動画を小紅書(RED)ノートに:AIで長尺動画をバズる画像ノートに再活用(2026 ガイド)
動画を小紅書(RED)ノートに:AIで長尺動画をバズる画像ノートに再活用(2026 ガイド)
すごく良い情報系の動画に出会う——40分のポッドキャスト、オンライン講座、あるクリエイターの深掘り解説など。見終わって、自分の小紅書(RED)ノートにして投稿したくなります。でもいざ手を動かすと気づくのです。何度もシークバーを行き来して要点を探し、ポイントを手打ちし、画像を一枚ずつ配置し、タイトルを考え、レイアウトを整える……ノート1本に2時間かかり、情熱はとっくに消えています。
100字でわかる要点:2026年Q2時点で、長尺動画を小紅書の画像ノートに変える最速ルートは「AIで要点を分解 → ノートテンプレートに落とし込む → 表紙画像を付ける」です。BibiGPT に動画リンクを貼れば、タイムスタンプ付きの構造化要点が数分で手に入ります。本記事の「フックの見出し+3〜5個の要点+行動喚起」テンプレートに沿って埋め、AI生成の表紙画像を付ければ、1本あたりの制作時間が2時間から15分以内に圧縮できます。
これは実は「ノートを書く」問題ではなく、コンテンツの再活用(リパーパス) の選択です。同じ動画でも、一度消費して忘れる消耗品にするか、フォロワーを増やし続ける画像ノートとして価値を絞り出すか。本記事が扱うのは後者——再現可能な「動画→小紅書ノート」ワークフローです。
世の中の「動画から文字へ」のチュートリアルの多くは、字幕の塊を手に入れて、その後がありません。でも小紅書のノートは字幕の移植ではなく、独自の形があります。フックは強烈に、ポイントは明確に、画像は見応えよく、締めには行動指示を。このガイドは抽出だけでなく、型に当てはめる方法を教えます。
1. なぜ動画をそのまま小紅書に投稿できず、まず「分解」が必要なのか
小紅書のコンテンツロジックは動画プラットフォームとはまったく違います。動画は線形で消費に時間がかかりますが、小紅書の画像ノートは断片的で、ざっと読めて、ビジュアル重視です。ユーザーがフィード内であなたのノートを判断する時間は2秒未満——表紙が刺さらず、最初の画面に価値がなければ即スワイプです。
ですから「動画を小紅書ノートに」の核心は翻訳ではなく再構築です。40分の線形ナラティブを、それぞれ独立して成立する5つの情報ポイントに圧縮し、各ポイントを画像カードの見出しに使えるようにします。
- 学生:オンライン講座や公開講義を「3つの試験ポイント速記」ノートに分解し、復習時に一目で振り返る
- ビジネスパーソン:業界ポッドキャストを「今回の3つのトレンド」要点投稿に分解し、ついでに人物像を確立
- クリエイター:他人のバズり動画を自分の二次創作ノートに分解し、企画アイデア集を作る
Buffer のコンテンツ再活用の分析によれば、1つのコア・コンテンツを複数フォーマットに分割して配信することは、単位時間あたりの産出を増幅する最も効果的なレバーの1つです——1本の動画の価値は1回の再生だけではありません。
実践ルール: 動画を小紅書ノートにするときは、まず「この動画から独立して成立するポイントを何個取り出せるか」を問いましょう。「字幕をどうコピーするか」ではありません。文字数よりポイントです。
下のデモで「1本の動画 → 構造化要点」の流れを一度見て、直感をつかんでください:
出典:YouTube · AI動画要約とノート作成のデモ
2. ステップ1:AIで動画を構造化した要点に分解する
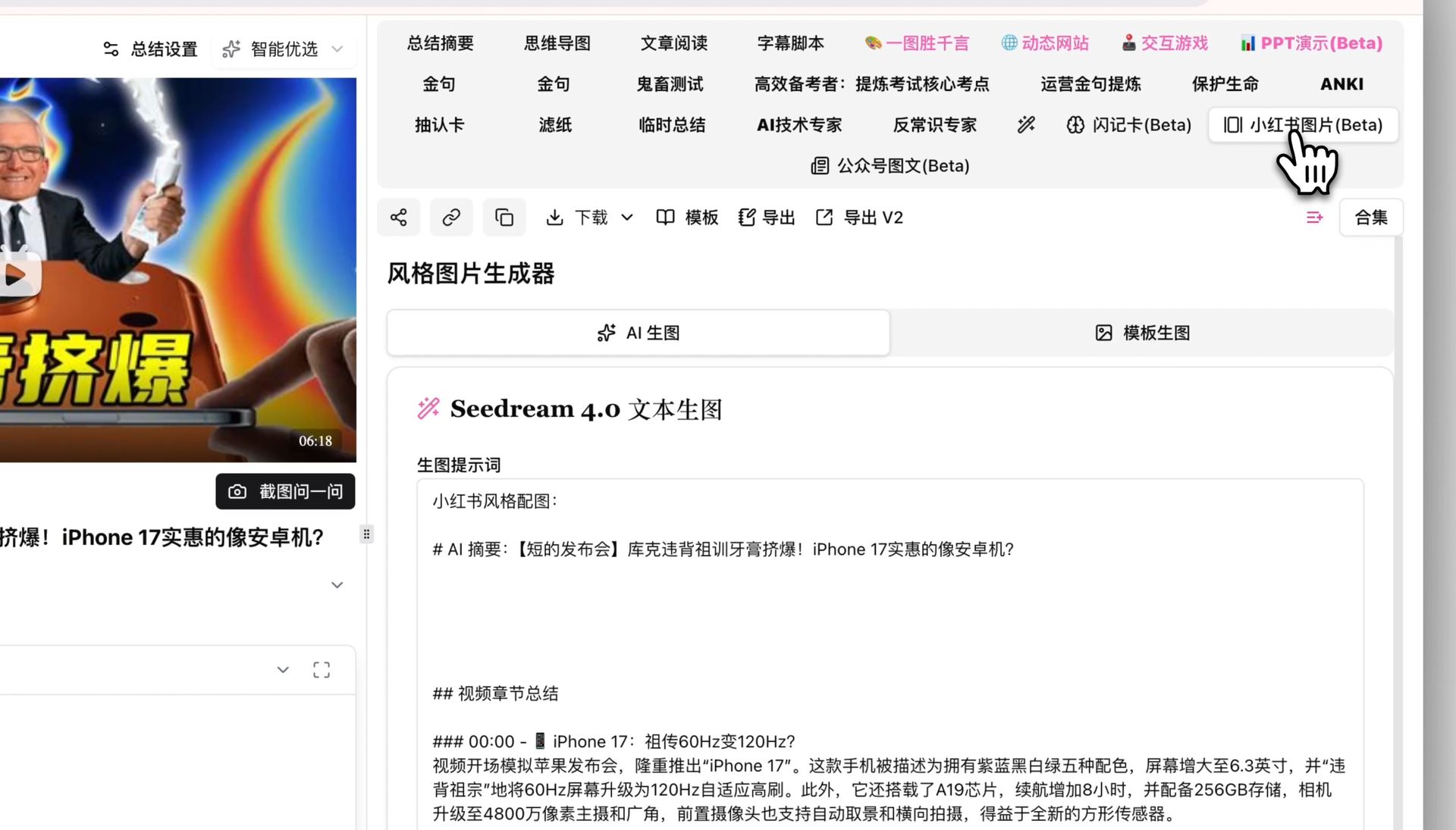
ワークフロー全体で最も体力を使うのが「要点を探す+メモする」工程。ここはAIに任せるのが一番。BibiGPT 動画要約 を開いて動画リンクを貼るだけ——YouTube・Bilibili・TikTok・小紅書・ポッドキャストなど30以上のプラットフォームに対応、ローカルファイルのアップロードも可能です。数分で次が手に入ります:
- TL;DR:動画全体が何を語っているか、3〜5文で
- セクションごとの要点+タイムスタンプ:各セグメントの核心論点と対応時刻
- キーフレーズ:そのままノートの小見出しに使える発言
ここでのコツ:要点が出たらすぐ使わず、まず「カードにできるか」でふるい分けます。40分の動画ならAIは10個のセクションを出すかもしれませんが、小紅書ノートには最大5〜6枚のカードしか入りません。だからやるのは二次選抜——意外性のある、常識破りな、または最も実用的なポイントを選びます。
下のインタラクティブなデモで、サンプル動画を自分で選んで、AIが出すTL;DR+要点+タイムスタンプを見てみてください:
どんな動画も数秒で要約
サンプルを選ぶと AI 要約が表示——結論ひとこと、要点リスト、ジャンプできるタイムスタンプ。
ひとこと: Karpathy が GPT 風の言語モデルをコードでゼロから構築。小さな文字レベルモデルから完全な Transformer まで、各パーツを丁寧に解説。
要点
- まず bigram モデル、次に自己注意を加えてトークン同士を"対話"させる
- Transformer ブロック = マルチヘッド注意 + 順伝播 + 残差接続 + 層正規化
- 学習は「次のトークン予測」だけ。あとは規模とデータ次第
- nanoGPT の背後の構造を拡大したものが ChatGPT
ジャンプ
- 00:07 なぜゼロから作るのか
- 08:23 自己注意を直感的に
- 1:00:00 Transformer ブロックの組み立て
- 1:35:00 nanoGPT から ChatGPT へ
実践ルール: AIが出すセクションは「全量」、あなたが欲しいのは「精選」。8個を浅くなぞるより、3個を徹底的に語り切るほうがいい。
3. ステップ2:小紅書ノートのテンプレートに当てはめ、要点を画像ノートに
精選した要点が揃ったら、ノートがバズるかを実際に決めるのは型です。小紅書の画像ノートには比較的固定された高転換の構造があるので、そこに当てはめるだけです:
タイトル:3秒で刺すフックの公式
小紅書のタイトルの本質は「一文でタップする理由を作る」こと。よく使う公式:
- 数字+痛点:「40分のポッドキャストを見て、覚えるのはこの3文で十分」
- 常識破り:「実はXはずっと間違ってた?この動画が解き明かす」
- アイデンティティ訴求:「社会人必見|今回でXがやっと分かった」
本文:フック → 中身 → 行動
- 冒頭のフック:前置きせず、結論や痛点を先に(小紅書の最初の画面は冒頭数行しか表示されない)
- 3〜5個の中身:各行を絵文字で始め+一文の要点、それぞれ画像カードに対応
- 締めの行動指示:「保存」「コメントで次に見たい回を教えて」「フォローして更新を追う」
画像:表紙+内ページカード
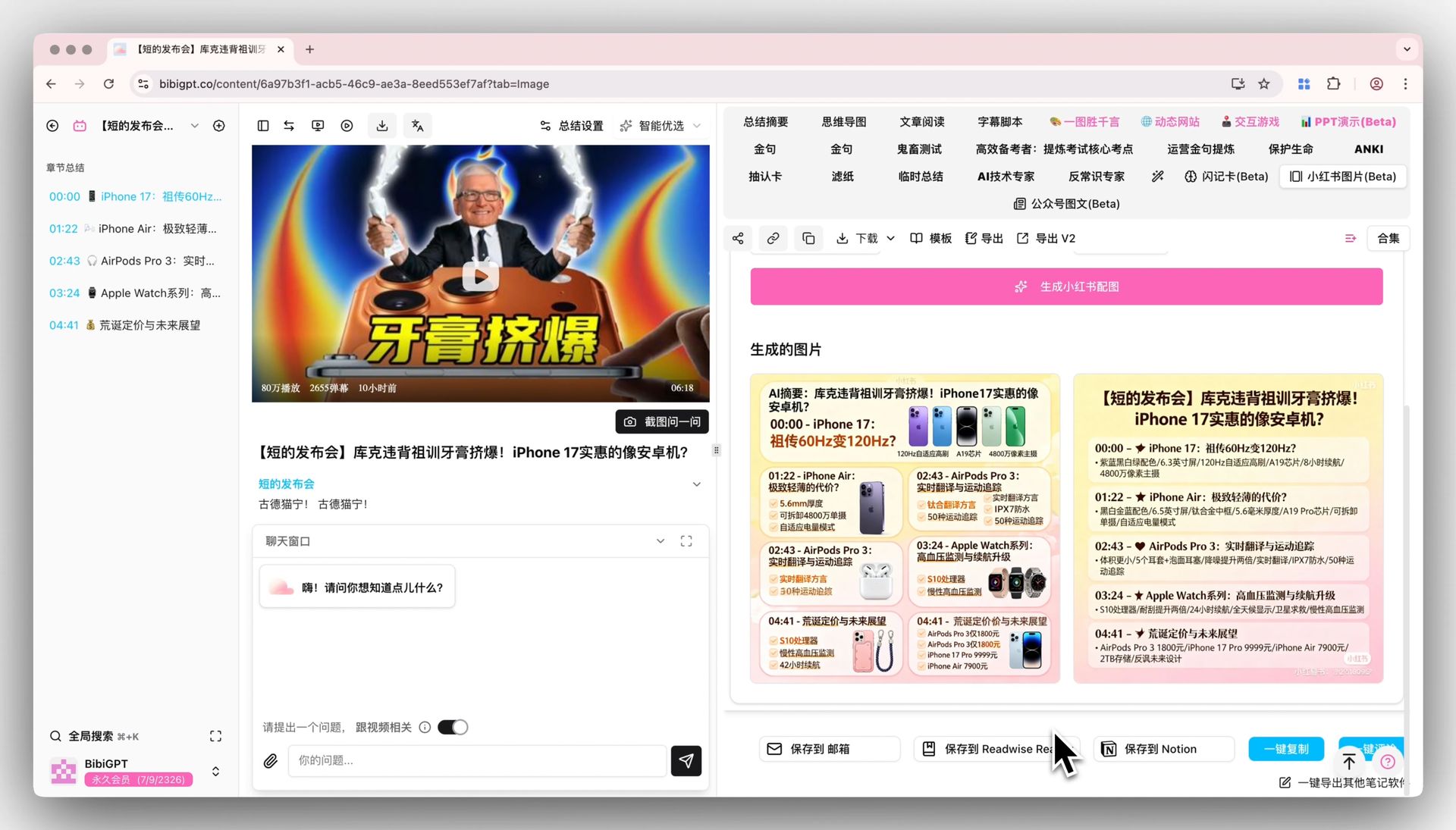
表紙はクリック率を、内ページカードは読了率を決めます。ここでAI画像生成が活躍します——BibiGPT 小紅書画像生成 で各要点をそのまま対応スタイルの画像カードに生成すれば、Canvaで一枚ずつ並べる必要はありません。
| ノートの部品 | 役割 | 内容の出どころ |
|---|---|---|
| 表紙画像 | クリック率を決める | 最も意外性のある要点 |
| タイトル | タップする理由を作る | AIのキーフレーズ+数字/痛点の公式 |
| 中身カード | 読了率を決める | 精選後の3〜5個の要点 |
| 締めのCTA | エンゲージ率を決める | 「保存/フォローして更新」 |
4. ステップ3:視覚化分析で「画面の中の情報」を補う
多くの動画の価値は「何を言ったか」だけでなく「何を映したか」にもあります——チュートリアルの操作手順、発表会の製品画像、講義の板書や図表など。字幕だけの抽出ではこの部分を取りこぼします。
そこで BibiGPT 視覚化分析 の出番。AIが動画のキーフレームを自動で抽出し「画像を見て説明」、画面内容も使える画像ノートの要点に変えます。操作系・展示系の動画では、この工程でノートの情報密度が一気に倍増します。
画面分析パネルはフレームごとに画像+テキストの解説を出すので、そのままノートカードに選んで使えます:
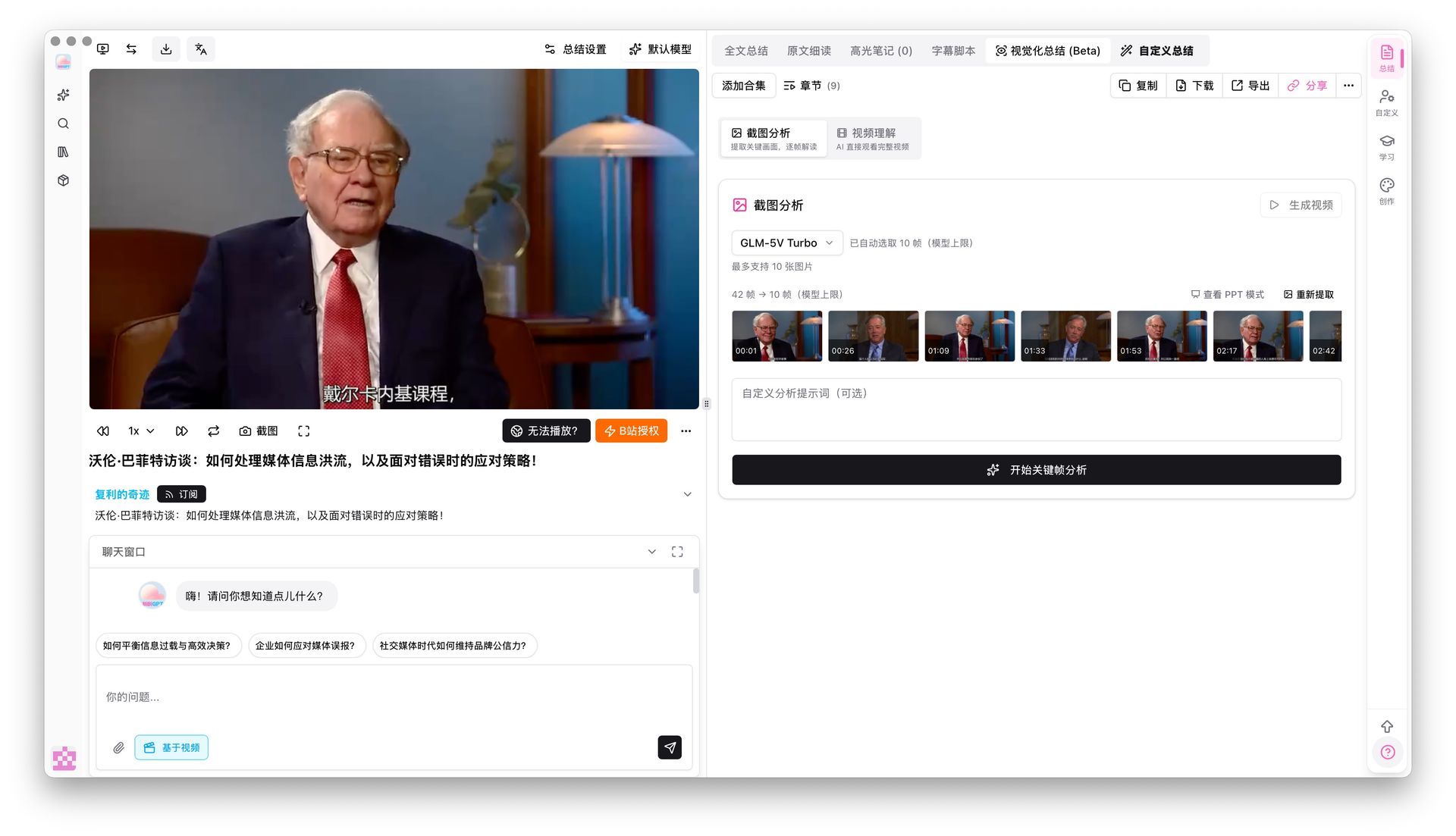
下のデモで、AIが動画のキーフレームから画面情報をどう読み取るか見てみてください:
動画のフレームを図解ノートに
AI は音声だけでなく画面も見ます——スライド、図表、画面の文字まで文章化。
キーフレーム

画面の文字: nanoGPT
Karpathy が bigram モデルをライブコーディング——現在の文字から次を予測する最も単純なモデル。
実践ルール: 動画に「言わないが映している」情報(手順・図表・製品)があるなら、字幕だけでなくAIに画面も読ませましょう。
5. ステップ4:投稿前の注意点チェックリストとリズム
技術的な作業が終わったら、この最後の工程がノートの生死を決めます。
- 他人の動画内容を丸ごと転載しない:二次創作には自分の見解とまとめが必要——単なる転載は価値がなくリスクもあります。AIの要点は骨格、肉は自分でつける
- 表紙を文字だけにしない:小紅書はビジュアル・プラットフォーム。表紙には最低限、配色とレイアウトを
- 投稿時間:Hootsuite のソーシャル投稿タイミングの調査によれば、平日の昼休み(12〜13時)と夜(19〜22時)が一般にエンゲージのピーク。これに合わせて投稿リズムを組む
- 1本の動画を複数ノートに分割:1回のポッドキャストを異なる切り口の3本に分けるほうが、無理に1本に詰め込むよりフォロワーが伸びる
よくある質問(FAQ)
動画を小紅書ノートにする際、AIが抽出した内容はそのまま投稿できますか?
おすすめしません。AIが渡すのは構造化された要点(骨格)ですが、小紅書のノートには自分の見解、調整したトーン、フックの見出しが必要です。AIを「8割の体力仕事を肩代わりする助手」とし、最後の2割の「人間味」は自分で足す——そうすれば速く、かつ画一的になりません。
どんな動画が小紅書ノートに分解するのに向いていますか?
情報密度が高く、明確なポイント構造のある動画が最適です:知識系ポッドキャスト、オンライン講座、業界分析、製品レビュー、チュートリアル。純粋なエンタメ・ストーリー系は、価値が「情報ポイント」にないため、かえって分解しにくいです。
1本の長尺動画を何本のノートにできますか?
40分以上の情報系動画なら、通常は異なる切り口で2〜4本に分割できます。例えば「AIツール」のポッドキャストなら「無料の3ツール」「今回が反対した1つの見解」「初心者向けの入門ルート」の3本にして、異なる検索意図をカバーできます。
画像は必ずAI生成にする必要がありますか?
必須ではありませんが、AI画像生成は最も時間のかかる工程を省けます。自分のデザインテンプレートとセンスがあるなら手動でも構いません。ただ、要点を素早く見られるカードにしたいだけなら、AI生成の画像カードが最もコスパの高い選択です。
6. 「見て忘れる」から「継続的に産出する」へ
上の4ステップをつなげれば、再現可能なコンテンツ・パイプラインの完成です:
- 良い動画を見つける → リンクを BibiGPT に貼る
- 要点を得る → AIがTL;DR+セクション要点+画面情報を出力
- 精選する → 独立して成立する3〜5個のポイントを選ぶ
- テンプレートに当てはめる → フックの見出し+中身カード+行動CTA
- 画像を付けて投稿 → AIが表紙と内ページカードを生成、リズムに沿って投稿
コンテンツを本当に使いこなす人は、見た動画の本数ではなく、良いコンテンツ一つひとつから二次的価値を絞り出した人です。BibiGPTは100万人以上のユーザーに利用され、500万件以上のAI要約を生成、30以上のプラットフォームに対応——目指すのはまさにこれ。動画を消費する速度を、すぐ自分の作品に変えられるほど速くすることです。
関連記事:
- 動画からスライドへ:AIで動画からPPTを抽出
- Claude Opus 4.8 の100万トークン・コンテキストが長尺動画要約にもたらすもの
- ポッドキャストを学習ノートに:4ステップ間隔復習ワークフロー
- AI動画から記事ジェネレーター完全ガイド
今日見た動画を今すぐ小紅書ノートに変えたいですか?BibiGPT 動画要約 を開き、リンクを貼って、あとはAIに任せましょう。
BibiGPT チーム