The Heavy Podcast Listener's Second Brain: Turning 20 Hours of Weekly Audio Into a Searchable Knowledge Base (Deep Work Workflow, 2026-05)
The Heavy Podcast Listener’s Second Brain: Turning 20 Hours of Weekly Audio Into a Searchable Knowledge Base (Deep Work Workflow, 2026-05)
TL;DR: People listening to 20+ hours of long-form podcasts weekly can’t possibly remember details from memory — you need a second brain. Fastest path: paste podcast link into BibiGPT → auto-generated deep summary + AI highlights + raw transcript → one-click export to Obsidian/Notion → use Deep Search to locate any sentence by keyword. One week to build a searchable podcast second brain.
If you subscribe to Lex Fridman / Tim Ferriss / Huberman Lab / The Knowledge Project / The All-In Podcast — long-form, multi-hour conversation podcasts — you already know the cost: 2-4 hours per episode, 5-10 episodes per week, huge time investment, and yet you remember less than 5% of the detail.
It’s not a memory problem. Audio is a linear medium with no index, no structure, no searchability. Two weeks later you’ve forgotten exactly what Jensen Huang said about CUDA’s origins on that Lex Fridman episode.
This article is a PKM methodology for the heavy long-form podcast listener. Not for video researchers, students, or marketers — for people who treat podcast listening as their primary cognitive input channel. Core question: how do you turn 20 hours of weekly audio into a searchable second brain?
Deep Work View: Why Podcast PKM Is Fundamentally Different from Video PKM
Cal Newport’s Deep Work makes the point: the core of deep learning isn’t “how much you consumed” but “how much you sedimented”. Video PKM and podcast PKM workflows differ at the root:
| Dimension | Video PKM | Podcast PKM |
|---|---|---|
| Consumption context | At a desk, sitting, focused | Commute, exercise, chores, fragmented time |
| Episode length | Mostly 5-30 min | Mostly 60-240 min |
| Content density | Medium (visual redundancy) | High (pure speech) |
| Note timing | Can pause and note | Hands busy — recall later is hard |
| Retrieval need | Find a frame / segment | Find which sentence from which episode |
The core tension of podcast PKM: can’t take notes while listening, forget after listening. Video lets you pause and screenshot; podcasts on a metro pole leave you no hand free. That’s why most people subscribe to a pile of podcasts but sediment exactly zero.
The Deep Work answer isn’t “listen more carefully” — it’s “sediment within 5 minutes of finishing” — and that 5 minutes must be automated, or commute-fatigue and work-interruptions will eat it.
3-Layer Second Brain Structure (for Long-Form Podcasts)
Layer 1: Verbatim Layer
Purpose: When you later need to search “which episode did Jensen Huang talk about CUDA’s origins?”, you must be able to find the original sentence.
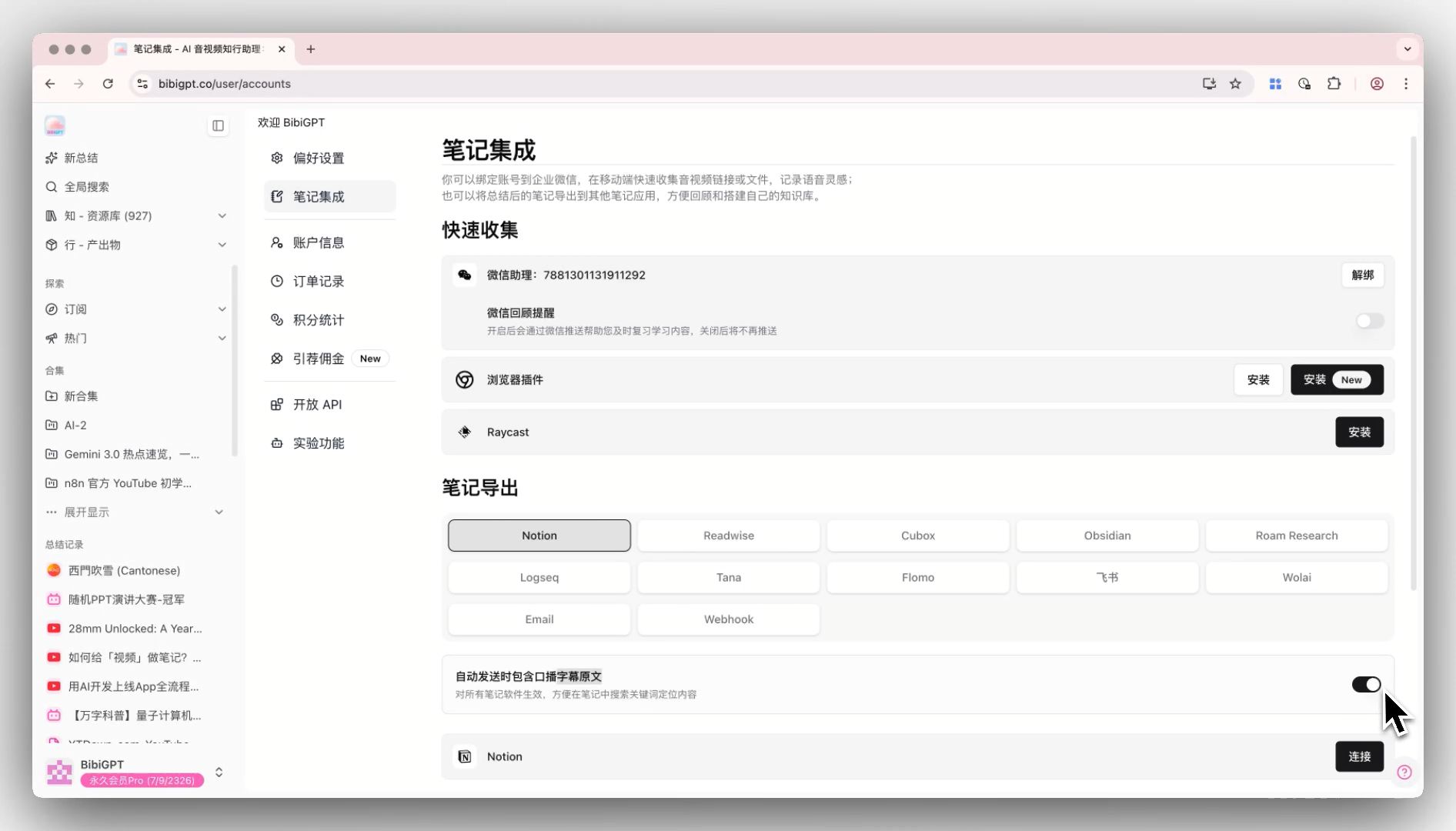
How: Every podcast episode’s full transcript must land in your notes. BibiGPT’s Include Original Subtitles in Note Export feature is designed for this layer — toggle the global switch once, and every export automatically bundles the full transcript.
Why the verbatim layer matters: Even the best AI summary loses information. You’ll forget the exact phrasing, but when searching you can only use keywords — the transcript is the safety net.
Layer 2: Highlight Layer
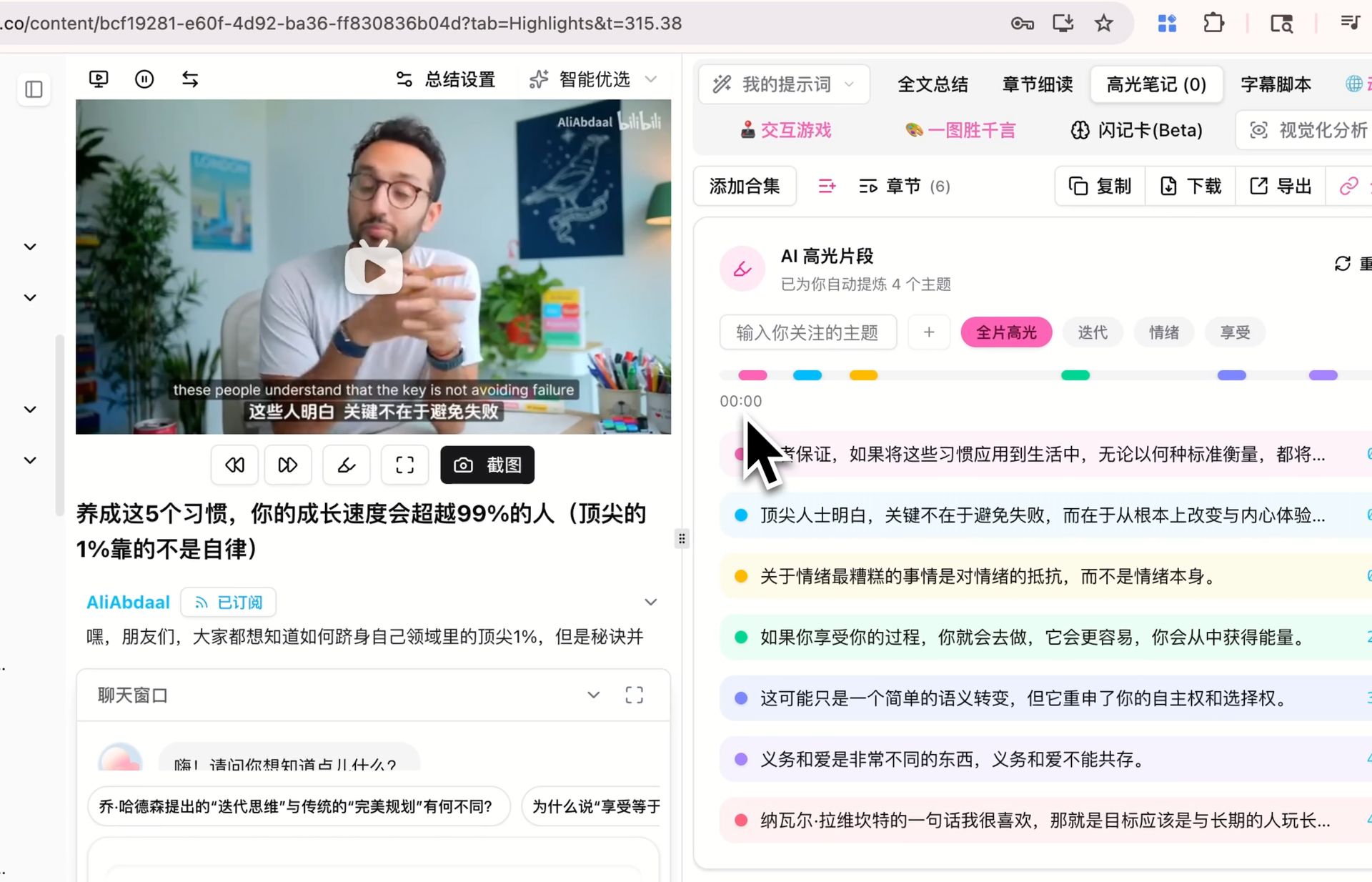
Purpose: The core arguments, money quotes, key insights buried in a long podcast — these are what you’ll most want to find later.
How: Use BibiGPT’s AI Highlight Note to auto-extract and topic-cluster. The AI itself identifies “core guest arguments,” “money quotes,” “counterintuitive claims,” then groups them by theme.
Key design philosophy: The highlight layer isn’t an AI summary — it’s a timestamped, jump-back-to-audio set of high points. When you later read “Jensen said X” in your notes, you can one-click back to that exact timestamp in the audio — this is the core differentiator of audio PKM versus text PKM.
Layer 3: Retrieval Layer
Purpose: The whole second brain must be searchable.
How: BibiGPT’s Deep Search doesn’t just search titles and summaries — it searches the full transcript of every episode. Even if the AI summary never mentioned “vector database,” but the guest said it once at the 47-minute mark, Deep Search still finds that episode at that timestamp.
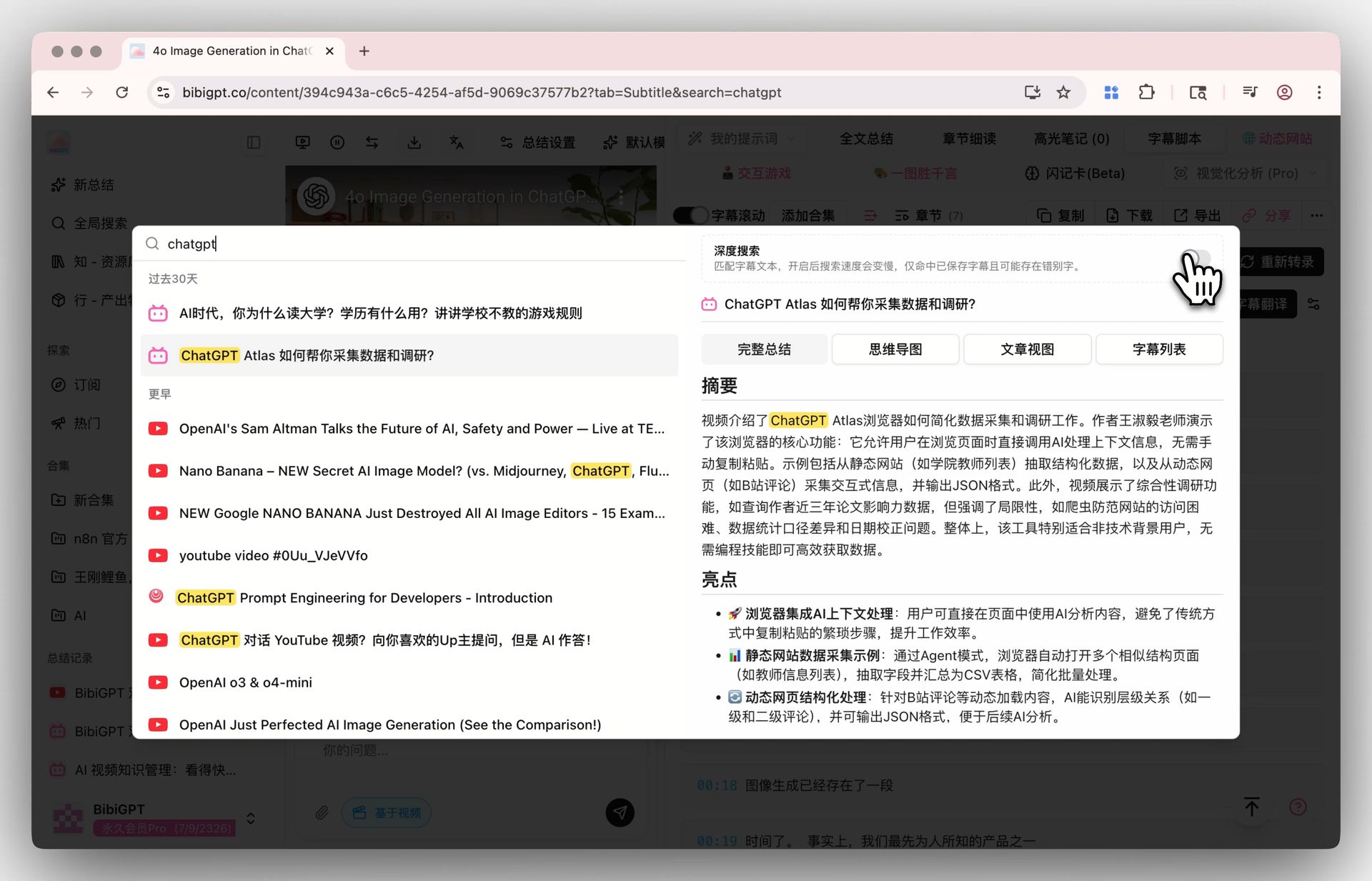
Pair with Obsidian / Notion: If you’re already on Obsidian, BibiGPT’s notes export directly into your Vault. Then Dataview / Search inside Obsidian lets you do richer correlation — “list all podcast notes mentioning CUDA,” for instance.
Weekly Workflow: 30 Minutes a Day to Manage 20 Hours of Audio
You don’t need to spend 3 hours a day on notes — that’s not sustainable. Deep Work’s core is 30 focused minutes daily, doing one thing: turning yesterday’s podcasts into searchable notes.
Monday-Friday (30 min/day)
Morning commute (60 min) — listen to one 60-minute podcast (no notes, just listening).
Last 10 minutes before reaching the office:
- Paste the link into BibiGPT, let it run (1-3 min for results);
- While waiting, type 1-2 sentences on your phone: “First reaction after listening to this episode” — this metadata is invaluable months later when you revisit notes;
- When BibiGPT’s done, glance at the AI Highlights and confirm the extracted core arguments match what you remember — if not, add a brief annotation.
Evening (20 min):
- One-click export to Obsidian (with transcript-included toggle on + auto-sync set, this step is zero-effort);
- In Obsidian, tag the note with 2-3 labels (e.g.,
#AI #CUDA #Lex-Fridman); - If something’s worth deep-diving, write a one-line TODO at the top: “later, write a standalone post about X”.
Weekend (1 hour)
Sunday weekly review:
- Scan all 5 podcast highlight notes from this week, identify 3 recurring themes;
- Use BibiGPT’s Collection Summary to put these 5 into one weekly collection — let AI summarize the week’s cognitive arc across episodes;
- Write the “weekly cognitive arc” as a paragraph in your Obsidian weekly review.
The key to this workflow is sustainability, not complexity. One week = 5 podcast notes + 1 weekly collection. One month = 20+ episodes in your searchable knowledge base. One year = 240+ episodes in your second brain.
Cross-Podcast Inquiry: Start with Collection AI Chat
The peak of PKM is cross-content conversation — after listening to 50 AI-themed podcasts, asking “what consensus and disagreement do these 50 guests show on AGI timelines?”
BibiGPT’s Collections AI Chat lets you query the whole collection directly. Examples:
- “Across these 30 Lex Fridman episodes, which papers got cited most often by guests?”
- “In the All-In Podcast collection, what root causes do hosts most often cite when discussing failed startups?”
- “In the past year of Huberman Lab on sleep, what’s still an open scientific debate?”
The AI aggregates across episodes. This is impossible from single-episode listening — no human mind can hold the detail of 30 episodes simultaneously, but the AI can.
Turn Podcasts into Podcasts: Bidirectional Sedimentation
Sometimes after listening you think “this argument is worth re-narrating to others” — BibiGPT’s Xiaoyuzhou Podcast Generation auto-generates a two-host conversation audio from any video content, turning your output back into audio form.
This is especially useful for content creators: listen to others’ podcasts → sediment insights → regenerate as your own podcast → close the content flywheel.
BibiGPT Is Built to Make “Content Consumption Speed Match Production Speed”
The pain of long-form content is obvious: production speed fast, consumption speed slow, sedimentation speed slower still. Thousands of new podcasts ship every week — no human can listen to them all, let alone sediment them.
BibiGPT’s design philosophy: make “listen to podcast → sediment into knowledge base” a seconds-level experience end-to-end.
- 30+ platforms: Apple Podcasts, Spotify, YouTube podcasts, Pocket Casts, Xiaoyuzhou, etc. — all paste-and-go;
- Native multilingual: EN/ZH/JA/KO AI summaries — listen to English podcasts, get Chinese notes;
- Batch + collections: paste 10 podcast links for parallel processing, collection-level AI conversation;
- Export integration: Notion, Obsidian, Cubox, local folder auto-sync;
- Trusted by over 1 million users, with over 5 million AI summaries generated.
FAQ
Q1: I’m used to listening without taking notes — isn’t this workflow exhausting?
A: Opposite — the core of this workflow is “take no notes while listening”. Listening is the input; the notes are an artifact that pops out 5 minutes after you finish. If you can spend 5 minutes scanning AI summaries + adding 2 tags within 30 minutes of finishing, you’re done.
Q2: How good is BibiGPT’s Chinese-language summary of English podcasts?
A: Not machine translation — AI rewrites in native Chinese based on the source. For fast-paced English long podcasts like Lex Fridman / Tim Ferriss, the Chinese summaries are high quality (accurate chapter splits, core arguments captured). For AI engineers/researchers, this saves at least 60% of time vs. reading English transcripts directly.
Q3: Apple Podcasts, Spotify, Xiaoyuzhou — all supported?
A: Yes. BibiGPT supports 30+ mainstream audio/video platforms — the major podcast platforms are covered. Apple Podcasts, Spotify, YouTube podcasts, Xiaoyuzhou, Pocket Casts, and most Chinese podcast platforms work.
Q4: I’m already using Notion for PKM — can BibiGPT integrate?
A: Absolutely. BibiGPT notes one-click export to Notion (set the sync path once, then auto-archive). It preserves the three-layer structure: AI summary, AI highlight, raw transcript. Notion’s Database view makes “guest / topic / date” multi-axis filtering simple.
Q5: How well does BibiGPT handle bilingual podcasts (Chinese/English mixed)?
A: This is BibiGPT’s strong suit. Even when guests mix Chinese and English freely, BibiGPT’s transcription and summary handle cross-language content — much better than single-language transcription tools.
Closing
A second brain isn’t “remember everything” — it’s “find what you want, when you want it”. The biggest obstacle to podcast PKM is audio’s non-indexability. BibiGPT turns audio into a three-layer searchable structure (raw + highlight + summary) precisely to break that barrier.
The Deep Work workflow’s core isn’t spending more time on PKM — it’s doing 3 right things 30 minutes a day: paste the link after listening, scan AI highlights, add 2 tags. One weekly collection per week. 240+ episodes in your second brain per year.
Want to try it? Paste a podcast you listened to recently into BibiGPT, see if the AI Highlights match your core takeaways.
—— BibiGPT Team