论文 → 思维导图 → 知识库:用 BibiGPT 把一篇论文吃透的 4 步法 (2026 方法论)
论文 → 思维导图 → 知识库:用 BibiGPT 把一篇论文吃透的 4 步法 (2026 方法论)
80 字直答:把一篇论文真正吃透,最有效的不是只读 PDF,而是 PDF + 作者讲解视频 + 同主题相关论文 三路并行。BibiGPT 4 步法:① 定向阅读论文 → ② 找到对应讲解视频/会议演讲做 AI 总结 → ③ 生成可点击的思维导图 → ④ 把所有论文沉淀进合集知识库做 AI 对话追问。读完一次就能跨论文检索、跨主题联想。
读论文最痛苦的体感是什么?我问过 200 多位用户,回答惊人一致:“看完合上电脑,半小时后不记得论文讲了什么”。
PDF 是阅读的死亡形态,因为它:
- 没有时间轴 → 你不知道哪段是关键论证;
- 没有图谱 → 章节之间的概念关系藏在文字里;
- 没有对话 → 看不懂的地方只能反复重读;
- 没有沉淀 → 这篇看完跟下一篇之间断层巨大。
这篇文章给你 BibiGPT 论文吃透 4 步法 —— 一套可以从今晚开始执行的方法论。配 5 个真实场景示范。
4 步法总览
第 1 步:定向阅读论文(PDF 不变,但加问题驱动)
↓
第 2 步:找作者讲解视频 / 会议演讲,用 BibiGPT 做 AI 总结
↓
第 3 步:生成可点击的思维导图,把概念关系可视化
↓
第 4 步:把所有相关论文 + 视频沉淀进 BibiGPT 合集知识库,跨论文 AI 对话追问每步都有具体动作 + BibiGPT 工具支撑。
第 1 步:定向阅读论文(先想问题,再看 PDF)
最大的反模式是”打开论文从摘要读到参考文献”。研究表明,被动线性阅读的留存率不到 20%。
正确姿势:阅读前先写下 3 个问题。
举例:你要读 “OpenAI o3 system card”,先写:
- o3 相比 o1 的核心架构变化是什么?
- 它在 ARC-AGI 上的得分背后用了什么 trick?
- 这对我们用 BibiGPT 做视频总结有什么启发?
带着问题打开 PDF,看到答案就停下来记。这一步不需要任何工具,但能提升你对后续步骤的吸收效率 3-5 倍。
第 2 步:找作者讲解视频,做 AI 总结
90% 的高引用论文在 NeurIPS / ICML / 实验室 YouTube 频道 / 播客访谈上都有作者本人讲解。作者口述的 30 分钟 = PDF 里 50 页的精华。
为什么?因为讲解视频自带:
- 重点强调的语气和重复(PDF 平铺直叙);
- 提问环节暴露 PDF 没明说的边界条件;
- 视觉示意图(slide 比正文公式更直观)。
用 BibiGPT 操作:
- 在 YouTube / B 站搜
"<论文标题>" + "作者名" + lecture/talk/session; - 把视频链接粘贴到 bibigpt.co;
- 选择 自定义提示词总结,使用模板:
作为论文阅读助理,请按以下结构总结: 1. 论文核心 claim(1 句话) 2. 三个最重要的实验设置 3. 与已有方法的关键差异(用对比表) 4. 作者口述但 PDF 里写得不够清楚的 caveat / 边界条件 5. 我应该把哪段 paper 重点回去精读? - 把这条提示词通过 自定义总结置顶默认 设为默认,所有论文讲解视频自动按这套结构产出。
体感:原本 30 分钟讲解 + 90 分钟看论文,现在 15 分钟讲解 AI 总结 + 30 分钟带问题精读 PDF,时间砍半,留存翻倍。
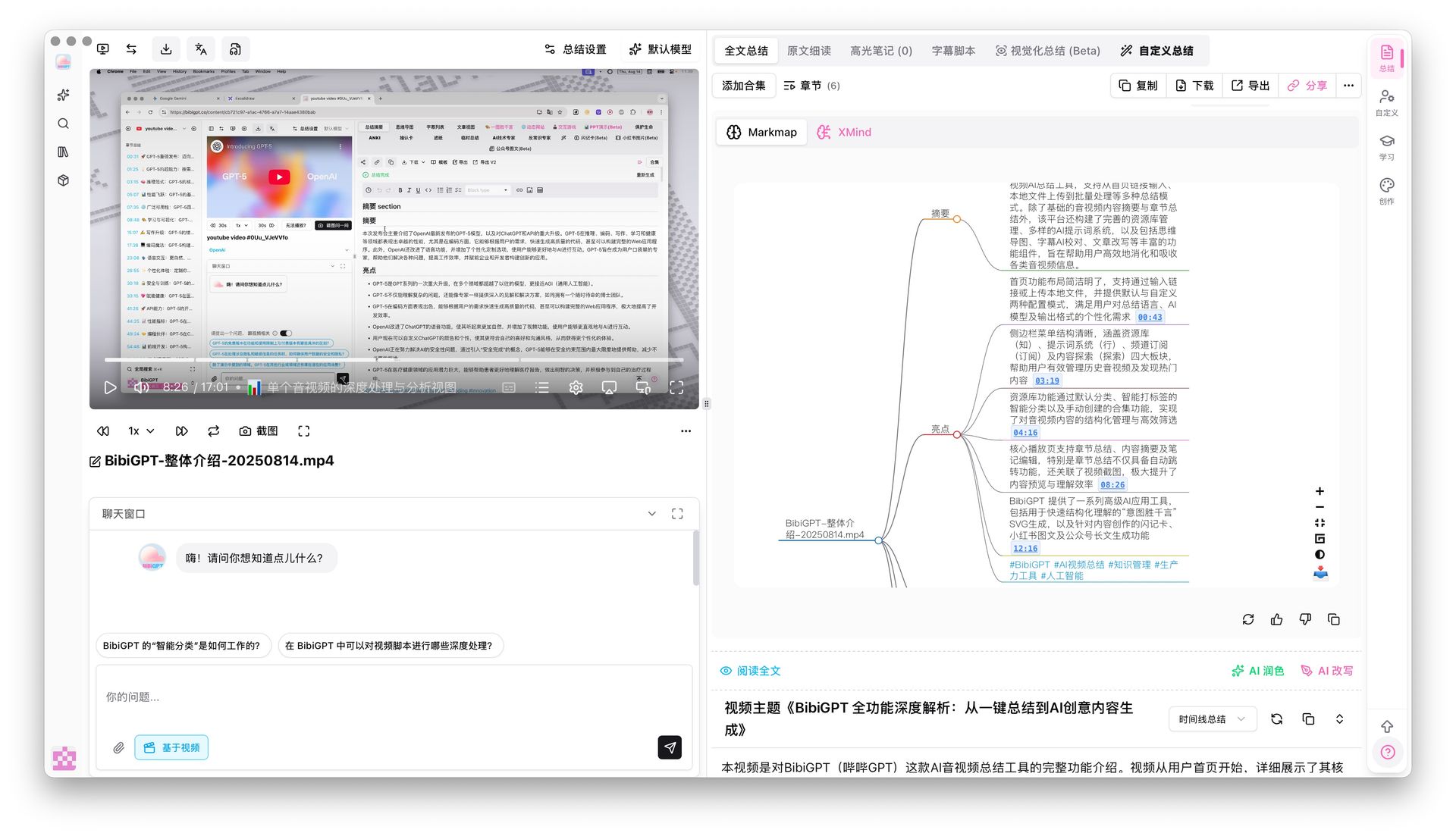
第 3 步:生成可点击的思维导图
读完讲解 + PDF 后,最关键的动作是让概念之间的关系长出来。
文字稿是线性的,但知识是网状的。BibiGPT 的思维导图时间戳跳转把讲解视频自动转成可点击的 Markmap:
- 每个节点 = 论文一个核心概念;
- 节点之间 = 论文里的论证链路;
- 点击任意节点 → 视频跳转到对应时间点(你能听原话);
- 同时支持导出成 Markdown,丢进 Obsidian 直接用。
进阶用法:把多篇相关论文的思维导图导出后合并到一张大图——你能直观看到这些论文之间的概念交集(共享的方法论)和差异(独家创新点)。这是单独读 PDF 永远做不到的。
第 4 步:合集知识库——所有论文沉淀进同一个 AI 对话
到这一步,你可能已经读了 5-10 篇论文 + 讲解视频。下一个反模式:这些论文各自孤立,下次找一个引用还是得重新打开 PDF。
正确做法:用 BibiGPT 的 合集 AI 对话 把所有论文 + 视频聚合成一个可对话的知识库。
具体动作:
- 在 BibiGPT 资源库里新建合集,命名为
<研究主题>,例如”AI Reasoning 2026”; - 把每篇论文的讲解视频总结、AI 整理稿、思维导图全部归入合集;
- 进入合集页面,使用合集归纳总结生成”主题级”综述(基于合集内所有视频内容);
- 在合集 AI 对话框里直接问跨论文问题:
- “这 5 篇论文对 reasoning 的定义有什么差异?”
- “哪一篇的实验设置最严谨?”
- “如果我要写一篇综述,引用顺序应该是什么?”
- 写论文 / 写综述时,用全局搜索 - 深度搜索直接在所有合集字幕里搜关键词。
真正的复利来了:你读的每一篇新论文都会让合集变得更”懂”这个领域,跟你的 AI 对话伙伴一起成长。
5 个真实场景示范
场景 1:CS 博士生跟进 LLM 最新进展
- 每周固定 4 篇论文 + 4 个 NeurIPS / ICML 讲解视频;
- 全部归入 “LLM Frontier 2026” 合集;
- 周五用合集归纳总结生成”本周综述”,发给导师。
场景 2:产品经理研究 AI 产品趋势
- 看 Anthropic / OpenAI / Google 的发布会演讲 + 对应 system card PDF;
- 合集名”AI Product 2026”,每周对话:“本周哪些功能值得我们做”;
- 直接产出竞品分析 doc。
场景 3:研究生准备开题报告
- 把导师推荐的 30 篇 reference + YouTube 上对应作者的 talk 全部喂给 BibiGPT;
- 用合集归纳总结生成”领域脉络”;
- 开题答辩时拿着 BibiGPT 思维导图讲,评委被惊艳。
场景 4:内容创作者做”论文带读”系列
- 把读论文的讲解视频做成 BibiGPT 总结 + 思维导图;
- 用 视频转图文 直接生成小红书 / 公众号深度长文;
- 一篇论文产出 1 个视频 + 1 篇图文 + 1 张思维导图,单篇产能翻 3 倍。
场景 5:跨领域学习者打通新领域
- 不熟悉的领域不要一上来就硬啃论文;
- 先在 YouTube 看 5 个不同 angle 的”领域科普视频” → BibiGPT 总结 → 找出最常被提到的关键概念;
- 再去精读 2-3 篇核心论文,配讲解视频,按本文 4 步法吃透。
论文阅读 PKM 闭环:从 BibiGPT 到 Obsidian / Notion
很多研究者已经有 Obsidian / Notion 双链笔记系统。BibiGPT 4 步法的产出可以无缝接入:
- BibiGPT 思维导图导出 Markdown → Obsidian 双链笔记;
- BibiGPT 包含字幕原文的笔记导出 → Notion 数据库(每行一篇论文);
- BibiGPT Cubox 集成 一键归档读后感;
- 完整工作流详见 BibiGPT 知识库 PKM 实战指南。
FAQ
Q1:我没有时间看 30 分钟讲解视频,能不能直接读 PDF?
可以,但建议先用 BibiGPT 的 视频转文章 把讲解视频转成 5-10 分钟可扫读的 markdown,看完再带着问题进 PDF。
Q2:论文没有讲解视频怎么办?
三个备选:① 找同主题的讲座视频(不一定是同一作者);② 找 podcast 访谈(很多 AI 研究者上播客);③ 把 PDF 上传到 BibiGPT,本地隐私模式 处理后做对话追问。
Q3:BibiGPT 思维导图能脱离视频独立看吗?
能。导出为 Markdown / Markmap 文件后可以脱离 BibiGPT 单独打开,但失去时间戳跳转能力——回到 BibiGPT 才能听原话。
Q4:合集知识库会不会太多导致 AI 对话变慢?
BibiGPT 的合集知识库后端用了多模型路由,Gemma 4 31B 模型 的 256K 上下文专门处理长合集场景,几十篇论文都能稳定对话。
Q5:这套方法论是不是只适合 AI / CS 论文?
不是。我们有用户用同一套流程读法律判决书 + 庭审视频、读医学指南 + 临床示教视频、读财报 + earnings call 录音——任何”长文档 + 可视化讲解”的领域都适用。
内链与延伸阅读
- 学习方法论:费曼学习法 + AI 视频学习
- 知识管理:AI 视频学习的主动回忆方法
- 工作流深挖:AI 增强课程幻灯片学习看板
- 工具基础:BibiGPT 完整指南 2026
读论文最大的复利是:你读的每一篇都让你下一次读论文更快。BibiGPT 4 步法把这个复利从”凭意志”变成”工具自动累积”。现在打开 BibiGPT,把你正在读的那篇论文的讲解视频粘进去试试。
—— BibiGPT 团队