视频转小红书笔记:用 AI 把长视频拆成爆款图文笔记(2026 实操指南)
视频转小红书笔记:用 AI 把长视频拆成爆款图文笔记(2026 实操指南)
你刷到一条特别好的干货视频——可能是一段 40 分钟的播客、一节网课、或者某个博主的深度拆解。看完很想做成自己的小红书笔记发出去,但真要动手才发现:得反复拖进度条找重点、手敲要点、再一张张配图、想标题、排版……一条笔记折腾两个小时,热情早就被磨没了。
100 字直答:截至 2026 年 Q2,把长视频变成小红书图文笔记最快的路径是「AI 拆要点 → 套笔记模板 → 配封面图」。用 BibiGPT 粘贴视频链接,几分钟拿到带时间戳的结构化要点,再按本文的「钩子标题 + 3-5 条干货 + 行动建议」模板填充,配上 AI 生成的封面图,单条笔记的制作时间能从两小时压到 15 分钟以内。
这其实不是「写笔记」的问题,而是一个**内容再利用(repurposing)**的选择:同样一段视频,你是把它当一次性消费品看完就忘,还是把它的价值榨成一条能持续涨粉的图文笔记?本文要讲的,正是后者——一套可复制的「视频 → 小红书笔记」工作流。
市面上大部分「视频转文字」教程只教你拿到一坨字幕,然后就没有然后了。但小红书笔记不是字幕的搬运,它有自己的形态:钩子要狠、分点要清、配图要够看、结尾要有行动指令。这篇指南不只教你提取,更教你套形态。
一、为什么视频不能直接发小红书,要先「拆」
小红书的内容逻辑和视频平台完全不同。视频是线性的、需要时间消费的;小红书图文是碎片化、可速读、强视觉的。用户在信息流里给你一条笔记的判断时间不超过 2 秒——封面没钩住、首屏没干货,直接划走。
所以「视频转小红书笔记」的核心不是翻译,而是重构:把 40 分钟的线性叙事,压成 5 个能独立成立的信息点,每个点都能当作一张配图卡片的标题。
- 学生党:把网课、公开课拆成「3 个考点速记」笔记,复习时一眼回顾
- 职场人:把行业播客拆成「这期讲了哪 3 个趋势」干货贴,顺便立人设
- 博主 / 创作者:把别人的爆款视频拆成自己的二创笔记,做选题灵感库
根据 Buffer 对内容再利用的分析,把一份核心内容拆分成多种格式分发,是创作者放大单位时间产出的最有效杠杆之一——一条视频的价值,远不止一次播放。
实用规则: 视频转小红书笔记,先问自己「这段视频里能拎出几个能独立成立的点」,而不是「怎么把字幕复制过来」。点比字数重要。
下面这条演示走一遍「一段视频 → 结构化要点」的过程,先看一眼建立直觉:
来源:YouTube · AI 视频总结与笔记演示
二、第一步:用 AI 把视频拆成结构化要点
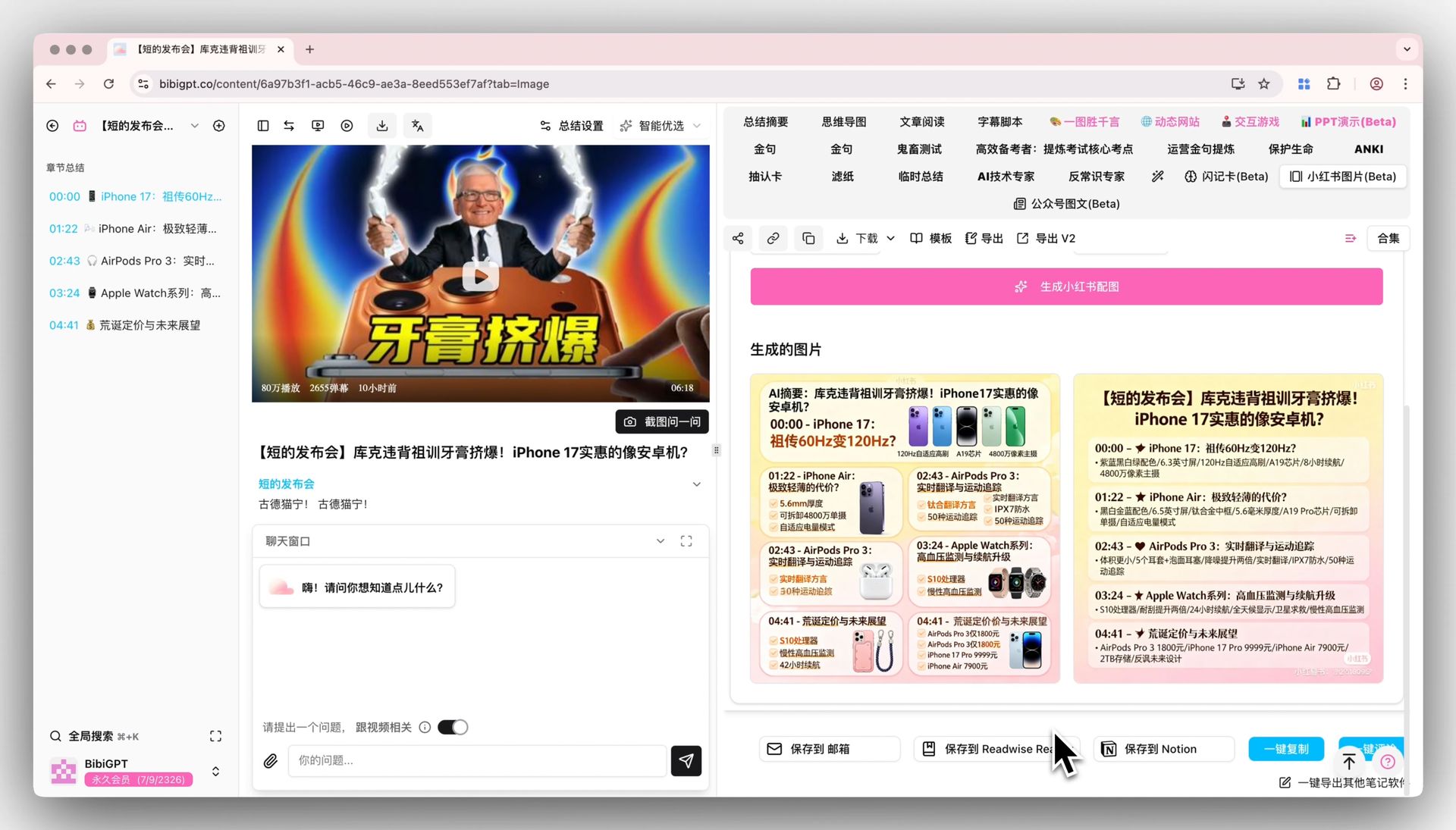
整个工作流里最费体力的就是「找重点 + 记要点」,这一步交给 AI 最划算。打开 BibiGPT 智能视频总结,粘贴视频链接——支持 YouTube、B 站、抖音、小红书、播客等 30+ 平台,也能直接上传本地录屏。几分钟后你会拿到:
- 一段 TL;DR:整条视频在讲什么,3-5 句话说清
- 分章节要点:每个段落的核心论点 + 对应时间戳
- 关键金句:可以直接当笔记小标题用的句子
这里有个小技巧:拿到要点后别急着用,先按「能不能做成一张卡片」筛一遍。一段 40 分钟的视频,AI 可能给你 10 个章节,但小红书笔记最多放 5-6 张图,所以你要做的是二次精选——挑出最有冲突感、最反常识、或最实用的那几个点。
下面这个交互演示,你可以亲手选一个样例视频,看 AI 输出的 TL;DR + 要点 + 时间戳长什么样:
几秒读完任何视频
选个样例,看 AI 总结——一句话结论、要点清单、可跳转的时间戳。
一句话: Karpathy 用代码从零搭出一个 GPT 风格的语言模型,逐行讲清每个部件——从最小的字符级模型到完整的 Transformer。
要点
- 先做一个 bigram 基线模型,再加自注意力,让 token 之间能"互相对话"
- 一个 Transformer 块 = 多头注意力 + 前馈网络 + 残差连接 + 层归一化
- 训练本质就是"预测下一个 token";剩下的交给规模和数据
- nanoGPT 背后的架构,放大后就是 ChatGPT
跳转
- 00:07 为什么要从零搭 GPT
- 08:23 直观理解自注意力
- 1:00:00 拼出 Transformer 块
- 1:35:00 从 nanoGPT 到 ChatGPT
实用规则: AI 给的章节是「全量」,你要的是「精选」。宁可一条笔记只讲 3 个点讲透,也不要 8 个点蜻蜓点水。
三、第二步:套小红书笔记模板,把要点变成图文
拿到精选要点后,真正决定笔记能不能爆的是形态。小红书图文笔记有一套相对固定的高转化结构,套进去就行:
标题:3 秒钩住的公式
小红书标题的本质是「用一句话制造点开的理由」。常用公式:
- 数字 + 痛点:「看了 40 分钟播客,就记这 3 句够了」
- 反常识:「原来 XX 一直都做错了?这条视频讲透了」
- 身份代入:「打工人必看 | 这期把 XX 讲明白了」
正文:钩子 → 干货 → 行动
- 首句钩子:先抛结论或痛点,不要铺垫(小红书首屏只显示前几行)
- 3-5 条干货:每条一个 emoji 开头 + 一句话要点,对应一张配图卡片
- 结尾行动指令:「码住」「评论区告诉我你想看哪期」「关注追更」
配图:封面 + 内页卡片
封面决定点击率,内页卡片决定完读率。这就是 AI 配图能力的用武之地——用 BibiGPT 小红书图文生成 把每条要点直接生成对应风格的图文卡片,不用再去 Canva 一张张拖。
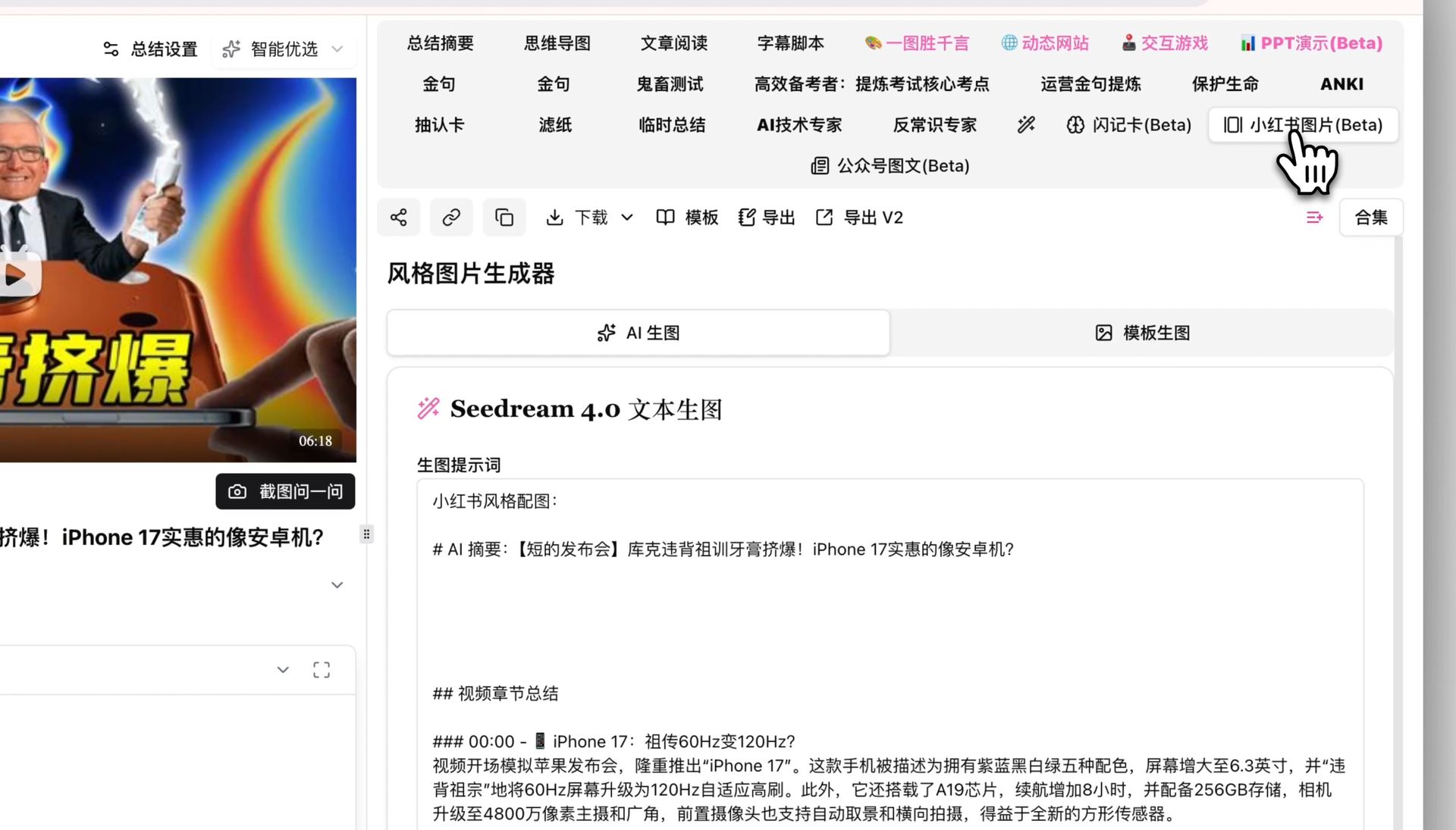
| 笔记部件 | 作用 | 内容来源 |
|---|---|---|
| 封面图 | 决定点击率 | 最有冲突感的那条要点 |
| 标题 | 制造点开理由 | AI 金句 + 数字/痛点公式 |
| 干货卡片 | 决定完读率 | 精选后的 3-5 条要点 |
| 结尾 CTA | 决定互动率 | 「码住 / 关注追更」 |
四、第三步:用视觉化分析补上「画面里的信息」
很多视频的价值不只在「说了什么」,还在「画面里展示了什么」——比如教程里的操作步骤、发布会里的产品图、网课里的板书和图表。光提取字幕会漏掉这部分。
这时候用 BibiGPT 视觉化分析,AI 会自动抓取视频里的关键画面并「看图说话」,把画面内容也转成可用的图文要点。对于操作类、展示类视频,这一步能让你的笔记信息密度直接翻倍。
画面分析面板会逐帧给出对应的图文解读,方便你直接挑来做笔记卡片:
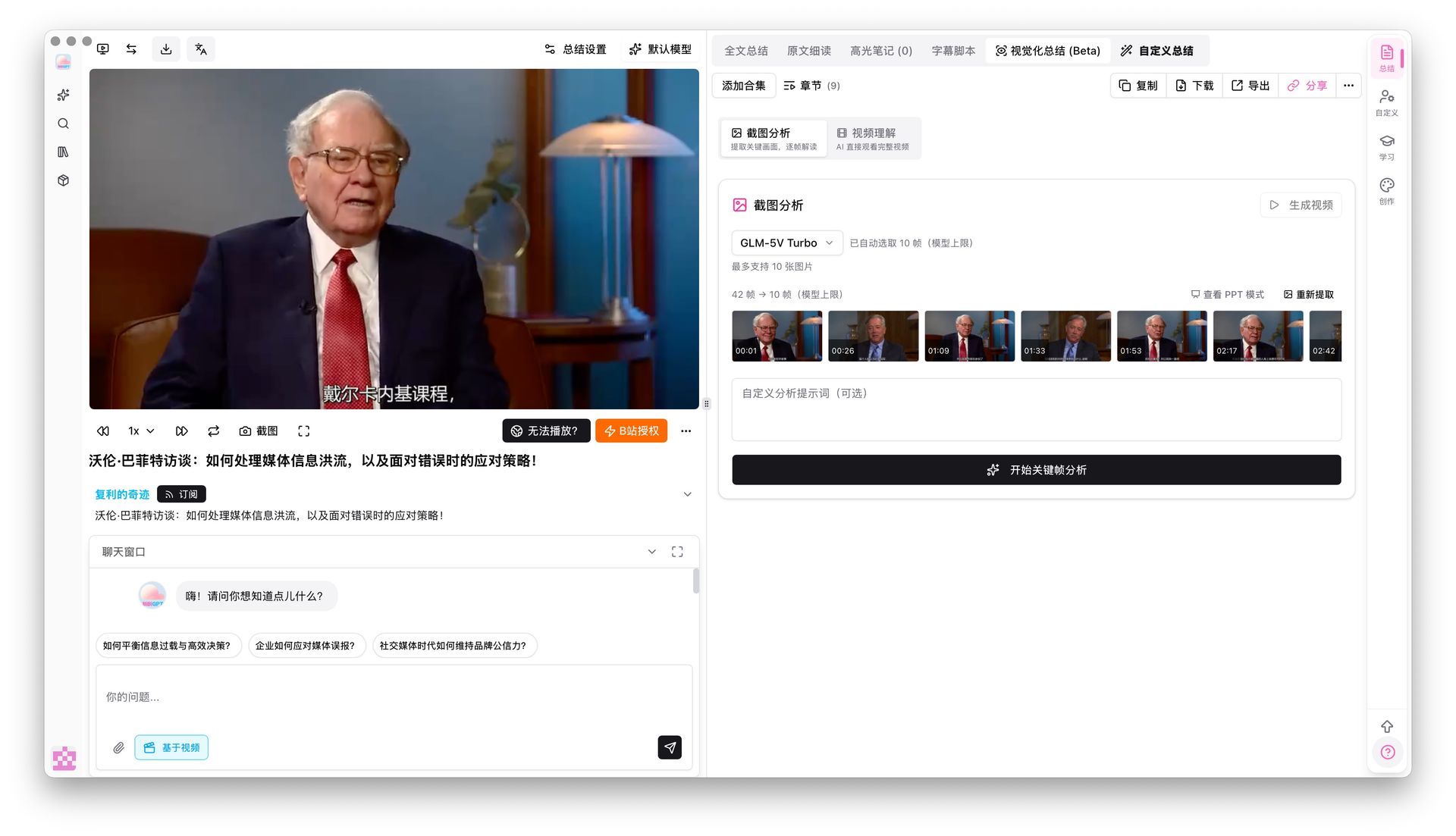
下面这个演示,你可以看 AI 怎么从视频关键帧里读出画面信息:
把画面变成图文笔记
AI 不只听声音,还会看画面——幻灯片、图表、屏幕上的文字,全都帮你整理成文字。
关键画面

画面文字: nanoGPT
Karpathy 现场敲出 bigram 模型——最简单的语言模型,用当前字符预测下一个字符。
实用规则: 如果视频里有「不说出来但展示出来」的信息(步骤、图表、产品),别只提字幕——让 AI 把画面也读一遍。
五、第四步:发布前的避坑清单与节奏
技术活做完,最后这步决定笔记能不能活下来。
- 别整段照搬别人的视频内容:二创要加自己的观点和总结,纯搬运既没价值也有风险。把 AI 要点当骨架,肉要自己长
- 首图别放纯文字:小红书是视觉平台,封面至少要有配色和排版
- 发布时间:根据 Hootsuite 对社媒发帖时机的研究,工作日午休(12-13 点)和晚间(19-22 点)通常是互动高峰,可以据此排你的发布节奏
- 一条视频拆多条笔记:一期播客拆 3 条不同角度的笔记,比硬塞成一条更涨粉
常见问题(FAQ)
视频转小红书笔记,AI 提取的内容能直接发吗?
不建议直接发。AI 给你的是结构化要点(骨架),但小红书笔记需要你加入个人观点、调整语气、套钩子标题。把 AI 当成省掉 80% 体力活的助手,最后 20% 的「人味」由你来加,这样既快又不会千篇一律。
哪些视频最适合拆成小红书笔记?
干货密度高、有明确分点结构的视频最好拆:知识类播客、网课、行业分析、产品评测、教程。纯娱乐、纯剧情类视频拆起来反而费劲,因为它的价值不在「信息点」上。
一段长视频能拆成几条笔记?
一段 40 分钟以上的干货视频,通常能拆出 2-4 条不同角度的笔记。比如一期讲「AI 工具」的播客,可以拆成「3 个免费工具」「这期反对的 1 个观点」「适合新手的入门路径」三条,覆盖不同搜索意图。
配图一定要用 AI 生成吗?
不一定,但 AI 配图能省掉最耗时的环节。如果你有自己的设计模板和审美,手动配也行;但如果只是想快速把要点变成能看的卡片,AI 生成的图文卡片是性价比最高的选择。
六、从「看完就忘」到「持续产出」的工作流
把上面四步串起来,你就有了一条可复制的内容流水线:
- 看到好视频 → 粘贴链接到 BibiGPT
- 拿要点 → AI 输出 TL;DR + 分章节要点 + 画面信息
- 做精选 → 挑出 3-5 个能独立成立的点
- 套模板 → 钩子标题 + 干货卡片 + 行动 CTA
- 配图发布 → AI 生成封面与内页卡片,按节奏发出
真正会用内容的人,不是看了多少视频,而是把每一段好内容都榨出了二次价值。BibiGPT 已服务超过 100 万用户、累计生成超过 500 万次 AI 总结、支持 30+ 平台——它要解决的就是这件事:让你消费一段视频的速度,快到能立刻把它变成自己的产物。
延伸阅读:
想把今天看的视频立刻变成一条小红书笔记?打开 BibiGPT 智能视频总结,粘贴链接,剩下的交给 AI。
BibiGPT 团队