播客重度听众的第二大脑:把每周 20 小时音频沉淀成可检索知识库(Deep Work 工作流,2026-05)
播客重度听众的第二大脑:把每周 20 小时音频沉淀成可检索知识库(Deep Work 工作流,2026-05)
80 字直答:每周听 20+ 小时长格式播客的人,靠人脑记不住任何细节,必须建第二大脑。最快路径:粘贴播客链接到 BibiGPT → 自动生成深度总结 + AI 高光笔记 + 字幕原文 → 一键导出到 Obsidian/Notion → 用深度搜索按关键词直接定位某句话出自哪期。一周构建一个可检索的播客第二大脑。
如果你订阅了 Lex Fridman / Tim Ferriss / 罗辑思维 / 黑马公社 / 小宇宙上的「张小珺商业访谈录」「忽左忽右」这类长格式播客——你已经知道这件事的代价:每期 2-4 小时,每周 5-10 期,时间投入大,但记得住的内容不到 5%。
不是你记忆力差。是音频是一种线性媒介,没有索引、没有结构、没有可搜索性。听完两周前那期就忘了「Jensen Huang 在 Lex Fridman 那期讲 CUDA 起源时具体说了什么」。
这篇文章是给「长格式播客重度听众」的 PKM 方法论。不是给视频研究员、不是给学生、不是给营销人——是给那些把「听播客」作为认知输入主通道的人。核心问题:怎么把每周 20 小时音频,沉淀成可检索的第二大脑?
Deep Work 视角:播客 PKM 和视频 PKM 的本质区别
Cal Newport 在《Deep Work》里讲过:深度学习的核心不是「听了多少」,是「沉淀了多少」。视频和播客两种媒介的 PKM 工作流有根本差异:
| 维度 | 视频 PKM | 播客 PKM |
|---|---|---|
| 消费场景 | 桌前、坐着、专注 | 通勤、运动、家务、碎片时间 |
| 单期时长 | 5-30 分钟为主 | 60-240 分钟为主 |
| 内容密度 | 中(含画面冗余) | 高(纯口播+对谈) |
| 笔记时机 | 看的时候可暂停记 | 听的时候手不空,事后回忆很难 |
| 检索需求 | 找某个画面/段落 | 找某句话出自某期 |
播客 PKM 的核心矛盾是:听的时候没法记,听完就忘。视频可以随时暂停截屏做笔记,播客通勤路上一只手挂在地铁拉环上根本没法记。这就是为什么大多数人订阅一堆播客但实际沉淀为零。
Deep Work 工作流的解法不是「听的时候认真」,而是「听完之后 5 分钟内把它沉淀好」——这个 5 分钟必须自动化,否则会被通勤后的疲倦/工作干扰打断。
第二大脑的 3 层结构(针对长格式播客)
第 1 层:原文层(Verbatim Layer)
作用: 你以后想搜「Jensen Huang 在哪期讲过 CUDA 起源」时,必须能搜到原句。
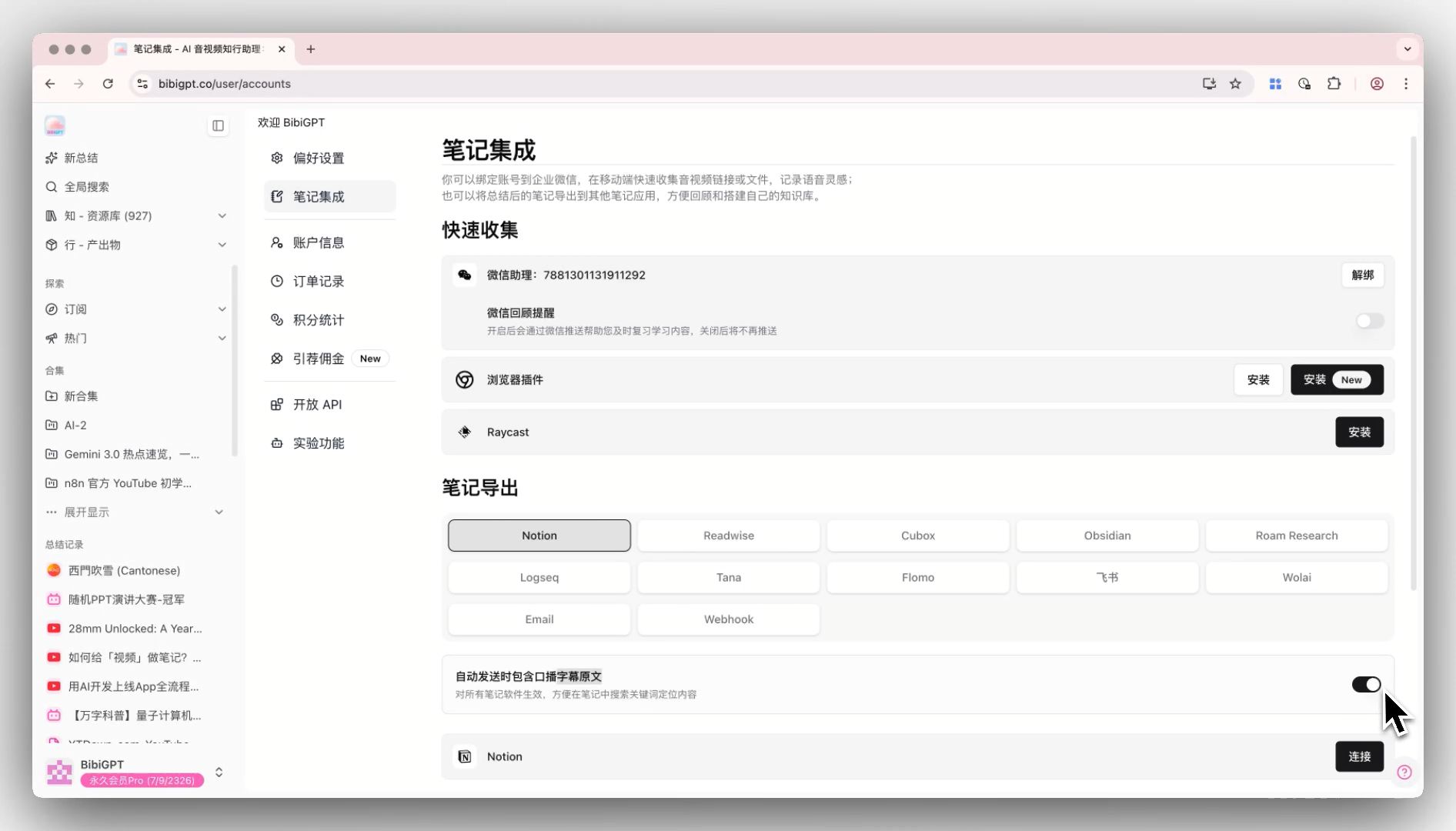
做法: 每期播客的完整字幕原文必须落进笔记。BibiGPT 的 笔记导出包含字幕原文 功能就是为这一层设计的——一次性打开全局开关,之后每次导出都自动附带逐字稿。
为什么原文层很重要: AI 总结再好也有信息损耗。你会忘记某句话的具体措辞,但搜索时只能用关键词——这时候原文是兜底。
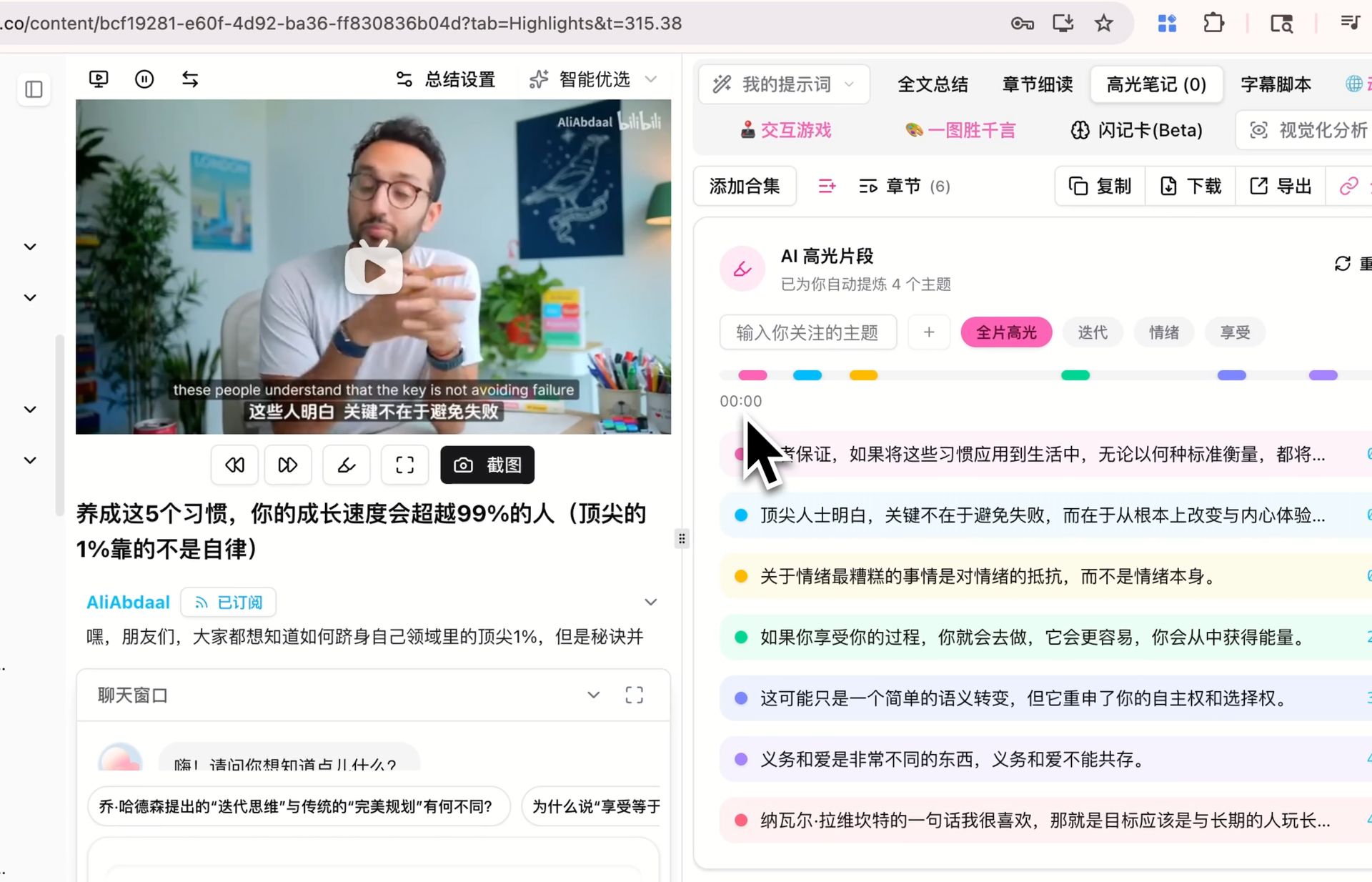
第 2 层:高光层(Highlight Layer)
作用: 长播客里的核心观点、好句子、关键洞察——这些是你以后回看时最想找的部分。
做法: 用 BibiGPT 的 AI 高光笔记 自动提取并按主题分类。AI 会自己识别哪些段落是「嘉宾的核心观点」、哪些是「金句」、哪些是「反共识表达」,然后按主题归类。
关键设计哲学: 高光层不是 AI 总结,是「带时间戳的可点回原音频的精彩片段」。这意味着你以后翻笔记看到「嘉宾说 X」,可以一键回到那个时间点听原音——这是音频 PKM 不同于文字 PKM 的核心价值。
第 3 层:检索层(Retrieval Layer)
作用: 整个第二大脑要可以被搜索。
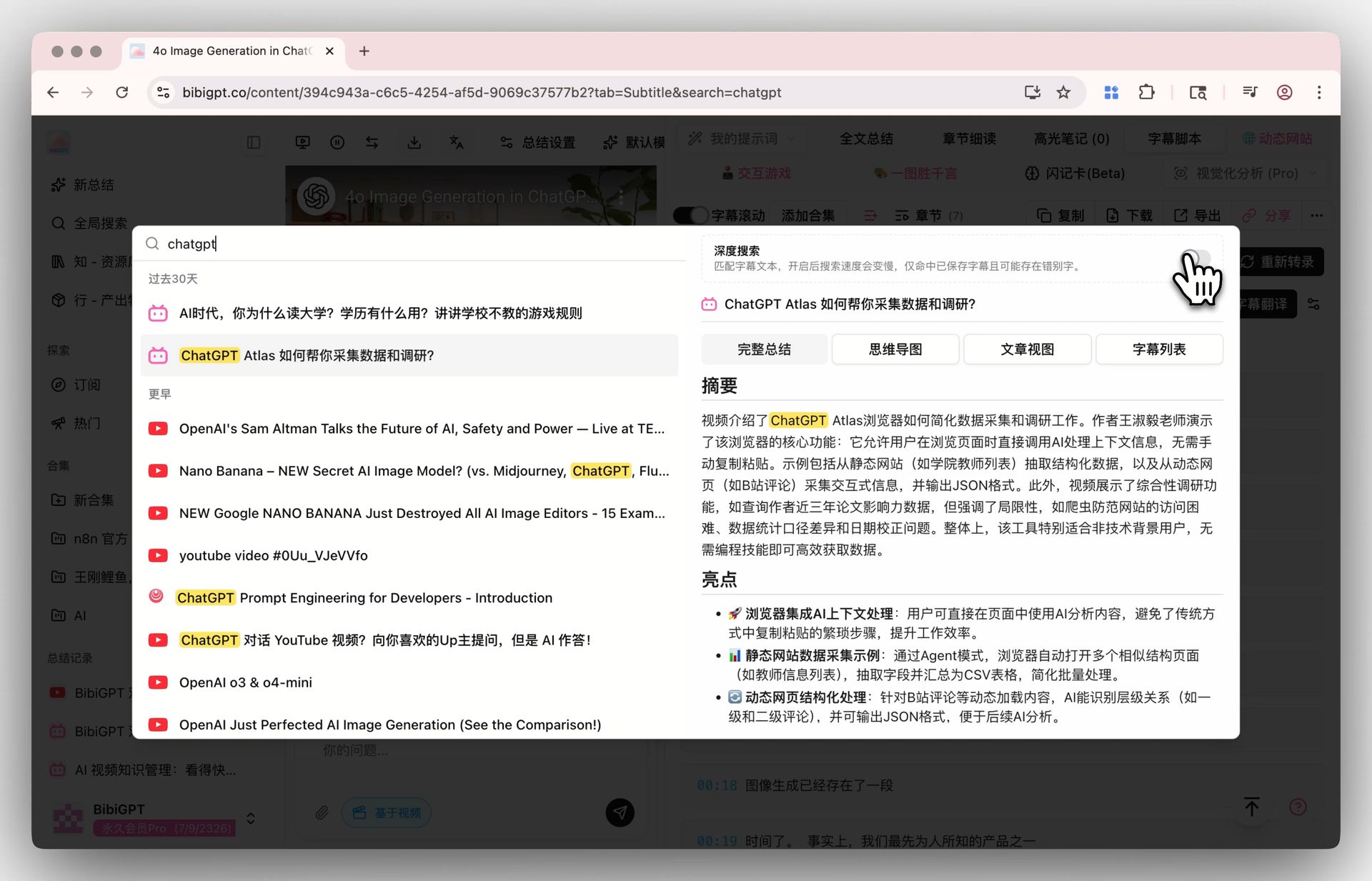
做法: BibiGPT 的 深度搜索 不只是搜标题和总结,而是搜每期播客的完整字幕全文。意思是即使 AI 总结里没提到”vector database”这个词,但嘉宾在第 47 分钟说过一次,深度搜索一样能定位到那期那个时间点。
配合 Obsidian / Notion: 如果你已经在用 Obsidian 做笔记,BibiGPT 导出的笔记可以直接同步到 Obsidian Vault。在 Obsidian 里用 Dataview / Search 可以做更复杂的关联——比如「列出所有提到 CUDA 的播客笔记」。
一周工作流:每天 30 分钟管理 20 小时音频
不是要你每天花 3 小时整理笔记——那不可持续。Deep Work 的核心是每天 30 分钟,专注做一件事:把昨天听的播客沉淀成可检索的笔记。
周一到周五(每天 30 分钟)
早上通勤 (60 分钟) - 听一期 60 分钟的播客(不做任何笔记,纯听)。
到办公室前 10 分钟,做下面 3 步:
- 在 BibiGPT 把这期播客的链接粘贴进去,让它跑(约 1-3 分钟出结果);
- 等待时拿出手机打字 1-2 句「我听完这期的第一感受是什么」——这是 metadata,没有它将来翻笔记时看不到自己当时的理解;
- BibiGPT 出结果后,扫一眼 AI 高光,确认提取的核心观点和你听到的一致——不一致就在笔记里加一行批注。
晚上回家后 (20 分钟):
- BibiGPT 笔记一键导出到 Obsidian(开了字幕原文开关 + 自动同步设置后这步是零操作);
- 在 Obsidian 里给这期笔记加 2-3 个 tag(如
#AI #CUDA #Lex-Fridman); - 如果有特别想深挖的点,在笔记顶部写一行待办:「以后要单独写一篇关于 X 的总结」。
周末 (1 小时)
每周日做一次「周回顾」:
- 翻一遍这周 5 期播客的高光笔记,找 3 个反复出现的主题;
- 用 BibiGPT 的 合集功能 把这 5 期放进一个 weekly 合集,让 AI 跨期总结这周的认知主线;
- 把「周认知主线」写成一段话放在 Obsidian 的周报里。
这套工作流的关键不在于复杂,而在于每天 30 分钟是可持续的。一周下来你有 5 期播客的完整笔记 + 1 个周认知合集——一个月就是 20+ 期播客的可检索知识库,一年就是 240+ 期的第二大脑。
跨播客追问:从合集 AI 对话开始
PKM 系统的最高境界是跨内容对话——当你听了 50 期 AI 主题的播客,问「这 50 个嘉宾对 AGI 时间表的预测有什么共识和分歧」?
BibiGPT 的 合集 AI 对话 让你直接向整个合集提问。比如:
- 「这 30 期 Lex Fridman 播客里,被嘉宾提到次数最多的论文是哪几篇?」
- 「在张小珺的商业访谈合集里,每个创业者讲到失败时最常提的根本原因是什么?」
- 「忽左忽右这一年里关于教育话题的讨论,有哪些没有共识的争论点?」
AI 会跨期整合答案。这是单期听播客做不到的能力——人脑无法同时持有 30 期的细节,但 AI 可以。
把播客做成播客:双向沉淀
有些播客内容你听完会发现「这个观点我想再说一遍给别人听」——BibiGPT 的 小宇宙播客生成 可以把视频内容自动生成双人对谈音频,让你的产出也变成音频形态。
这对内容创作者尤其有用:听别人的播客 → 沉淀洞察 → 重新生成自己的播客 → 形成内容飞轮。
BibiGPT 是为「内容消费速度跟上生产速度」设计的
播客这种长格式内容的痛点是显然的:生产速度快、消费速度慢、沉淀速度更慢。每周有数千期新播客上线,靠人脑根本听不完,更别说沉淀。
BibiGPT 的设计哲学是:把「听播客 → 沉淀成知识库」这个全链路做成秒级体验。
- 30+ 平台覆盖:小宇宙、苹果播客、Spotify、YouTube 播客、喜马拉雅等主流平台粘贴链接即可;
- 多语言原生:中/英/日/韩四语 AI 总结,听英文播客也能得到中文笔记;
- 批量+合集:一次粘贴 10 期播客链接批量处理,合集级别 AI 跨期对话;
- 导出整合:Notion、Obsidian、Cubox、本地文件夹自动同步;
- 服务超过 100 万用户,累计生成超过 500 万次 AI 总结。
常见问题(FAQ)
Q1: 我习惯只听不做笔记,这套工作流是不是太累?
A: 反过来——这套工作流的核心就是「听的时候不做任何笔记」。听播客是输入,笔记是事后 5 分钟自动跑出来的产物。如果你听完播客 30 分钟内能花 5 分钟扫一眼 AI 总结+加 2 个 tag,就够了。
Q2: BibiGPT 处理英文播客的中文笔记质量怎么样?
A: BibiGPT 不是机翻,是 AI 基于原文重新组织中文表达。Lex Fridman / Tim Ferriss 这类语速较快的英文长播客,中文总结质量很高(章节切分准确,核心观点抓得到)。对 AI 工程师/研究员而言比直接读英文 transcript 节省至少 60% 的时间。
Q3: 小宇宙、苹果播客、Spotify 都能用吗?
A: 是的。BibiGPT 支持 30+ 主流音视频平台,主流播客平台基本全覆盖。小宇宙、苹果播客、Spotify、YouTube 播客、喜马拉雅、网易云音乐、荔枝 FM 都能粘贴链接处理。
Q4: 我已经用 Notion 做 PKM 系统了,能集成吗?
A: 完全可以。BibiGPT 笔记可以一键导出到 Notion(设置同步路径后自动归档),保留 AI 总结、AI 高光、字幕原文三层结构。在 Notion 里用 Database 视图按「嘉宾/主题/日期」做多维筛选很顺。
Q5: 跨语言播客(中英夹杂的访谈)BibiGPT 处理得好吗?
A: 这是 BibiGPT 的强项。即使嘉宾中英文混合表达,AI 字幕识别和总结都能跨语言处理——比一些只支持单一语言的转录工具好用得多。
写在最后
第二大脑的本质不是「把所有东西都记下来」,是「让你想找的时候能找到」。播客 PKM 的最大障碍是音频的不可索引性——BibiGPT 把音频做成可检索的三层结构(原文+高光+总结),就是为了打破这个障碍。
Deep Work 工作流的核心不是花更多时间在 PKM 上,是每天 30 分钟坚持做对的 3 件事:听完粘贴链接、扫一眼 AI 高光、加 2 个 tag。一周一个周认知合集,一年 240+ 期的第二大脑。
想试试?粘贴一期最近听的播客链接到 BibiGPT,看看 AI 高光提取的核心观点和你听到的是否一致。
—— BibiGPT 团队