What Does Claude Opus 4.8's 1M-Token Context Mean for Long-Video Summary? (2026 Deep Dive)
What Does Claude Opus 4.8’s 1M-Token Context Mean for Long-Video Summary?
As of May 28, 2026: Anthropic officially released Claude Opus 4.8, bringing three capability upgrades worth noting — a 1M-token context window, controllable effort (thinking-effort) levels, and a faster Fast mode. To the average user, these parameters sound abstract; but if you regularly need to digest long videos, long podcasts, or hours of meeting recordings, the meaning of this upgrade is actually very concrete: very long content can finally be read in one whole pass, without being chopped into fragments.
1. Background: what exactly did Opus 4.8 upgrade
A direct look beats a spec sheet — here’s anthropic.com’s homepage as of publishing:

Screenshot: anthropic.com (captured on the publish date)
What happened
On May 28, 2026, Anthropic announced Claude Opus 4.8 on its official release page. Unlike the usual “benchmarks went up a few points” iterations, several directions of this upgrade hit the “handling long content” scenario directly:
- 1M-token context: think of it as a big expansion in how much content the AI can “hold in its head” at once. 1M tokens is roughly equivalent to several hundred thousand words — enough to hold an entire book, a multi-hour meeting, or a full season’s worth of podcast transcripts.
- Controllable effort levels: users can decide whether the AI does “a quick scan” or “a slow, deep think.” Use low effort for speed on simple tasks, high effort for depth on complex ones — handing the speed-vs-depth trade-off back to the user.
- Faster Fast mode: quicker responses, and lower cost than the previous generation — which means “quickly skimming long content” just got cheaper.
Timeline
| Time | Event |
|---|---|
| Early 2026 | Long context becomes a focus of the model race; 100K–200K tokens is mainstream |
| 2026 Q1-Q2 | Multiple models push context to the 1M-token level |
| May 28, 2026 | Anthropic releases Claude Opus 4.8: 1M context + controllable effort + Fast mode |
Why this matters to “content consumers”
In the past, when AI processed a two-hour video or podcast, it often had to chop the subtitles into many chunks, summarize each, then stitch those mini-summaries together. This “chunk-then-stitch” approach has an inherent flaw: the AI can’t see the whole picture. A person mentioned in the first half might be “forgotten” by the time they reappear in the second half; an argument that runs through the whole piece loses its logical thread once chopped up.
The significance of 1M-token context is that it makes “reading the whole thing at once” possible. The AI is no longer peeking through a window segment by segment, but has the entire “book” laid open in front of it to read in one go — a structural improvement to the summarization quality of long videos, long podcasts, and long meetings.
Practical rule: The context window determines how much the AI “sees at once.” When handling long content, the bigger the window, the less likely cross-section logic and details are to be lost.
The demo below walks through “a video → complete structured summary”:
Source: YouTube · AI long-video summary demo
2. Deep dive: what million-token context changes
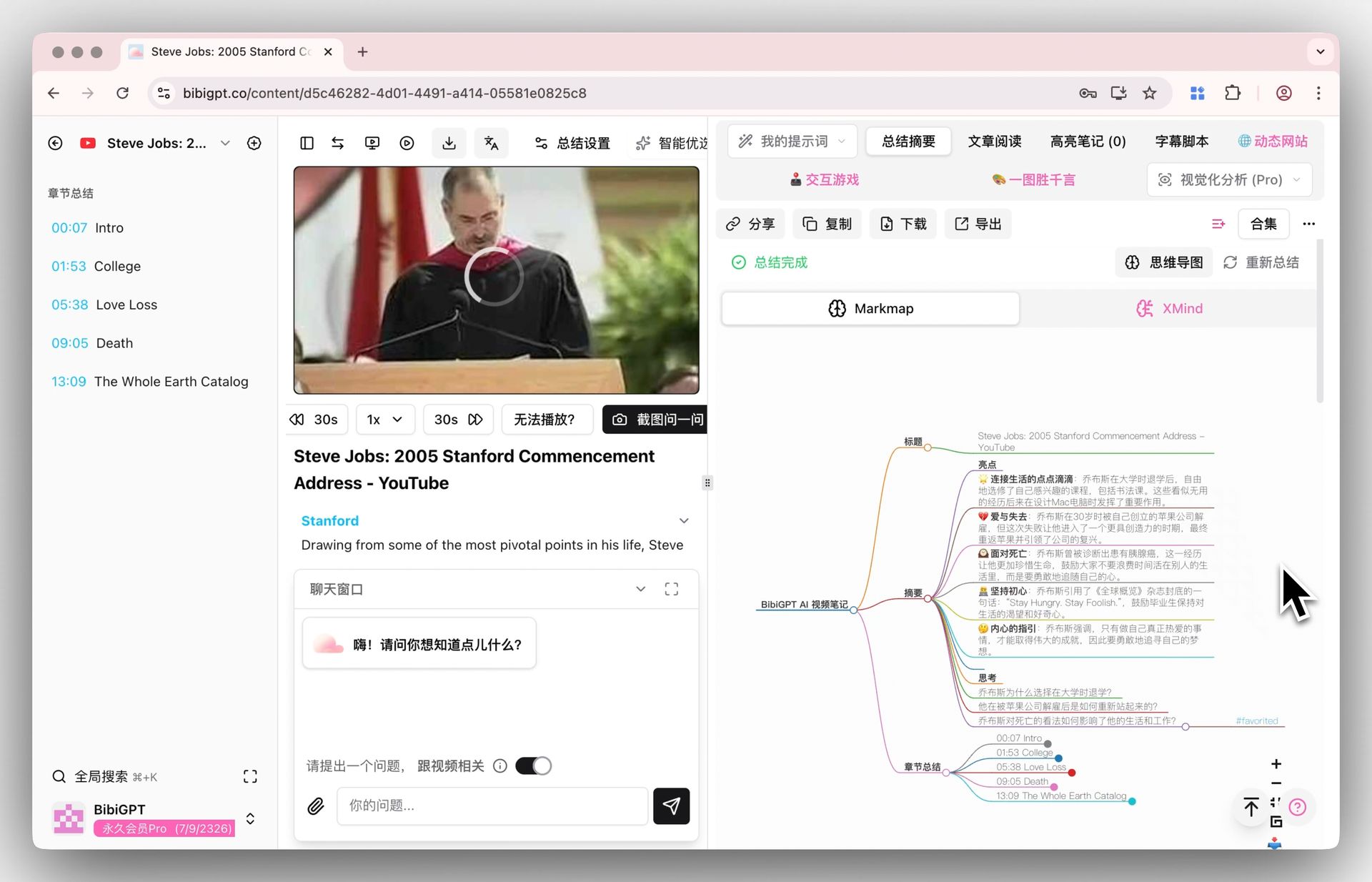
Here’s the same idea inside BibiGPT — paste a long video and it reads the whole thing into a structured summary:
Screenshot: BibiGPT
2.1 Technical impact: from “chunk-and-stitch” to “whole-piece understanding”
Chunking long content is fundamentally a compromise forced by a limited context window. Its biggest cost is lost coherence: a three-hour interview might respond in hour 2 to a point made in hour 1, but when chunked these two segments land in different batches, and the AI struggles to connect them.
When context expands to 1M tokens, an entire piece of long content can be fed in at once. The AI can see the complete narrative arc, the people and concepts that run throughout, the call-backs in the argument. The lift this brings to summary quality isn’t “faster” but “more accurate, more complete” — especially for long content where information is highly interconnected and requires global understanding.
2.2 Experience impact: tiered thinking lets “fast” and “deep” coexist
Controllable effort levels solve another old problem: not every summary needs the same depth.
- You just want to know “roughly what this 1-hour video covers, and whether it’s worth watching” → low effort, a TL;DR in seconds
- You need to turn a course session into exam-review material, requiring precise section-by-section points → high effort, slower but more detailed
In the past these two needs often had to share one tier — either fast but shallow, or deep but slow. Tiered effort lets the user choose on demand, which maps perfectly to the two typical modes of content consumption: screen quickly first, then digest deeply.
2.3 Ecosystem impact: models keep improving, but “consumption speed” is the real scarcity
One thing worth viewing calmly: the underlying models get stronger, faster, and cheaper every few months — that’s a certainty in the industry. 1M context is news today; in half a year it’ll be table stakes.
So for content consumers, what’s really worth watching isn’t “which model is newest” but “can I immediately apply the stronger model capability to the videos and podcasts I have to digest every day.” The model itself is becoming infrastructure-like — the model is no longer scarce; whether you can consume long content quickly and turn it into something usable is the scarcity.
Practical rule: Don’t chase model version numbers. What you really need is a stable entry point so that when the underlying model gets stronger, your long-video experience automatically improves.
3. What it actually means for content consumers (by role)
The “whole-piece, no-truncation understanding” that million-token context brings has different value for different groups:
- Students / lifelong learners: a 90-minute online lecture or academic talk can be summarized as one whole pass into chapter-structured review material, instead of a pile of points with broken logic after chunking.
- Professionals / researchers: hours-long industry podcasts, earnings calls, deep interviews can be read in full and distilled into a core argument that runs throughout, with cross-section cause-and-effect no longer lost.
- Creators: feed someone’s long video/long podcast in whole, quickly get the global structure, then plan derivative topics from it — the “information goldmine” of long content can finally be mined efficiently.
In the interactive demo below, pick a sample video and see the complete TL;DR + section points + timestamps the AI outputs:
Summarize any video in seconds
Pick a sample below to see the AI summary — TL;DR, key points, and jump-to timestamps.
TL;DR: Karpathy builds a GPT-style language model from scratch in code, explaining every piece — from a tiny character-level model up to the full Transformer.
Key points
- Start with a bigram model, then add self-attention so tokens can "talk" to each other
- A Transformer block = multi-head attention + feed-forward + residual connections + layer norm
- Training is just predicting the next token; scale and data do the rest
- The same architecture behind nanoGPT is what scales up to ChatGPT
Jump to
- 00:07 Why build GPT from scratch
- 08:23 Self-attention, intuitively
- 1:00:00 Assembling the Transformer block
- 1:35:00 From nanoGPT to ChatGPT
4. Hands-on pairing: how to apply this capability to your everyday videos
The lift in underlying model capability only matters once it lands in a usable product entry point. BibiGPT video summary does exactly this — it turns “summarize very long content in one whole pass without truncation” into a capability you use by pasting a link.
A typical long-content consumption workflow:
- Paste a link: YouTube, Bilibili, TikTok, podcasts, and 30+ platforms — or upload a multi-hour local recording directly
- Screen quickly: grab a TL;DR first and judge in seconds whether this long content is worth a deeper look
- Summarize deeply: for what’s worth it, let the AI read the whole piece and output timestamped section points
- Distill into structure: turn the points into a mind map and see the global structure at a glance
The demo below turns a video into an interactive mind map — the fastest way to see the global structure of long content:
Turn a video into a mind map
A linear talk becomes a structured tree. Drag to pan, click nodes to fold.
It’s worth stressing: BibiGPT is not just another model chat box. On top of the underlying model, it layers a full set of capabilities purpose-built for “audio-video consumption” —
- Direct link-reading across 30+ platforms: paste and go, no download-then-upload
- Timestamped source tracing: every point links back to its spot in the original video — verifiable, no fabrication
- Visual analysis: it even reads the charts, operations, and products shown on screen, not just subtitles
- Collection / multi-video synthesis: a whole series, a whole season of a podcast can be batch-processed and synthesized
These are things “a stronger model” alone can’t give you — they’re product engineering layered on top of the model, built for real usage scenarios.
Practical rule: The model decides “how accurate the read is,” the product decides “how smooth the use is.” Layered together, that’s the experience you actually need every day.
5. Looking ahead: the next step in long-content consumption
Based on this upgrade, three judgments:
- Context windows will keep escalating, but will quickly become “table stakes not worth advertising.” Today’s 1M might be 10M next year. For users, the marginal value of window size decreases — “can it read the whole thing” soon stops being a selling point.
- “Tiered processing” will become a default design for content tools. Screen quickly first, then dig deep on demand — this interaction paradigm will sink from a model capability into product experience and become standard in every content tool.
- Competition will shift from “model” to “scenario.” When every tool can dial up a strong model underneath, the deciding factor lands on “who polished a specific scenario (long video / long podcast / online course) the smoothest.”
Frequently Asked Questions (FAQ)
What use is a 1M-token context to me watching videos?
The most direct benefit: very long videos or podcasts (multiple hours) can be read by the AI in one whole pass before summarizing, instead of being chopped into many chunks and processed separately. Whole-piece understanding means cross-section logic, people, and argument relationships are less likely to be lost — the summary is more complete and accurate.
What is an effort level, and do I need to set it manually?
An effort level is the switch for whether the AI does “a quick pass” or “a slow, deep think.” Most good products choose by scenario automatically — fast for screening, deep for detailed organizing — so you usually don’t need to fuss over it manually; just know that “skim first, then look closely” is the more efficient way to consume.
The model got upgraded — will my video-summary tool automatically get better?
If you use a product entry point that abstracts away the underlying model (rather than calling one fixed model directly), then when the underlying model gets stronger, your experience usually improves automatically. That’s why, for users, picking a stable, easy-to-use entry point matters more than chasing a specific model version.
What’s the difference between whole-piece long-video summary and segment-by-segment summary?
Segment summary chunks the content, processes each separately, then stitches — easy to lose the call-backs at the seams. Whole-piece summary lets the AI see the global picture, preserving the relationships among arguments, people, and concepts that run throughout — especially suited to long content where information is highly interconnected.
6. The core competitiveness of the AI era: the speed of consuming content
Back to the judgment we started with: the model is no longer scarce; the speed of consuming content is.
Stronger models launch every month, but people’s time hasn’t grown. What truly separates people is who can quickly consume the world’s vast long videos, long podcasts, and long meetings — turning them into their own usable knowledge and creations. 1M-token context, tiered effort — these upgrades ultimately serve one goal: make consuming audio-video as fast as consuming text.
This is exactly what BibiGPT has long been doing: trusted by over 1 million users, with 5M+ AI summaries generated, supporting 30+ platforms — turning each advance in the underlying model into a “faster, more accurate, smoother” you can feel when handling long content, right away.
Further reading:
- Video to Xiaohongshu Notes: turn videos into viral picture-text notes with AI
- Podcast to study notes: a 4-step spaced-review workflow
- Qwen AI Video Summary vs BibiGPT: a free comparison
- Video to Slides: extract PPT from any video with AI
Want to read a multi-hour long video in one whole pass and get a complete summary in minutes? Open BibiGPT and paste a link to try it.
BibiGPT Team