AI Haoji vs BibiGPT: 2026 Deep Comparison of AI Meeting Notes Tools (Professional Buyer's Guide)
AI Haoji focuses on meeting audio transcription; BibiGPT covers everything from meetings to Bilibili / YouTube / podcast AI summaries. This post compares both across features, pricing, and scenarios so professionals can pick the right tool.
AI Haoji vs BibiGPT: 2026 Deep Comparison of AI Meeting Notes Tools (Professional Buyer's Guide)
80-word answer: AI Haoji is a meeting-focused audio-transcription + notes tool, great for pros with heavy internal-meeting loads. BibiGPT is a broader AI audio-video assistant that handles meetings, Bilibili / YouTube / podcasts, plus AI follow-up chat, cross-video collections, and Obsidian auto-sync. Meetings only → AI Haoji. Meetings + external content consumption → BibiGPT.
Written for pros who juggle meetings, online learning, and content research — no cheerleading, just scenario-by-scenario mapping.
1. Product positioning
| Dimension | AI Haoji | BibiGPT |
|---|---|---|
| Core positioning | Meeting audio transcription + notes | AI audio-video assistant (general-purpose) |
| Input sources | Meeting audio, local audio | Paste URL (Bilibili / YouTube / Xiaoyuzhou / Douyin / TikTok / Xiaohongshu) + local files + meeting audio |
| AI summary structure | Meeting-minutes layout (agenda, decisions, todos) | Chapter timestamps + free structure + custom prompts |
| AI follow-up chat | Per-meeting | Per-video + cross-collection |
| Multi-language output | Mostly Chinese | Chinese / English / Japanese / Korean / Traditional Chinese |
| Note sync | In-app mainly | Obsidian auto-save / Notion / Lark / Yuque |
| Desktop client | Yes | Yes (Tauri, multi-platform) |
| Mobile | Yes | Yes (Expo) |
| Browser extension | Partial | Yes (Chrome / Firefox / Edge) |
2. Scenario comparison: five real use cases
Scenario 1: internal weekly / project meetings
AI Haoji: home turf. Minutes follow "agenda → discussion → decision → todos", matching OKR/PM conventions.
BibiGPT: also works. Meeting audio uploads fine, transcribes, summarizes. Default structure skews toward video chapters — flip to minutes format via a custom prompt.
Pick: Heavy meeting-only → AI Haoji. Meeting + video learning → BibiGPT.
Scenario 2: online courses / Bilibili / YouTube learning notes
AI Haoji: not home turf. Requires audio download before upload — roundabout flow.
BibiGPT: paste a Bilibili / YouTube URL, get chapter timestamps + AI summary + captions in ~10 seconds, with timestamp jump-to-play.
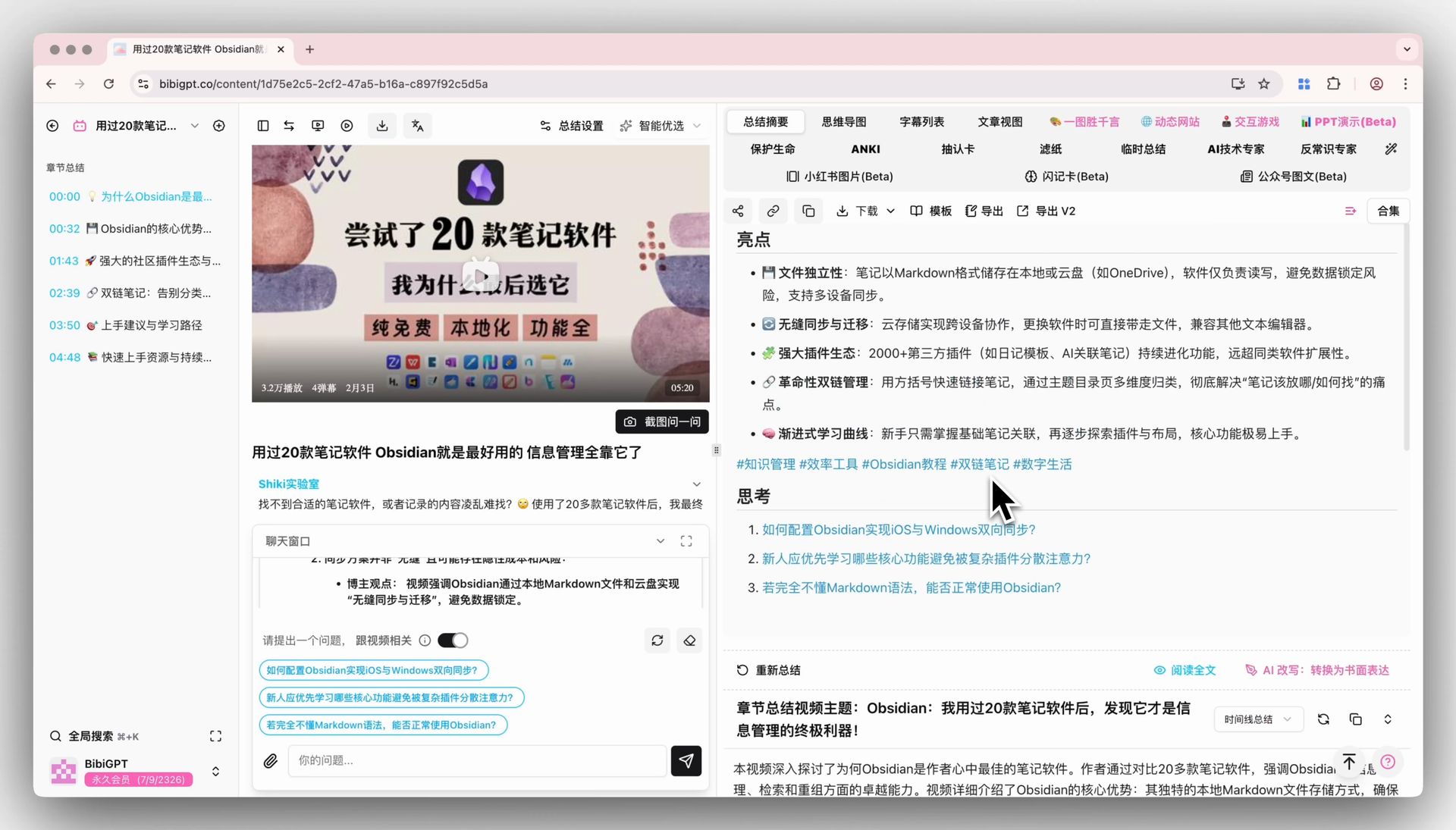 Custom prompt summary
Custom prompt summary
Pick: online learning → BibiGPT, clearly.
Scenario 3: deep podcast consumption (Xiaoyuzhou / Apple Podcasts)
AI Haoji: requires manual audio download and upload.
BibiGPT: paste Xiaoyuzhou URL directly — transcribe + AI summary + chapter jumps built in.
Pick: podcast users → BibiGPT.
Scenario 4: multilingual meetings (MNCs / cross-border teams)
AI Haoji: mainly Chinese market; English / multilingual support is weaker.
BibiGPT: native multilingual summary and translation (EN / CN / JA / KO / zh-TW). Can summarize an English video directly in Chinese — fits MNCs, cross-border e-commerce, international schools.
Pick: multilingual → BibiGPT.
Scenario 5: building a long-term knowledge base
AI Haoji: minutes centralized in-app; exports are manual.
BibiGPT: auto-save to Obsidian Vault, cross-collection AI chat forms a personal knowledge network.
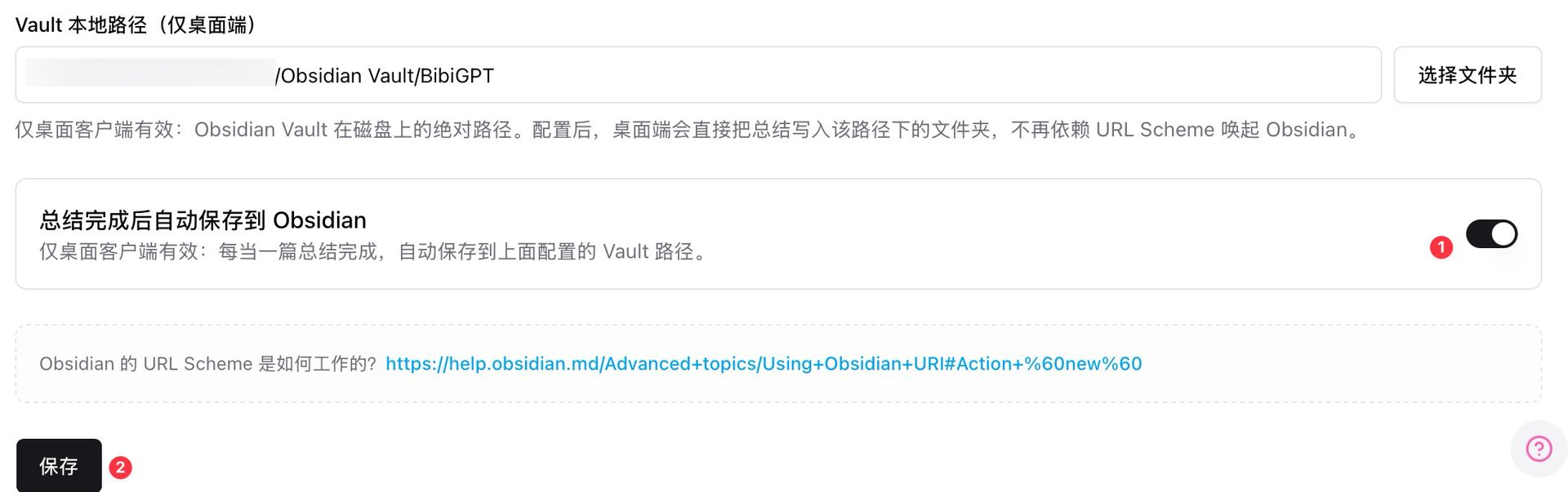 Obsidian auto-save
Obsidian auto-save
Pick: heavy PKM users → BibiGPT.
3. Pricing & subscriptions
Both run on free tier + subscription. AI Haoji leans toward per-minute billing for high-frequency meeting users. BibiGPT offers Plus / Pro subscriptions plus on-demand top-up (great for API customers); details at bibigpt.co/pricing.
Pricing may change. Official site values are the source of truth.
4. Honest take for "mixed-scenario" professionals
If your weekly content diet is:
- 2–3 internal meetings
- 2–3 Bilibili / YouTube knowledge videos
- 1–2 Xiaoyuzhou podcasts
- Occasional English interviews / keynotes
Then AI Haoji alone leaves Bilibili / YouTube / podcasts as blind spots — you either add another tool or keep manual notes. That's where BibiGPT's "one tool covers all" value peaks.
Conversely, if you only attend meetings and don't watch videos (full-time PM / HR), AI Haoji's minutes template aligns tighter with your existing meeting-notes habit — less tool-learning cost.
5. BibiGPT differentiators (AI Haoji lacks or is weaker)
1. Collections AI Chat: cross-video knowledge base
Group same-topic videos into a Collection, ask one question, AI integrates answers across all videos.
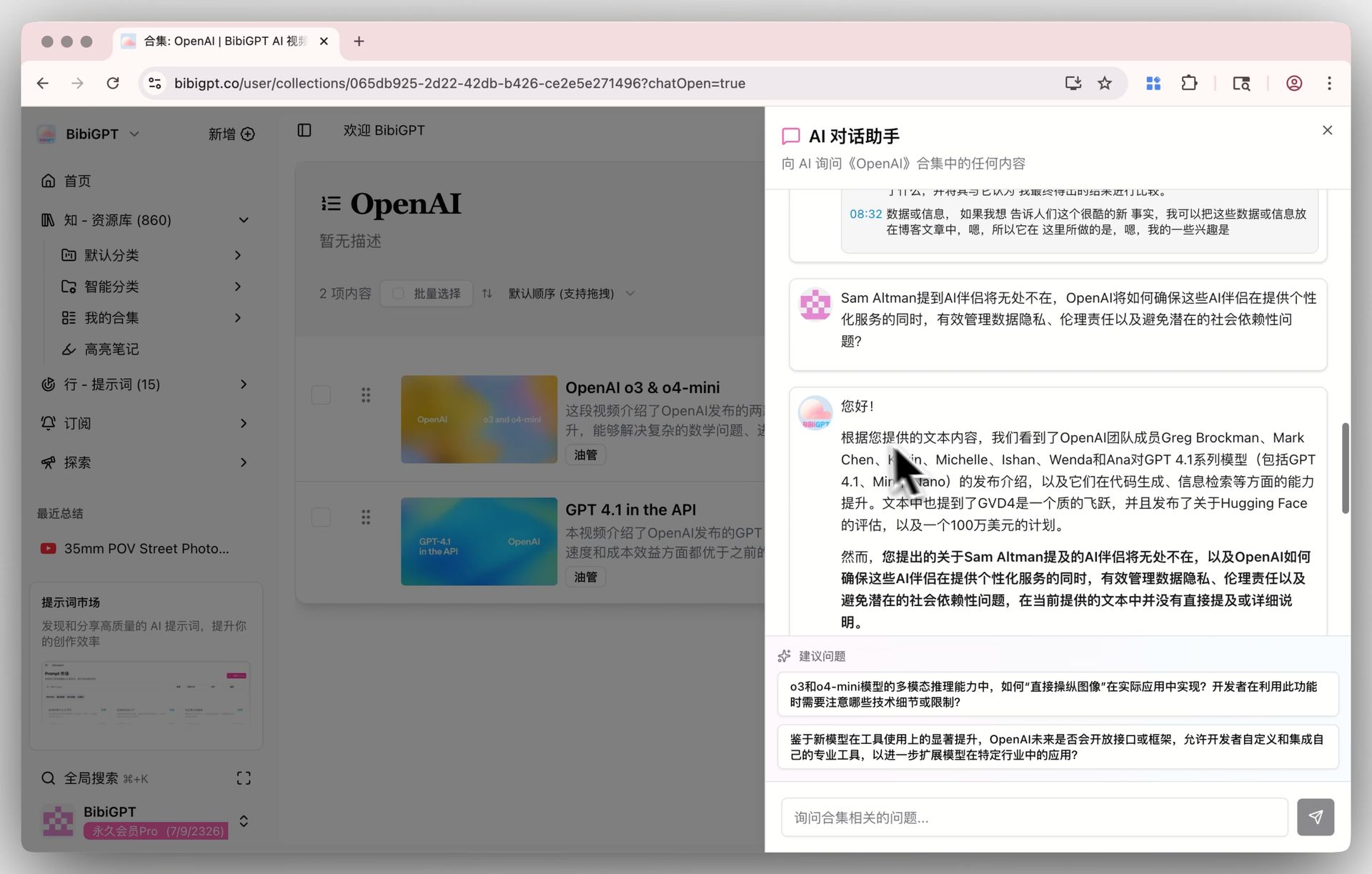 Collections AI chat
Collections AI chat
2. Custom prompts: one video, many outputs
Run the same meeting recording through different prompts: "meeting minutes", "action-item list", "email draft to the team", "one-pager for the boss". Replaces the usual back-and-forth with ChatGPT copy-paste.
3. Native external-video support
Paste Bilibili, YouTube, Xiaohongshu, Xiaoyuzhou, Douyin, TikTok URLs directly — the core scenario AI Haoji doesn't cover.
4. Obsidian / Notion / Lark integration
Desktop auto-writes to local Obsidian Vault. Combined with backlink graphs, you grow a living knowledge network. Built for heavy PKM.
6. FAQ
Q1: What's AI Haoji's strength?
Meeting-scenario specialization + Chinese meeting-minutes structure (agenda / decisions / todos) that matches Chinese workplace conventions. If you're a PM / HR running 3–5 meetings a day, AI Haoji's template is plug-and-play.
Q2: Can BibiGPT replace AI Haoji for meeting notes?
Yes. Set up a "meeting-minutes format" custom prompt in BibiGPT — one-time config, all future meeting recordings follow that structure. Plus external video scenarios are covered.
Q3: Can I use both?
Absolutely. AI Haoji for internal meetings, BibiGPT for external content — non-conflicting. Most pros pick one primary tool to avoid note fragmentation.
Q4: Does BibiGPT support live recording?
Desktop supports local audio-file upload. For live meeting recording, use OS-level recorders (macOS Screen Recording / Windows Voice Recorder) then upload.
Q5: Meeting content is confidential — how's data security?
BibiGPT offers enterprise + private-link modes, with on-prem or privatized processing options. Regular subscribers can also set content to private. See the enterprise page.
Q6: Can it recognize Chinese–English code-switching meetings?
Yes, BibiGPT's ASR handles Chinese–English code-switching — fits MNCs and cross-border teams. AI Haoji is improving multilingual but its core strength remains Chinese.
Q7: Which is cheaper?
Depends on usage. Short / low-frequency users: both free tiers are enough. High-frequency users: compare meeting-hours vs video-count. BibiGPT's Plus + on-demand top-up tends to be more flexible.
Try it: experience both scenarios
试试粘贴你的视频链接
支持 YouTube、B站、抖音、小红书等 30+ 平台
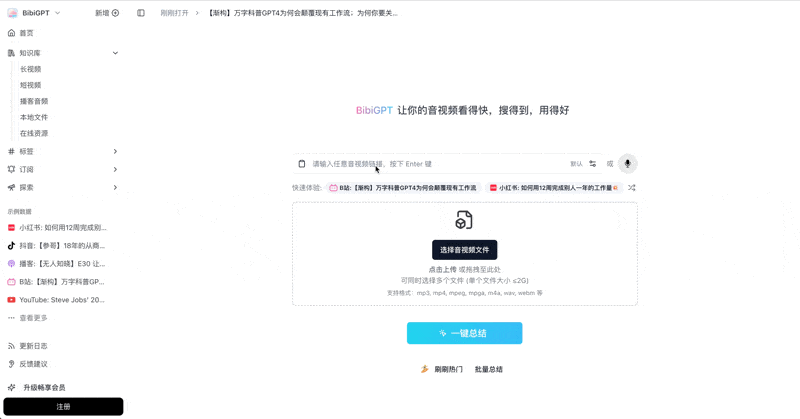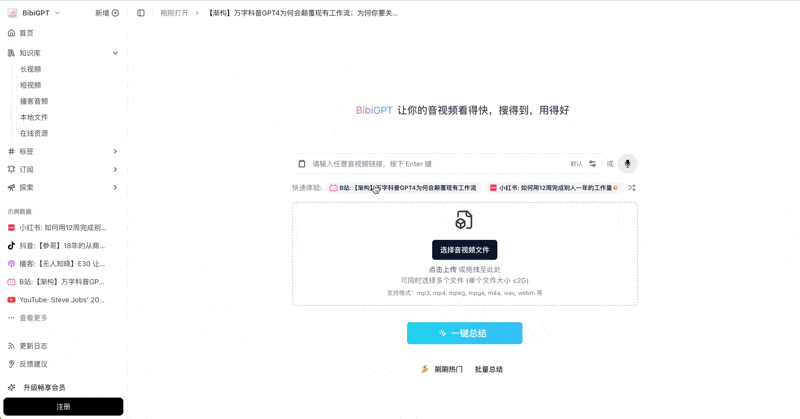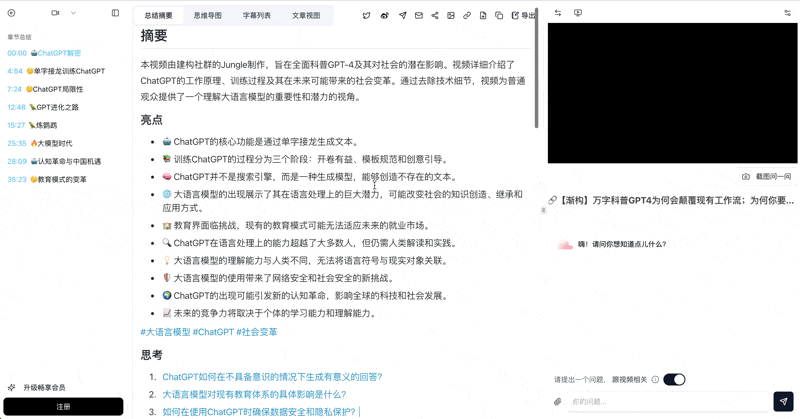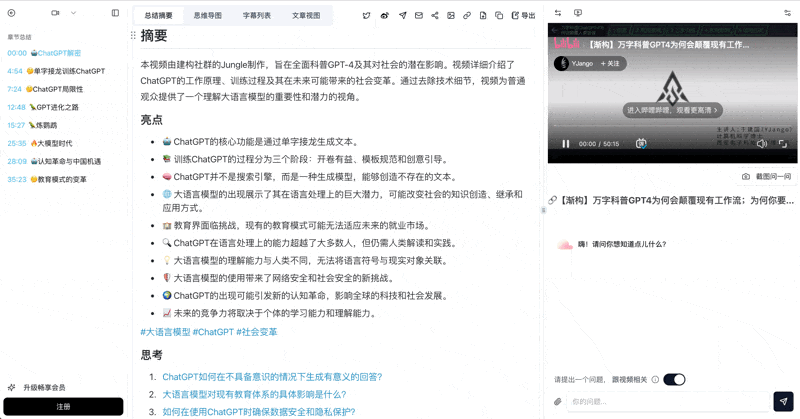
See a real example — a 30-min meeting recording through BibiGPT:
看看 BibiGPT 的 AI 总结效果
Let's build GPT: from scratch, in code, spelled out
Andrej Karpathy walks through building a tiny GPT in PyTorch — tokenizer, attention, transformer block, training loop.
Further reading:
- AI Video to Article Complete Guide 2026
- AI Video Summary Productivity Workflows
- Build a Personal Video Knowledge Base with BibiGPT + Obsidian
Core features: Custom Prompt Summary, Collections AI Chat, Obsidian Auto-Save.
BibiGPT Team