100万トークン・マルチモーダルのオープンモデル登場:超長尺動画・ポッドキャストのAI要約が「分割」されなくなる(2026年トレンド解説)
100万トークン・マルチモーダルのオープンモデル登場:超長尺動画・ポッドキャストのAI要約が「分割」されなくなる(2026年トレンド解説)
結論から: 2026年6月初旬、オープンモデルMiniMax M3が登場しました。100万トークンのコンテキストとネイティブ画像・動画入力を一つのモデルに収め、SWE-Bench Proで59%を記録しています。一般ユーザーにとって本当に効くのは一文で十分です。2時間の講義録画も3時間のポッドキャストも、理論上は一度に丸ごと投入でき、いくつにも切り分けて別々に要約し、無理につなぎ直す必要がなくなるということ。「超長尺動画のAI要約」が、文脈を失わない技術的土台を初めて手にしたのです。長尺動画を一度に見終える体験をすぐ試したいなら、BibiGPTにリンクを貼り付けてください。
下のデモは「長尺動画のリンクを貼る → 構造化要約が出る」という流れを示しています:
どんな動画も数秒で要約
サンプルを選ぶと AI 要約が表示——結論ひとこと、要点リスト、ジャンプできるタイムスタンプ。
ひとこと: Karpathy が GPT 風の言語モデルをコードでゼロから構築。小さな文字レベルモデルから完全な Transformer まで、各パーツを丁寧に解説。
要点
- まず bigram モデル、次に自己注意を加えてトークン同士を"対話"させる
- Transformer ブロック = マルチヘッド注意 + 順伝播 + 残差接続 + 層正規化
- 学習は「次のトークン予測」だけ。あとは規模とデータ次第
- nanoGPT の背後の構造を拡大したものが ChatGPT
ジャンプ
- 00:07 なぜゼロから作るのか
- 08:23 自己注意を直感的に
- 1:00:00 Transformer ブロックの組み立て
- 1:35:00 nanoGPT から ChatGPT へ
デモ:BibiGPTのワンクリック動画要約
1. 何が起きたか:100万トークン+マルチモーダルを一挙に
まず事実を整理します(2026-06-10時点)。MiniMaxの公式発表によると、新しいオープン重みモデルM3は、これまで別々に行っていた3つを一つのモデルに統合しました —
- 100万トークンの超長尺コンテキスト:1回の推論で中くらいの厚さの本1冊分を「記憶」できます;
- ネイティブマルチモーダル入力:テキストだけでなく、画像や動画フレームをテキスト説明に変換せず直接入力できます;
- 強力なコーディング・推論能力:公表されたSWE-Bench Proのスコア約59%は、同時期のオープンモデルで第一線です。
3つは個別に見れば新しくありませんが、同じオープンモデルに初めて収まったことが、長尺コンテンツ理解の分水嶺です。3時間のポッドキャストを要約するには、十数個に切って別々に処理し、結果をつなぐのが定番でしたが、継ぎ目こそ文脈が漏れる場所です。前半に仕込んだ伏線、章をまたいだ呼応は、切った瞬間に途切れます。
実践ルール: 「長尺動画要約」ツールが信頼できるかは、まず分割せずに全体を理解できるかで判断しましょう。一度に読み切ってこそ、章をまたいだ論理が途切れません。
2. なぜ「分割なし」が長尺動画・ポッドキャストにこれほど重要か
録画全体を頭に置いて考えるのは、10個のメモを別々に読んで思い出すのとはまったく別の営みです。超長尺の音声・動画では、分割が3つの典型的な損失を招きます:
- 章をまたぐ呼応の喪失 — 講師が10分で出した概念が、90分で回収される。分割要約では両者が別バッチに分かれ、モデルは「伏線→回収」の構造全体を見られません。
- 指示解消の誤り — 「さっきのあの案」「前の節で話したあの人」といった指示は、分割をまたぐと参照を失い、取り違えが起きます。
- 画面情報の破棄 — 字幕だけの要約はスライドやホワイトボード、図表を見られません。ネイティブ動画入力なら、モデルが重要フレームを実際に「見る」ことができます。
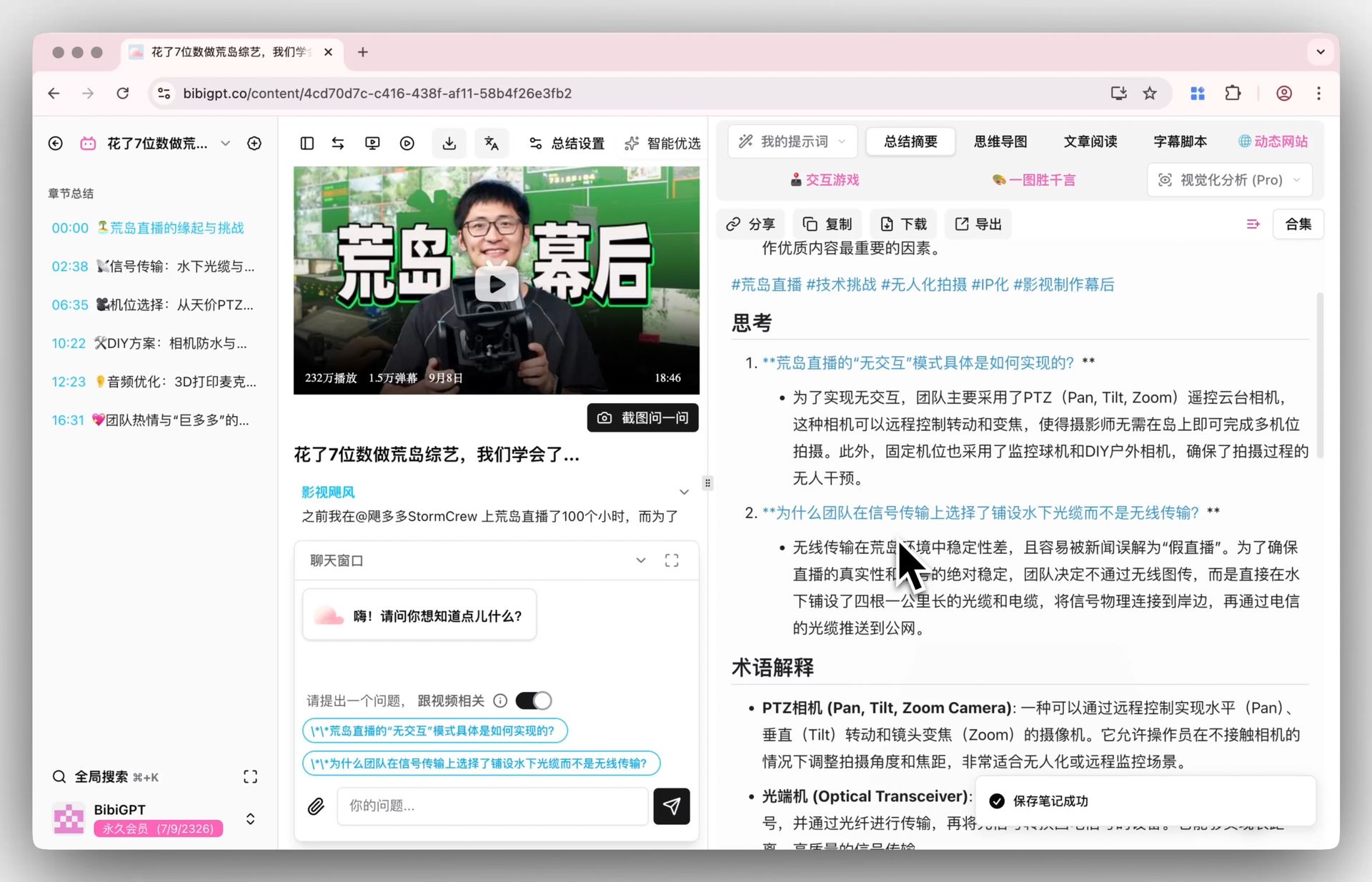
字幕と画面を一緒に読み込めば、章ごとの要点が黒板やスライドの重要情報を取りこぼしません。下の製品実写は「長尺コンテンツ全体を章構造に」した様子を示します:
スクリーンショット:BibiGPT · チャプターディープリーディング機能のデモ
下の動画は、長文コンテキストモデルがどう学習されるかをエンジニアリングの視点で解説します。「全体を一度に読む」の裏にある論理を理解する助けになります:
動画出典:YouTube · 長文コンテキスト言語モデルの解説
土台が整った次に、ユーザーが本当に気にするのは「長いリンクを貼れば、すぐ使える要約が出るか」です。
3. 人によってどんな意味があるか
100万トークン・マルチモーダルは実験室の妙技ではありません。日常の場面では、3つの層がまず恩恵を受けます:
- クリエイター / 個人メディア:2時間の発表会、長尺インタビューを丸ごと投入して構造化要点を得て、記事・SNSノート・ショート動画の台本に作り変え、繰り返し再生して素材を探す時間を節約します。
- ビジネスパーソン:3時間の業界カンファレンス録画、四半期決算コールを一度にTL;DR+重要意思決定+タイムスタンプで受け取り、必要な時だけ原本に飛びます。
- 学生 / 研究者:一学期分の講義録画、1時間の論文解説動画を、スライド画面ごと要約し、復習はシークバーを最初から引かず流れだけを見ます。
長尺コンテンツ全体を一枚のマップに広げると、復習時に本筋が一目で掴めます:
動画をマインドマップに
一本道の講演が構造化された知識ツリーに。ドラッグで移動、ノードをクリックで開閉。
デモ:BibiGPTが長尺動画を構造化された流れに自動変換
4. BibiGPTでこれを日常のワークフローにする
トレンドが速くても、実際に使えてこそ意味があります。BibiGPTはもう一つの「モデルアグリゲーター」ではなく、音声・動画向けのパイプラインの上にモデル能力を重ね、「長い録画を一度に見る」を再現可能な日常動作にします。3ステップ:
- リンクを貼る — Bilibili、YouTube、ポッドキャストの長尺動画リンクやローカルファイルをそのまま入れます。ダウンロードやトランスコード不要。
- 構造化された成果物 — 数十秒でTL;DR、章ごとの要点、タイムスタンプを得て、必要ならマインドマップや記事への書き換えを作ります。
- さらに質問 — 不明点はAI対話で追加質問し、Notion / Obsidianに書き出して知識ベースに蓄積します。
補足すると、BibiGPTは複数の先進AIモデルの自動ルーティングと自由な切り替えに対応しています。背後でどこのモデルを使うか気にせず、使える要約だけを受け取れます。「画面理解」では、ビジュアル分析がスライドや図表の情報まで要点に取り込み、字幕だけを読むことはしません。
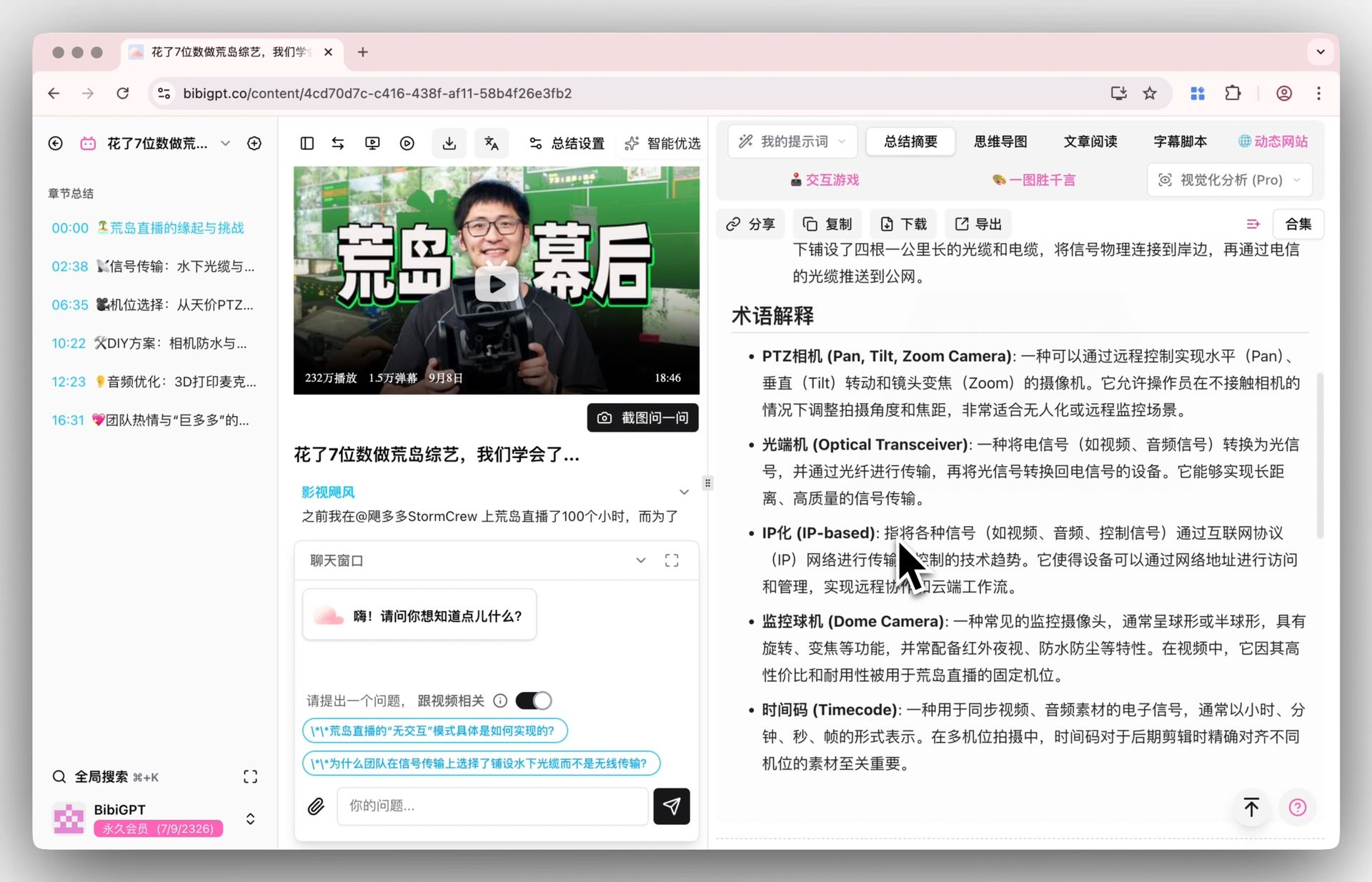
スクリーンショット:BibiGPT · スマートディープ要約機能のデモ
「長尺動画を一度に見る」効率をまず体感するには、最近見る時間がなかった2時間の録画を選び、BibiGPTに貼り付けて一度試してみてください。
5. 展望:長文コンテキストはコンテンツ消費をどう変えるか
現在のペースを踏まえ、3つの判断:
- 「要約」が贅沢品から既定動作へ — 長尺動画を分割する必要がなくなると、要約の限界費用は下がり続け、「見る前にまず要約」が「検索前にキーワードを考える」ほど自然になります。
- 画面理解が加点ではなく標準に — 字幕だけの要約は次第に半端に見え、スライド・図表・デモ画面を読むツールが差を広げます。
- モデルは希少でなく、消費速度が希少 — オープンな100万トークンモデルが能力を公共財にすると、本当の争点は「誰が長尺コンテンツをより速く消費させるか」に戻ります。まさにBibiGPTが長期的に狙う位置です。音声・動画を、テキストと同じ速さで消費させること。
実践ルール: モデル能力がもうボトルネックでなくなると、あなたのボトルネックは「長尺コンテンツを安定して使える成果物に変える、滑らかなワークフローがあるか」になります。ワークフローを先に回すことが、最新モデルを追うより重要です。
6. よくある質問(FAQ)
Q1:100万トークンのコンテキストなら、どんな長さの動画も一度に要約できますか? 方向としてはそうです。コンテキストが長いほど分割は不要になります。実際の体験は、ツールが動画内容をどうコンテキストに組み込むかに左右されます。BibiGPTは長尺の音声・動画を専用に処理し、丸ごと貼れば手動分割なしで動きます。
Q2:モデルに詳しくなくても、自分で選ぶ必要がありますか? 不要です。BibiGPTは複数の先進AIモデルを自動ルーティングし、既定で動作します。上級者は要約モデルを自由に切り替えられますが、必須ではありません。
Q3:字幕だけの要約と「画面を見る」要約で、差は大きいですか? スライドが密で図表の多いコンテンツでは大きな差です。字幕だけでは画面の重要情報を見落とし、画面を理解する要約でこそ完全になります。
Q4:長尺動画の要約は通常どれくらいかかりますか? 通常は数十秒から数分、長さによります。最初から最後まで見るよりはるかに速いです。
Q5:要約後に何ができますか? AIで追加質問、マインドマップ生成、記事への書き換え、Notion / Obsidianへの書き出しで長期の知識ベースに蓄積できます。
トレンドはトレンド、まず長尺動画を1本「見終える」
100万トークン・マルチモーダルモデルは確かに分水嶺ですが、あなたに最も役立つのは、あるモデル名を覚えることではなく、今日、見る時間がなかった長尺動画を1本、実際に消費することです。2時間の録画か長尺ポッドキャストを選び、BibiGPTに貼り付けて、数十秒で構造化要約とタイムスタンプを受け取り、「全体を一度に」を体験してみてください。新規ユーザーは無料で試せます。
関連記事:無料AI動画要約ツールまとめ · クロスプラットフォームAI動画要約ガイド
BibiGPTチーム