How to Batch Summarize YouTube Playlists with AI: Complete BibiGPT Guide (2026)
How to Batch Summarize YouTube Playlists with AI: Complete BibiGPT Guide (2026)
Table of Contents
- Why You Need Batch Playlist Summarization
- BibiGPT Collection Summary Features Explained
- Step-by-Step: Batch Summarize a YouTube Playlist
- Bilibili Collections: Same Workflow, Same Power
- Advanced Use Cases for Batch Summarization
- FAQ
- Conclusion: From Watching Every Video to Systematic Learning
Why You Need Batch Playlist Summarization
When you face a 20-episode YouTube tutorial series or a Bilibili learning collection, watching each video and taking notes manually requires dozens of hours. BibiGPT’s collection summary feature processes entire playlists in one click, generating cross-video structured summaries and mind maps that compress hours of content into a 5-minute knowledge overview.
This is not a nice-to-have convenience feature. It is a core workflow need in the age of information overload. Consider these real scenarios:
- Online Courses: A complete Coursera or Udemy course has 30-50 video lectures, but you may only need a few key concepts
- Technical Tutorials: YouTube programming tutorial series often run 20+ episodes — watching them all takes an entire day
- Industry Analysis: A finance creator’s analysis series contains critical data points scattered across multiple videos
- Meeting Recordings: Multiple meeting recordings need to be mined for decisions and action items
The old approach: open each video, scrub through, take notes, then manually synthesize. The new approach: paste the playlist link into BibiGPT and let AI do the heavy lifting.
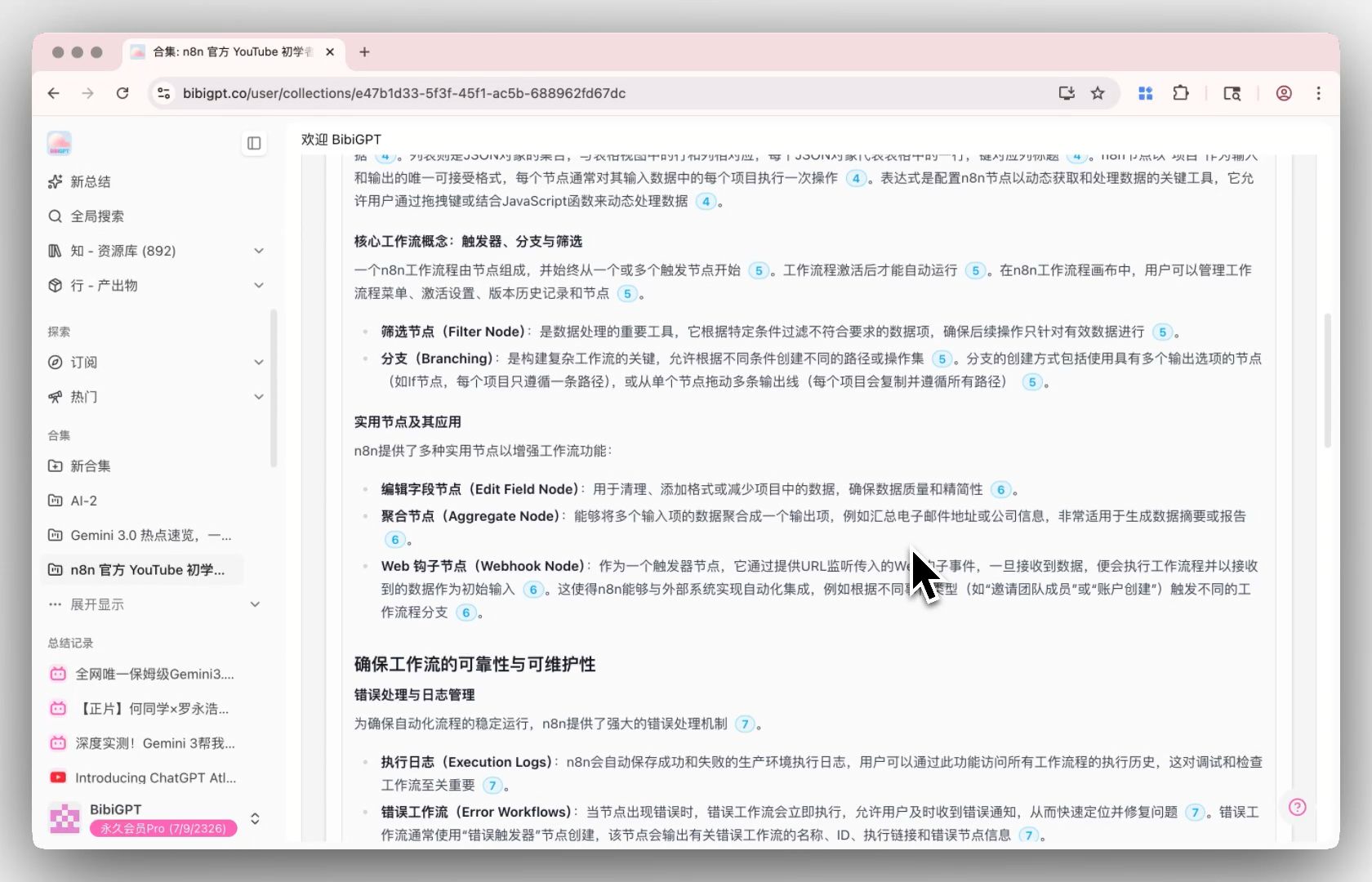
BibiGPT Collection Summary Features Explained
BibiGPT’s collection summary is not a simple concatenation of individual video summaries. It performs cross-video intelligent analysis across the entire series, extracting the global knowledge structure and producing a genuinely valuable series-level summary — complete with structured text, expandable source references, and mind maps.
Core capabilities:
Collection-Level Summary
All videos in a playlist or collection are analyzed as a single knowledge unit. The AI generates:
- Global Structured Summary: Not a stack of per-video summaries, but a cross-video extraction of core themes, logical chains, and key knowledge points
- Expandable Source Citations: Every insight is tagged with the specific video and timestamp it came from, making verification easy
- Series Mind Map: Visualizes the entire playlist’s knowledge structure in one map
Collection Detail View
A sidebar lets you quickly switch between individual videos in the collection without navigating away. You can move freely between the global overview and deep-dive summaries for specific videos.
Collection AI Chat
Use the entire collection as a knowledge base for AI conversation. You can ask cross-video questions like “How do the perspectives in episode 3 and episode 7 differ on concept X?” — the AI retrieves across all videos and provides a synthesized answer.
Bulk Export
Export your processed collection in Markdown, ZIP, or JSON format. Seamlessly integrate with Notion, Obsidian, or any knowledge management system.
Step-by-Step: Batch Summarize a YouTube Playlist
Here is the complete workflow for batch summarizing a YouTube playlist with BibiGPT. With 1M+ active users and 5M+ AI summaries generated, BibiGPT makes this process as simple as three steps.
Step 1: Get the Playlist URL
Open the target playlist on YouTube and copy the full URL from your browser’s address bar. The link format is typically https://www.youtube.com/playlist?list=PLxxxxxx.
Step 2: Paste into BibiGPT
Open BibiGPT and paste the playlist URL into the input field. BibiGPT automatically detects that it is a playlist and displays all videos in the collection.
Need to process multiple links at once? Use the multi-link batch summarize feature — press Shift+Enter to add new lines and paste multiple video URLs simultaneously. BibiGPT processes all links in parallel.
Step 3: Get the Collection Summary
After starting the process, BibiGPT will:
- Automatically extract subtitles from each video
- Generate individual AI summaries for each video
- Perform cross-video collection-level analysis
- Output a structured series summary + mind map
Step 4: Deep Interaction (Optional)
- Use Collection AI Chat to ask follow-up questions about the series content
- Switch to the Detail View to examine a specific video’s in-depth summary
- Bulk export everything to your knowledge management tool
Bilibili Collections: Same Workflow, Same Power
BibiGPT fully supports batch summarization of Bilibili collections and favorites. The workflow is identical to YouTube — copy the Bilibili collection link, paste it into BibiGPT, and receive a cross-video collection-level summary.
Both UP-created series (collections) and user favorites are supported. Whether it is a 50-episode programming tutorial or a 10-part book review series, BibiGPT’s AI accurately extracts the knowledge structure and generates high-quality series summaries.
Beyond YouTube and Bilibili, BibiGPT supports 30+ platforms for audio and video content processing, including podcasts (Apple Podcasts, Spotify), TikTok, TED, Coursera, and more.
Advanced Use Cases for Batch Summarization
Once you have mastered basic playlist summarization, here are some powerful advanced scenarios worth exploring:
Course Learning Notes: Summarize an entire online course, export to Obsidian, and automatically build a course knowledge graph. See our video content repurposing guide for more ways to transform video content into multiple knowledge products.
Meeting Recording Batch Processing: Process a series of weekly project meetings or team syncs to extract all decisions and action items at once, generating a project progress report. Combine with our AI meeting minutes guide to double your efficiency.
Content Research: As a content creator, batch summarize a competitor’s video series to quickly understand industry topic trends and content frameworks.
Cross-Language Learning: An English tutorial series too long to watch in full? Batch summarize it, generate an overview in your native language, understand the big picture first, then dive into specific episodes that matter.
FAQ
How large a playlist can BibiGPT handle?
BibiGPT supports processing playlists containing dozens of videos. For very large collections, the system automatically processes them in batches. Whether it is a 10-video short series or a 50-video complete course, you can start processing with one click.
What is the difference between a collection summary and individual video summaries?
An individual video summary analyzes only one video. A collection summary performs cross-video global analysis — it identifies knowledge connections between different videos, tracks theme progression, and maps logical chains. The output is a unified structured summary of the entire series, not a simple concatenation of individual summaries.
Can I export the batch summary results?
Yes. BibiGPT supports exporting collection summaries in Markdown, ZIP, and JSON formats. You can sync directly to Notion, Obsidian, or other note-taking tools, or download locally for archiving.
Which platforms are supported besides YouTube and Bilibili?
BibiGPT supports audio and video content from 30+ platforms, including YouTube, Bilibili, podcasts (Apple Podcasts, Spotify, etc.), TikTok, TED, Coursera, and more. You can also upload local audio and video files directly.
Does batch summarization require a paid plan?
BibiGPT offers free trial credits. The advanced collection summary features require a Pro subscription. Given the time it saves — a 20-episode series might take 10+ hours to watch — the return on investment is substantial.
Conclusion: From Watching Every Video to Systematic Learning
In 2026, the competitive edge in learning has shifted from “who watches more” to “who captures core knowledge faster.” BibiGPT’s collection summary feature upgrades your workflow from the inefficient mode of watching videos one by one to a systematic, structured approach to knowledge acquisition.
1M+ users already rely on BibiGPT to batch process their learning and work videos. Try it now — compress a playlist that would take dozens of hours into a 5-minute knowledge overview.
Start using BibiGPT collection summary today:
- Official Website: https://bibigpt.co/en/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=youtube-playlist-batch-summary-bibigpt-guide
- Mobile Download: https://aitodo.co/app
- Desktop Download: https://aitodo.co/download/desktop
BibiGPT Team