NotebookLM Deep Research vs BibiGPT 工作流对比 2026:研究升级后的选型决策
NotebookLM Deep Research vs BibiGPT 工作流对比 2026:研究升级后的选型决策
目录
- 背景:NotebookLM 在 2026 年 5 月 6 日的双重升级
- 深度分析:Deep Research + 新源类型给研究工作流带来的三层变化
- BibiGPT 工作流:从”链接+本地文件+字幕”三入口出发
- 对 BibiGPT 用户的实际意义:研究者、学生、企业知识库
- BibiGPT 实战搭配:把 NotebookLM Deep Research 当成”读”,BibiGPT 当成”看”
- 前景预测:研究工具的三个分叉点
- 常见问题 FAQ
核心答案(截至 2026-05-19): 2026 年 5 月 6 日 Google 在 NotebookLM 官方更新页 同步发布两件事——Deep Research 模式 GA,自动浏览百+网站合成报告;同时新增 Google Sheets、.docx、Google Drive URLs、PDFs、图片作为可用数据源。BibiGPT 的差异化定位被进一步清晰:NotebookLM 把”读文档”做深,BibiGPT 把”看音视频”做完整——两者在严肃研究工作流里互补,而不是替代。
实用规则: 任何”NotebookLM 升级了 BibiGPT 就过时了”的判断都过于简化。问对的问题是:“这次升级把哪条工作流的瓶颈搬到了哪里?“
背景:NotebookLM 在 2026 年 5 月 6 日的双重升级
事件时间线(截至 2026-05-19):
- 2024 年 9 月:NotebookLM 推出,主打”上传 PDF/文档生成笔记和音频概览(Audio Overview)”
- 2025 年下半年:Cinematic Video Overviews(Gemini 3 + Veo 3 联合生成视频摘要)、Interactive Audio Mode(可打断的播客对话)
- 2026 年 5 月 6 日:Deep Research GA — 自动浏览百+网站合成报告
- 2026 年 5 月 6 日(同日):新数据源类型上线 — Google Sheets /
.docx/ Drive URLs / PDFs / 图片 - 2026 年 5 月 12 日:NotebookLM 接入 Workspace Studio 全量铺开 — notebook 变 AI 知识源
实用规则: 当一个工具同时升级”输入侧”(更多数据源类型)和”处理侧”(自动浏览百+网站合成),意味着它从”被动文档库”变成”主动研究员”——这种跨越远比单点功能改进重要。
Google Cloud Next 2026 大会 上 Google 把 NotebookLM 定位为”企业研究入口”。在原本的”上传文档→生成 podcast 概览”模式之上,Deep Research 让用户只需要给一个研究问题(如”过去 6 个月 GenAI 在医疗领域的进展”),系统自动浏览 100-300 个网站,合成一份 5000-15000 字的结构化报告。
深度分析:Deep Research + 新源类型给研究工作流带来的三层变化
技术影响:从”上传文档”到”主动研究”
NotebookLM 2024 版本的核心交互是 RAG(检索增强生成)——用户上传几十个 PDF/网页,AI 在这些固定文档上做问答。Deep Research 把这套范式倒过来:用户给一个问题,AI 主动出去抓 100-300 个网页,合成结构化报告。
这是研究工具的范式跃迁——从”在你提供的资料里答题”到”主动去把资料找齐再答题”。但它的边界依然清晰:只能”读网页”。所有可被 Google Search 索引的页面都是它的素材;所有不能被索引的内容——YouTube 视频、播客音频、B 站长视频、内部 mp4 录像、Twitter Spaces 录制——它都拿不到。
市场影响:研究工具赛道的两极化
从 Perplexity Deep Research 到 ChatGPT Deep Research 到 NotebookLM Deep Research,2026 年 H1 至少有 5 家顶级 AI 公司围绕”自动深度研究”开战。但它们的共同前提都是文档为本位——核心数据源仍然是网页和 PDF。
而严肃研究的另一半数据源——音视频——目前几乎全靠 BibiGPT、Otter.ai、Memories.ai 等垂直工具承担。这导致 2026 年的研究工作流出现明显的两极分化:
| 数据源类型 | 主导工具 | 典型场景 |
|---|---|---|
| 网页 / PDF / 文档 | NotebookLM / Perplexity / ChatGPT Deep Research | 行业研究报告、学术论文综述 |
| YouTube / 播客 / B站长视频 / 本地 mp4 | BibiGPT / Memories.ai | 嘉宾访谈观点提炼、会议录像归纳 |
| 会议录音 / 转录 | Otter.ai / Granola.ai | 实时会议纪要 |
生态影响:研究产物的归宿在哪里
NotebookLM 的产物默认留在 Google 生态里——notebook、Audio Overview、Deep Research 报告都活在 Google Drive 和 Workspace 之中。这对 Google 是好事,但对追求工具中立的研究者是坏事——你的研究素材永远绑死在一个平台。
BibiGPT 的产物则刻意保持中立:所有结果都可导出为 Markdown、可直接同步到 Notion、Obsidian、飞书、本地文件夹。这不是产品偏好,而是研究工具的伦理选择——你的笔记不应该被任何单一平台扣留。
实用规则: 选择研究工具的第一原则是看”输出的可携带性”。AI 模型几年就换一茬,但你的研究笔记应该跟随你一辈子。
BibiGPT 工作流:从”链接+本地文件+字幕”三入口出发
BibiGPT 的研究工作流核心入口是三个,每个对应一类典型研究素材:
入口一:链接(30+ 主流平台)
粘贴任意 YouTube、B 站、小宇宙、Apple Podcasts、抖音、小红书、TED、Bilibili 课程、Coursera 等 30+ 平台的链接,60 秒内得到字幕 + 章节 + 思维导图 + 金句。
这是研究者最常用的入口——大量行业会议、专家访谈、学术讲座都先发在 YouTube 或 B 站,而 NotebookLM Deep Research 看不到这些(它只能抓 Google Search 能索引到的网页摘要)。
入口二:本地文件(最大 2GB 单文件)
公司内部会议录像、付费课程下载视频、田野调查录音文件、播客原始 mp3——这些素材不会出现在公网,NotebookLM Deep Research 永远抓不到,但又是严肃研究最核心的一手数据。
BibiGPT 桌面客户端支持本地完全处理,转写和总结全在你的电脑跑,不上传任何文件到云端。详见 BibiGPT 桌面客户端介绍。
入口三:字幕(多模型转录引擎选择)
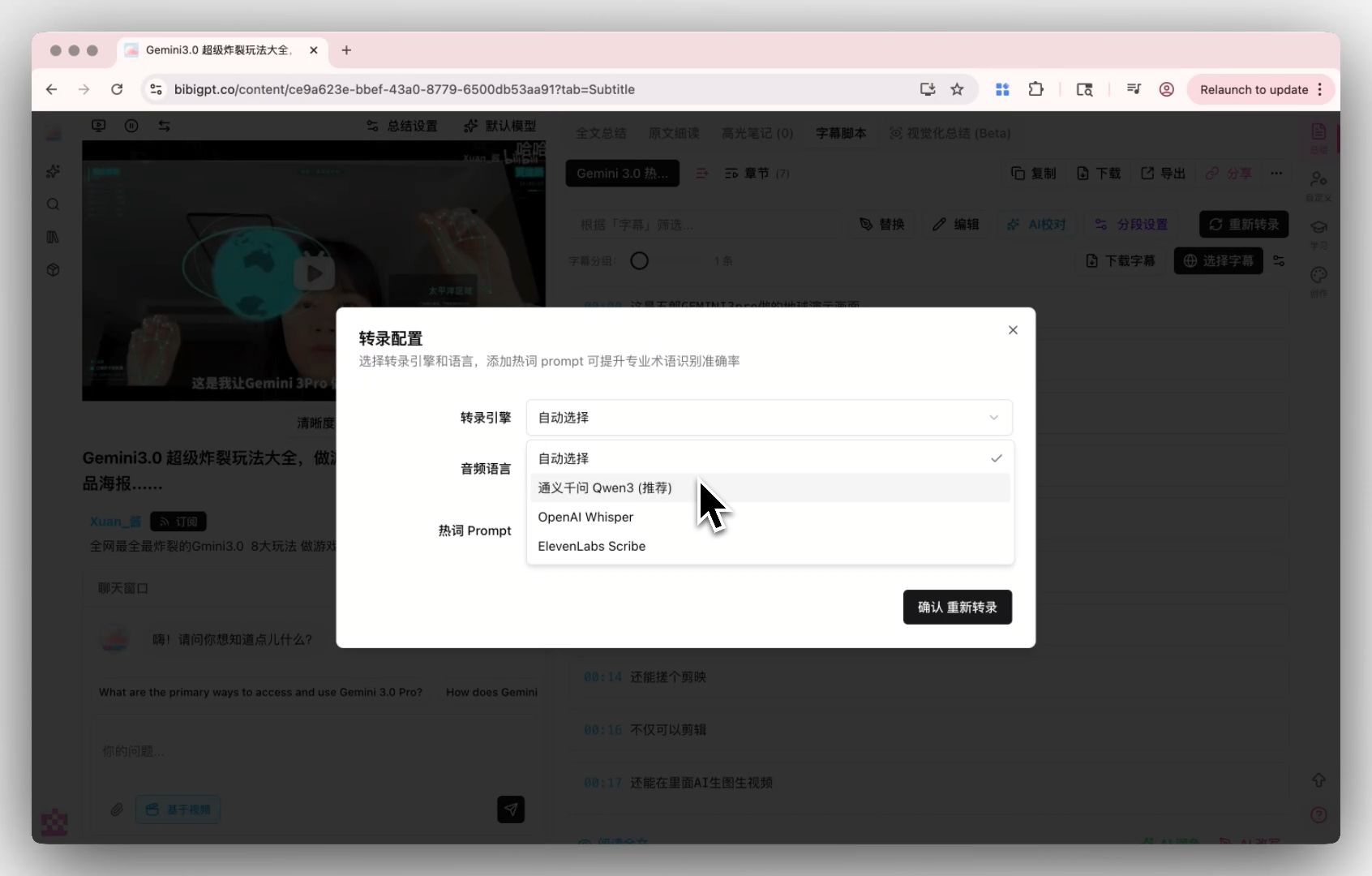
对于音质特殊、行业术语密集的素材(医疗访谈、法律会议、技术深谈),BibiGPT 的 自定义转录引擎 允许选择不同模型转录,匹配你的素材类型——这是任何”通吃模型”工具都无法提供的精度。
对 BibiGPT 用户的实际意义:研究者、学生、企业知识库
1. 学术研究者:双工具并行才是最佳实践
接下来的两年,做严肃学术综述的最佳工作流是:
- NotebookLM Deep Research:扫描已发表的论文、政府报告、行业白皮书等网页文档
- BibiGPT:处理学术 podcast(Tyler Cowen 经济学访谈)、学术 YouTube 频道(3Blue1Brown 数学可视化、Two Minute Papers)、会议录像
研究综述里最稀缺的素材常常不是论文,而是论文作者在播客或讲座里的”未发表观点”——这部分只有 BibiGPT 能拿到。
2. 学生:NotebookLM 处理课件,BibiGPT 处理课程录像
Google AI Educator Series 2026 年免费培训 600 万美国 K12 教师;Gemini 2026 年 5 月起接入 Moodle LMS 全量铺开。这意味着越来越多课件、考试大纲、阅读材料会以 NotebookLM 格式分发。
但课程录像(教授 90 分钟讲座视频)依然是 BibiGPT 的主战场——配合 章节深度阅读 和费曼学习法,把 90 分钟讲座压成 9 分钟精读 + 3 道自测问题。
3. 企业知识库:本地敏感数据走 BibiGPT 桌面端
NotebookLM 进入 Google Workspace Studio 后会成为企业首选的”文档 AI 入口”。但很多企业的会议录像、内部培训视频、私域客户访谈录音绝对不能上传到 Google 云——这部分 BibiGPT 桌面客户端的完全本地处理是唯一合规方案。
BibiGPT 实战搭配:把 NotebookLM Deep Research 当成”读”,BibiGPT 当成”看”
下面这套四步工作流,是把 NotebookLM Deep Research 和 BibiGPT 串起来做一份真正完整的行业研究报告的方法。
步骤一:用 NotebookLM Deep Research 生成文档基线
在 NotebookLM 提一个研究问题(如”过去 6 个月 GenAI 在医疗影像诊断领域的进展”),让 Deep Research 浏览 100-300 个网页,输出一份基础报告。
步骤二:抓取关键音视频素材
NotebookLM 报告里会引用一批关键人物(学者、创业者、监管者)。打开 YouTube 搜索这些人最近 6 个月的访谈/讲座/播客出席记录,把所有相关视频链接收集起来——通常是 10-30 个。
步骤三:BibiGPT 合集归纳总结
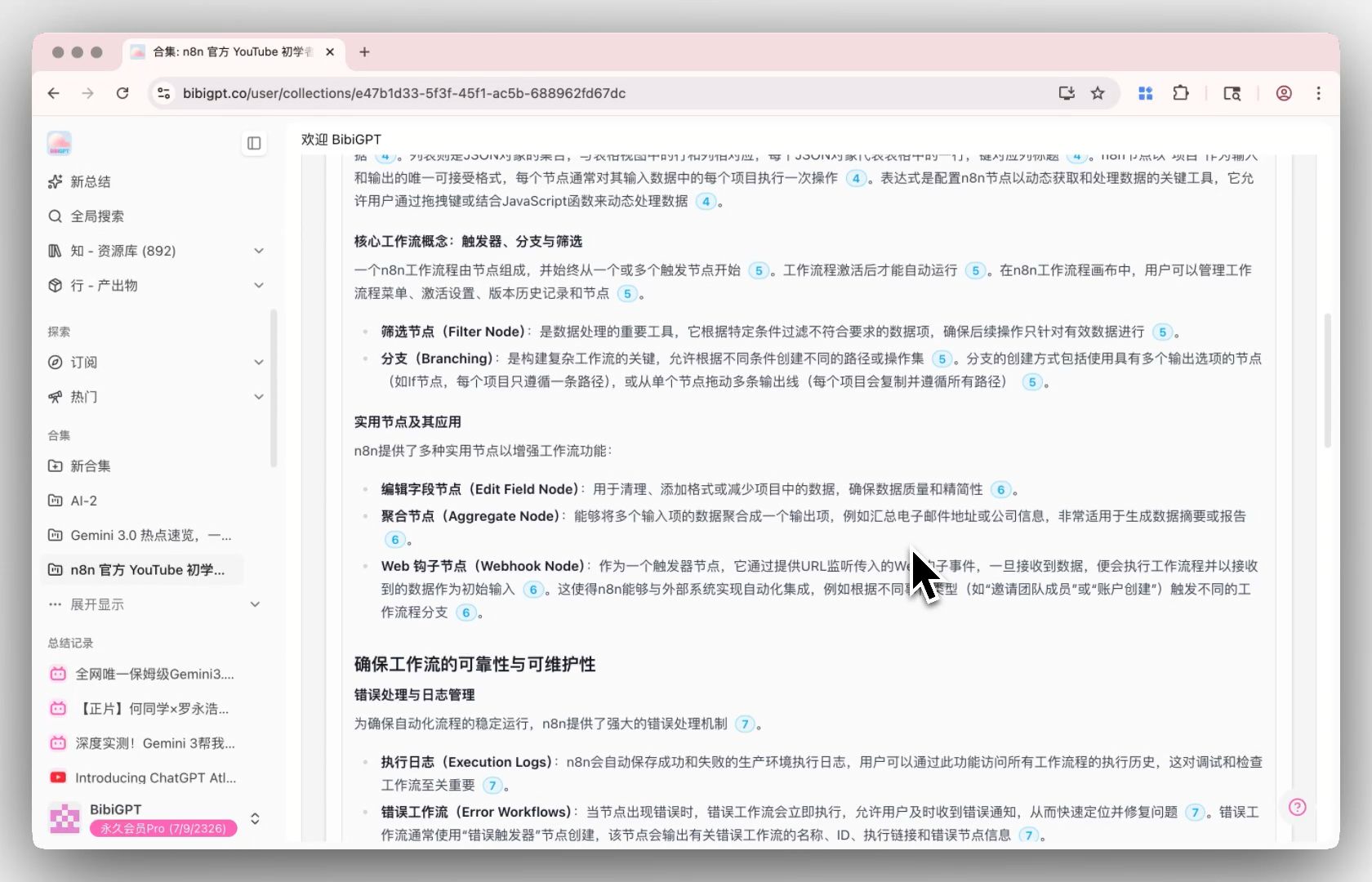
把 10-30 个视频链接一次性丢进 BibiGPT 的 合集归纳总结,AI 不仅每个视频单独总结,还会跨视频生成主题趋势——比如”30 个访谈里有 21 个都提到 FDA 监管路径的新挑战”。这种跨素材主题挖掘是 NotebookLM Deep Research 完全做不到的(它只能看网页静态文档)。
步骤四:合并产出最终报告
把 NotebookLM 的文档报告 + BibiGPT 的音视频合集报告合并到一份 Notion 或 Obsidian 笔记里:
- 文档证据 → NotebookLM 抓取的论文/报告引用
- 一手观点 → BibiGPT 抓取的关键人物访谈金句
- 跨素材趋势 → BibiGPT 合集归纳的主题分析
- 时间线 → 自己整合
这才是 2026 年严肃研究报告的合格基线——文档与音视频双源、可携带、可复核。
实用规则: 严肃研究的本质是”信源多样性”。任何只覆盖一种信源(只看文档 / 只看视频)的工作流都不完整。
前景预测:研究工具的三个分叉点
接下来 12 个月,研究工具市场会沿三个方向继续分化:
- 文档侧的竞争白热化:NotebookLM、Perplexity Deep Research、ChatGPT Deep Research 之间会出现 Google AI Overviews 级别的红海竞争,价格快速下探。
- 音视频侧的高速扩张:BibiGPT、Memories.ai、InfiniteTalk AI 在音视频信源的覆盖广度和深度上会拉开差距。
- 跨源整合工具的出现:未来 12-18 个月一定会出现”原生跨源研究 IDE”——同时消化文档和音视频。BibiGPT 已经在产品方向上明确朝这个目标走,详见 BibiGPT Agent Skill 让 Claude Code 类 AI Agent 调用 BibiGPT 完成跨视频研究。
常见问题 FAQ
1. 为什么不直接全用 NotebookLM?毕竟它是 Google 系?
NotebookLM Deep Research 拿不到 YouTube / B 站 / 小宇宙 / 抖音的内容(即便它能搜到该视频页,也只是看摘要文字,看不到视频本身的内容)。对严肃研究者来说,这等于丢掉一整个维度的信源。BibiGPT 把这个维度补齐。
2. NotebookLM 的 Audio Overview 可以替代 BibiGPT 的播客总结吗?
不能。Audio Overview 是 NotebookLM 把它读过的文档生成一段双人播客给你听——它是”AI 创作了一段音频”,不是”AI 总结了一段已有音频”。BibiGPT 的播客总结是反过来——你提供 90 分钟原始播客,AI 把它压成字幕 + 章节 + 金句 + 思维导图。两件完全不同的事。
3. NotebookLM 进 Workspace Studio 后,BibiGPT 会被边缘化吗?
不会。Workspace Studio 是 Google 把 NotebookLM 推给 G Suite 企业用户的内部渠道——它解决”上 Workspace 的企业用 AI 处理 Google Docs”的需求。完全不影响”中国用户处理小宇宙播客”、“研究者处理 YouTube 学术访谈”、“创作者处理 B 站长视频”这些 BibiGPT 的核心场景。
4. NotebookLM 新增的图片数据源意味着什么?
意味着 NotebookLM 终于支持把 PPT 截图、Infographic、论文 figure 当成数据源——这一直是 BibiGPT 的 AI 视频画面分析 已经在做的事情。所以这次升级更应该解读为”NotebookLM 在补齐 BibiGPT 的视觉分析能力,朝多模态走”,而不是”NotebookLM 包揽一切”。
5. 我现在应该 NotebookLM Pro 和 BibiGPT Plus 都订吗?
如果你每周需要处理 10+ 条文档型研究素材 + 10+ 条音视频素材,是。如果只是单边——纯学生只看课件,纯创作者只看 YouTube——选一边就够。
立刻开始:把 NotebookLM 和 BibiGPT 搭配进你的研究流程
- 在 bibigpt.co 把你最近想研究的一个主题的 10 个关键视频链接做一次合集归纳总结
- 在 notebooklm.google.com 用 Deep Research 模式跑一遍同一主题
- 把两份报告对照着读,找出”文档信源说 X、视频信源说 Y”的差异点——这些差异点常常就是研究最有价值的入口
进阶阅读:
—— BibiGPT 团队