Second Brainに動画を組み込む:BibiGPT × Obsidian / Notion 4ステップワークフロー(2026)
Second Brainに動画を組み込む:BibiGPT × Obsidian / Notion 4ステップワークフロー(2026)
YouTube「あとで見る」リストを開きます。「見るつもりだったけどまだ手をつけていない」動画が80本溜まっていませんか?Apple Podcastsを更新すると、購読中の番組10話が待っています。B站のお気に入りをスクロールすると、去年保存した90分のKeynoteもそのまま。あなたは二度と見ません——重要じゃないからではなく、それらが毎日トリガーされるワークフローに入っていないから。
動画とポッドキャストは、ナレッジワーカーが直面する最も「アンチSecond Brain」のコンテンツ形態です:情報密度が極めて高い(1時間の講演 ≈ 1万字の原稿)が、検索が困難、引用が困難、知識フラグメントの再利用が困難。テキストノートは双方向リンク可能、動画ノートは不可。スクリーンショットはNotionに保存できるが、スクリーンショット自体はgrep不可。
この記事は完全な答えを提示します:Tiago ForteのCODEフレームワーク(Capture / Organize / Distill / Express)を使って動画コンテンツをSecond Brainに組み込む——BibiGPTをCapture入り口、Obsidian / NotionをOrganize/Distill層とし、最終的に実用可能な成果物を生み出す。全プロセス4ステップ、各ステップで具体的アクション付き。
目次
- なぜ動画コンテンツはSecond Brainの最大の弱点か
- CODEフレームワークの簡潔復習
- 動画化CODE:4ステップワークフロー
- BibiGPT × Obsidian / Notion統合図
- よくある落とし穴と対処
- FAQ
なぜ動画コンテンツはSecond Brainの最大の弱点か
Tiago ForteはBuilding a Second Brainで、ナレッジワーカーが直面するコンテンツソースを3種類に分類しています:テキスト(記事、PDF)、音声動画(ポッドキャスト、動画、講演)、会話(会議、チャット)。
PKM Newsletter 2026年度調査によれば、2000名超のアクティブなSecond Brain実践者のうち、87%が動画/ポッドキャストコンテンツが最大の弱点と回答——記事に双方向リンク、PDFにハイライトとノートはできるが、動画はほぼPKMシステムに入らない。
なぜか?
実用ルール: Second Brainのコアは「未来のあなたが過去のあなたをgrepできる」。テキストはデフォルトでgrep可能、動画はそうでない。
動画ノートの伝統的失敗モード:
- 見て忘れる:見ながらメモは気が散る、見終わってから思い出すと印象だけ
- スクリーンショットでアーカイブ:スクリーンショットをNotionに保存しても検索不可
- 手で写す:実用的だが遅い、1時間動画ごとに2-3時間の整理が必要
- transcriptをダウンロード:原始transcriptは長く乱雑、構造化なしではほぼ役立たず
AI動画要約ツールの登場でtranscript段階は解決——しかしtranscriptがあるだけではSecond Brainに組み込まれない。本当の作業はtranscript後の3つ:原子化ノートに精製 / 既存ノートとリンク / 未来必要な時に浮かび上がらせる。これがCODEフレームワークの解決対象。
CODEフレームワークの簡潔復習
Tiago ForteのCODEはSecond Brainのコア方法論、4つのアクション:
- C - Capture:心を動かしたコンテンツ断片を抓取(全部ではなく、思考をトリガーした部分のみ)
- O - Organize:「実行可能度」で分類(主題別ではなく)、PARAシステムでProjects / Areas / Resources / Archivesに振り分け
- D - Distill:段階的精製(progressive summarization)、同じノートを複数回再訪して毎回精簡化
- E - Express:ノートを成果物に変える(記事、動画スクリプト、意思決定、教材)
動画コンテンツはどの段階で詰まるか?
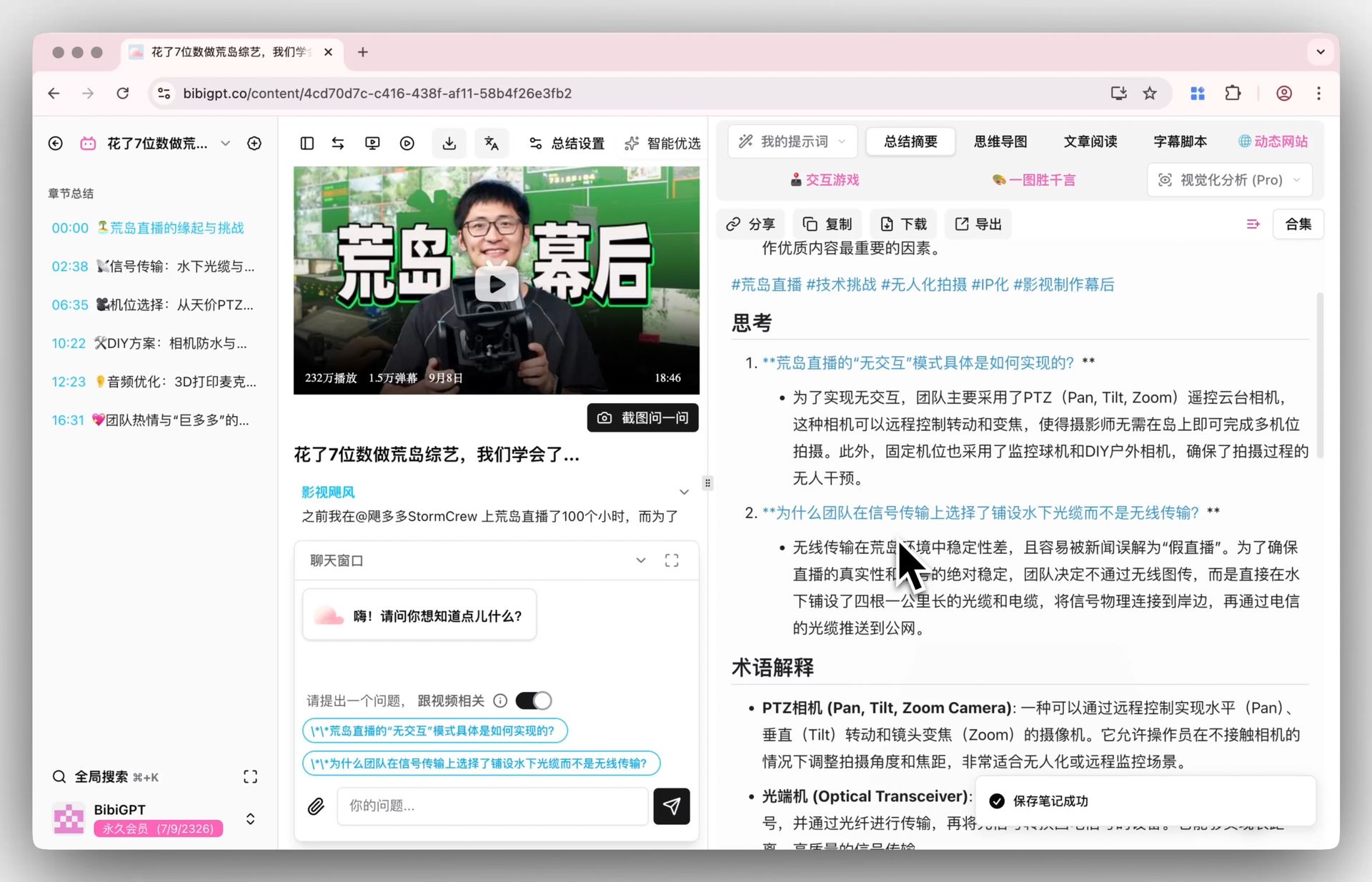
| 段階 | テキストコンテンツ | 動画コンテンツ(伝統的) | 動画コンテンツ(BibiGPTワークフロー) |
|---|---|---|---|
| Capture | コピペまたはReadwise | スクリーンショット/手書き | URL貼付 → AI自動で構造化要点 |
| Organize | タグ/フォルダ | ほぼアーカイブされない | MD導出してPARA分類 |
| Distill | ハイライト/太字 | 再視聴しないと再精簡不可 | AI追問 + 自分で要点書き直し |
| Express | 断片を草稿にコピー | スクリーンショット埋込み + テキスト説明 | ノート + タイムスタンプリンクで記事/スクリプトに |
実戦に入りましょう。
動画化CODE:4ステップワークフロー
Step 1 — Capture:BibiGPTで動画を構造化ノート草稿に
BibiGPTを開き、YouTube / B站 / ポッドキャスト / 抖音動画リンクを貼り付け(またはローカル音声動画ファイルをアップロード)、数分待つと、構造化された出力を取得:
- 章節要約:長動画は自動的にテーマで分割
- キータイムスタンプ:各観点にクリック可能なタイムスタンプ
- 思考問答:AIが自動生成する「この動画は何の問いに答えているか」
- 用語解説:未知の概念が自動展開
この出力は等しくない Second BrainのPermanent Note——「原料」に過ぎない。これがCapture段階の産物:60分動画から5-10個のコア観点 + タイムスタンプアンカーを抽出。
実用ルール: Captureの核心は「心を動かした部分だけ抓取、全部ではない」。BibiGPTが8つの章節要約を提示しても全部保存する必要はない——本当に再考したい2-3章節を選んで先へ。
Step 2 — Organize:Markdownエクスポート、PARAでObsidian / Notionに振り分け
BibiGPTはワンクリックでMarkdownエクスポート(元動画リンク、タイムスタンプ、全スクリーンショット付き)、Obsidian / Notionノートライブラリに同期。Tiago ForteのPARAシステム推奨:
- Projects(30日以内に成果物目標のあるプロジェクト):この動画が特定プロジェクトに役立つ場合(講演準備、記事執筆など)、対応Projectフォルダへ
- Areas(長期的責任領域):長期関心領域に関連する場合(プロダクトデザイン、AIエンジニアリング、フィットネス)、対応Areaへ
- Resources(興味 + 資料):内容が「面白い + 将来使うかも」だけなら、Resourcesへ
- Archives(完了/停止):基本的に自分で入れない、他3類の「引退」場所
意思決定フィルター: 一つの質問——「このノート、30日以内に開くか?」はい → Projects;開かないが戻って見る → Areas / Resources;どれでもない → Captureしない。
ファイル命名推奨:<日付>-<動画コア観点>-<ソースプラットフォーム>.md。例:2026-05-20-second-brain-video-knowledge-tiago-forte.md。未来のファジー検索で日付/主題/ソース、どれでもgrep可能。
Step 3 — Distill:段階的精製 + AI追問
ほとんどの人の動画ノートワークフローが死ぬのがここ——transcript入手で「タスク完了」と思い込み、数ヶ月後に振り返ると使い物にならない。
段階的精製(Progressive Summarization) はTiagoがDistillに与えた具体的アクション:
- 1回目再訪(24時間以内):最重要な30%段落を太字でマーク
- 2回目再訪(1週間後):太字段落内で最も重要な30%をハイライト
- 3回目再訪(1ヶ月後):ハイライト内に自分の一文要約を記入(Permanent Note)
毎回再訪のたびに厳格化——これがtranscriptを「未来のあなたが一目でコアを見える」ものに変える鍵。BibiGPTはここで一段加速:
- AI追問でDistill加速:BibiGPTの動画対話と知能ソース追跡を開き、「この動画で最も重要な3つの洞察は?」——AIがタイムスタンプ付き回答を出力、そのままPermanent Note領域へコピー。
- クロス動画追問:同主題動画10本をBibiGPTコレクションに保存済みなら、コレクションAI対話で「これら10人のクリエイターのXに対する見解はどこで分岐するか」——これがSecond Brain最強の能力、クロスノート総合。
Step 4 — Express:動画ノートを成果物に変える
Second Brainの終点は「500ノートを持っている」ではなく、「この500ノートが毎週1記事 / 1意思決定 / 1講演を生み出す」。動画ノートのExpressパス:
- 記事執筆:あるAreaフォルダから関連動画ノート3-5本をgrep、BibiGPT動画から記事機能で1つの動画を画像テキスト初稿に、自分のノートと総合して記事化。
- 講演スクリプト:関連動画ノート5-10本のPermanent Notesを繋げば、「専門家見解の総合 + 自分の判断」の講演草稿。
- 意思決定根拠:ある決定に直面した時、「過去半年で見たXに関する全動画」を検索——AIが見解分布表を提示。
- 教育素材:ノート + 元動画タイムスタンプをMarkdownでパッケージ、各観点に元動画リンク + 数秒プレビュー、学生に有用な資料に直接できる。
実用ルール: ExpressはSecond Brainの「資産化出力」。CaptureだけでExpressをしないと、6ヶ月後に動画ノートをどれも開かない——普通のお気に入りの200本「見たい」動画と変わらない。
BibiGPT × Obsidian / Notion統合図
最小実行可能な統合方案:
[動画 / ポッドキャスト / Keynote]
↓
[BibiGPT] ← Step 1: Capture
- 章節要約
- タイムスタンプ
- AI追問
↓ Markdownエクスポート
[Obsidian / Notion] ← Step 2: Organize (PARA)
- 0-Inbox(24h以内処理待ち)
- 1-Projects / 2-Areas / 3-Resources / 4-Archives
↓ 段階的精製(3ラウンド)
[Permanent Notes] ← Step 3: Distill
- 自分の一文要約
- 関連ノートへの双方向リンク
↓
[記事 / 講演 / 意思決定] ← Step 4: Express重要なObsidianプラグイン推奨:
- Dataview:PARA内の動画ノートをタグ/時間/プロジェクトでフィルター表示
- Templater:「動画ノート」テンプレートを自動適用(BibiGPT URL、元動画リンク、タイムスタンプフォーマット含む)
- Excalidraw:クロス動画の観点総合を知識マップに描画
Notionワークフロー推奨:
- フォルダではなくDatabaseでノート整理、PARAステータスプロパティ追加
- Synced Blockである「金言」を同時にProjectとPermanent Notesに表示
- Notion AIの「Ask AI」でクロスノート総合(BibiGPTコレクションAI対話と相補)
よくある落とし穴と対処
落とし穴1:Capture過剰——全BibiGPT出力をObsidianに保存。 結果:6ヶ月後、ノートライブラリが2000 MDに膨張、検索が逆にノイズに。修正:「Step 2意思決定フィルター」を通過した動画のみ保存(30日以内に開く / 長期領域関連 / 興味 + 将来使うかも)。
落とし穴2:エクスポート後、再訪しない。 これが80%の失敗原因。修正:Obsidian / Notionで「Weekly Review」固定アクションを設定(推奨:日曜30分)、今週新規追加のInboxノートをPARAに振り分け + 1回目Progressive Summarization完了。
落とし穴3:動画タイムスタンプを省略。 結果:未来引用時、原文のコンテキストが見つからない。修正:BibiGPTエクスポート時に全タイムスタンプ保持、Markdown内に[03:45](原動画URL?t=225s)形式、未来ワンクリックで原映像に戻る。
落とし穴4:言語横断動画を翻訳せず保存。 結果:英語ポッドキャストのノートが数ヶ月後に英語要約のみで残り、再訪時に記憶があいまい。修正:BibiGPTアップロード時に自動翻訳を有効化、日本語要約と英語要約を双言語で並列保存、未来どうgrepしてもOK。
実用ルール: Second Brainの最大の敵は「コンテンツ品質不足」ではなく「未来のあなたが過去のあなたを見つけられない」。すべてのワークフロー設計はこの敵に対抗するため。
FAQ
Obsidian / Notionなしでもこのワークフロー走らせる?
可能、ただし効果は割引。BibiGPT側のCapture + Distillで十分使える——処理済み動画を全部BibiGPT内で検索、コレクションでクロス動画追問、時間でアーカイブ。欠けるのはPARAシステム化分類と双方向リンク2能力のみ、個人ライトユーザーには十分。ヘビーPKMユーザーはObsidian / Notion外接推奨。
週に50本以上動画見る、全部このフローを走らせる時間ある?
絶対こうしないで。Second Brainのコアは厳格な選別。50本のうちCaptureに値するのは大体5-8本だけ——残りは見て終わり。BibiGPTが「見て即フィルター」を支援——リンク貼付後、章節要約を一瞥してPARA入りするか決定。
Obsidian動画ノートに動画埋め込み必要?
不要。Obsidianの動画レンダリングは大量メモリ消費、多くの動画ソース(YouTube埋込除く)は非対応。推奨:「テキスト要約 + タイムスタンプリンク + 1-3スクリーンショット」方式で保存。原映像を見る必要があればリンククリックでBibiGPTか動画ソースへジャンプ。
Notion AIはBibiGPTの代わりになる?
なれない。Notion AIは動画を直接処理しない——あなたが貼り付けたテキストに基づいて要約のみ。つまり先にBibiGPTで動画を構造化テキストに変換、その後Notionに貼り付けてNotion AIに処理させる必要。実務:BibiGPTが「Capture + 初回Distill」担当、Notion AIが「クロスノートExpress」担当、両ツールは役割相補。
Tiago Forte本人がBibiGPT推奨したことある?
正式推奨はなし。本記事はCODEフレームワークの動画化拡張、BibiGPTをCapture / Distill2段階の具体的アクションに組み込んだもの。Tiago自身は2025年のインタビューで「動画コンテンツは依然Second Brain最弱の入力タイプ」と言及、それがこのワークフローの解決対象。
このフローはZettelkasten カード筆記法 × AI動画ノートとどう違う?
Second BrainとZettelkastenは2つのPKM哲学——Second Brainは「実行可能度で整理」+「段階的精製」を強調、Zettelkastenは「原子化カード」+「双方向リンクでネットワーク化」を強調。動画ノートに両方法を同時適用可能:Second Brainで「この動画Captureすべきか」を解決、Zettelkastenで「Capture後ノートがどうネットワーク編む」を解決。両者相補で衝突しない。
7. 次の一歩:今週から動画化Second Brain構築開始
「研究し尽くした」のを待たずに始めて——Second Brainのコアは実践しながら学ぶ。今週、小さな一つ:
最近本気で消化したい動画1本を選び(できれば30分以上)、BibiGPTで4ステップフル流程を一度走らせ、結果をObsidian / Notionの新フォルダ「Second Brain - Videos」に保存。1週間後に振り返り、「このノート、grepできるか」「この動画のコアを1分で話せるか」と自問。
このアクションを4週間継続(4本動画)、自分の動画ノート筋肉記憶が自然に形成される。それからPARAフルセットへの拡張を検討。
初期コスト:動画1本あたり15-20分(BibiGPT処理 + PARA振り分け + 1回目Distill)、リターンはこの動画が未来の任意の時点でgrepできること。
まだBibiGPT使ったことなければ、BibiGPT無料アクセス、Step 1 Captureから始めて。