Claude Opus 4.8 的 100 万 token 上下文,给长视频总结带来了什么?(2026 深度解读)
Claude Opus 4.8 的 100 万 token 上下文,给长视频总结带来了什么?
截至 2026 年 5 月 28 日: Anthropic 正式发布 Claude Opus 4.8,带来三个值得关注的能力升级——100 万 token 的上下文窗口、可控的 effort(思考努力)等级、以及更快的 Fast 模式。对普通用户来说,这些参数听起来很抽象;但如果你经常需要消化长视频、长播客或几个小时的会议录音,这次升级的意义其实非常具体:超长的内容,AI 终于可以一次性整段读完,不用再被切成碎片。
一、事件背景:Opus 4.8 到底升级了什么
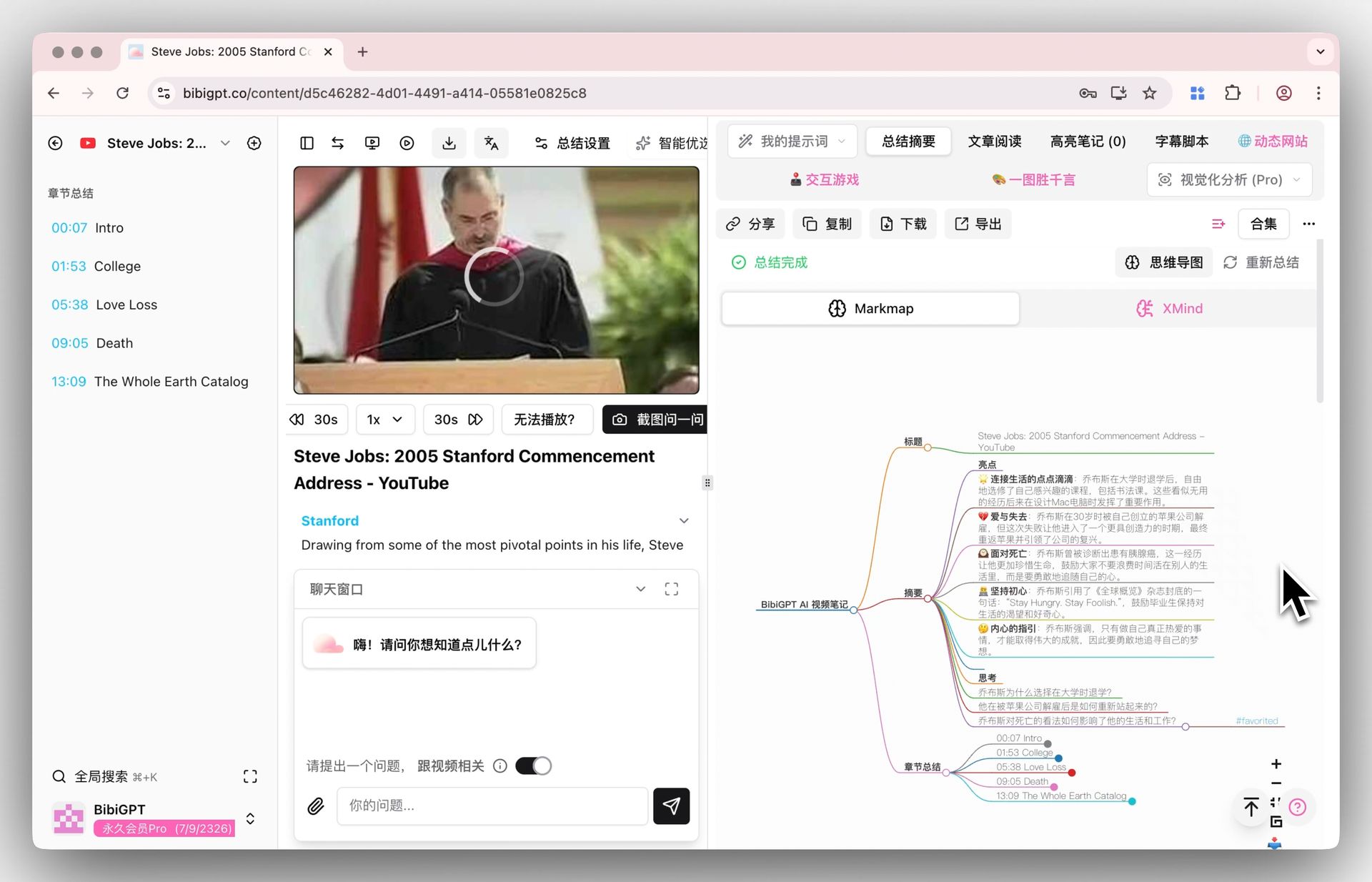
如下图所示,BibiGPT 在这一步的处理方式是这样的:
截图:BibiGPT · ai video to article 功能演示
发生了什么
2026 年 5 月 28 日,Anthropic 在其官方发布页公布了 Claude Opus 4.8。和过往「跑分又涨了几个点」的常规迭代不同,这次升级的几个方向都直接戳中了「处理长内容」这个场景:
- 100 万 token 上下文:可以理解为 AI 一次能「读进脑子」的内容量大幅扩张。100 万 token 大约相当于几十万字的文本,足够装下一整本书、一场数小时的会议、或一整季播客的文字稿。
- 可控的 effort 等级:用户可以决定让 AI「快速扫一遍」还是「慢慢深想」。简单任务用低 effort 求快,复杂任务用高 effort 求深,把速度和深度的取舍交还给使用者。
- Fast 模式提速:响应更快,且成本相比上一代更低——这意味着「快速过一遍长内容」这件事,门槛降下来了。
时间线
| 时间 | 事件 |
|---|---|
| 2026 年初 | 长上下文成为各家大模型竞赛焦点,10 万~20 万 token 是主流 |
| 2026 年 Q1-Q2 | 多个模型陆续把上下文推到 100 万 token 级别 |
| 2026 年 5 月 28 日 | Anthropic 发布 Claude Opus 4.8:1M 上下文 + 可控 effort + Fast 模式 |
为什么这件事对「内容消费者」重要
过去,AI 处理一段两小时的视频或播客时,往往要先把字幕切成很多块,分别总结,再把这些小总结拼起来。这套「分块再拼接」的做法有个天然的毛病:AI 看不到全局。前半段提到的人物,到后半段再出现时它可能已经「忘了」;一个贯穿全片的论证链条,被切碎后逻辑关系容易丢失。
100 万 token 上下文的意义,就是让「整段读完」成为可能。AI 不再是隔着窗户一段段窥视,而是把整本「书」摊开在面前一次看完——这对长视频、长播客、长会议的总结质量,是结构性的提升。
实用规则: 上下文窗口决定 AI「一次能看多少」。处理长内容时,窗口越大,跨段落的逻辑和细节就越不容易丢。
下面这条演示走一遍「一段视频 → 完整结构化总结」的过程:
来源:YouTube · AI 长视频总结演示
二、深度分析:百万 token 上下文改变了什么
下面这张是 BibiGPT 里对应的实拍画面,可以一眼对照:
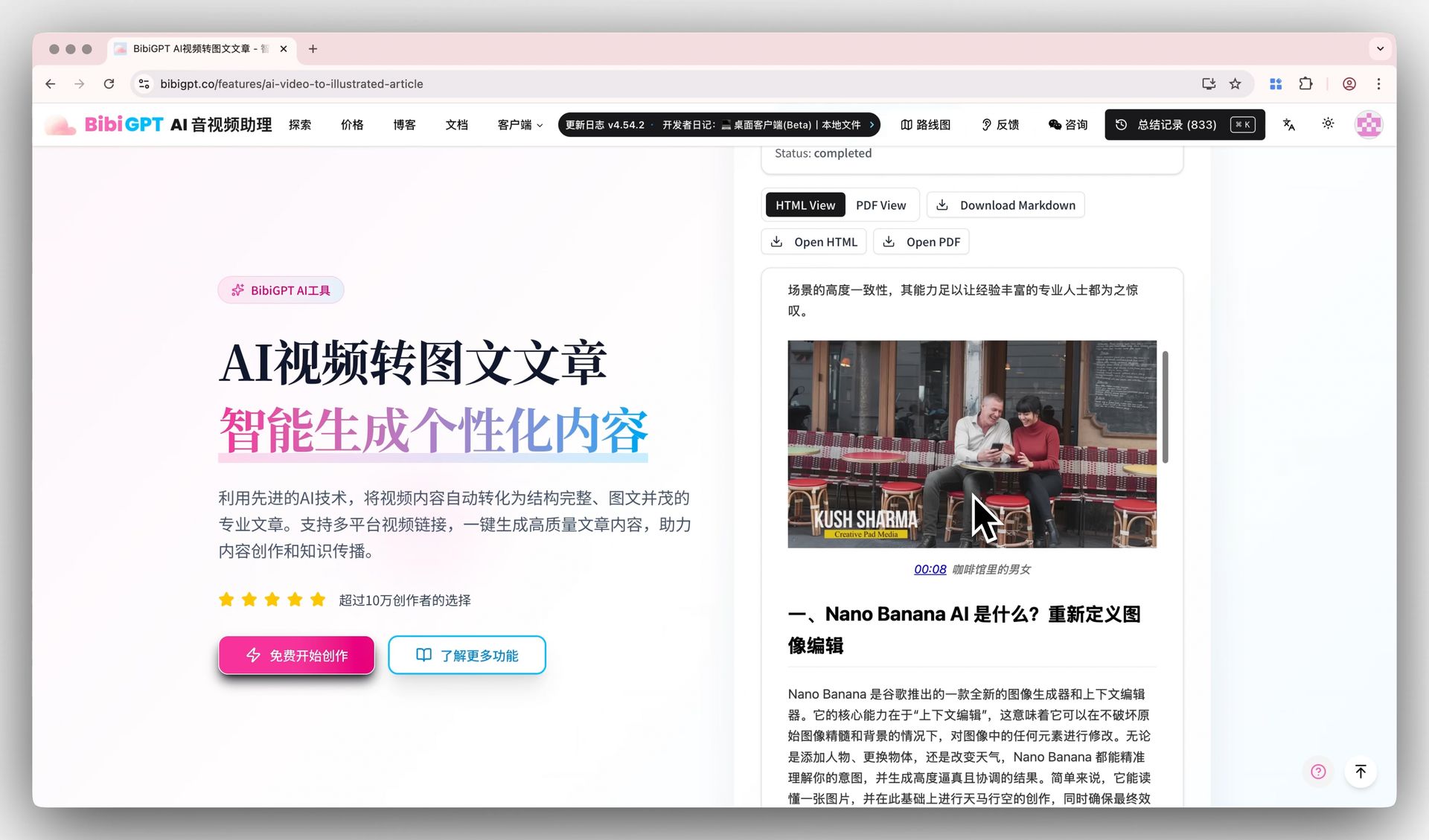
截图:BibiGPT · ai video to article 功能演示
2.1 技术影响:从「分块拼接」到「整段理解」
把长内容切块处理,本质是受限于上下文窗口不得不做的妥协。它最大的代价是连贯性丢失:一场三小时的访谈,可能在第 2 小时回应了第 1 小时的某个观点,分块处理时这两段被切到了不同批次,AI 很难把它们关联起来。
当上下文扩张到 100 万 token,一整段长内容可以一次性喂进去。AI 能看到完整的叙事弧线、贯穿全片的人物和概念、前后呼应的论证。这对总结质量的提升不是「更快」,而是「更准、更完整」——尤其是对那些信息高度关联、需要全局理解的长内容。
2.2 体验影响:分层思考让「快」和「深」可以兼得
可控的 effort 等级,解决的是另一个老问题:不是所有总结都需要同样的深度。
- 你只想知道「这条 1 小时的视频大概讲了啥,值不值得看」→ 低 effort,几秒给你一个 TL;DR
- 你要把一节网课整理成考试复习材料,需要逐章节的精确要点 → 高 effort,慢一点但更细致
过去这两种需求往往只能用同一档处理,要么快但浅,要么深但慢。分层 effort 让使用者按需取舍,这正好对应了内容消费的两种典型场景:先快速筛选,再深度消化。
2.3 生态影响:模型在变好,但「消费速度」才是真稀缺
值得冷静看待的一点是:底层模型每隔几个月就会变得更强、更快、更便宜,这是行业的确定性趋势。1M 上下文今天是新闻,半年后会变成标配。
所以对内容消费者来说,真正值得关注的不是「哪个模型最新」,而是「我能不能把变强的模型能力,立刻用在我每天要消化的视频和播客上」。模型本身正在变成基础设施般的存在——模型不再稀缺,能不能把长内容快速消费掉、变成自己能用的东西,才是稀缺的。
实用规则: 别追模型版本号。你真正需要的是一个稳定的入口,让底层模型变强时,你处理长视频的体验自动跟着变好。
三、对内容消费者的实际意义(分角色)
百万 token 上下文带来的「整段不截断理解」,对不同人群的价值不一样:
- 学生 / 终身学习者:一节 90 分钟的网课、一场学术讲座,可以一次性整段总结成带章节结构的复习材料,而不是被切碎后逻辑断裂的要点堆。
- 职场人 / 研究者:几个小时的行业播客、财报电话会、深度访谈,能被完整读完并提炼出贯穿全场的核心论点,跨段落的因果关系不再丢失。
- 创作者:把别人的长视频/长播客整段喂入,快速拿到全局结构,再据此做二创选题——长内容的「信息富矿」终于可以被高效开采。
下面这个交互演示,你可以选一个样例视频,亲手看 AI 输出的完整 TL;DR + 分章节要点 + 时间戳:
几秒读完任何视频
选个样例,看 AI 总结——一句话结论、要点清单、可跳转的时间戳。
一句话: Karpathy 用代码从零搭出一个 GPT 风格的语言模型,逐行讲清每个部件——从最小的字符级模型到完整的 Transformer。
要点
- 先做一个 bigram 基线模型,再加自注意力,让 token 之间能"互相对话"
- 一个 Transformer 块 = 多头注意力 + 前馈网络 + 残差连接 + 层归一化
- 训练本质就是"预测下一个 token";剩下的交给规模和数据
- nanoGPT 背后的架构,放大后就是 ChatGPT
跳转
- 00:07 为什么要从零搭 GPT
- 08:23 直观理解自注意力
- 1:00:00 拼出 Transformer 块
- 1:35:00 从 nanoGPT 到 ChatGPT
四、实战搭配:怎么把这种能力用在你每天的视频上
底层模型能力的提升,最终要落到一个能用的产品入口才有意义。BibiGPT 智能视频总结 做的就是这件事——把「超长内容整段不截断地总结」变成一个粘贴链接就能用的能力。
一个典型的长内容消费工作流:
- 粘贴链接:YouTube、B 站、抖音、播客等 30+ 平台,或直接上传几小时的本地录音
- 快速筛选:先拿一个 TL;DR,几秒判断这条长内容值不值得深看
- 深度总结:值得看的,让 AI 整段读完,输出带时间戳的分章节要点
- 结构化沉淀:把要点转成思维导图,全局结构一眼看清
下面这个演示,是把一段视频变成交互式思维导图的效果——长内容的全局结构,这样看最快:
把视频变成思维导图
一段线性的演讲,瞬间变成结构化知识树。拖动平移,点节点展开/收起。
值得强调的是:BibiGPT 不是另一个模型聊天框。 在底层模型之上,它叠了一整套专门为「音视频消费」打磨的能力——
- 跨 30+ 平台的链接直读:粘贴即用,不用先下载再上传
- 带时间戳的源追踪:每个要点都能点回原视频对应位置,可核验、不臆造
- 视觉化分析:连画面里的图表、操作、产品也能读出来,不只是字幕
- 合集 / 多视频归纳:一整个系列、一整季播客可以批量处理、统一归纳
这些是「模型变强」本身给不了的——它们是叠在模型之上、面向真实使用场景的产品工程。
实用规则: 模型决定「读得准不准」,产品决定「用得顺不顺」。两者叠加,才是你每天真正需要的体验。
五、前景预测:长内容消费的下一步
基于这次升级,可以做三个判断:
- 上下文窗口会继续卷,但会迅速变成「不值得宣传的标配」。今天的 1M,明年可能是 1000 万。对用户而言,窗口大小的边际价值会递减——「能不能整段读完」很快不再是卖点。
- 「分层处理」会成为内容工具的默认设计。先快速筛选、再按需深挖,这套交互范式会从模型能力下沉到产品体验,成为每个内容工具的标配。
- 竞争焦点会从「模型」上移到「场景」。当所有工具底层都能调到强模型,胜负手会落在「谁把某个具体场景(长视频/长播客/网课)打磨得最顺」。
常见问题(FAQ)
100 万 token 上下文,对我看视频到底有什么用?
最直接的好处是:很长的视频或播客(几小时)可以被 AI 一次性整段读完再总结,而不是切成很多块分别处理。整段理解意味着跨段落的逻辑、人物、论点关系不容易丢,总结更完整、更准确。
effort 等级是什么,我需要手动调吗?
effort 等级就是让 AI「快速过一遍」还是「慢慢深想」的开关。多数好的产品会按场景自动选——快速筛选时求快,深度整理时求深,你通常不需要手动操心,只要知道「先扫一遍再细看」是更高效的消费方式即可。
模型升级了,我用的视频总结工具会自动变好吗?
如果你用的是一个把底层模型抽象掉的产品入口(而不是直接调某个固定模型),那么底层模型变强时,你的体验通常会自动跟着提升。这也是为什么对用户来说,选一个稳定好用的入口,比追某个具体模型版本更重要。
长视频整段总结,和分段总结相比有什么区别?
分段总结是把内容切块、分别处理、再拼接,容易在拼接处丢失前后呼应的逻辑。整段总结让 AI 看到全局,贯穿全片的论证、人物和概念关系都能保留,尤其适合信息高度关联的长内容。
六、AI 时代的核心竞争力:消费内容的速度
回到最开始的那个判断:模型不再稀缺,消费内容的速度才稀缺。
每个月都有更强的模型发布,但人的时间没有变多。真正拉开差距的,是谁能把世界上海量的长视频、长播客、长会议,快速地消费掉、变成自己能用的知识和产物。100 万 token 上下文、分层 effort,这些升级最终都服务于一个目标——让消费音视频,像消费文本一样快。
这正是 BibiGPT 长期在做的事:已服务超过 100 万用户、累计生成超过 500 万次 AI 总结、支持 30+ 平台,把每一次底层模型的进步,第一时间变成你处理长内容时能感知到的「更快、更准、更顺」。
延伸阅读:
想把一段几小时的长视频整段读完、几分钟拿到完整总结?打开 BibiGPT,粘贴链接试一下。
BibiGPT 团队