Qwen3.5 Omni 장영상 요약 실측: 10시간 오디오 + 400초 영상 네이티브 처리 vs BibiGPT (2026)
알리바바 Qwen3.5 Omni는 10+ 시간 오디오, 400+ 초 720p 영상, 113개 언어, 256k 컨텍스트를 네이티브로 처리한다. 본 글은 모델 스펙을 풀어 보고, BibiGPT가 이 모델급 오픈소스 기반을 어떻게 최종 사용자 경험으로 포장하는지 비교한다.
Qwen3.5 Omni 장영상 요약 실측: 10시간 오디오 + 400초 영상 네이티브 처리 vs BibiGPT (2026)
목차
- Qwen3.5 Omni가 AI 영상 요약에 주는 의미
- Qwen3.5 Omni 기술 스펙 요약
- 모델 능력에서 최종 사용자 경험까지
- BibiGPT × 오픈 멀티모달 모델 실전
- BibiGPT가 여전히 중요한 이유
- 자주 묻는 질문 (FAQ)
- 마무리
Qwen3.5 Omni가 AI 영상 요약에 주는 의미
핵심 답변: 알리바바 통의는 2026년 3월 30일 Qwen3.5 Omni를 공개했다. 현재 오픈소스 전모달 모델 중 가장 강력한 축에 속하며 10+ 시간 오디오, 400+ 초 720p 영상, 113개 언어 ASR, 256k 컨텍스트를 네이티브로 지원한다. AI 영상 요약의 "모델 상한"이 프론티어 폐쇄 모델 수준으로 밀려 올라갔다. 최종 사용자에게는 기반 계층의 업그레이드에 가깝다 — 오픈소스 모델이 BibiGPT 같은 AI 비서에게 더 많은 선택지를 주고, 이는 더 길고 더 정확하며 더 많은 언어를 더 저렴하게 요약할 수 있다는 뜻이다.
试试粘贴你的视频链接
支持 YouTube、B站、抖音、小红书等 30+ 平台
지난 1년간 "영상이 너무 길어서 AI가 다 못 본다", "비영어 전사 오류가 심하다", "요약이 30분 지나면 끊긴다"는 불만을 가졌다면 Qwen3.5 Omni 세대의 전모달 모델이 그 병목을 직접 해결해 준다. 이 글은 세 가지 시각에서 풀어 본다: 모델 스펙, 실제 돌리는 데 필요한 것, BibiGPT 같은 제품을 통해 사용자에게 어떻게 도달하는가.
Qwen3.5 Omni 기술 스펙 요약
핵심 답변: Qwen3.5 Omni의 헤드라인은 "하나의 모델로 텍스트/이미지/오디오/영상 전 모달을 커버"하며 10+ 시간 오디오 네이티브 입력, 400+ 초 720p 영상 프레임 이해, 256k 토큰 컨텍스트, 113개 언어 ASR, Qwen 시리즈의 Thinker/Talker 듀얼 브레인 아키텍처를 유지한다.
MarkTechPost의 알리바바 Qwen 공식 발표 커버리지를 기반으로 핵심 스펙을 정리하면:
| 축 | 스펙 | 영상 요약에 미치는 영향 |
|---|---|---|
| 오디오 입력 | 10+ 시간 네이티브 | 장편 팟캐스트·세미나·온종일 강의 완전 커버 |
| 영상 입력 | 400+ 초 720p | 화면과 음성을 결합한 장면 인식 요약 |
| 언어 ASR | 113개 언어 | 현지화·국경 간 회의 |
| 컨텍스트 | 256k 토큰 | 장편 영상 + 참고 자료 + 후속 질문 일괄 수용 |
| 아키텍처 | Thinker / Talker 듀얼 브레인 | 추론과 음성 출력 분리, 실시간 상호작용 자연스러움 |
| 라이선스 | Apache 2.0 | 상업 이용·파인튜닝·온프레미스 배포 허용 |
GPT·Claude·Gemini·Qwen 시리즈의 동일 영상 벤치마크를 보고 싶다면 2026 AI 음성·영상 요약 도구 최고 평가를 참고하자.
오픈소스 경로의 진짜 가치
Qwen3.5 Omni가 공개된 그 주에 InfiniteTalk AI, Gemma 4, Llama 4 Scout, Microsoft MAI도 새 모델을 냈다. 오픈 멀티모달 분야가 "월 단위 릴리스" 리듬에 들어갔다. 사용자에게 이것이 뜻하는 바는:
- 장영상 요약이 더 이상 유료 특권이 아니다 — 오픈 기반은 제품 가격 인하를 가능케 한다
- 비영어 영상이 드디어 구원받는다 — 113 언어 커버리지로 스페인어 팟캐스트·일본어 강의·한국어 라이브 모두 가용권으로
- 프라이버시 민감 시나리오의 선택지 확대 — Apache 2.0으로 온프레미스 배포 허용
모델 능력에서 최종 사용자 경험까지
핵심 답변: 모델 스펙은 천장일 뿐이다. 최종 사용자 경험은 엔지니어링·플랫폼 적응·상호작용 설계·안정성에 달려 있다. Qwen3.5 Omni의 256k 컨텍스트는 논문에서 멋지지만, Bilibili 링크를 붙여넣고 최종 요약 텍스트까지 가려면 URL 파싱, 자막 추출, 하드 자막 OCR, 분절 전처리, 프롬프트 엔지니어링, 렌더링, 내보내기 경로를 거쳐야 한다.
제대로 된 AI 영상 비서는 최소 7가지 엔지니어링 문제를 해결한다:
- URL 파싱 — YouTube / Bilibili / TikTok / Xiaohongshu / 팟캐스트 플랫폼마다 다른 URL 형식과 안티스크래핑 대응
- 자막 소싱 — CC 있으면 추출, 없으면 ASR, 하드 자막은 OCR
- 장콘텐츠 청크 — 256k도 10시간 오디오에선 한계. 스마트 청크 + 요약 병합 필요
- 줄 단위 번역 — 자막 번역은 타임스탬프를 보존해야지, 문단 통째로 번역해선 안 됨
- 구조화 출력 — 챕터 / 타임스탬프 / 요약 / 마인드맵, 안정된 프롬프트 엔지니어링 필요
- 내보내기 호환 — SRT / Markdown / PDF / Notion / 위챗 포맷 각각 규범
- 안정성과 비용 — 10시간 팟캐스트 한 번 돌리면 비싸다. 캐싱·큐·우선순위 필요
즉 프론티어 모델만으론 부족하다. 사용자는 가중치 파일이 아니라 "붙여넣기만 하면 작동"하는 제품을 원한다.
BibiGPT × 오픈 멀티모달 모델 실전
핵심 답변: BibiGPT는 100만 명 이상의 사용자가 신뢰하는 AI 음성/영상 비서로, 500만 건 이상의 AI 요약을 생성했다. Qwen3.5 Omni급 오픈 모델의 시대에 BibiGPT의 역할은 "프론티어 모델의 능력을 최종 사용자의 원클릭 경험으로 포장"하는 것. 사용자는 모델 이름·배포 환경·청크 전략을 알 필요 없이 링크만 붙이면 된다.
URL에서 구조화 요약까지
看看 BibiGPT 的 AI 总结效果
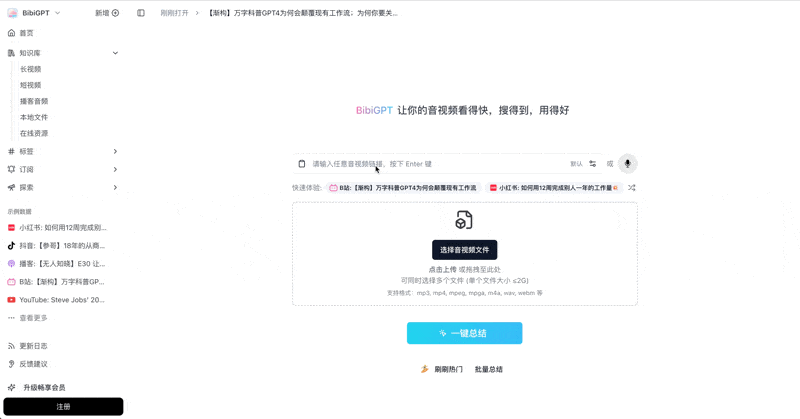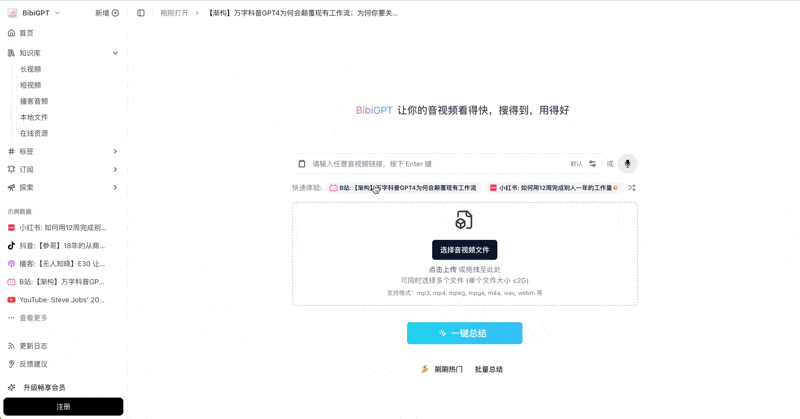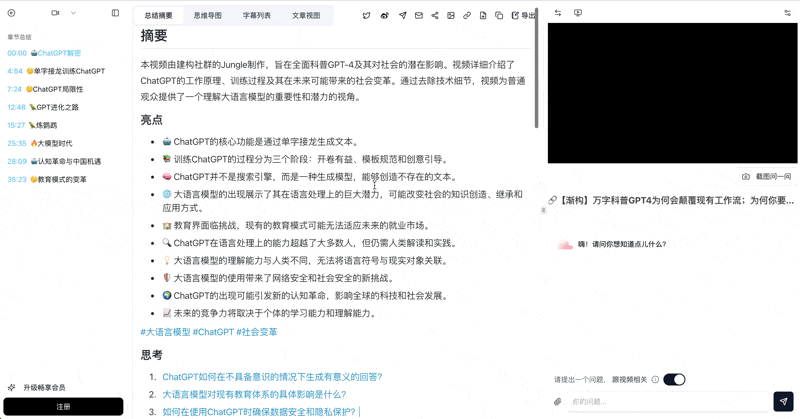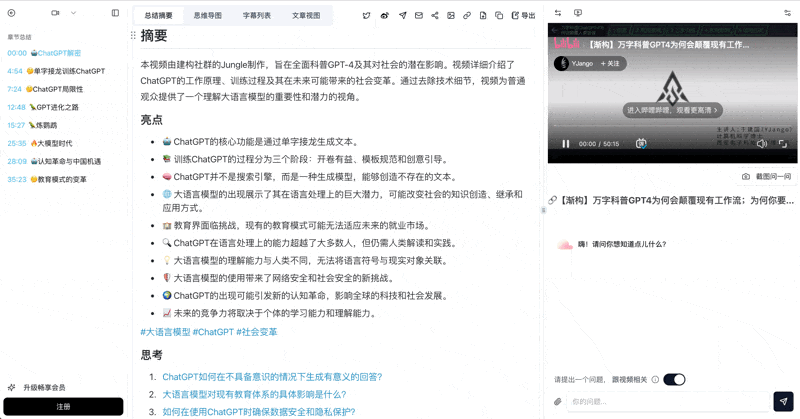
Bilibili: GPT-4와 워크플로우 혁명
GPT-4가 업무 방식을 어떻게 혁신하는지 심층 분석한 과학 해설 영상. 모델 내부, 학습 단계, 사회적 변화를 다룹니다.
3시간짜리 Bilibili 기술 강연을 BibiGPT로 요약하는 흐름:
- aitodo.co를 열고 링크를 붙인다
- 시스템이 자동으로 자막을 가져온다 (CC 있으면 사용, 없으면 ASR)
- 스마트 청크 + 분절 요약 + 챕터 병합
- 약 2분 후: 전체 전사, 챕터 요약, 마인드맵, 타임스탬프가 있는 AI 대화
같은 흐름이 플랫폼을 가로질러 재사용된다 — Bilibili 영상 요약, YouTube 영상 요약, 팟캐스트 생성.
장영상 UX의 핵심 엔지니어링
장영상은 이 세대 모델의 강점이지만 "4시간 팟캐스트를 끊김 없이 요약"하려면 모델 컨텍스트 길이만으론 부족하다:
- 스마트 자막 분절 — 174개의 조각 자막을 38개의 가독성 좋은 문장으로 병합, 컨텍스트 절약
- 챕터 딥 리딩 — 챕터 요약·AI 윤색·자막을 한 화면에 통합한 집중 리더
- AI 영상 대화 — 타임스탬프 추적이 가능한 출처 인용
- 시각 분석 — 키프레임 스크린샷 + 내용 분석으로 소셜 카드·숏폼·슬라이드 생성
 AI 영상 기사화 생성 화면
AI 영상 기사화 생성 화면
BibiGPT가 여전히 중요한 이유
핵심 답변: Qwen3.5 Omni는 기반 모델이고, BibiGPT는 제품 경험이다. 둘은 경쟁이 아니라 상호 보완이다. BibiGPT의 차별화는 네 층에 걸친다: 30+ 플랫폼 커버, 완결된 자막 파이프라인, 중국어 창작자 워크플로 심화, Notion/Obsidian 노트 생태계 연동.
1. 30+ 플랫폼 + 안티스크래핑 엔지니어링
오픈 모델은 Bilibili·Xiaohongshu·Douyin 스크래핑을 해결하지 않는다. BibiGPT는 플랫폼 어댑터에 지속 투자한다 — Qwen3.5 Omni 가중치를 직접 다운로드한다고 재현할 수 없는 공학적 가치.
2. 완결된 자막 파이프라인
추출·번역·분절·하드 자막 OCR·내보내기까지 폐쇄 루프. "요약만 주세요"가 아니라 "자막 + 번역 + SRT + AI 재작성 한 번에"로 매뉴얼 작업 5-8회를 줄인다.
3. 중국어 창작자 워크플로 심화
위챗 기사 재작성, Xiaohongshu 홍보 이미지, 숏폼 영상 생성 — 창작자의 고빈도 요구. 원시 모델 자체는 "위챗으로 내보내기"를 해결하지 않는다. BibiGPT의 AI 영상 기사화는 창작자의 재배포 워크플로를 직격한다.
4. 노트 도구 심층 연동
Notion·Obsidian·Readwise·Cubox — BibiGPT는 여러 노트 동기화 커넥터를 내장한다. 링크를 붙이면 요약이 개인 지식 베이스로 흘러 들어간다. 원시 모델 호출이 못 하는 생태계 가치.
자주 묻는 질문 (FAQ)
Q1: Qwen3.5 Omni는 GPT-5나 Gemini 3보다 강한가? A: "오픈 전모달" 세부 분야에서는 현재 최강급. 10시간 오디오와 113 언어 ASR이 프론티어 폐쇄 모델과 경쟁할 수준. 폐쇄 모델 간 비교는 NotebookLM vs BibiGPT 참고.
Q2: Qwen3.5 Omni로 직접 영상 요약을 돌릴 수 있나? A: 가능. Apache 2.0은 상업 이용과 온프레미스를 허용. 다만 GPU 비용, URL 파싱, 자막 소싱, 장영상 청크, 구조화 출력까지 한 묶음의 엔지니어링을 해결해야 한다. 없다면 BibiGPT 같은 패키지 제품이 더 가성비 좋다.
Q3: BibiGPT가 Qwen3.5 Omni를 쓰나? A: BibiGPT는 시나리오와 비용에 따라 모델을 동적 선택한다. 핵심 원칙은 "사용자에게 가장 안정·정확·빠른 경험", 구체적 백엔드는 최종 사용자에게 투명하다.
Q4: 10시간 오디오를 한 번에 돌릴 수 있나? A: 스펙상 가능. 실제 UX는 구현에 달려 있다. BibiGPT는 스마트 청크 + 분절 요약 + 병합 전략으로 3-5시간 팟캐스트를 2-3분 내 안정 산출. 10시간 초장편은 분할 업로드를 권장.
Q5: 오픈 모델이 BibiGPT 같은 제품을 대체할까? A: 오히려 반대. 오픈 모델이 강해질수록 제품화 계층의 가치가 부각된다. 대부분의 사용자는 가중치가 아니라 "붙여넣기만 하면 되는" 경험을 원한다. 모델 강화는 BibiGPT를 더 빠르고 정확하고 저렴하게 만든다.
마무리
Qwen3.5 Omni가 예고하는 오픈 멀티모달 물결은 "AI 영상 요약"을 사치품에서 생필품으로 바꾸고 있다. 모델 천장은 계속 올라가지만, 최종 사용자에게 결정적인 변수는 "링크를 붙이면 되는가"라는 제품화 계층.
연구자·창작자·학생·지식 노동자라면 가중치 추격보다 잘 포장된 AI 영상 비서를 쓰는 것이 최고의 레버리지다:
- 🎬 aitodo.co에서 영상 링크 붙여넣기
- 💬 배치 API 접근이 필요하다면 BibiGPT Agent Skill 개요 참고
- 🧠 내장 동기화로 영상 지식을 Notion / Obsidian에 직접 반영
BibiGPT 팀