Gemini 3.1 Flash Image 能直接读视频出封面了,BibiGPT 的画面分析还有优势吗?
Gemini 3.1 Flash Image 能直接读视频出封面了,BibiGPT 的画面分析还有优势吗?
截至 2026 年 6 月 2 日: 2026 年 5 月 28 日,Google 在 Gemini API changelog 里给 gemini-3.1-flash-image 加了一个值得注意的能力——它现在能直接吃一段视频文件,甚至一条 YouTube 链接,然后据此生成缩略图、海报这类视觉产物。这一步正面撞上了 BibiGPT 一直在做的事:把视频画面看懂,再变成图文。下面这篇就把这次升级讲清楚,再聊聊在「视频→图文产物」这条链路上,两者到底各自强在哪。
一、这次升级到底改了什么
把上面的话题放到屏幕里看效果——下面这条视频值得花几分钟过一遍:
视频来源:YouTube · 萊丘 Laichu · Gemini 3 + AI Studio 最強應用!五分鐘快速掌握免費必學技能 | Laichu
先把事实摆清楚。根据 Google Gemini API 官方更新日志,gemini-3.1-flash-image 这个图像模型在 2026 年 5 月 28 日拿到了一个新输入通道:
- 视频作为上下文:以前文生图模型只吃文字和静态图,现在能把整段视频(或一条 YouTube 链接)当成参考素材
- 直接产出视觉物:基于视频内容生成缩略图、封面、海报,不用你先手动截一堆帧再描述
- 延续 Flash 系列的快:定位仍是「快而便宜」的那一档,适合大批量出图
一句话总结:模型从「读文字画图」进化到了「读视频画图」。 对做封面、做配图的人来说,这确实省了「先看视频→再截图→再写 prompt」的中间环节。
实用规则: 任何一次「模型能直接读视频了」的升级,真正的看点都不是模型本身,而是它替你省掉了哪几步中间搬运。
二、对内容创作者意味着什么
为了避免凭印象判断,下面这张是 gemini.google.com 真实页面截图(截于发文当天):
截图来源:gemini.google.com(截于发文当天)
这次升级的直接受益者,是天天和「视频→图」打交道的人。分三类看:
自媒体 / 短视频作者——做封面是高频刚需。以前要在剪辑软件里翻来覆去找那个「最有代表性的一帧」,现在让模型读完视频帮你出几版封面,确实快。
公众号 / 小红书运营——一条视频拆成图文,配图是绕不开的环节。能直接从视频生成配图,省掉了找图、截图、版权顾虑这一摊事。
电商 / 课程团队——批量给视频出主图、出宣传海报,对「快而便宜」这一档模型的需求最旺。
但这里要说一句冷静话:「能从视频生成一张图」和「能把整段视频变成一篇能直接发的图文」,是两个量级的事。 前者是一个素材点,后者是一条完整产线。模型升级解决的是前者,而创作者真正卡的往往是后者。
实用规则: 评估一个 AI 出图能力时,别只看它能不能出一张好图,要看它能不能接上你「从素材到成品」的整条流程。
三、BibiGPT 不是又一个套壳出图工具
说到「读视频出图文」,很容易让人以为这又是个调模型 API 的套壳产品。事实不是。BibiGPT 已经服务了 100 万+ 用户、累计生成 500 万+ 次总结,支持 30+ 主流音视频平台,它在模型之上叠了一整条产线:
- 画面分析 → 图文产物:不只生成一张图,而是看完整段视频,理解画面在讲什么,再生成公众号图文、小红书宣传图这类能直接发的成品。试试 AI 视频转图文的完整链路
- 章节级深读:把长视频按章节拆开,每段配上要点和画面,长内容也能快速消化
- 多模型路由:底层接了多家模型,哪个出图好用哪个,你不用自己管该调谁
- 源头可追溯:每个要点都能跳回视频原始时间点,不是凭空总结
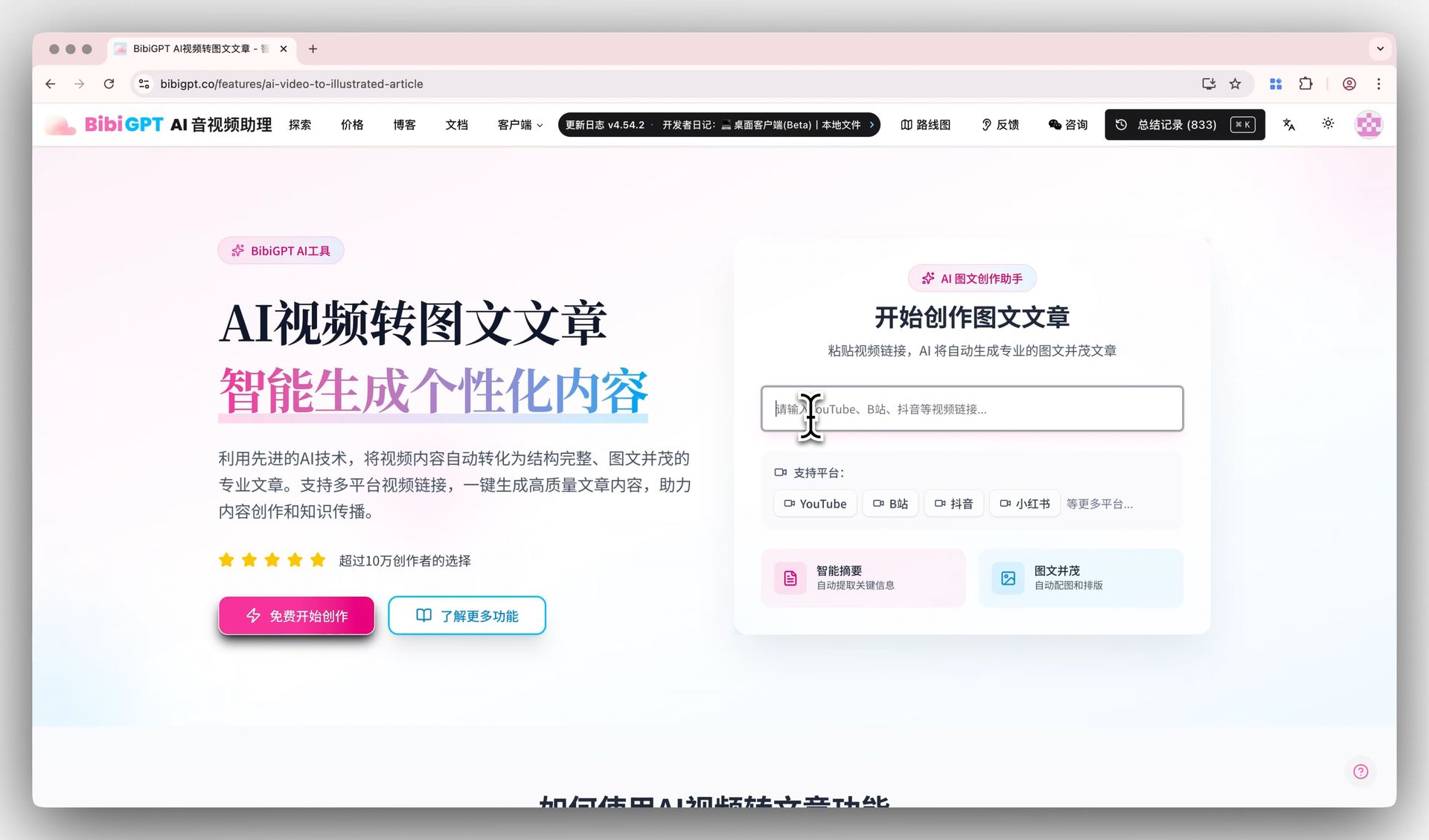
下面这张是 BibiGPT 把一段视频转成图文产物的实际入口:
截图:BibiGPT · AI 视频转图文功能演示
换句话说,单点的出图能力是这条产线里的一环,而不是终点。Google 这次让模型更会「读视频出图」,恰恰把这一环做强了——对 BibiGPT 这种做整条产线的产品反而是利好:底层素材环节更强,上层成品就更好。
四、用 BibiGPT 把一段视频变成图文,实战四步
把上面的差异落到具体操作上。假设你手上有一条 20 分钟的产品讲解视频,想拆成一篇带配图的公众号文章:
- 贴链接,让 AI 看完整段视频——粘贴视频链接,BibiGPT 提取字幕 + 分析画面,几十秒出结构化要点
- 生成图文产物——切到创作面板,选「视频转图文」,AI 按章节生成带配图的图文初稿
- 挑画面、调风格——对关键章节生成配图,不满意就换一版风格
- 导出直接发——一键导出,配图、要点、时间戳都在,复制到公众号即可
对照下面这个交互演示,你能直观感受「贴一条链接→拿到结构化总结」是什么体验:
几秒读完任何视频
选个样例,看 AI 总结——一句话结论、要点清单、可跳转的时间戳。
一句话: Karpathy 用代码从零搭出一个 GPT 风格的语言模型,逐行讲清每个部件——从最小的字符级模型到完整的 Transformer。
要点
- 先做一个 bigram 基线模型,再加自注意力,让 token 之间能"互相对话"
- 一个 Transformer 块 = 多头注意力 + 前馈网络 + 残差连接 + 层归一化
- 训练本质就是"预测下一个 token";剩下的交给规模和数据
- nanoGPT 背后的架构,放大后就是 ChatGPT
跳转
- 00:07 为什么要从零搭 GPT
- 08:23 直观理解自注意力
- 1:00:00 拼出 Transformer 块
- 1:35:00 从 nanoGPT 到 ChatGPT
整个过程里,「从视频生成视觉素材」只是第 3 步的一环;真正帮你省时间的是 1、2、4 这条把素材串成成品的产线。想深入了解这次 Gemini 升级本身,可以读这篇 Gemini 3.1 Flash Image 能力解析;想看画面分析在更复杂场景下的表现,可以体验 视觉化分析:
把画面变成图文笔记
AI 不只听声音,还会看画面——幻灯片、图表、屏幕上的文字,全都帮你整理成文字。
关键画面

画面文字: nanoGPT
Karpathy 现场敲出 bigram 模型——最简单的语言模型,用当前字符预测下一个字符。
五、接下来会怎么走
基于这次升级,给三个判断:
- 「读视频出图」会变成标配:今年内主流出图模型大概率都会支持视频输入,这一能力本身不再是壁垒
- 竞争会上移到「产线」层:当人人都能从视频出一张图,比的就是谁能把出图接进「素材→成品→发布」的完整流程
- 可能催生的衍生品:自动封面 A/B、按平台尺寸批量出图、视频要点+配图一键成稿——这些都是产线层的机会
模型不再稀缺,能把视频快速变成你能直接用的成品,才稀缺。这也是 BibiGPT 一直锚定的位置——让消费和再创作音视频,像处理文字一样快。
实用规则: 当某个 AI 能力变成人人都有的标配,价值就从「拥有这个能力」转移到「把它接进你的完整流程」。
六、常见问题
Q1:gemini-3.1-flash-image 能直接替代视频转图文工具吗? 它解决的是「从视频生成一张图」这个素材点,不负责把整段视频拆成带要点、带时间戳、能直接发的图文成品。后者需要总结 + 画面分析 + 排版导出的完整产线。
Q2:BibiGPT 用的是哪个出图模型? BibiGPT 底层接了多家模型并自动路由,你在创作面板里直接用即可,不用关心调用哪个、也不用自带 API Key。
Q3:从视频生成的图,版权上安全吗? AI 生成的配图避开了找图、截图的版权顾虑,但具体使用前仍建议按所在平台规则确认。BibiGPT 生成的图文产物供你二次编辑后发布。
Q4:长视频也能处理吗? 可以。BibiGPT 支持章节级深读,把长视频按段拆开处理,每段配要点和画面,30+ 平台的长内容都能消化。
Q5:这次升级对普通用户有直接影响吗? 普通用户感知不到模型层变化,但会享受到「视频→图文」整条链路变得更顺更快的结果。
现在就试试
把一条视频粘进去,看 AI 几十秒把它拆成带配图的图文要点——比手动截图写文案快得多。
BibiGPT 团队