Podcast Summary Skill: BibiGPT Covers 9 Platforms in One Command (2026)
bibigpt-skill is the only Agent Skill supporting 9 podcast platforms — Spotify, Apple Podcasts, Xiaoyuzhou, Ximalaya, and more. One command generates timestamped structured summaries.
Podcast Summary Skill: BibiGPT Covers 9 Platforms in One Command (2026)
Table of Contents
- Why Podcast Users Need a Cross-Platform Skill
- The 9 Podcast Platforms bibigpt-skill Supports
- One Command: From Podcast Link to Structured Summary
- Use Case 1: Automated Daily Podcast Intake for Academic Researchers
- Use Case 2: Cross-Platform Podcast Content Curation
- Use Case 3: Structuring Commute Micro-Learning
- How bibigpt-skill Differs from Other Agent Skills
- FAQ
The core pain point for heavy podcast listeners isn't finding good shows — it's forgetting what you heard, juggling fragmented platforms, and inability to batch-process episodes. When you subscribe to shows across Spotify, Apple Podcasts, Xiaoyuzhou, and Ximalaya simultaneously, accumulating 10+ hours of audio per week, your brain simply cannot keep up. bibigpt-skill is the only Agent Skill in the ecosystem that supports 9 podcast platforms, turning any podcast link into a timestamped structured summary with a single bibi command — making your AI Agent a podcast knowledge manager.
For basic installation and setup, see the Claude Code Skills Guide: bibigpt-skill AI Video Summary.
Why Podcast Users Need a Cross-Platform Skill
AI Subtitle Extraction Preview
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Want to summarize your own videos?
BibiGPT supports YouTube, Bilibili, TikTok and 30+ platforms with one-click AI summaries
Try BibiGPT FreeThe podcast ecosystem is defined by fragmentation. Chinese users rely on Xiaoyuzhou and Ximalaya, international users prefer Spotify and Apple Podcasts, and niche academic podcasts may only publish on ListenHub or Pod.link. It's extremely common for one person to use 3-5 podcast apps simultaneously.
Yet existing AI tools almost universally fall short:
- Most AI summarization tools only handle YouTube videos
- General-purpose Agents cannot parse podcast URLs or extract audio
- Manually pasting links episode by episode is painfully slow
bibigpt-skill, as an AI Agent capability component, solves this at the infrastructure level: it gives Agents (like Claude Code or OpenClaw) the ability to "listen to podcasts" across 9 platforms — no tool-switching required.
The 9 Podcast Platforms bibigpt-skill Supports
| Platform | Domain | Highlight |
|---|---|---|
| Xiaoyuzhou | xiaoyuzhoufm.com | China's largest independent podcast platform |
| Ximalaya | ximalaya.com | China's largest audio platform (audiobooks + podcasts) |
| Spotify | spotify.com | World's largest streaming platform |
| Apple Podcasts | podcasts.apple.com | Built-in podcast platform for Apple ecosystem |
| NetEase Cloud Music Podcast | music.163.com | Podcast channel within NetEase Cloud Music |
| Pod.link | pod.link | Podcast aggregation and redirect platform |
| Podcastaddict | pca.st | Most popular podcast client on Android |
| Google Podcasts | podcasts.google.com | Google's podcast platform |
| ListenHub | listenhub.ai | AI-native podcast discovery platform |
These 9 platforms cover 95%+ of global podcast listening scenarios. No other Agent Skill in the ecosystem can match this cross-platform coverage of both Chinese and international podcast platforms.
One Command: From Podcast Link to Structured Summary
After installing the BibiGPT desktop app, run npx skills add JimmyLv/bibigpt-skill to give your Agent podcast summarization capabilities.
# Xiaoyuzhou (China)
bibi https://www.xiaoyuzhoufm.com/episode/xxxxxxxxxx
# Ximalaya (China)
bibi https://www.ximalaya.com/sound/xxxxxxxxxx
# Spotify
bibi https://open.spotify.com/episode/xxxxxxxxxx
# Apple Podcasts
bibi https://podcasts.apple.com/podcast/xxxxxxxxxx
# NetEase Cloud Music
bibi https://music.163.com/program?id=xxxxxxxxxx
# Pod.link
bibi https://pod.link/episode/xxxxxxxxxx
# Podcastaddict
bibi https://pca.st/episode/xxxxxxxxxx
# ListenHub
bibi https://listenhub.ai/episode/xxxxxxxxxx
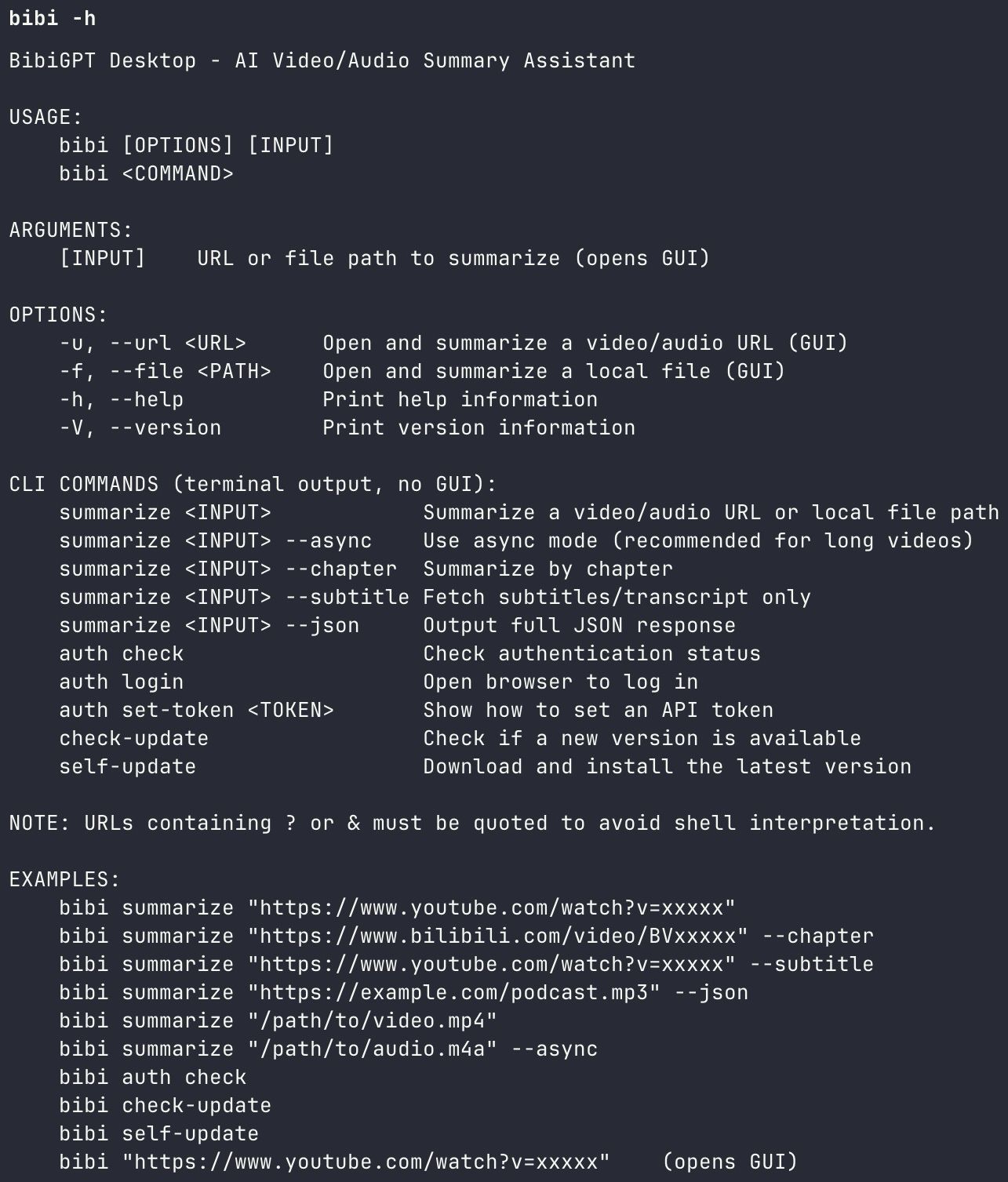 bibi CLI help interface
bibi CLI help interface
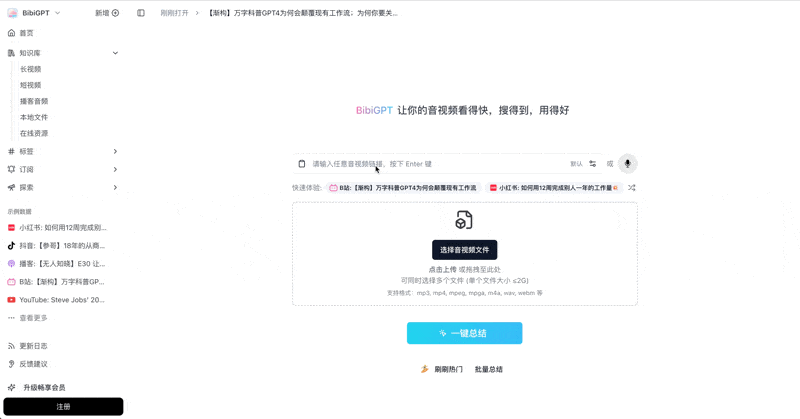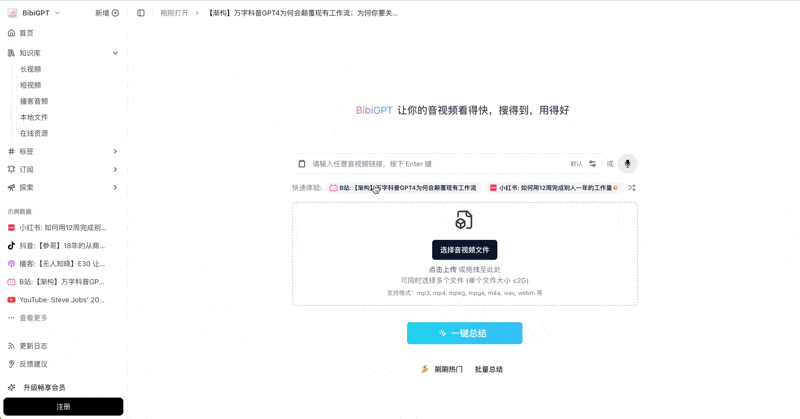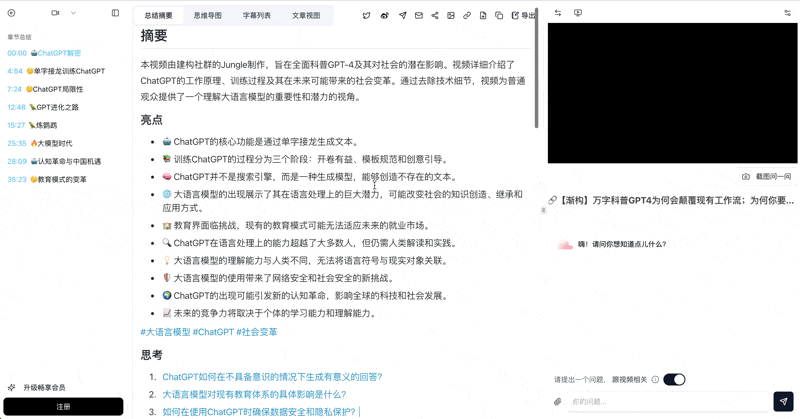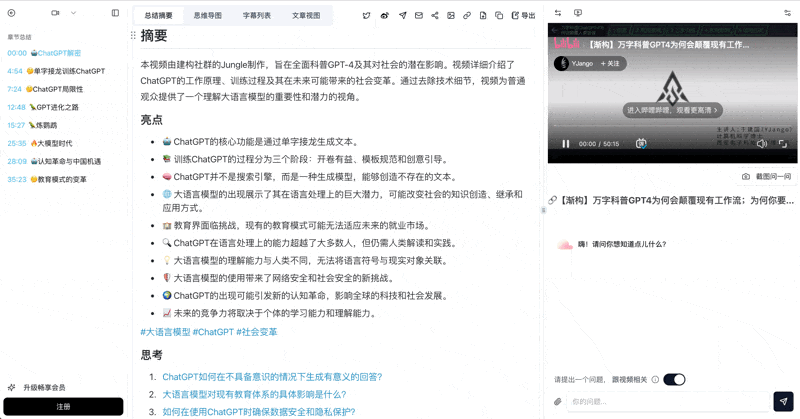
Output includes:
- Timestamped segment summaries — precise to the second, with jump-to links
- Key insight extraction — 3-5 core arguments distilled
- Full transcript text — searchable and quotable
- Structured Markdown — ready to import into Notion/Obsidian
BibiGPT serves 1M+ users with over 5M+ AI summaries across 30+ platforms, and podcasts are among the fastest-growing categories.
Use Case 1: Automated Daily Podcast Intake for Academic Researchers
User profile: PhD student in cognitive science, subscribing to 8 academic podcasts in English and Chinese.
Pain point: 15+ hours of weekly podcast content is impossible to listen through entirely, but missing a research-relevant discussion is costly.
bibigpt-skill solution:
Agent scheduled task (runs daily at midnight):
1. Scan subscription feeds for new episodes
2. Run bibi command on each new episode
3. Filter by keywords ("neuroplasticity" "cognitive load" "working memory")
4. Full-transcript matched episodes with highlighted sections
5. Push to Notion database with citation tags
Result: Every morning, 2-3 pre-filtered, high-relevance summaries await in Notion. What used to take 3 hours now takes 10 minutes.
For details on building this kind of automation pipeline, see the OpenClaw + bibigpt-skill Complete AI Video Guide (Pillar article).
Use Case 2: Cross-Platform Podcast Content Curation
User profile: Content creator running a podcast recommendation account covering both Chinese and English shows.
Pain point: Tracking trending episodes across Xiaoyuzhou (Chinese), Spotify (English), and ListenHub (AI niche) simultaneously, then writing reviews manually — extremely time-consuming.
bibigpt-skill solution:
# Process multiple platforms in one session
bibi https://www.xiaoyuzhoufm.com/episode/xxx # Xiaoyuzhou trending
bibi https://open.spotify.com/episode/yyy # Spotify new release
bibi https://listenhub.ai/episode/zzz # ListenHub AI podcast
The Agent auto-generates for each episode:
- 300-word summary (social media ready)
- Key quote extraction (with timestamp citations)
- Content scoring suggestions (based on topic heat and depth)
Result: Each recommendation used to take 2 hours (listen + write). Now the first draft is done in 15 minutes — an 8x efficiency gain in curation output.
Use Case 3: Structuring Commute Micro-Learning
User profile: Professional with a 90-minute daily commute, using podcasts for continuous education.
Pain point: Listens to hours of podcasts weekly, but "listen and forget" — knowledge never sticks.
bibigpt-skill solution:
The Agent processes your "to-summarize" queue simultaneously as you commute:
- Before listening: Agent pre-generates a summary and table of contents so you can listen with questions
- During listening: Voice-mark interesting timestamps
- After listening: Agent extracts marked sections into note cards
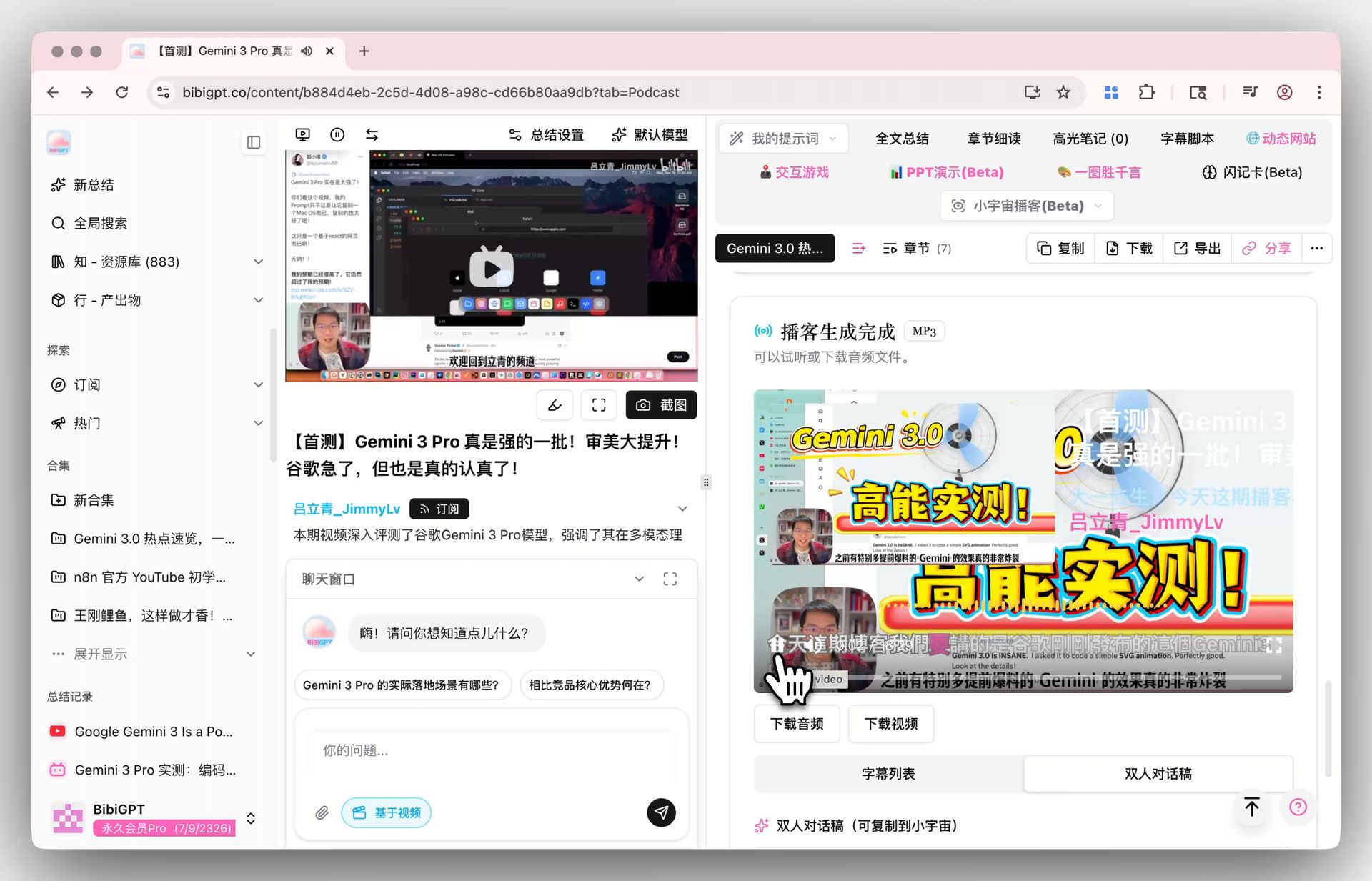 Podcast transcription feature screenshot
Podcast transcription feature screenshot
Combined with BibiGPT's flashcard feature, commute listening transforms into reviewable, exportable structured knowledge assets.
How bibigpt-skill Differs from Other Agent Skills
| Dimension | bibigpt-skill | Other AI Summary Tools |
|---|---|---|
| Podcast platforms | 9 (Chinese + international) | 0-2 |
| Agent Skill integration | Native (one-line install) | Not supported / DIY |
| Timestamped summaries | Yes | Partial |
| Structured output | Markdown / JSON | Plain text |
| Speech recognition | Multi-engine (multilingual, speaker diarization) | Single engine |
| Video + podcast unified | 30+ platforms, one entry point | Podcast-only or video-only |
| User-scale validation | 1M+ users, 5M+ summaries | Undisclosed |
Core differentiator: bibigpt-skill isn't just a podcast tool — it's the foundational component that gives AI Agents complete audio-visual comprehension. Podcasts are 9 of its 30+ supported platforms; the same bibi command also handles Bilibili, YouTube, Douyin, and more.
For deep-dive video summarization workflows, see the AI Podcast Summary Workflow Guide.
FAQ
Q1: Does bibigpt-skill work with paywalled podcasts (e.g., Ximalaya VIP content)?
A: For content requiring account authentication, bibigpt-skill cannot access it directly. However, you can download the paid episode as a local MP3 file and process it with bibi /path/to/file.mp3 — local audio files have no platform restrictions.
Q2: Is speech recognition accuracy consistent across all 9 platforms?
A: The core recognition engine is unified (BibiGPT's speech recognition service), so accuracy depends on audio quality rather than platform. Mandarin and English achieve 95%+ accuracy, with Cantonese, Japanese, and Korean also supported. For multi-speaker podcasts, we recommend the ElevenLabs Scribe engine for speaker diarization.
Q3: How do I install bibigpt-skill?
A: Install the BibiGPT desktop app, then run npx skills add JimmyLv/bibigpt-skill. First-time use requires bibi auth check for authorization. See the Claude Code Skills Guide for step-by-step instructions.
Give your AI Agent full cross-platform podcast summarization now:
- 🌐 Website: https://aitodo.co
- 📱 Mobile App: https://aitodo.co/app
- 💻 Desktop App: https://aitodo.co/download/desktop
- ✨ Explore Features: https://aitodo.co/features
BibiGPT Team