Sora Alternatives 2026: 5+ AI Video Generation and Summary Tools to Switch To (Updated)
OpenAI sunset the Sora app and API in March 2026. This guide compares 5+ Sora alternatives across generation tools (Veo, Kling, Runway, Pika, MiniMax) and summary tools (BibiGPT), so you can pick by use case.
Sora Alternatives 2026: 5+ AI Video Generation and Summary Tools to Switch To (Updated)
Contents
- Which AI Video Tool Should You Pick After Sora?
- Generation-Side Sora Alternatives: Veo / Kling / Runway / Pika / MiniMax
- Understanding-Side Alternatives: BibiGPT and Other AI Video Summary Tools
- Picking by Use Case
- Why BibiGPT Holds a Unique Slot Post-Sora
- FAQ
- Wrap-up
Which AI Video Tool Should You Pick After Sora?
Quick answer: OpenAI officially sunsetted the Sora app and API in late March 2026, leaving a flagship-sized hole in the AI video generation space. The real Sora alternative depends on what you actually used Sora for: if it was creating new video, go with Google Veo 3.1, Kuaishou Kling 3.0, Runway Gen-4, Pika 2.0, or MiniMax Hailuo 02. If it was "quickly make sense of a video", the better fit is actually an AI video summary tool like BibiGPT, not a generator. This guide covers both tracks.
Try pasting your video link
Supports YouTube, Bilibili, TikTok, Xiaohongshu and 30+ platforms
If you've been using Sora mostly to "digest a video fast," the product you really want isn't a generator — it's an AI video summary like BibiGPT, already trusted by over 1 million users with 5M+ AI summaries generated. Pick by use case below.
Generation-Side Sora Alternatives: Veo / Kling / Runway / Pika / MiniMax
Quick answer: If your goal is "turn text into a video clip," the 2026 Sora alternatives are Google Veo 3.1, Kuaishou Kling 3.0, Runway Gen-4, Pika 2.0, and MiniMax Hailuo 02. The top three have moved into the "synchronized audio and video in one pass" era.
Per Zapier's 2026 AI video generator roundup, the leading generation-side Sora alternatives stack up like this:
| Tool | Best at | Pricing | Key breakthrough |
|---|---|---|---|
| Google Veo 3.1 | Long-take narrative + synced audio | Subscription | Joint dialogue + SFX + ambient generation |
| Kuaishou Kling 3.0 | Vertical shorts + physics sync | Credit-based | Lip, motion, and physics alignment |
| Runway Gen-4 | Pro post-production workflow | Subscription | Motion Brush, fine-grained control |
| Pika 2.0 | Fast ideation + social shorts | Subscription | Pikaffects effects system |
| MiniMax Hailuo 02 | Chinese-native + emotional expression | Credit-based | Strong semantic grasp, China platform fit |
Pick guide:
- Ads, cinematic clips → Veo 3.1 or Runway Gen-4.
- TikTok / Shorts → Kling 3.0 or Pika 2.0.
- Chinese creators, Chinese prompts → MiniMax Hailuo 02.
- Want to see how far synchronized generation has come → read Veo 3.1 + Kling 3.0 Synchronized Generation: Why It Makes BibiGPT More Essential.
Heads-up: These are all generation tools (text-to-video). If your real need is "make sense of video that already exists," jump to the next section.
Understanding-Side Alternatives: BibiGPT and Other AI Video Summary Tools
Quick answer: A lot of Sora users didn't want to "create a video." They wanted "AI help with existing video." If your workflow is "paste a link, get a summary + transcript + timestamps + chapters," Sora was never the right tool — and its post-sunset successor for this job is a summary product like BibiGPT.
| Tool | Input | Output | Best for |
|---|---|---|---|
| BibiGPT | 30+ platform links: YouTube, Bilibili, TikTok, podcast, etc. | Structured summary / transcript / mindmap / article | Digesting existing video fast, remixing |
| NotebookLM | Docs, audio, PDFs, links | Q&A chat, podcast generation | Research notes, lit reviews |
| NoteGPT | YouTube, PDFs | Summary, notes | Study notes |
| Snipcast / Snipd | Podcast links | Auto summary, clips | Podcast consumption |
Why count BibiGPT as a "Sora alternative"?
Look at the actual demand distribution in "AI video." Creators are a minority. Most people touch video like this:
- Watching a YouTube tutorial → want the takeaways fast
- Scrolling TikTok for tips → want to save the gist
- Listening to a podcast → want a text version
- Getting a video link forwarded → want to judge whether to watch
Sora solved none of those — it makes video, it doesn't read video. BibiGPT video summary solves all four by paste-and-go.
See BibiGPT's AI Summary in Action
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeOne flow across platforms
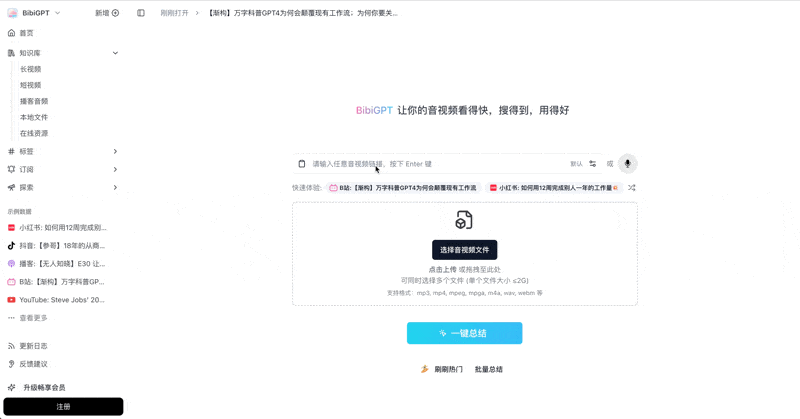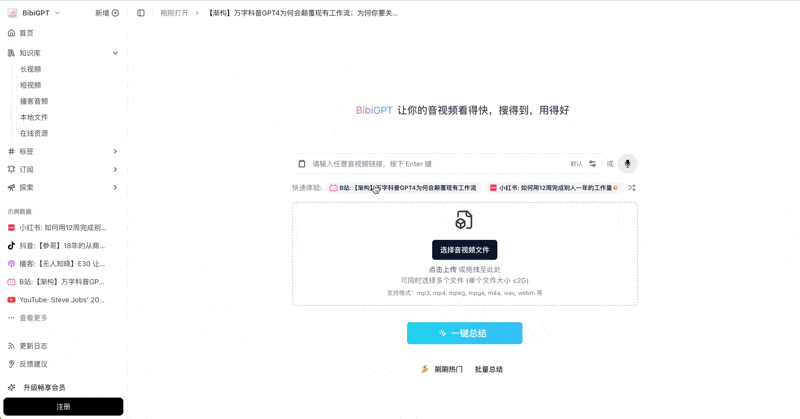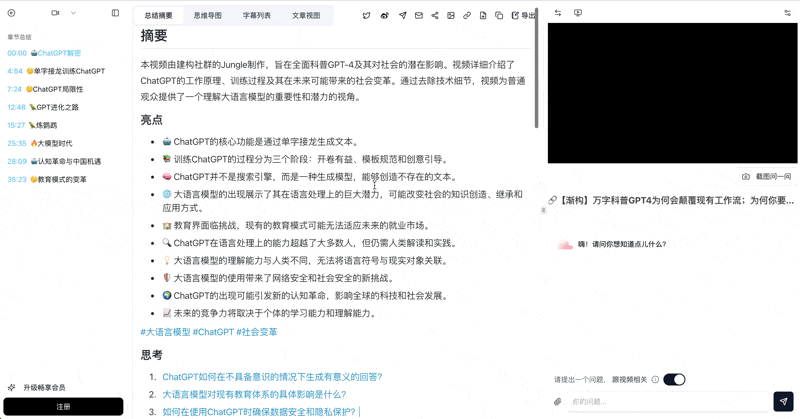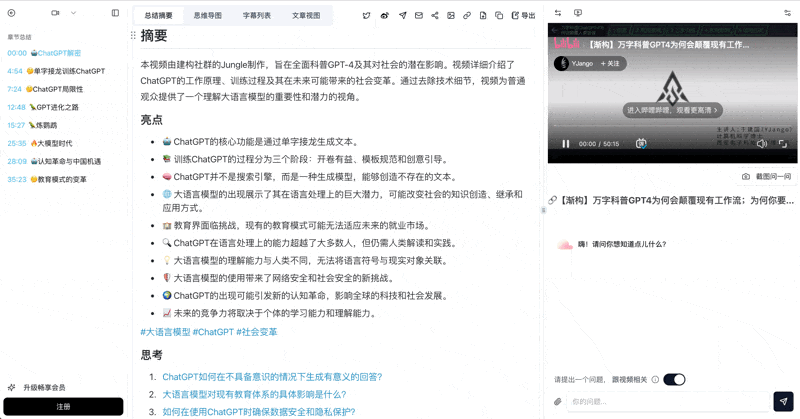
BibiGPT's moat in this niche is 30+ platform support. No matter where the link is from, the pipeline is the same:
 AI video to article UI
AI video to article UI
Picking by Use Case
Quick answer: Split your real need into three buckets — create new video (generation), digest existing video (understanding), or both (combined flow) — and pick the matching row.
| Use case | Best pick | Alternatives |
|---|---|---|
| Making ad / short original video | Veo 3.1 / Kling 3.0 | Pika 2.0, Runway Gen-4 |
| Get a 2-minute gist of a video | BibiGPT | NotebookLM |
| Turn a long video into a polished article | BibiGPT AI video to article | Manual editing |
| Podcast → timestamped transcript | BibiGPT AI podcast to article | Snipcast, Otter |
| Build a personal knowledge base | BibiGPT + Notion sync | NotebookLM |
| Generate video + analyze outcome | Veo/Kling for generation + BibiGPT for retrospective | Fully manual |
Best combo: generation + understanding in a loop
The most productive AI-video workflow in 2026 uses both:
- Digest reference videos with BibiGPT for inspiration.
- Distill the points, then generate a new clip with Veo / Kling.
- Run the new clip back through BibiGPT for structure check, transcript export, article rewrite.
Every step is AI; you only make judgment calls. More operating detail: Best AI live audio transcription tools 2026.
Why BibiGPT Holds a Unique Slot Post-Sora
Quick answer: Sora's exit opens a mindshare gap — partly absorbed by Veo/Kling on the generation side, partly by AI video summary tools on the understanding side. BibiGPT's differentiation there: Chinese-native experience, 30+ platform reach, full content remix pipeline, and deep integration with Notion / Obsidian / other knowledge tools.
1. Multilingual, strongest on Chinese platforms
BibiGPT was designed Chinese-first from day one. Bilibili, Xiaohongshu, Douyin, Xiaoyuzhou ingestion isn't a bolt-on — it's foundational. Most English Sora alternatives barely touch those platforms, which is a product-experience gap for users in China and across Asia.
2. Full subtitle chain in multiple languages
Subtitle download, subtitle translation, subtitle burn-in — the full post-processing chain lives inside BibiGPT. Generation-side Sora alternatives don't touch any of this, yet it's one of the highest-frequency needs for real users.
3. Creator-facing remix pipeline
Video → Xiaohongshu post, video → social image — the middleware Sora never filled. BibiGPT fills it deepest.
4. Knowledge tool integration
Notion, Obsidian, Readwise, Lark — after watching a video, moving the content into your knowledge system used to be mostly manual. BibiGPT closes that loop.
FAQ
Q1: Did Sora really shut down completely? A: Yes. OpenAI announced in late March 2026 it was sunsetting the Sora app and API to focus on other priorities (details in Zapier's latest roundup). Existing subscriber access is being phased out.
Q2: How does Veo 3.1 compare to Sora? A: On image quality, clip length, and synchronized audio, Veo 3.1 has already surpassed Sora's ceiling — especially "dialogue + SFX + ambient generated in one inference." Full comparison: Veo 3.1 + Kling 3.0 Synchronized Generation: Why It Makes BibiGPT More Essential.
Q3: Can BibiGPT process Sora-generated videos? A: Yes. Upload the clip to YouTube / Bilibili / TikTok and paste the link, or upload the MP4 directly. BibiGPT extracts frames and dialogue and produces a structured summary.
Q4: I just want notes from a YouTube video — NotebookLM or BibiGPT? A: NotebookLM leans toward multi-document chat; BibiGPT leans toward "paste a link → get summary + transcript + chapters" in one go. If you process video links more than PDFs, BibiGPT is the smoother path. See NotebookLM vs Gemini Notebooks comparison.
Q5: Any free options among Sora alternatives? A: Generation tools are mostly subscription or credit-based. On the understanding side, both BibiGPT and NotebookLM offer free tiers. BibiGPT's free tier covers basic AI summary; Pro subscription unlocks long videos, article rewriting, batch processing, etc.
Wrap-up
Sora's shutdown isn't the end of AI video — it's the formal moment the space split into "generation" and "understanding." Picking the right alternative is really about recognizing which bucket you're in:
- Making new video → Veo 3.1 / Kling 3.0 / Runway / Pika / MiniMax.
- Digesting existing video → paste a link into BibiGPT.
- Both → BibiGPT as the understanding layer, a generator as the creation layer.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://aitodo.co
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team