人——あるいは未来のあなた——が空白のシークバーではなく、知識から始められるようにする。
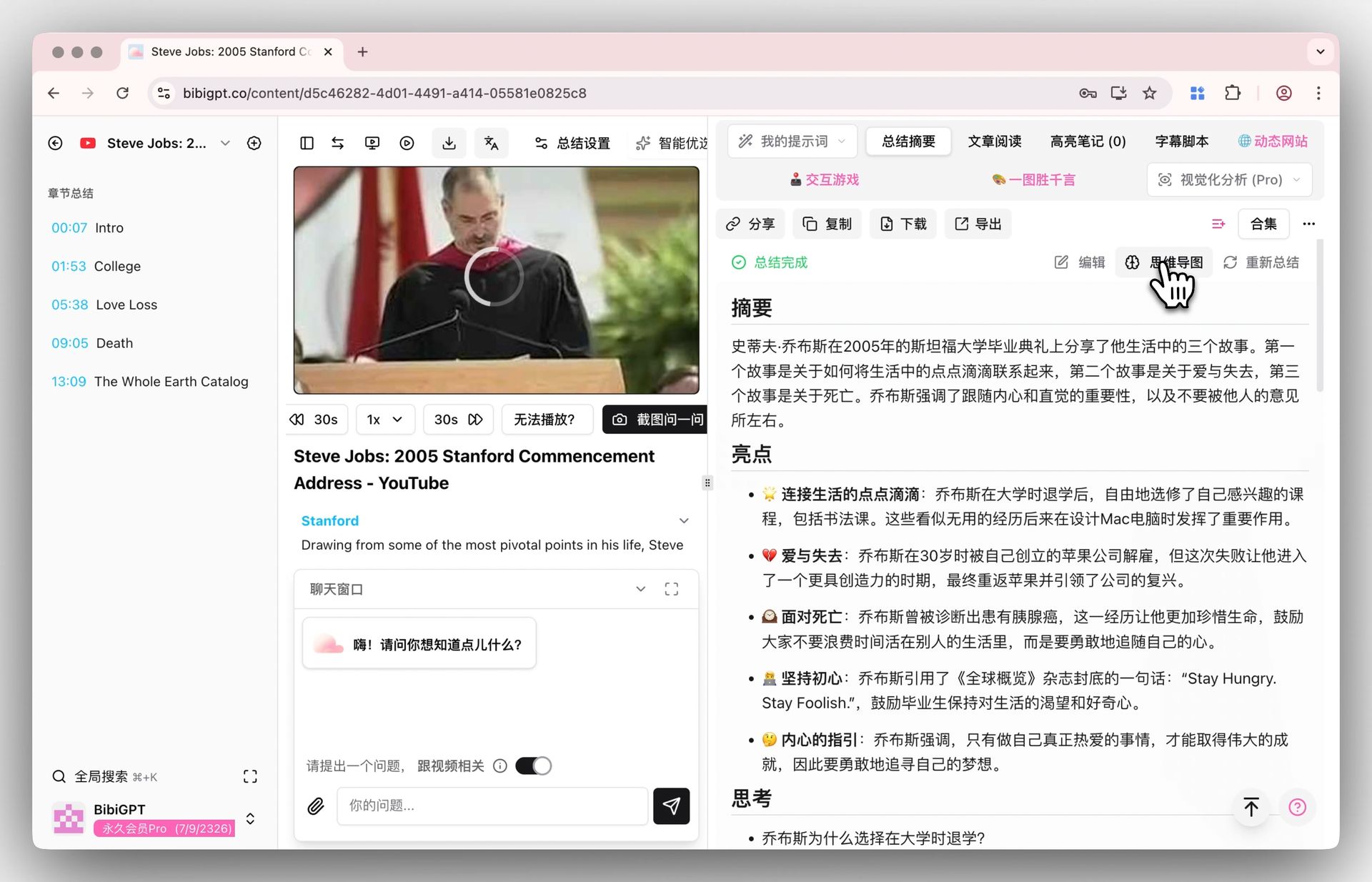
スクリーンショット:BibiGPT · 思考マップ入口
これが動画との対話の静かな超能力です。見る時間を省くだけでなく、もともと持っていなかった構造化された成果物を残してくれます。
7. つなげる:今日から回せるワークフロー
「長すぎて見たくない、でも重要すぎて飛ばせない」あらゆる動画に効く、完結したループがこれです:
- リンクを BibiGPT に貼り、タイムスタンプ付きで読める要約を作る。
- 具体的な質問をふつうの言葉で投げる。
- 答えを読み、タイムスタンプで出典を確認する。
- 追問してさらに深掘る——対話は積み上がる。
- テーマごとに複数の動画をコレクションにまとめ、全体へ問う。
- 最良の答えを思考マップやノートに整形して保存する。
初めてなら、最も穏やかな入口は先に要約することです——BibiGPT で YouTube 動画を要約する方法を参照。慣れたら、AI を使って動画から学ぶ方法が「答えを得る」から「本当に学ぶ」へ進む道を示します。BibiGPT は 30 以上のプラットフォームに対応し、100 万人以上のユーザーに使われ、累計 500 万回以上の要約を支えてきたので、何を貼っても、たいていそれと対話できます。
変化はシンプルですが全面的です。情報を探すために動画を見るのをやめ、動画に直接情報を求めるようになる。数時間の素材が、数分で済ませられる対話に変わります。
いますぐ試す
次に「長すぎて見たくない、でも重要すぎて飛ばせない」動画に出会ったら、シークバーをドラッグするのはやめて——リンクを貼り、質問を投げ、AI に出典の瞬間ごと答えを見つけさせましょう。
BibiGPT チーム