Kann Gemini 3.1 Flash TTS BibiGPT ersetzen? Warum „KI spricht" und „KI versteht" verschiedene Probleme sind
Kann Gemini 3.1 Flash TTS BibiGPT ersetzen? Warum „KI spricht“ und „KI versteht“ verschiedene Probleme sind
Kurze Antwort: Gemini 3.1 Flash TTS lässt KI günstiger und ausdrucksstärker sprechen. Gemini Embedding 2 GA macht semantischen Abruf produktionsreif. BibiGPT löst den schwersten vorgelagerten Schritt — ein einstündiges Video, einen Podcast oder ein Meeting in lesbares, durchsuchbares, neu mischbares Wissen zu verwandeln. Synthese (TTS) + Retrieval (Embedding) + Verstehen (ASR+LLM) sind drei komplementäre Dinge. Dieser Beitrag trennt sie und zeigt, wie sie sich komponieren.
Inhaltsverzeichnis
- Was Gemini 3.1 Flash TTS bringt
- Warum Gemini Embedding 2 GA wichtig ist
- Rollenvergleich entlang der Pipeline
- Wo BibiGPT sitzt: „verstehen und produzieren“ per Klick machen
- Kombinierter Workflow: TTS + Embedding + BibiGPT
- FAQ
Was Gemini 3.1 Flash TTS bringt
Laut Google Gemini API Changelog (2026-04-15) konzentriert sich Gemini 3.1 Flash TTS Preview auf drei Säulen: niedrige Kosten, starke Ausdruckskraft und Steuerbarkeit. „Steuerbar“ bedeutet, dass natürlichsprachliche Prompts Ton, Tempo, Emotion und sogar Akzent abstimmen können — ein bedeutender Schritt nach oben für Podcast-Produzenten, Hörbuch-Macher und Video-Voiceover-Creator.
Aber hier die Schlüsselunterscheidung: TTS synthetisiert bereits geschriebenen Text in Audio. Sein Eingang ist Text, sein Ausgang ist Audio. Es löst „KI spricht“; es löst nicht „KI versteht eine rohe Aufnahme“. Das wird leicht verwechselt.
Warum Gemini Embedding 2 GA wichtig ist
Am 2026-04-22 ging Gemini Embedding 2 GA. Embedding-Modelle projizieren Text in Vektoren und ermöglichen semantische Suche — z. B. „finde die Meeting-Notizen, in denen wir Q2-Wachstumsziele diskutiert haben“ über tausend Dokumente.
Embedding löst „finde, was relevant ist“. Es nimmt an, dass Sie bereits Text zum Embedden haben. Roh-Video, Podcasts und Meeting-Aufnahmen sind Audio und visuelle Frames — kein Text. Bevor Embedding also seinen Job machen kann, brauchen Sie hochwertige Transkripte und Zusammenfassungen.
Rollenvergleich entlang der Pipeline
Drei grundlegend verschiedene Schritte:
| Fähigkeit | Eingang | Ausgang | Löst |
|---|---|---|---|
| TTS (Gemini 3.1 Flash TTS) | Text | Audio | KI liest Untertitel laut |
| Embedding (Gemini Embedding 2) | Text | Vektor | Semantische Suche über bestehenden Text |
| ASR + LLM-Zusammenfassung (BibiGPT) | Audio-/Video-Datei oder URL | Untertitel + strukturierte Zusammenfassung + Mindmap + Karten | Ein einstündiges Video in 5 Minuten lesbaren Inhalt komprimieren |
Mit anderen Worten: Sie brauchen etwas wie BibiGPT, um rohes A/V zuerst in strukturierten Text zu verwandeln; erst dann haben TTS und Embedding etwas, womit sie arbeiten können.
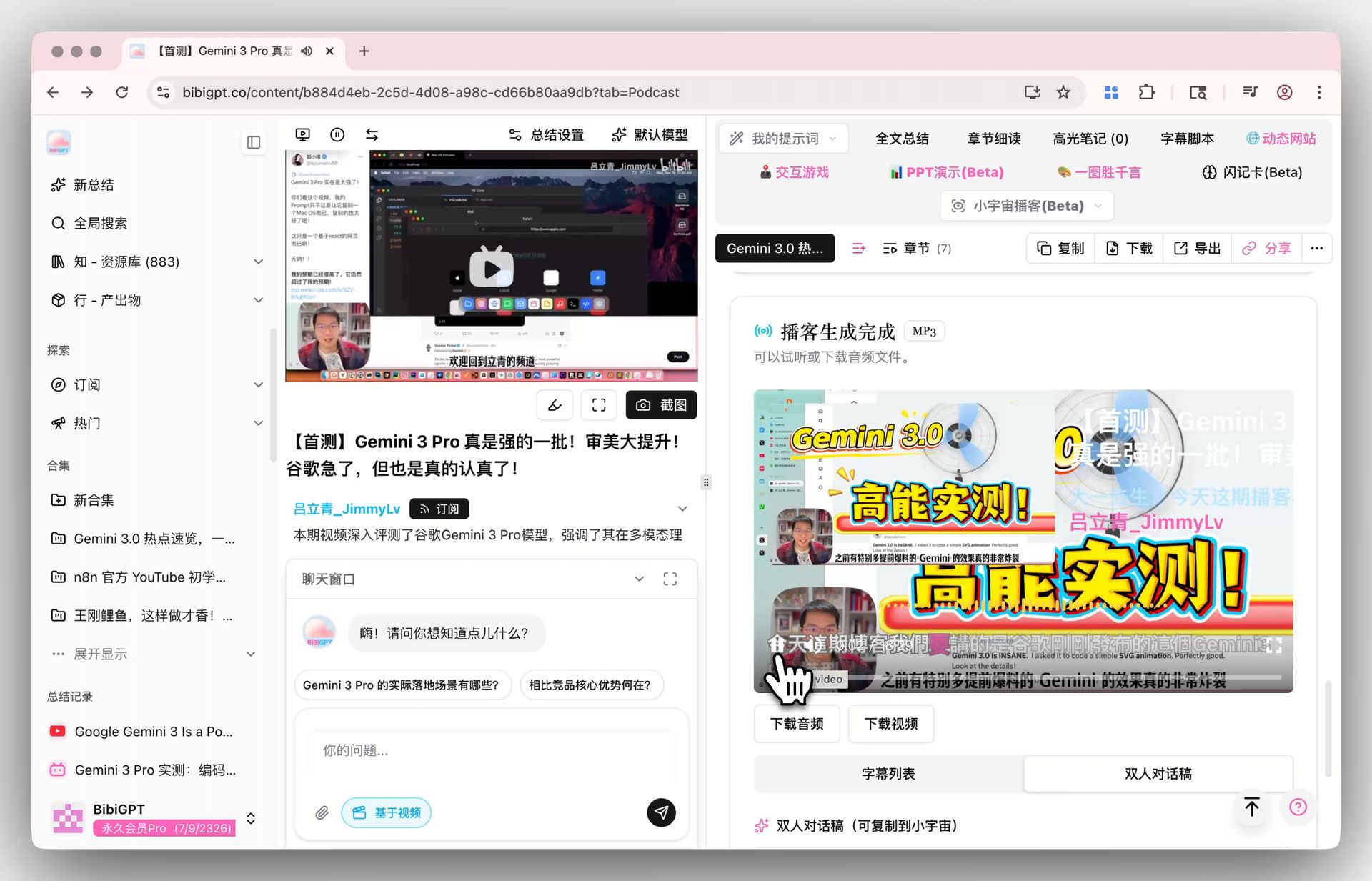
Wo BibiGPT sitzt: „verstehen und produzieren“ per Klick machen
BibiGPT ist ein erstklassiger KI-Audio/Video-Assistent mit 1M+ Nutzern, 5M+ KI-Zusammenfassungen und Unterstützung für 30+ wichtige Plattformen. Wir konzentrieren uns auf den schwersten Teil der Pipeline: Verstehen und Produzieren.
- KI Podcast-Zusammenfassung: ein zweistündiges Interview in 5 Minuten lesbaren Inhalt mit Zeitstempel-Links komprimieren
- KI YouTube-Zusammenfassung: einen Link einfügen, in 30 Sekunden kapitelbewusste Zusammenfassung + Mindmap erhalten
- Visuelle Inhaltsanalyse: nicht nur Untertitel — BibiGPT liest auch Folien, Diagramme und Frames, ideal für Produkteinführungen und Vorlesungen

Ausgaben umfassen Untertitel, Zusammenfassungen, Mindmaps, KI-Q&A, Xiaohongshu-/WeChat-Umschreibungen und PPT-Extraktion — Dinge, die weder TTS noch Embedding direkt machen.
Kombinierter Workflow: TTS + Embedding + BibiGPT
Eine reale End-zu-End-Schleife:
- Verstehen: Einen 90-minütigen Launch-Event-Link in BibiGPT einfügen → vollständige Untertitel, kapitelweise Zusammenfassung und Ideenkarten erhalten
- Abrufen: Zusammenfassung und Transkript-Chunks in einen Vektor-Store embedden (Gemini Embedding 2 oder pgvector) → beim nächsten Mal nach Bedeutung suchen
- Synthetisieren: Die strukturierte Zusammenfassung in Gemini 3.1 Flash TTS einspeisen → eine Version „5-Minuten-Audio-Briefing“ für das Hören beim Pendeln produzieren
BibiGPT übernimmt den schwersten vorgelagerten Schritt; TTS ist die Last-Mile-Verpackung; Embedding ist die mittlere Retrieval-Schicht. Drei Schichten, komplementär, nicht konkurrierend.
Wenn Sie Video in einen Artikel verwandeln möchten, siehe How to repurpose video to blog posts; für zweisprachiges Untertitel-Einbrennen siehe AI subtitle translation bilingual workflow.
FAQ
F1: Kann Gemini 3.1 Flash TTS ein Video direkt in eine Zusammenfassung verwandeln? Nein. TTS behandelt nur Text → Audio. Um eine Zusammenfassung aus einem Video abzuleiten, brauchen Sie ASR (Spracherkennung) + LLM-Zusammenfassung — das macht BibiGPT.
F2: Mit Gemini Embedding 2, brauche ich BibiGPT trotzdem? Embedding erfordert Text. Roh-Video/Podcast ist Audio — BibiGPT verwandelt es zuerst in strukturierten Text.
F3: Welche Modelle nutzt BibiGPT? BibiGPT routet über mehrere Modelle (Gemini, GPT, Claude, DeepSeek) und lässt Nutzer frei wechseln. Siehe BibiGPT integrates DeepSeek V4 1M context.
F4: Macht eine TTS-„Audio-Zusammenfassung“ Sinn? Sehr, beim Pendeln, Trainieren, Hausarbeit — eine 5-minütige Audio-Zusammenfassung eines langen Videos ist ein bewährtes Konsummuster.
F5: Kann sich ein einzelner Entwickler diese Pipeline leisten? Ja. BibiGPT übernimmt das Verstehen mit einem Abonnement; Gemini Embedding und TTS sind pay-per-call und für persönliche Nutzung günstig.
Die knappe Ressource im KI-Zeitalter sind nicht Modelle — es ist die Geschwindigkeit, mit der Sie Inhalte konsumieren. Mehr Modelle, günstigeres TTS, besseres Embedding — sie alle erhöhen den Bedarf nach dem Schritt davor: das Verstehen roher Langform-Inhalte. Dieser Schritt ist BibiGPT. Fügen Sie einen langen Video- oder Podcast-Link ein und probieren Sie es jetzt: aitodo.co.
BibiGPT Team