¿Puede Gemini 3.1 Flash TTS reemplazar a BibiGPT? Por qué "la IA habla" y "la IA entiende" son problemas distintos
¿Puede Gemini 3.1 Flash TTS reemplazar a BibiGPT? Por qué “la IA habla” y “la IA entiende” son problemas distintos
Respuesta corta: Gemini 3.1 Flash TTS hace que la IA hable de forma más asequible y expresiva. Gemini Embedding 2 GA lleva la recuperación semántica a calidad de producción. BibiGPT resuelve el paso upstream más difícil — convertir un video, podcast o reunión de una hora en conocimiento legible, buscable y remixable. Síntesis (TTS) + Recuperación (Embedding) + Comprensión (ASR+LLM) son tres cosas complementarias. Este post las separa y muestra cómo se componen.
Tabla de contenidos
- Qué trae Gemini 3.1 Flash TTS
- Por qué importa Gemini Embedding 2 GA
- Comparativa de roles a lo largo del pipeline
- Dónde se ubica BibiGPT: hacer “entender y producir” un solo clic
- Flujo combinado: TTS + Embedding + BibiGPT
- FAQ
Qué trae Gemini 3.1 Flash TTS
Según el changelog de Google Gemini API (2026-04-15), Gemini 3.1 Flash TTS Preview se enfoca en tres pilares: bajo costo, fuerte expresividad y controlabilidad. “Controlable” significa que prompts en lenguaje natural pueden ajustar tono, ritmo, emoción e incluso acento — un salto significativo para productores de podcast, fabricantes de audiolibros y creadores de voz en off de video.
Pero aquí va la distinción clave: TTS sintetiza audio a partir de texto ya escrito. Su entrada es texto, su salida es audio. Resuelve “la IA habla”; no resuelve “la IA entiende una grabación cruda”. Esto se confunde fácil.
Por qué importa Gemini Embedding 2 GA
El 2026-04-22, Gemini Embedding 2 pasó a GA. Los modelos de embedding proyectan texto en vectores y habilitan búsqueda semántica — por ejemplo “encuentra las notas de reunión donde discutimos los objetivos de crecimiento del Q2” sobre mil documentos.
El embedding resuelve “encontrar lo relevante”. Asume que ya tienes texto que embeber. Los videos crudos, podcasts y grabaciones de reunión son audio y frames visuales — no texto. Así que antes de que Embedding pueda hacer su trabajo, necesitas transcripciones y resúmenes de calidad.
Comparativa de roles a lo largo del pipeline
Tres pasos fundamentalmente distintos:
| Capacidad | Entrada | Salida | Resuelve |
|---|---|---|---|
| TTS (Gemini 3.1 Flash TTS) | Texto | Audio | La IA lee subtítulos en voz alta |
| Embedding (Gemini Embedding 2) | Texto | Vector | Búsqueda semántica sobre texto existente |
| ASR + resumen LLM (BibiGPT) | Archivo audio/video o URL | Subtítulos + resumen estructurado + mapa mental + tarjetas | Comprime un video de una hora en 5 minutos de contenido legible |
Dicho de otro modo: necesitas algo como BibiGPT para convertir A/V crudo en texto estructurado primero; solo entonces TTS y Embedding tienen con qué trabajar.
Dónde se ubica BibiGPT: hacer “entender y producir” un solo clic
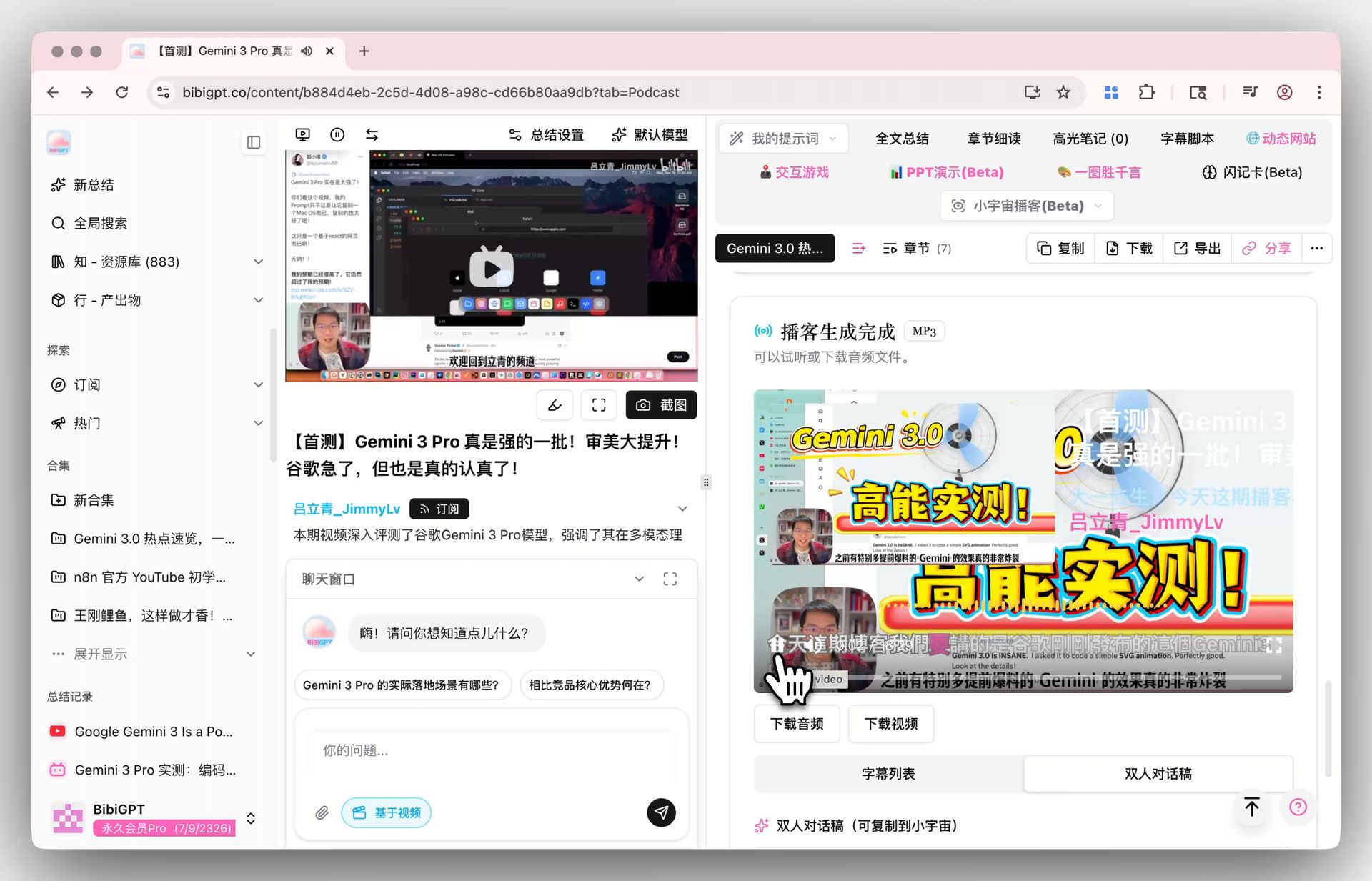
BibiGPT es un asistente de audio/video con IA top con 1M+ usuarios, 5M+ resúmenes IA y soporte para 30+ plataformas mayores. Nos enfocamos en la parte más difícil del pipeline: entender y producir.
- Resumen de podcast con IA: comprime una entrevista de dos horas en 5 minutos de contenido legible con enlaces con timestamp
- Resumen de YouTube con IA: pega un enlace, obtén resumen consciente de capítulos + mapa mental en 30 segundos
- Análisis de contenido visual: no solo subtítulos — BibiGPT también lee diapositivas, gráficos y frames, ideal para lanzamientos de producto y clases

Las salidas incluyen subtítulos, resúmenes, mapas mentales, Q&A con IA, reescrituras para Xiaohongshu/WeChat y extracción de PPT — cosas que ni TTS ni Embedding hacen directamente.
Flujo combinado: TTS + Embedding + BibiGPT
Un ciclo real de extremo a extremo:
- Entender: pega un enlace de evento de lanzamiento de 90 minutos en BibiGPT → obtén subtítulos completos, resumen capitulado y tarjetas de ideas
- Recuperar: embebe el resumen y los chunks de transcripción en un vector store (Gemini Embedding 2 o pgvector) → la próxima vez puedes buscar por significado
- Sintetizar: alimenta el resumen estructurado a Gemini 3.1 Flash TTS → produce una versión “audio brief de 5 minutos” para escuchar en el commute
BibiGPT maneja el paso upstream más difícil; TTS es el empaquetado de última milla; Embedding es la capa intermedia de recuperación. Tres capas, complementarias, no competitivas.
Si quieres convertir video en artículo, ver Cómo reciclar video a posts de blog; para burn-in de subtítulos bilingües, ver Flujo de traducción de subtítulos bilingües con IA.
FAQ
Q1: ¿Gemini 3.1 Flash TTS puede convertir un video en resumen directamente? No. TTS solo maneja texto → audio. Para sacar un resumen de un video necesitas ASR (reconocimiento de voz) + resumen con LLM — eso es lo que hace BibiGPT.
Q2: Con Gemini Embedding 2, ¿sigo necesitando BibiGPT? Embedding requiere texto. El video/podcast crudo es audio — BibiGPT lo convierte primero en texto estructurado.
Q3: ¿Qué modelos usa BibiGPT? BibiGPT enruta entre múltiples modelos (Gemini, GPT, Claude, DeepSeek) y deja al usuario cambiar libremente. Ver BibiGPT integra DeepSeek V4 contexto 1M.
Q4: ¿Tiene sentido un “resumen en audio” hecho con TTS? Mucho — para commute, entrenamiento, tareas — un recap de audio de 5 minutos de un video largo es un patrón de consumo probado.
Q5: ¿Puede un desarrollador individual permitirse este pipeline? Sí. BibiGPT cubre la comprensión con suscripción; Gemini Embedding y TTS son pay-per-call y baratos para uso personal.
El recurso escaso en la era IA no son los modelos — es la velocidad a la que consumes contenido. Más modelos, TTS más barato, mejor Embedding — todos aumentan la demanda del paso que va primero: entender contenido largo crudo. Ese paso es BibiGPT. Pega un enlace de video o podcast largo y pruébalo ya: aitodo.co.
BibiGPT Team