Qwen3-ASR-Flash 登場:より正確な音声認識は、動画の字幕と要約に何をもたらすのか(2026)
Qwen3-ASR-Flash 登場:より正確な音声認識は、動画の字幕と要約に何をもたらすのか(2026)
2026年6月、アリババは新しい音声認識モデル Qwen3-ASR-Flash を発表しました。注目すべきはベンチマークの数字ではなく、多言語・強いアクセント・さらには背景音楽つきの音声全体でも、音を誤った文字に変換する確率を非常に低い水準まで下げた点です。公開された数値では、歌詞の認識誤り率さえ8%を下回り、複数のシナリオでこれまでよく引用されてきた比較モデルを上回っています。
とても「技術的」な発表に聞こえます。しかし毎日オンライン講義を見て、ポッドキャストを掘り起こし、会議の録音を整理する人にとって、これは具体的な問いに答えてくれます。以前は誤字だらけで戻ってきたあの動画を、今度は一発で正しく文字起こしできるのか?
この記事ではスペック表もベンチマーク競争も扱いません。明らかにするのは3つだけ——なぜ文字起こしの正確さがAI動画要約の土台なのか、この進歩によってどんなコンテンツが「文字起こしできない」から「実用できる」に変わったのか、そしてそれを自分の動画や音声にどう活かすか、です。
100字回答:Qwen3-ASR-Flash のようなモデルが正確になって最も恩恵を受けるのは「音声認識」そのものではなく、その上に乗る AI要約・検索・翻訳 です。すべては音を正しい文字に変えることから始まるからです。この最初のステップが正確になれば、アクセントの強い講義、雑音のある会議、BGM入りのライブ動画も、ほぼ一発で使える文字になります。すぐ試すには、リンクを BibiGPT に貼り付ければ字幕と要約が手に入ります。
主張を鵜呑みにせず、下のサンプル動画を選んで「まず正確に文字起こし、それから要約」の流れをブラウザでそのまま確かめてください:
どんな動画も数秒で要約
サンプルを選ぶと AI 要約が表示——結論ひとこと、要点リスト、ジャンプできるタイムスタンプ。
ひとこと: Karpathy が GPT 風の言語モデルをコードでゼロから構築。小さな文字レベルモデルから完全な Transformer まで、各パーツを丁寧に解説。
要点
- まず bigram モデル、次に自己注意を加えてトークン同士を"対話"させる
- Transformer ブロック = マルチヘッド注意 + 順伝播 + 残差接続 + 層正規化
- 学習は「次のトークン予測」だけ。あとは規模とデータ次第
- nanoGPT の背後の構造を拡大したものが ChatGPT
ジャンプ
- 00:07 なぜゼロから作るのか
- 08:23 自己注意を直感的に
- 1:00:00 Transformer ブロックの組み立て
- 1:35:00 nanoGPT から ChatGPT へ
1. 今回の発表は何が新しいのか:2026年6月時点
まず事実を整理します。Qwen3-ASR-Flash はアリババが2026年6月に発表した音声認識(ASR、音声を文字に変換する技術)モデルで、強調されている能力は3点に集約されます。
- 多言語(中国語・英語ほか):中国語・英語、そして混在した発話でも安定して文字起こしでき、言語ごとにツールを切り替える必要がありません。
- ノイズとアクセントに強い:遠いマイク、アクセント、ライブの雑音といった「実世界」の録音により頑健です。
- 背景音楽でも文字起こしできる:これは従来最も難しいカテゴリでした。公開された数値では、歌1曲分の歌詞認識誤り率さえ8%を下回り、複数の比較シナリオでこれまでよく引用された文字起こしモデルを上回っています。
実践ルール: ASRモデルの発表を見るとき、「クリーンな録音の正確さ」だけに注目しないこと——そこはほぼどのモデルも悪くありません。本当の分かれ目は難しいコンテンツ、つまりアクセント・雑音・背景音楽です。Qwen3-ASR-Flash の見どころはまさにそこにあります。
なぜ一般ユーザーが気にすべきなのか。音声認識はAI動画ツールチェーン全体の最下層だからです。ここが正確になると、その上のすべてが恩恵を受けます。
2. なぜ文字起こしの正確さがAI要約の天井になるのか
多くの人はAI動画ツールの核心を「要約の出来栄え」だと思っています。実際の土台はもう一歩手前——まず音を正しい文字に変えることです。
AI要約・AI翻訳・AI追加質問は、本質的にすべて文字起こしされたテキストを「読んで」います。最初のステップで名前を聞き間違え、重要な用語を取り違え、肝心の一節を落とせば、後でどれだけ要約が美しく見えても、間違った内容の上に建っています。文字起こしの正確さは、その後すべての機能の天井です。
このページ上部のインタラクティブなデモで見たとおり、「まず正確に文字起こし、それから要約」は2つの分断した手順ではなく、ひとつの連続した流れです。
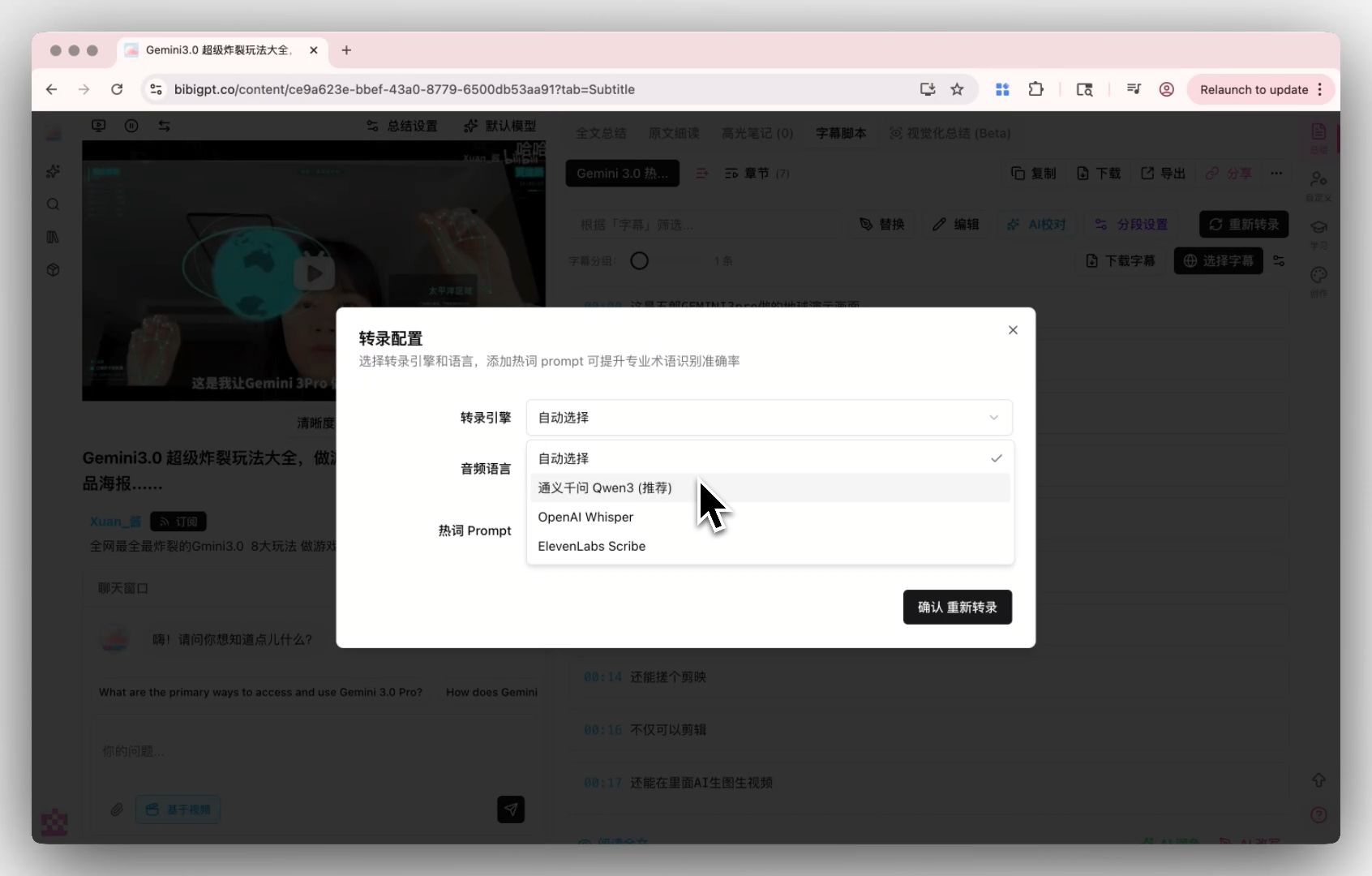
言い換えれば、Qwen3-ASR-Flash のようなモデルが最初のステップをより正確にすることは、後続のパイプライン全体の上限を一段引き上げるということです。だからこそ BibiGPT は文字起こしエンジンを核心的な能力として磨いてきました——設定で文字起こしエンジンを切り替え、コンテンツごとに最適なものを選べます。
下の文字起こしエンジン設定の画面で、この入口がどう見えるか確認してください。
スクリーンショット:BibiGPT 文字起こしエンジン設定
実践ルール: AI動画ツールを評価するなら、要約のレイアウトが綺麗かどうかから始めないこと——あなたの「聞き取りにくい」コンテンツをどれだけ正確に文字起こしできるかから始めましょう。それが土台です。
3. 以前は「文字起こしできなかった」3種類のコンテンツが、今は使える
より正確な音声認識の最大の受益者は、スタジオ品質のはっきりしたナレーションではありません——それはどれも問題なく文字起こしできます。差が出るのは実世界の難しいコンテンツで、今回の改善は下の3カテゴリにぴたりと当たります。
聞き取りにくい講義・大教室の録音
アクセントの強い教授、反響する教室、演壇から遠いマイク——留学生やオンライン受講者にとって最も悩ましい場面です。以前は誤字だらけでノートとして使い物になりませんでした。認識がより安定した今、90分の講義録音から概ね読めるテキストが得られ、AI要約と組み合わせれば、まず要点を見て、どの区間を聞き直すべきか判断できます。
下の動画は、実世界の場面での音声文字変換を分かりやすく示しています。
動画の出典:YouTube · 音声文字変換のデモ
雑音・アクセントのある会議や対談の録音
会議室の咳払い、紙をめくる音、エアコンの音、対談での口語的な被せ発話は、かつて認識を狂わせました。文字起こしがより頑健になり、こうした「臨場感の強い」録音も使えるテキストになり、後から「あの重要な結論を誰がどこで言ったか」を検索しやすくなります。
背景音楽つきのライブ動画・歌詞
これは従来最も難しいカテゴリでした——背景音楽があるだけで、多くのツールはその区間全体を文字化けさせました。Qwen3-ASR-Flash が特に強調するのは、まさに背景音楽つきの音声全体の認識で、歌詞の誤り率は8%未満です。つまり、BGM入りの講演、ライブVlog、さらにはボーカル入りの楽曲の一部も、正しく文字起こしされる可能性が高まります。
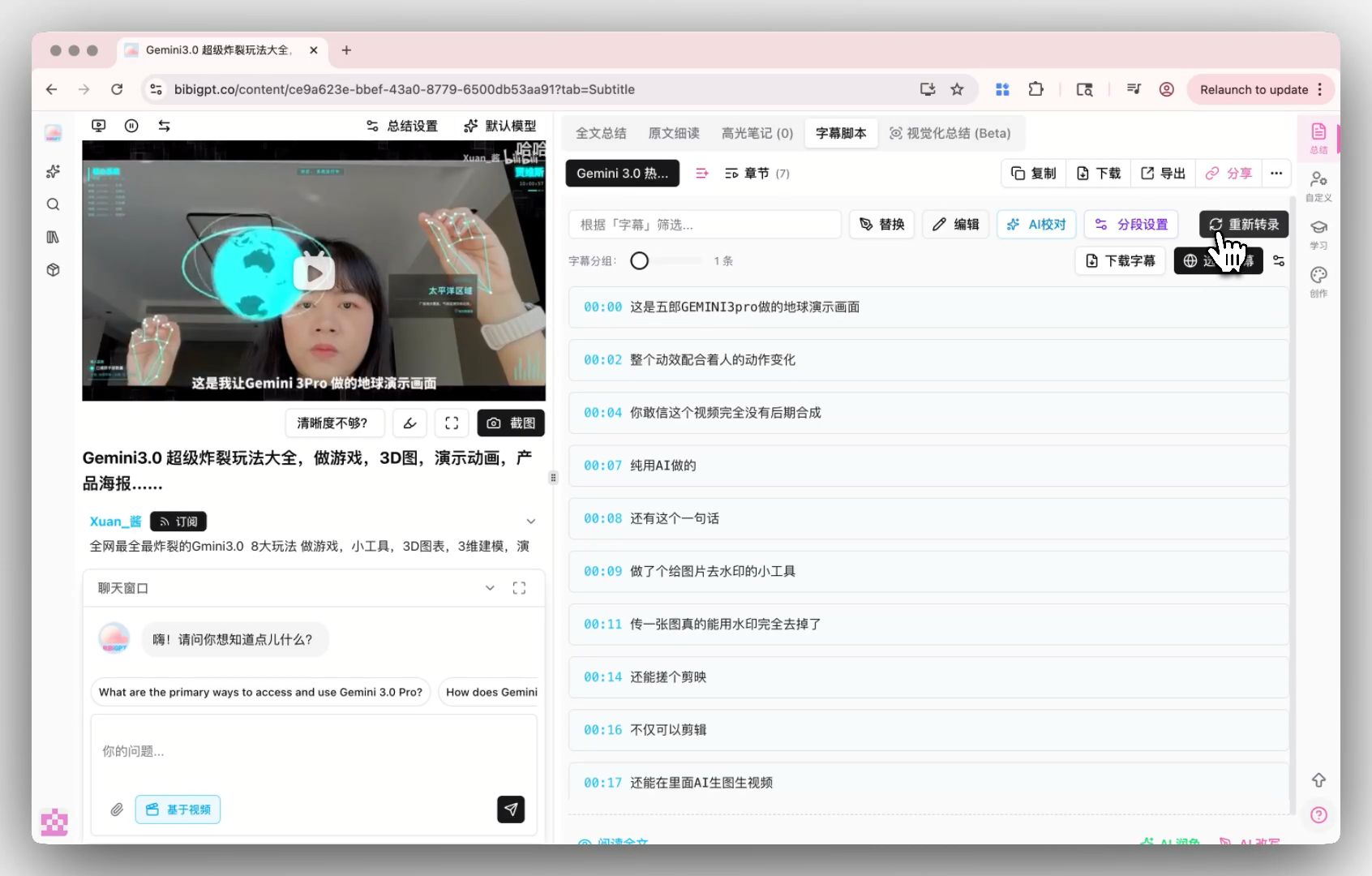
文字起こし後は、字幕の分割方法をカスタマイズして、スクリプトを整然と読みやすく保てます。下図の通りです。

スクリーンショット:BibiGPT スマート字幕分割設定
実践ルール: 「以前は文字化けして戻ってきた」難しいコンテンツが手元にあるなら、今もう一度試す価値があります——今年の認識力向上の最大の配当は、まさにそうしたコンテンツに落ちています。
関連記事:「字幕が正確になると何が変わるのか」をより体系的に理解したい方は より正確なAI字幕が意味するもの を、B站・YouTube・ポッドキャストなど複数プラットフォームを一つの入口で処理したい方は クロスプラットフォームAI動画要約ガイド をご覧ください。
4. 「より正確な文字起こし」を活かす:3ステップのワークフロー
モデルの進歩は、使える製品に落ちて初めて意味を持ちます。BibiGPT を例にすると、難しいコンテンツを使えるテキストと要約に変えるのは、たいてい3ステップです。
- リンクを貼るかファイルをアップロード:YouTube・B站・抖音・TikTok・小紅書・ポッドキャストなど30以上のプラットフォームからリンクを直接貼り付け、ローカルの音声/動画ファイルもアップロードできます。
- 自動文字起こし+要約:システムはまず音をタイムスタンプ付きの文字稿に変え、次に構造化された要約(TL;DR+箇条書きの要点)を生成します。聞き取りにくい箇所はタイムスタンプをタップすれば元動画に戻って確認できます。
- 必要に応じて翻訳/エクスポート:英語の講義はワンクリックで日本語字幕に翻訳でき、文字稿も要約も Markdown やプレーンテキストなどの形式でエクスポートしてノートアプリに保存できます。
コンテンツが英語で、対訳字幕の参照が欲しい場合は、下の翻訳デモで効果を先に確認できます。
字幕をあなたの言語へ
原文と訳文を一行ずつ対照、タイムスタンプつき。外国語の動画もすぐ理解。
| 00:07 | We're going to build GPT from scratch, together. | 一緒に GPT をゼロから作っていきます。 |
| 08:23 | Self-attention is the heart of the Transformer. | 自己注意は Transformer の心臓部です。 |
| 45:10 | Each token emits a query and a key. | 各トークンはクエリとキーを出します。 |
| 1:35:00 | At its core, this is the same model behind ChatGPT. | 本質的には、ChatGPT の背後にあるのと同じモデルです。 |
実践ルール: 難しいコンテンツの正しい扱い方は「まず文字起こし、タイムスタンプで照合、それから要約」であって、AIが一発で完璧であることを期待することではありません——元動画に戻って確認できることこそ、信頼できる要約の証です。
BibiGPT はこれまでに100万人を超えるユーザーに対し、30以上の主要プラットフォームで500万回以上のAI要約を生成してきました——まさに「音声と動画を素早く正確に、消費できるテキストに変える」ために磨かれてきました。
5. 展望とよくある質問(FAQ)
先を見据えると、今年の音声認識の進歩は3つの変化をもたらします。難しいコンテンツの文字起こしの壁が下がり続ける(アクセント・雑音・BGMはもう障害ではない)、混在言語の発話がますますシームレスになる(中英混じりの対談を2回に分けて処理する必要がなくなる)、そして**「文字起こし+要約+翻訳」が3つの分断したツールではなく、一つの連続した動作のように感じられていく**——です。
Q1:Qwen3-ASR-Flash を直接使えますか? A:一般ユーザーはモデルに直接つなぐ必要はありません。高品質な文字起こしを備えた製品を使い、リンクやファイルを入れるだけで、どのモデルが裏で動いているかを気にせず、この認識力向上の恩恵を受けられます。
Q2:背景音楽つきの動画は本当に正確に文字起こしできますか? A:1〜2年前より明らかに改善しています。純粋な音声が最も正確です。BGM入りのコンテンツも今はほぼ使えるテキストになりますが、極端に騒がしい場面ではまだ小さな誤りが残ることがあるため、重要な区間はタイムスタンプで照合してください。
Q3:アクセントの強い英語講義は文字起こしできますか? A:できます。アクセントへの頑健性は今年の重点の一つです。文字起こし後にワンクリックで日本語の要約も得られ、全編英語の授業についていけない学生に特に役立ちます。
Q4:文字起こししたテキストは検索・エクスポートできますか? A:できます。文字稿はタイムスタンプ付きで全文検索でき、要約も文字稿も Markdown やプレーンテキストなどの形式でエクスポートできます。
Q5:もう一度試す価値が最も高いコンテンツは? A:「以前は文字化けして戻ってきた」難しいコンテンツ——遠いマイクの講義、アクセントのある対談、BGM入りのライブ動画——が、今回の改善の恩恵を最も受けます。
音声認識のこの進歩に乗って、聞き取りにくい講義・ポッドキャスト・BGM入りの動画を、一発でクリーンで読みやすく要約できるテキストに変えたいですか?リンクを BibiGPT のスマート文字起こしと要約 に貼り付け、結果を見てから決めてください。
BibiGPT チーム