Claude Opus 4.8의 100만 토큰 컨텍스트는 긴 영상 요약에 무엇을 가져오는가? (2026 심층 분석)
Claude Opus 4.8의 100만 토큰 컨텍스트는 긴 영상 요약에 무엇을 가져오는가?
2026년 5월 28일 기준: Anthropic은 Claude Opus 4.8을 공식 발표하며 주목할 만한 세 가지 능력 업그레이드를 선보였습니다——100만 토큰 컨텍스트 윈도우, 제어 가능한 effort(사고 노력) 레벨, 그리고 더 빠른 Fast 모드. 일반 사용자에게 이 파라미터들은 추상적으로 들리지만, 긴 영상·긴 팟캐스트·몇 시간짜리 회의 녹음을 소화해야 하는 사람에게 이 업그레이드의 의미는 사실 매우 구체적입니다. 아주 긴 콘텐츠를 AI가 드디어 한 번에 통째로 읽어낼 수 있고, 더 이상 잘게 쪼개지지 않아도 된다는 것입니다.
1. 배경: Opus 4.8은 무엇이 업그레이드됐나
직접 보는 게 빠릅니다. 아래는 게시 시점의 anthropic.com 화면입니다:

스크린샷: anthropic.com (게시일 기준)
무슨 일이 있었나
2026년 5월 28일, Anthropic은 공식 발표 페이지에서 Claude Opus 4.8을 발표했습니다. 지금까지의 “벤치마크가 몇 점 또 올랐다”는 통상적 이터레이션과 달리, 이번 업그레이드의 여러 방향은 “긴 콘텐츠 처리”라는 시나리오에 직접 꽂힙니다:
- 100만 토큰 컨텍스트: AI가 한 번에 “머릿속에 넣을 수 있는” 콘텐츠 양이 대폭 확장됐다고 이해하면 됩니다. 100만 토큰은 약 수십만 자에 해당해, 책 한 권, 몇 시간짜리 회의, 팟캐스트 한 시즌 분량의 전사를 통째로 담을 수 있습니다.
- 제어 가능한 effort 레벨: 사용자가 AI에게 “한 번 훑기”인지 “천천히 깊게 생각하기”인지 정할 수 있습니다. 간단한 작업은 낮은 effort로 속도를, 복잡한 작업은 높은 effort로 깊이를——속도와 깊이의 트레이드오프를 사용자에게 돌려줍니다.
- Fast 모드 속도 향상: 응답이 더 빠르고 이전 세대보다 비용도 낮습니다——즉 “긴 콘텐츠를 빠르게 한 번 훑기”의 문턱이 낮아졌습니다.
타임라인
| 시기 | 사건 |
|---|---|
| 2026년 초 | 롱컨텍스트가 모델 경쟁의 초점으로; 10만~20만 토큰이 주류 |
| 2026년 Q1-Q2 | 여러 모델이 컨텍스트를 100만 토큰급으로 끌어올림 |
| 2026년 5월 28일 | Anthropic이 Claude Opus 4.8 발표: 1M 컨텍스트 + 제어 가능 effort + Fast 모드 |
왜 “콘텐츠 소비자”에게 중요한가
과거 AI가 두 시간짜리 영상이나 팟캐스트를 처리할 때, 종종 자막을 여러 블록으로 잘라 각각 요약하고, 그 작은 요약들을 이어 붙여야 했습니다. 이 “블록 후 이어붙이기” 방식에는 태생적 결함이 있습니다. AI가 전체 그림을 보지 못한다는 것입니다. 전반부에 언급된 인물이 후반부에 다시 나올 때는 “잊어버렸을” 수 있고, 작품 전체를 관통하는 논증의 사슬은 잘게 쪼개지면 논리 관계가 사라지기 쉽습니다.
100만 토큰 컨텍스트의 의미는 “통째로 읽어내기”를 가능하게 한다는 것입니다. AI는 창문 너머로 한 단락씩 엿보는 게 아니라, 책 한 권을 눈앞에 펼쳐놓고 한 번에 읽어냅니다——긴 영상·긴 팟캐스트·긴 회의의 요약 품질에 이는 구조적 향상입니다.
실용 규칙: 컨텍스트 윈도우는 AI가 “한 번에 얼마나 보는가”를 결정합니다. 긴 콘텐츠를 다룰 때 윈도우가 클수록 단락을 가로지르는 논리와 디테일이 사라지기 어렵습니다.
아래 데모로 “영상 한 편 → 완전한 구조화 요약”의 흐름을 보세요:
출처: YouTube · AI 긴 영상 요약 데모
2. 심층 분석: 백만 토큰 컨텍스트가 무엇을 바꿨나
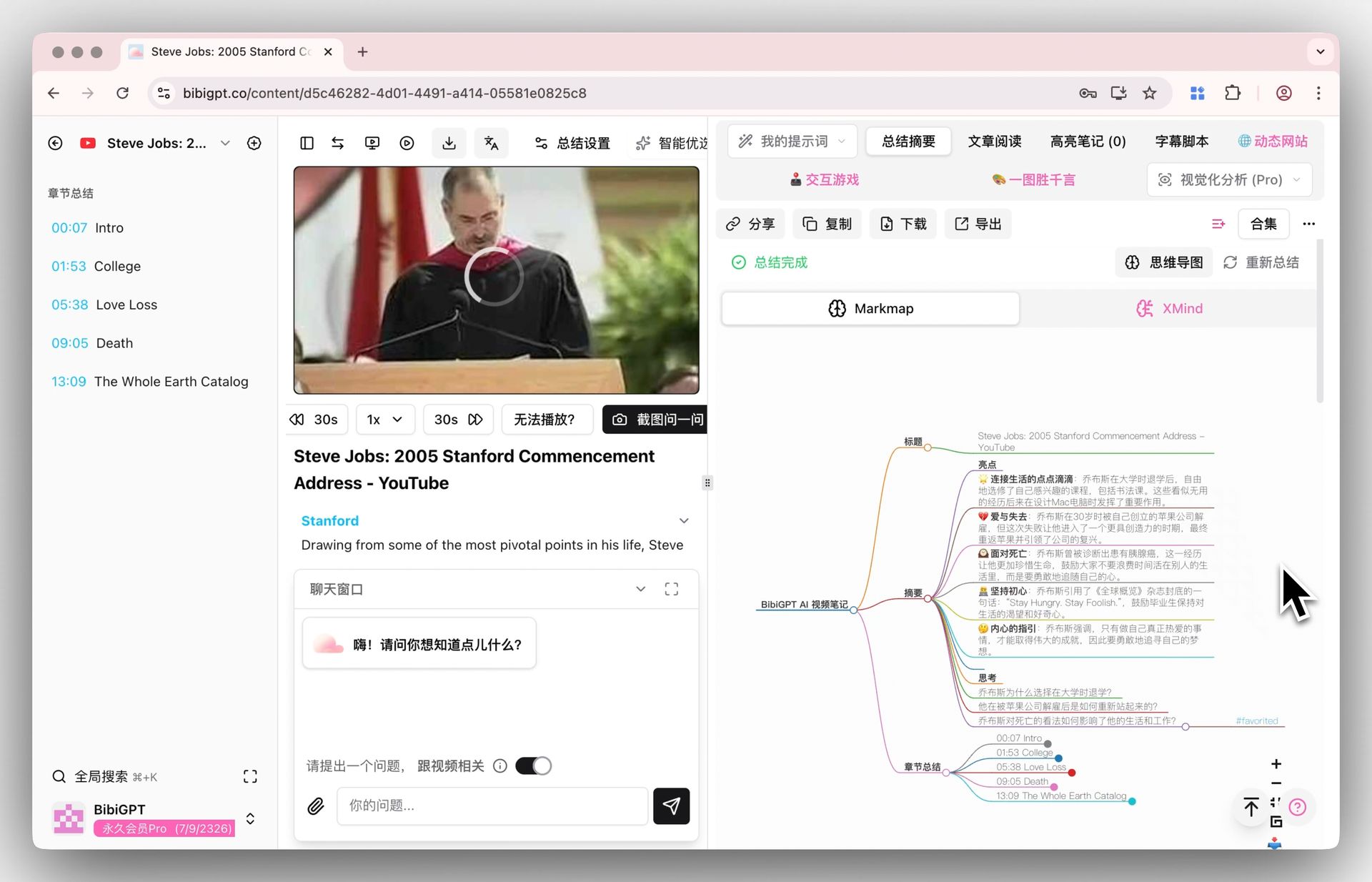
BibiGPT에서 같은 작업을 하면, 긴 영상을 통째로 읽어 구조화된 요약으로 정리합니다:
스크린샷: BibiGPT
2.1 기술적 영향: “블록 후 이어붙이기”에서 “통째 이해”로
긴 콘텐츠를 블록 처리하는 것은 본질적으로 제한된 컨텍스트 윈도우 때문에 어쩔 수 없는 타협입니다. 가장 큰 대가는 일관성 상실: 세 시간짜리 인터뷰가 2시간째에 1시간째의 어떤 견해에 응답하더라도, 블록화하면 이 둘이 다른 배치에 배정되어 AI가 연결하기 어렵습니다.
컨텍스트가 100만 토큰으로 확장되면 긴 콘텐츠 전체를 한 번에 넣을 수 있습니다. AI는 완전한 내러티브 호, 작품 전체를 관통하는 인물과 개념, 앞뒤로 호응하는 논증을 볼 수 있습니다. 요약 품질에 대한 이 향상은 “더 빠름”이 아니라 “더 정확하고 더 완전함”——특히 정보가 고도로 연결되어 전체 이해가 필요한 긴 콘텐츠에 효과적입니다.
2.2 경험에 대한 영향: 계층적 사고가 “빠름”과 “깊음”을 양립시킨다
제어 가능한 effort 레벨이 해결하는 것은 또 다른 오래된 문제: 모든 요약이 같은 깊이를 필요로 하는 것은 아니다라는 점입니다.
- “이 1시간짜리 영상이 대략 무엇을 말하는지, 볼 가치가 있는지”만 알고 싶다 → 낮은 effort, 몇 초 만에 TL;DR
- 온라인 강의 한 차시를 시험 복습 자료로 정리하고 싶고 챕터별 정확한 핵심이 필요하다 → 높은 effort, 조금 느리지만 더 세밀
과거 이 두 니즈는 같은 단으로만 처리할 수 있어, 빠르지만 얕거나 깊지만 느렸습니다. 계층적 effort는 사용자가 필요에 따라 고를 수 있게 하며, 콘텐츠 소비의 두 전형적 시나리오에 딱 대응합니다. 먼저 빠르게 걸러내고, 그다음 깊이 소화한다.
2.3 생태계에 대한 영향: 모델은 계속 좋아지지만 “소비 속도”가 진짜 희소성
냉정하게 봐야 할 점: 기반 모델은 몇 달마다 더 강하고 더 빠르고 더 저렴해집니다. 이는 업계의 확실한 트렌드입니다. 1M 컨텍스트는 오늘은 뉴스지만 반년 후에는 기본이 됩니다.
그래서 콘텐츠 소비자에게 정말 주목할 것은 “어떤 모델이 최신인가”가 아니라 “강해진 모델 능력을 매일 소화해야 할 영상과 팟캐스트에 바로 쓸 수 있는가”입니다. 모델 자체가 인프라 같은 존재가 되어 가고 있습니다——모델은 더 이상 희소하지 않고, 긴 콘텐츠를 빠르게 소비해 자신이 쓸 수 있는 것으로 바꿀 수 있느냐가 희소합니다.
실용 규칙: 모델 버전 번호를 쫓지 마세요. 정말 필요한 것은 안정된 입구로, 기반 모델이 강해질 때 긴 영상을 다루는 경험이 자동으로 좋아지는 것입니다.
3. 콘텐츠 소비자에게 갖는 실제 의미 (역할별)
백만 토큰 컨텍스트가 가져오는 “통째로 끊김 없는 이해”는 사람마다 가치가 다릅니다:
- 학생 / 평생 학습자: 90분짜리 온라인 강의, 학술 강연을 한 번에 통째로 챕터 구조가 있는 복습 자료로 정리할 수 있고, 블록화 후 논리가 끊긴 핵심 더미가 되지 않습니다.
- 직장인 / 연구자: 몇 시간짜리 업계 팟캐스트, 실적 발표 콜, 깊이 있는 인터뷰를 통째로 읽어내 전체를 관통하는 핵심 논점을 추출할 수 있고, 단락을 가로지르는 인과 관계가 사라지지 않습니다.
- 크리에이터: 남의 긴 영상·긴 팟캐스트를 통째로 넣어 빠르게 전체 구조를 얻고, 이를 바탕으로 2차 창작 기획을 세웁니다——긴 콘텐츠의 “정보 광맥”을 드디어 효율적으로 채굴할 수 있습니다.
아래 인터랙티브 데모에서 샘플 영상을 골라 AI가 출력하는 완전한 TL;DR + 섹션 핵심 + 타임스탬프를 보세요:
어떤 영상이든 몇 초 만에 요약
샘플을 선택하면 AI 요약이 나타납니다——한 줄 결론, 핵심 정리, 바로 이동하는 타임스탬프.
한 줄 요약: Karpathy가 GPT 형태의 언어 모델을 코드로 밑바닥부터 구축하며, 작은 문자 단위 모델부터 완전한 Transformer까지 모든 조각을 설명합니다.
핵심
- bigram 모델로 시작해 self-attention을 더해 토큰끼리 "대화"하게 만든다
- Transformer 블록 = 멀티헤드 어텐션 + 피드포워드 + 잔차 연결 + 층 정규화
- 학습은 그저 "다음 토큰 예측"; 나머지는 규모와 데이터가 한다
- nanoGPT의 구조를 키운 것이 곧 ChatGPT
바로가기
- 00:07 왜 밑바닥부터 만드나
- 08:23 직관으로 보는 self-attention
- 1:00:00 Transformer 블록 조립
- 1:35:00 nanoGPT에서 ChatGPT로
4. 실전 조합: 이 능력을 매일의 영상에 어떻게 쓰나
기반 모델 능력의 향상은 결국 쓸 수 있는 제품 입구에 떨어져야 비로소 의미가 있습니다. BibiGPT 영상 요약 이 하는 일이 바로 이것——“아주 긴 콘텐츠를 통째로 끊김 없이 요약하기”를 링크만 붙이면 쓸 수 있는 능력으로 바꿉니다.
전형적인 긴 콘텐츠 소비 워크플로우:
- 링크 붙이기: YouTube·Bilibili·TikTok·팟캐스트 등 30개 이상 플랫폼, 또는 몇 시간짜리 로컬 녹음 직접 업로드
- 빠르게 걸러내기: 먼저 TL;DR을 받아 이 긴 콘텐츠를 깊게 볼 가치가 있는지 몇 초 만에 판단
- 깊게 요약: 볼 가치가 있는 건 AI에게 통째로 읽게 해 타임스탬프가 달린 섹션 핵심 출력
- 구조화해 축적: 핵심을 마인드맵으로 바꿔 전체 구조를 한눈에 파악
아래 데모는 영상을 인터랙티브 마인드맵으로 바꾼 효과입니다——긴 콘텐츠의 전체 구조는 이렇게 보는 게 가장 빠릅니다:
영상을 마인드맵으로
일렬로 흐르던 강연이 구조화된 지식 트리로. 드래그로 이동, 노드 클릭으로 펼치기/접기.
강조하고 싶은 것: BibiGPT는 또 하나의 모델 채팅창이 아닙니다. 기반 모델 위에 “음성·영상 소비”를 위해 전용으로 다듬은 일련의 능력을 쌓았습니다——
- 30개 이상 플랫폼 링크 직독: 붙이면 바로 쓰고, 먼저 다운로드해 업로드할 필요 없음
- 타임스탬프 출처 추적: 각 핵심이 원본 영상의 대응 위치로 돌아갈 수 있어 검증 가능하고 날조하지 않음
- 시각화 분석: 화면 속 도표, 조작, 제품까지 읽어냄, 자막만이 아님
- 컬렉션 / 다중 영상 정리: 시리즈 전체, 팟캐스트 한 시즌을 배치 처리하고 통합 정리
이것들은 “모델이 강해지는” 것만으로는 얻을 수 없는 것——모델 위에 쌓은, 실제 사용 시나리오를 위한 제품 엔지니어링입니다.
실용 규칙: 모델은 “읽기가 정확한가”를, 제품은 “쓰기가 매끄러운가”를 결정합니다. 둘의 결합이야말로 매일 정말 필요한 경험입니다.
5. 전망: 긴 콘텐츠 소비의 다음 한 수
이번 업그레이드를 바탕으로 세 가지 판단:
- 컨텍스트 윈도우는 경쟁이 계속되지만 곧 “홍보할 만하지 않은 기본”이 된다. 오늘의 1M은 내년에 1000만일 수 있습니다. 사용자에게 윈도우 크기의 한계 가치는 체감되고, “통째로 읽을 수 있는가”는 곧 셀링 포인트가 아니게 됩니다.
- “계층 처리”가 콘텐츠 도구의 기본 설계가 된다. 먼저 빠르게 걸러내고 필요에 따라 깊게 파기——이 상호작용 패러다임은 모델 능력에서 제품 경험으로 내려와 모든 콘텐츠 도구의 표준이 됩니다.
- 경쟁의 초점이 “모델”에서 “시나리오”로 올라간다. 모든 도구가 기반에서 강한 모델을 부를 수 있게 되면, 승부처는 “어떤 구체 시나리오(긴 영상/긴 팟캐스트/온라인 강의)를 가장 매끄럽게 다듬었는가”에 떨어집니다.
자주 묻는 질문 (FAQ)
100만 토큰 컨텍스트는 영상을 보는 저에게 무슨 쓸모가 있나요?
가장 직접적인 이점은 아주 긴 영상이나 팟캐스트(몇 시간)를 AI가 한 번에 통째로 읽은 뒤 요약할 수 있다는 것입니다. 여러 블록으로 나눠 따로 처리하는 게 아닙니다. 통째 이해는 단락을 가로지르는 논리·인물·논점 관계가 사라지기 어려워, 요약이 더 완전하고 정확해집니다.
effort 레벨이 무엇이고, 수동으로 조정해야 하나요?
effort 레벨은 AI에게 “한 번 훑기”인지 “천천히 깊게 생각하기”인지의 스위치입니다. 좋은 제품 대부분은 시나리오에 따라 자동으로 고릅니다——걸러낼 땐 속도, 상세 정리할 땐 깊이——그래서 보통 수동으로 신경 쓸 필요가 없습니다. “먼저 훑고 자세히 보기”가 더 효율적인 소비라는 것만 알면 됩니다.
모델이 업그레이드되면 제가 쓰는 영상 요약 도구가 자동으로 좋아지나요?
기반 모델을 추상화한 제품 입구를 쓰고 있다면(고정 모델을 직접 호출하는 게 아니라), 기반 모델이 강해질 때 경험은 보통 자동으로 향상됩니다. 그래서 사용자에게는 안정되고 쓰기 좋은 입구를 고르는 것이 특정 모델 버전을 쫓는 것보다 중요합니다.
긴 영상 통째 요약은 분할 요약과 무엇이 다른가요?
분할 요약은 콘텐츠를 블록화해 따로 처리한 뒤 이어 붙입니다. 이음매에서 앞뒤 호응의 논리를 잃기 쉽습니다. 통째 요약은 AI에게 전체 그림을 보게 해 전편을 관통하는 논증·인물·개념의 관계를 유지할 수 있습니다——특히 정보가 고도로 연결된 긴 콘텐츠에 적합합니다.
6. AI 시대의 핵심 경쟁력: 콘텐츠를 소비하는 속도
처음의 판단으로 돌아갑니다: 모델은 더 이상 희소하지 않고, 콘텐츠를 소비하는 속도가 희소합니다.
매달 더 강한 모델이 발표되지만 사람의 시간은 늘지 않습니다. 진짜 격차를 만드는 것은 세상의 방대한 긴 영상·긴 팟캐스트·긴 회의를 빠르게 소비해 자신이 쓸 수 있는 지식과 창작물로 바꾸는 사람입니다. 100만 토큰 컨텍스트, 계층적 effort——이 업그레이드들은 결국 하나의 목표에 봉사합니다. 음성·영상 소비를, 텍스트 소비만큼 빠르게 만든다.
이것이 바로 BibiGPT가 오래 해온 일입니다: 100만 명 이상의 사용자가 신뢰하고, 500만 건 이상의 AI 요약을 생성했으며, 30개 이상의 플랫폼을 지원합니다——기반 모델의 진보를 하나하나, 긴 콘텐츠를 다룰 때 체감할 수 있는 “더 빠르고, 더 정확하고, 더 매끄럽게”로 가장 먼저 바꿉니다.
더 읽어보기:
- 영상을 샤오훙수 노트로: AI로 영상을 인기 이미지 노트로
- 팟캐스트를 학습 노트로: 4단계 간격 복습 워크플로우
- Qwen AI 영상 요약 vs BibiGPT: 무료 비교
- 영상을 슬라이드로: AI로 동영상에서 PPT 추출
몇 시간짜리 긴 영상을 통째로 읽어내고 몇 분 만에 완전한 요약을 얻고 싶으신가요? BibiGPT 를 열고 링크를 붙여 시도해 보세요.
BibiGPT 팀