DeepSeek-V4 आ गया! BibiGPT ने पहले ही दिन चार नए मॉडल + 1M कॉन्टेक्स्ट लॉन्च किए — AI वीडियो और पॉडकास्ट सारांश अब और बेहतर
DeepSeek-V4 आ गया! BibiGPT ने पहले ही दिन चार नए मॉडल + 1M कॉन्टेक्स्ट लॉन्च किए — AI वीडियो और पॉडकास्ट सारांश अब और बेहतर
आज (24 अप्रैल, 2026) DeepSeek-V4 Preview आधिकारिक तौर पर लॉन्च हुआ और पूरी तरह ओपन-सोर्स कर दिया गया — 1M कॉन्टेक्स्ट अब डिफ़ॉल्ट है, और एजेंट क्षमता Sonnet 4.5 के साथ अंतर खत्म कर चुकी है। BibiGPT ने उसी दिन इंटीग्रेशन पूरा किया है, और DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash, और V4 Flash Thinking अब सीधे मॉडल पिकर में चुने जा सकते हैं — पूरी डॉक्यूमेंट्री, दो घंटे के इंटरव्यू, या पूरे पॉडकास्ट सीज़न के लिए तैयार।
हमने मॉडल को तुरंत कुछ असली सीन में चलाया। यह पोस्ट उसी समय शेयर किया गया एक हैंड्स-ऑन नोट है, उन सबके लिए जो इसी तरह की कॉन्टेंट के साथ काम करते हैं।
विषय-सूची
- DeepSeek-V4 में नया क्या है
- चार DeepSeek V4 मॉडल अब BibiGPT में लाइव
- तीन स्टेप में DeepSeek V4 पर स्विच करें
- हैंड्स-ऑन: V4 Pro से DeepSeek के अपने लॉन्च वीडियो का सारांश
- V4 पर स्विच कहाँ सीधे लागू होता है
- AI युग: दुर्लभ चीज़ मॉडल नहीं, बल्कि कॉन्टेंट कितनी तेज़ी से पचा सकें
- FAQ
DeepSeek-V4 में नया क्या है
DeepSeek-V4 एक साथ तीन ज़रूरी डायल मूव करता है। हर एक अपने में अलग नोट चाहता है।
पहला, 1M कॉन्टेक्स्ट DeepSeek की आधिकारिक सेवाओं में डिफ़ॉल्ट बन गया है। नया अटेंशन मैकेनिज्म टोकन डाइमेंशन पर कंप्रेस करता है और DSA (DeepSeek Sparse Attention) के साथ मेमोरी और कंप्यूट कॉस्ट कम करता है। व्यवहार में, एक घंटे की सबटाइटल फीड करने के लिए अब “चंक-एंड-स्टिच” रूटीन की ज़रूरत नहीं — मॉडल इसे एक सतत बॉडी की तरह पढ़ता है।
दूसरा, एजेंट क्षमता एक स्पष्ट कदम आगे बढ़ी है। DeepSeek के अपने माप के अनुसार, V4-Pro सभी ओपन-सोर्स मॉडल्स में Agentic Coding पर सबसे आगे है और Opus 4.6 non-thinking के करीब क्वालिटी देता है; वे इसे पहले से ही डिफ़ॉल्ट इंटरनल कोडिंग मॉडल के रूप में इस्तेमाल कर रहे हैं। आम यूज़र्स के लिए इसका मतलब है ज़्यादा भरोसेमंद लंबे-टेक्स्ट का स्ट्रक्चरिंग — चैप्टरिंग, की-पॉइंट एक्सट्रैक्शन, माइंड मैप जनरेशन — स्थिरता में स्पष्ट सुधार के साथ।
तीसरा, Pro और Flash एक-दूसरे को पूरा करते हैं। Pro (1.6T params / 49B active / 33T pre-training tokens) टॉप क्लोज़्ड-सोर्स मॉडल्स को टारगेट करता है; Flash (284B / 13B / 32T) कॉस्ट-एफ़िशिएंट विकल्प है। दोनों thinking और non-thinking मोड सपोर्ट करते हैं, और thinking मोड reasoning_effort ट्यूनिंग सपोर्ट करता है। सिंपल टास्क के लिए Flash, भारी के लिए Pro — दोनों मज़बूत महसूस होते हैं।

मूल घोषणा (चीनी में) यहाँ है: DeepSeek-V4 Preview: the Million-Token Era Goes Mainstream। मॉडल वेट्स Hugging Face DeepSeek V4 collection पर उपलब्ध हैं (Pro / Pro-Base / Flash / Flash-Base, चार रिपो); टेक्निकल रिपोर्ट DeepSeek_V4.pdf में है।
चार DeepSeek V4 मॉडल अब BibiGPT में लाइव
कोई भी वीडियो या ऑडियो सारांश सेटिंग खोलें, मॉडल पिकर में deepseek टाइप करें, और आपको New टैग के साथ चार नई एंट्री दिखेंगी:
| मॉडल | उपयोग | Thinking |
|---|---|---|
| DeepSeek V4 Pro | लंबी, लॉजिक-हेवी कॉन्टेंट के लिए टॉप-टीयर क्वालिटी | Non-thinking |
| DeepSeek V4 Pro Thinking | स्पष्ट रीज़निंग के साथ V4 Pro — एजेंट और गहन विश्लेषण | Thinking |
| DeepSeek V4 Flash | कॉस्ट-एफ़िशिएंट, छोटी और कैज़ुअल कॉन्टेंट के लिए शानदार | Non-thinking |
| DeepSeek V4 Flash Thinking | रीज़निंग के साथ Flash, स्पीड और गहराई का संतुलन | Thinking |
कौन-सा चुनें? सरल निर्णय नियम:
- लंबी कॉन्टेंट (एक घंटे से ऊपर, पूरे पॉडकास्ट सीज़न, लंबे इंटरव्यू) → पूरे टुकड़े पर गहरी रीज़निंग के लिए Pro या Pro Thinking
- छोटी कॉन्टेंट (30 मिनट से कम, मीटिंग, डेली vlog) → Flash, ज़्यादा तेज़ और किफ़ायती
- मॉडल को स्टेप-दर-स्टेप रीज़न करवाना है, दृष्टिकोण तुलना करनी है, गहराई में जाना है → कोई Thinking वेरिएंट चुनें
- सिर्फ़ साफ़ सारांश चाहिए, रीज़निंग ट्रेस नहीं → non-thinking वेरिएंट चुनें
अगर ध्यान से तुलना नहीं करना चाहते, तो V4 Pro Thinking से शुरू करें — यह ज़्यादातर लंबी-कॉन्टेंट सीन में स्थिर परिणाम देता है।
तीन स्टेप में DeepSeek V4 पर स्विच करें
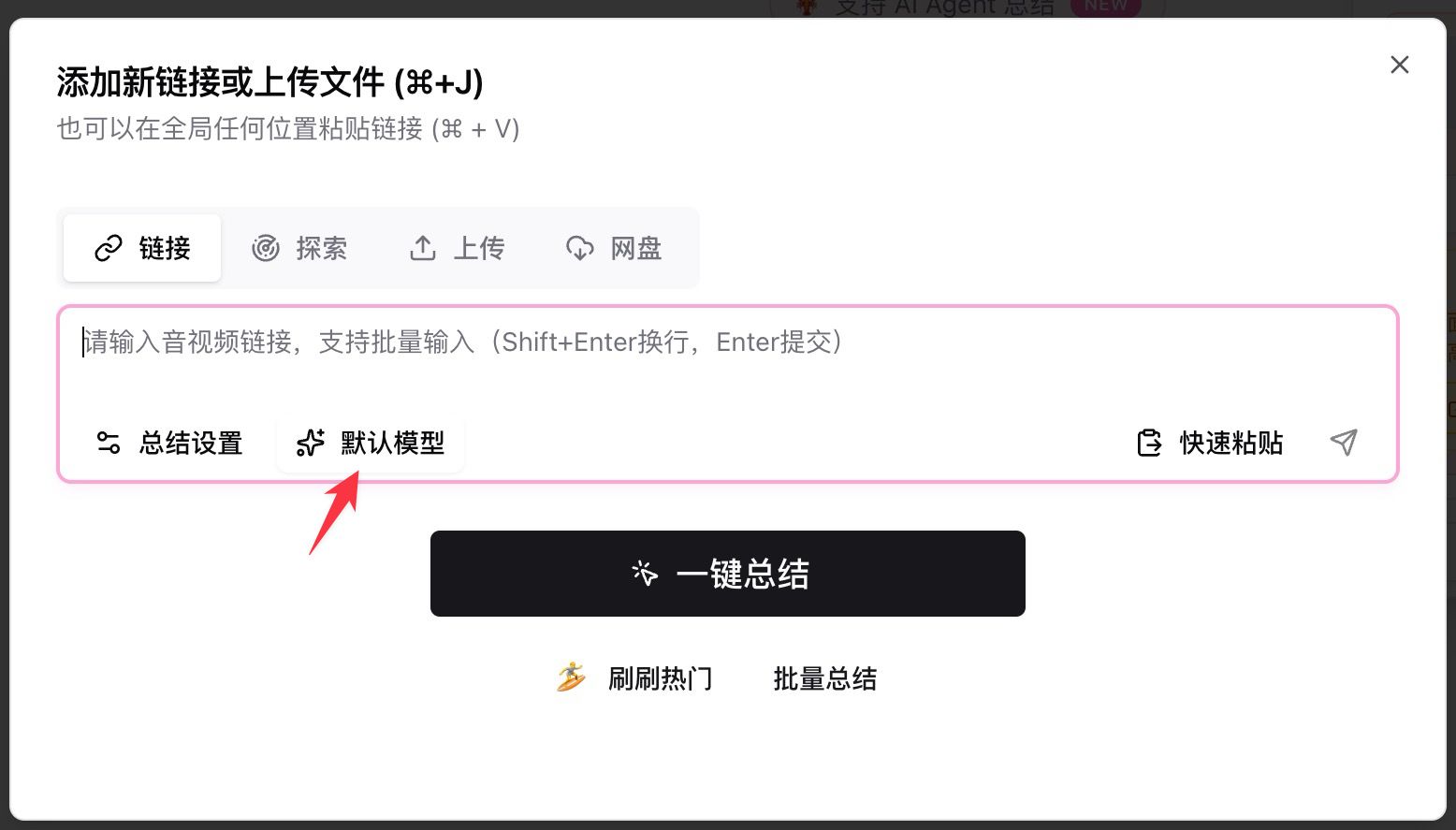
- BibiGPT खोलें, इनपुट बॉक्स में YouTube / पॉडकास्ट / लोकल फ़ाइल लिंक पेस्ट करें
- इनपुट के नीचे Default Model पर क्लिक करें, सर्च बार में
deepseekटाइप करें - किसी भी चार New एंट्री में से चुनें और सारांश बटन दबाएँ
चयन सेशन के बीच बना रहता है। पावर यूज़र्स V4 Pro Thinking को डिफ़ॉल्ट कस्टम सारांश के रूप में पिन कर सकते हैं, ताकि हर भविष्य का वीडियो स्वतः इसी से चले।
मॉडल बदलने से पहले BibiGPT की सारांश क्वालिटी महसूस करना चाहते हैं? नीचे दिए गए विजेट में कोई भी लिंक डालें:
हैंड्स-ऑन: V4 Pro से DeepSeek के अपने लॉन्च वीडियो का सारांश
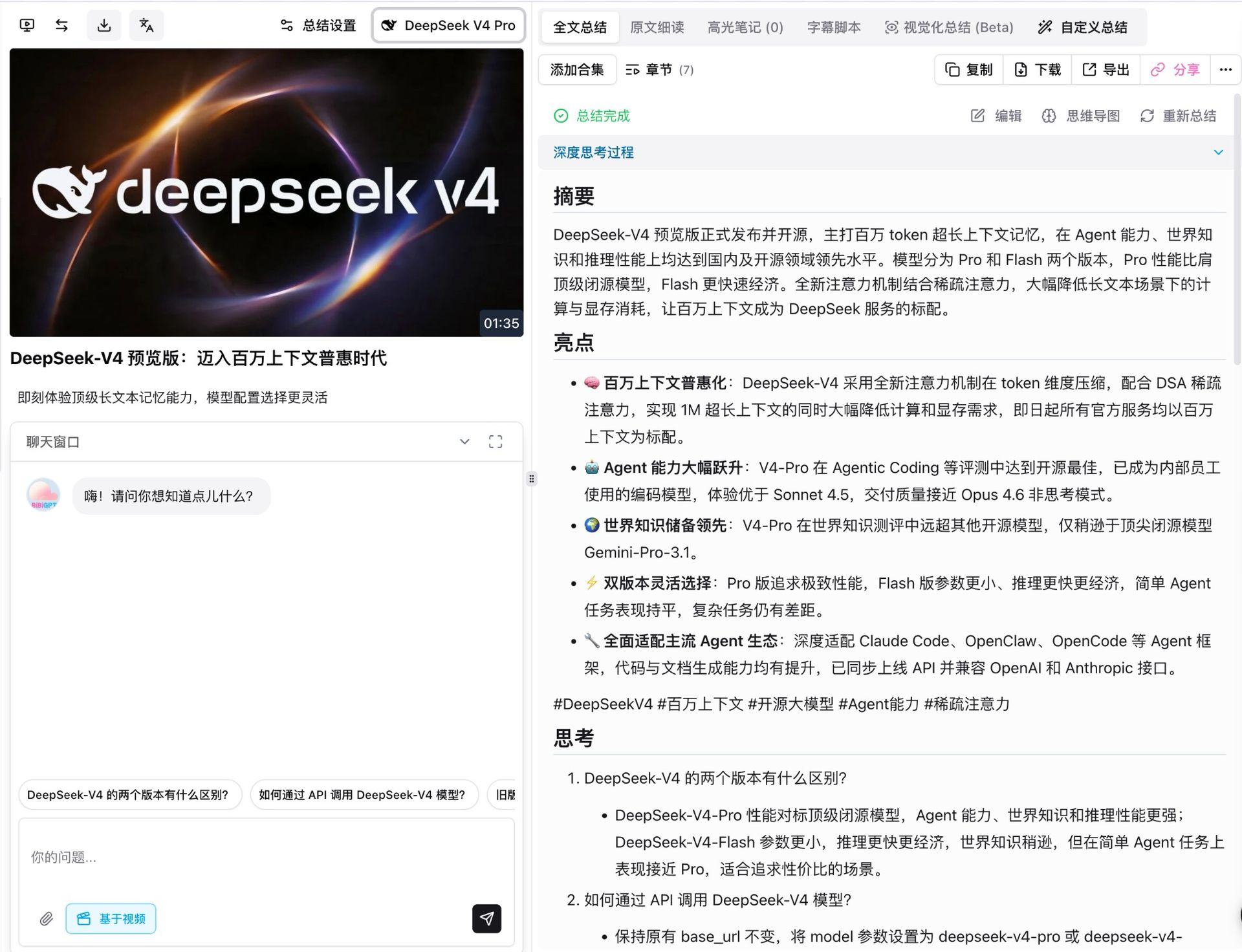
पहली चीज़ हमने DeepSeek के अपने लॉन्च वीडियो पर V4 Pro चलाई। यह लगभग डेढ़ मिनट का है, और thinking मोड ऑन के साथ, मॉडल ने इसे सात स्ट्रक्चर्ड चैप्टर में बाँटा, हर एक का अपना सारांश, हाइलाइट्स, रिफ्लेक्शन और क्रिटिकल रिव्यू।
ध्यान देने योग्य कुछ डिटेल्स:
- पूरी फैक्ट कवरेज: रिलीज़ के सभी पाँच हेडलाइन दावे (1M कॉन्टेक्स्ट डिफ़ॉल्ट, एजेंट छलांग, वर्ल्ड-नॉलेज लीड, ड्यूल-टीयर लचीलापन, एजेंट-इकोसिस्टम कम्पैटिबिलिटी) सटीक रूप से आए, पैरामीटर नंबर सहित
- हर निष्कर्ष ट्रेसेबल है: हर पॉइंट क्लिक करने योग्य वीडियो टाइमस्टैंप पर वापस लिंक करता है, सीधे संबंधित पल पर जाता है
- फ़ॉलो-अप सवाल स्वतः आते हैं: सारांश के नीचे मॉडल “V4 के दो टीयर में क्या अंतर है” और “API के माध्यम से उन्हें कैसे कॉल करें” जैसे एक्सटेंशन सुझाता है, एक-टैप गहरे डाइव के लिए तैयार
यहाँ सुधार मुख्यतः thinking मोड की गहरी रीज़निंग से आता है। लंबा कॉन्टेक्स्ट BibiGPT के बड़े मॉडल्स में पहले से डिफ़ॉल्ट पाथ है, और V4 का आगमन उस “गहरी रीज़निंग + पूर्ण-ट्रांसक्रिप्ट स्थिरता” संयोजन को पहली-दर्जे की क्वालिटी पर ओपन-सोर्स टीयर में लाता है।
V4 पर स्विच कहाँ सीधे लागू होता है
ओपन-सोर्स मॉडल्स लगातार ड्रॉप होते रहते हैं। आप पूछ सकते हैं: क्या मैं सीधे DeepSeek वेबसाइट या API इस्तेमाल नहीं कर सकता? BibiGPT से क्यों रूट करूँ?
यह सीन पर निर्भर करता है। DeepSeek वेबसाइट एक जेनेरिक चैटबॉक्स है — आपको अभी भी वीडियो डाउनलोड, ट्रांसक्राइब, पेस्ट करना और प्रॉम्प्ट करना सीखना पड़ता है। BibiGPT वर्षों से एक काम कर रहा है: लंबे वीडियो और पॉडकास्ट को एक लेख पढ़ने जितना आसान बनाना। V4 उस स्टैक में जोड़ी गई नवीनतम क्षमता है; “लिंक पेस्ट करें, असली समझ पाएँ” को असल में जो काम करवाता है वह प्रोडक्ट लेयर है जो हमने मॉडल के चारों ओर परिष्कृत की है।
BibiGPT के अंदर, निम्नलिखित क्षमताएँ सीधे उस मॉडल के साथ चलती हैं जिसे आप अपना “Default Model” चुनते हैं — दूसरे शब्दों में, एक बार DeepSeek V4 पर स्विच करने पर ये फ़ीचर V4 पर चल रहे हैं।
📝 वीडियो सारांश (डिफ़ॉल्ट + कस्टम प्रॉम्प्ट)
जो चीज़ आप सबसे ज़्यादा इस्तेमाल करते हैं — लिंक पेस्ट करने के बाद “Summarize” दबाना — वह उसी मॉडल पर चलता है जिसे आपने चुना है। कोई भी सेव किए गए कस्टम प्रॉम्प्ट (जैसे “Counterintuitive Analyst”, “Critical Thinking”, या “Investment Analyst”) भी उसी मॉडल से जाते हैं। DeepSeek V4 Pro Thinking पर स्विच करें, उसी प्रॉम्प्ट के साथ उसी वीडियो को री-रन करें, और आपको रीज़निंग गहराई और स्ट्रक्चर पर सीधी साइड-बाय-साइड तुलना मिलती है। यह उन सीन में से है जिनकी हम खुद भी खोज कर रहे हैं — अपनी कॉन्टेंट पर चलाएँ और देखें कि परिणाम आपकी अपेक्षाओं पर बेहतर फिट होता है या नहीं।
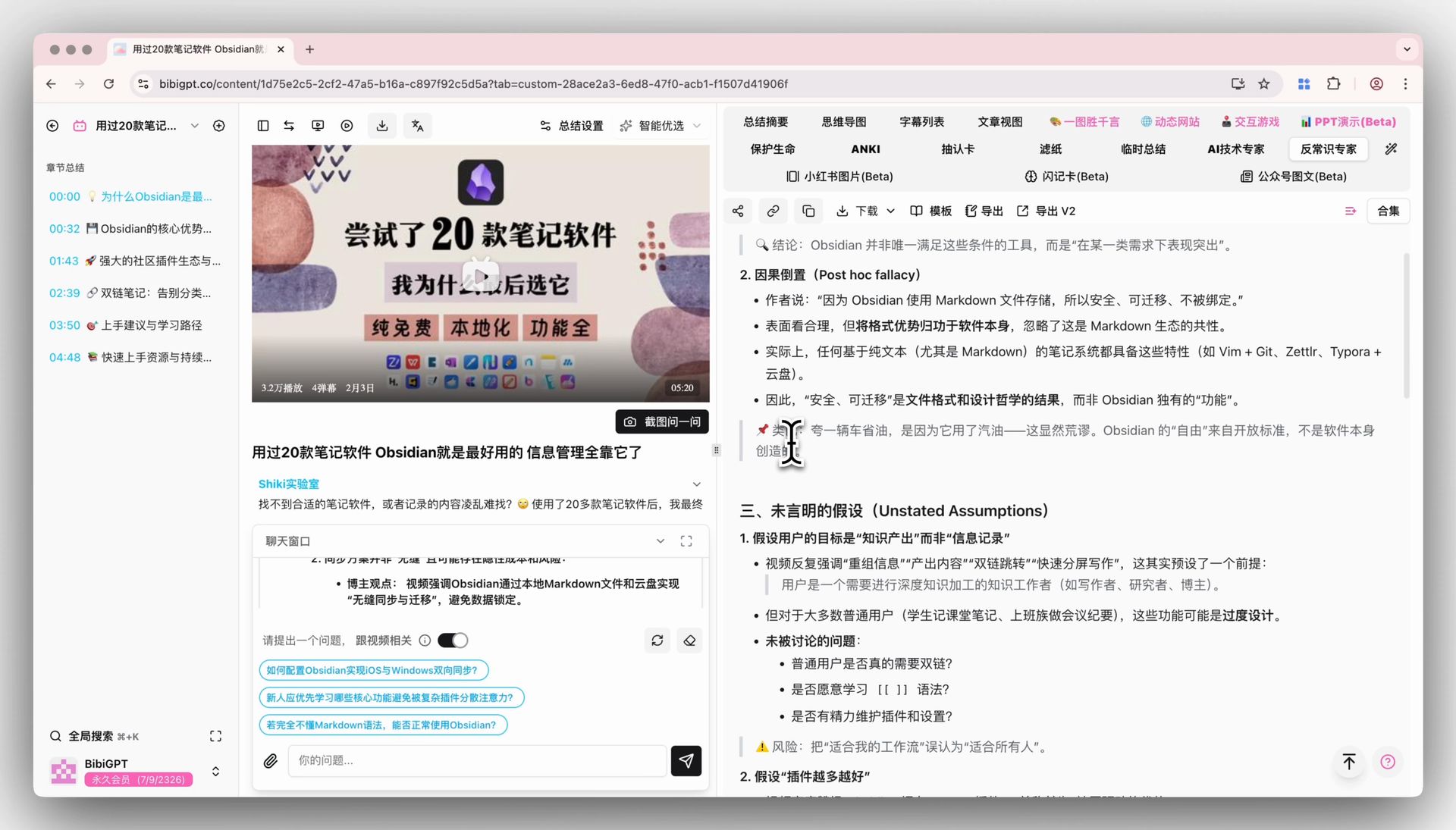
🎯 सोर्स ट्रेसिंग के साथ AI Video Chat
वीडियो डिटेल पेज के नीचे चैट विंडो भी डिफ़ॉल्ट मॉडल का अनुसरण करती है। हर उत्तर एक क्लिक करने योग्य टाइमस्टैंप ले जाता है — “उन्होंने 1:12:30 पर विपरीत बात कही”, एक टैप और आप वहाँ पहुँच जाते हैं। एक बार V4 पर स्विच कर लिया, तो 1+ घंटे का इंटरव्यू उठाएँ और कुछ राउंड फ़ॉलो-अप सवाल पूछें — यह वह सीन है जहाँ मॉडल्स के बीच अंतर तेज़ी से दिखते हैं, और प्रत्यक्ष रन के लायक है।
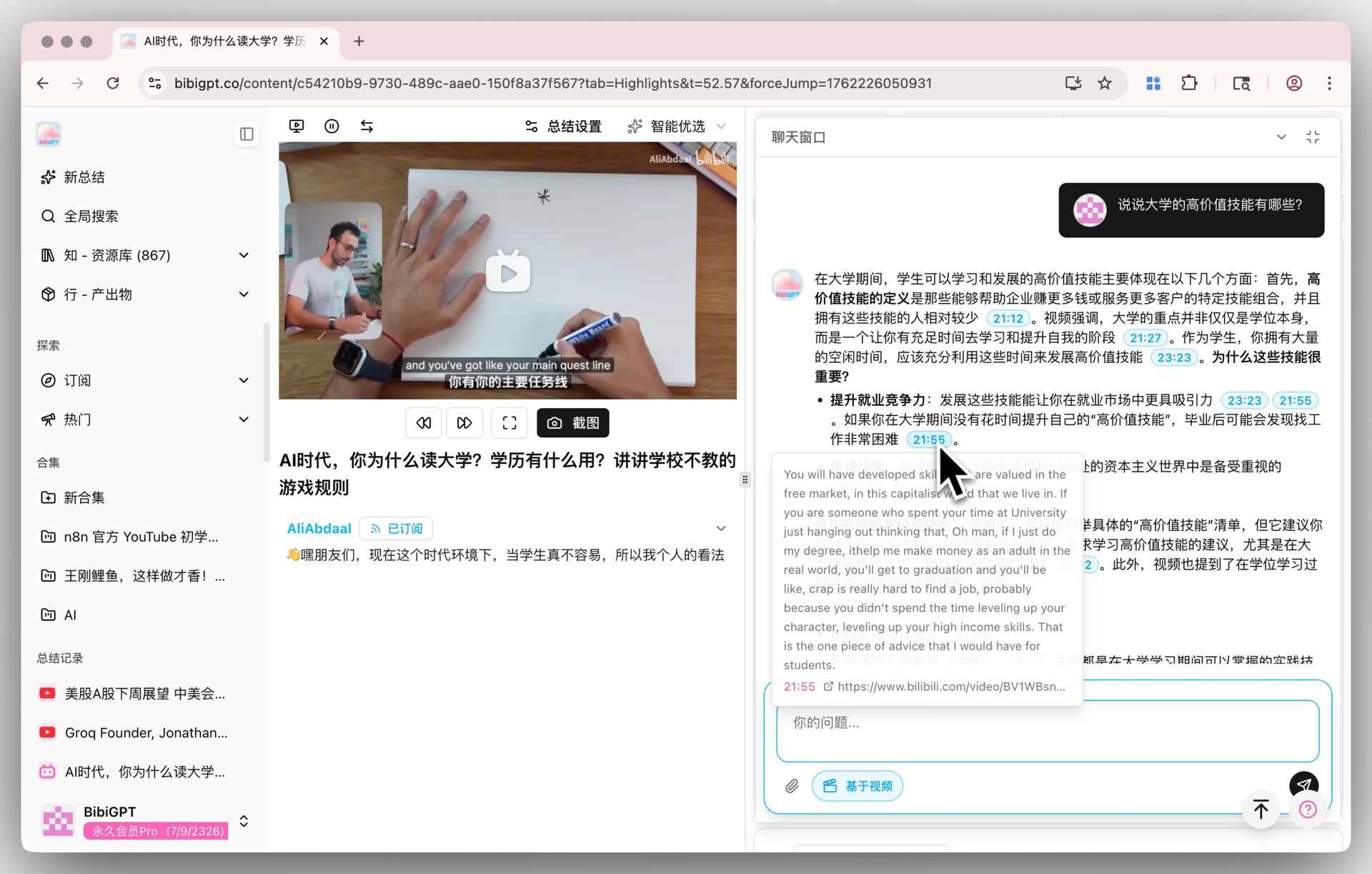
🔖 AI Highlight Notes
टाइमस्टैंप के साथ वीडियो से हाइलाइट क्लिप्स निकालना — विषय के अनुसार समूहित — भी डिफ़ॉल्ट मॉडल पर चलता है। अगर आपने पहले से किसी अन्य मॉडल पर हाइलाइट नोट्स जनरेट किए हैं, तो उन्हें V4 पर री-रन करें और तुलना करें कि कौन-सी क्लिप हाइलाइट्स के रूप में मार्क होती हैं और विषय कैसे क्लस्टर होते हैं। आपकी कॉन्टेंट पर अंतर सार्थक है या नहीं, इसका सबसे आसान निर्णय खुद करके है।
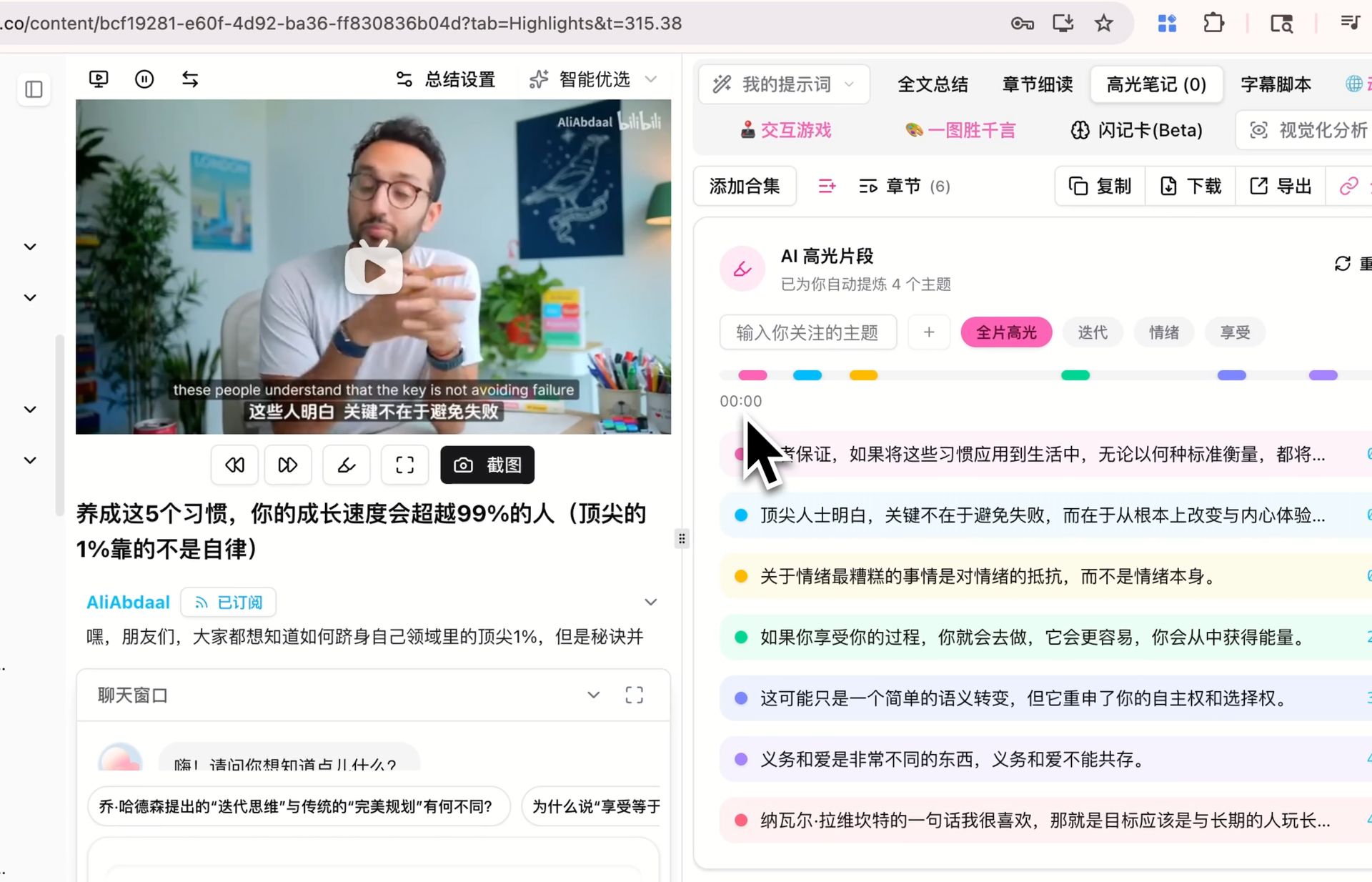
तीनों ऐसे सीन हैं जिनका हम खुद मूल्यांकन कर रहे हैं — परिणाम अलग कॉन्टेंट, प्रॉम्प्ट, और भाषाओं में बदलते हैं, और सबसे विश्वसनीय राय वह है जो आप अपने वर्कफ़्लो के अंदर कुछ रन के बाद बनाते हैं।
कुछ अन्य क्षेत्र समर्पित मॉडल इस्तेमाल करते हैं — विज़ुअल कॉन्टेंट विश्लेषण विज़न मॉडल पर चलता है, और वीडियो-टू-इलस्ट्रेटेड-आर्टिकल फ़िक्स्ड पाइपलाइन इस्तेमाल करता है — इसलिए वे डिफ़ॉल्ट-मॉडल स्विच का जवाब नहीं देते और ऊपर की तुलना का हिस्सा नहीं हैं।
BibiGPT ने आज तक 1M+ यूज़र्स की सेवा की है और 5M+ AI सारांश जनरेट किए हैं। वह स्केल हमें हर नए मॉडल को असल-दुनिया के सीन पर तेज़ी से मैप करने में मदद करता है, बेंचमार्क-तुलना लेयर पर रहने के बजाय।
AI युग: दुर्लभ चीज़ मॉडल नहीं, बल्कि कॉन्टेंट कितनी तेज़ी से पचा सकें
2026 में, AI मॉडल मूलतः बहते पानी जैसे हैं — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 सब पहुँच में हैं। मॉडल अब दुर्लभ नहीं हैं।
दुर्लभ क्या है? आप कितनी तेज़ी से सूचना को राय में, और राय को कार्य में बदलते हैं।
ऑडियो और वीडियो इंटरनेट पर सबसे कम-घनत्व वाले, सबसे लंबे-समय में पचने वाले फ़ॉर्मेट हैं। दो-घंटे का इंटरव्यू ट्रांसक्राइब किया जाए तो 8,000 शब्द है, लेकिन असली थीसिस शायद 300 हो। 30-घंटे का पॉडकास्ट सीज़न शायद 20 टिकाऊ कोट्स देता है। वर्षों से एकमात्र ट्रिक 1.5x या 2x प्लेबैक थी — घनत्व के लिए ध्यान का व्यापार। नवीनतम मॉडल्स के साथ, गणित बदल जाता है:
- अब निष्क्रिय सुनना नहीं, जो सवाल आप परवाह करते हैं वही पूछें — मॉडल ट्रांसक्रिप्ट से उत्तर निकालता है
- निर्णय करने से पहले समाप्त करने की ज़रूरत नहीं, पहले सारांश पढ़ें, फिर तय करें कि क्या यह घंटे के लायक है
- एक समय में एक वीडियो पलटना नहीं, उन सब में सर्च करें — “जिन 100 क्रिएटर्स को मैं फ़ॉलो करता हूँ उनमें से किसने इस विषय पर बात की”
BibiGPT एक काम करता है: उपलब्ध सबसे अच्छे मॉडल को सबसे बड़े लेकिन सबसे मुश्किल-से-पचने वाले फ़ॉर्मेट — ऑडियो और वीडियो — में प्लग करना — ताकि कोई भी दो-घंटे के वीडियो को पंद्रह मिनट की उच्च-घनत्व रीडिंग में कंप्रेस कर सके। DeepSeek V4 उस स्टैक में एक और भरोसेमंद विकल्प जोड़ता है।
FAQ
Q1: DeepSeek V4 Pro और V4 Pro Thinking में क्या अंतर है?
मूल अंतर है कि क्या रीज़निंग स्पष्ट है। Non-thinking कम लेटेंसी के साथ छोटा आउटपुट, साफ़ सारांश के लिए अच्छा। Thinking मोड पहले रीज़निंग चेन जनरेट करता है — मल्टी-स्टेप लॉजिक, क्रॉस-चैप्टर तुलना, या तर्क विश्लेषण के लिए बेहतर। आप reasoning_effort=high/max से गहराई ट्यून कर सकते हैं; गहरी रीज़निंग, धीमा आउटपुट।
Q2: मुझे V4 Pro चुनना चाहिए या V4 Flash?
“लंबाई × रीज़निंग जटिलता” के संदर्भ में सोचें। एक घंटे से ऊपर या मल्टी-स्टेप रीज़निंग → Pro। तीस मिनट से कम और साफ़ सारांश काफी है → Flash। संदेह में, Flash से शुरू करें और Pro पर स्विच करें अगर वह कम पड़े — BibiGPT ट्रांसक्रिप्ट कैश करता है ताकि री-समराइज़िंग ट्रांसक्रिप्शन स्टेप पूरी तरह स्किप करे।
Q3: सीधे DeepSeek वेबसाइट इस्तेमाल करने के बजाय BibiGPT के माध्यम से क्यों जाएँ?
DeepSeek वेबसाइट एक जेनेरिक चैटबॉक्स है — आपको अभी भी खुद डाउनलोड, ट्रांसक्राइब, पेस्ट, और प्रॉम्प्ट करना पड़ता है। BibiGPT अपस्ट्रीम पाइपलाइन (30+ प्लेटफ़ॉर्म लिंक पार्सिंग, ट्रांसक्रिप्शन, विज़ुअल विश्लेषण, टाइमस्टैंप अलाइनमेंट) हैंडल करता है, और DeepSeek V4 को सिर्फ़ अंतिम समझ-और-जनरेट स्टेप कवर करना है। एक ही इनपुट, और आप अतिरिक्त रूप से माइंड मैप, हाइलाइट नोट्स, इलस्ट्रेटेड आर्टिकल, और स्ट्रक्चर्ड एक्सपोर्ट बिना किसी अतिरिक्त असेंबली के पाते हैं।
Q4: DeepSeek V4 कितना लंबा वीडियो हैंडल कर सकता है?
V4 Pro और Flash दोनों के पास 1M टोकन कॉन्टेक्स्ट है — मोटे तौर पर 15 लाख चीनी अक्षर, या 20 घंटे से अधिक संवाद — पूरे पॉडकास्ट सीज़न के लिए पर्याप्त। BibiGPT मॉडल के प्रभावी कॉन्टेक्स्ट के आधार पर सिंगल-पास सारांश और चंक-फिर-कन्सॉलिडेट के बीच स्वतः निर्णय लेता है।
Q5: क्या DeepSeek V4 वेट्स ओपन-सोर्स हैं?
पूरी तरह ओपन-सोर्स। वेट्स Hugging Face deepseek-ai/deepseek-v4 और ModelScope पर हैं; टेक्निकल रिपोर्ट DeepSeek_V4.pdf में है। शोधकर्ता और सेल्फ़-होस्टर सीधे ले सकते हैं।
अभी V4 आज़माएँ
V4 को महसूस करने का सबसे सीधा तरीक़ा: एक लंबा वीडियो उठाएँ जिसे आप वास्तव में देखना चाहते थे — लेक्चर, पॉडकास्ट एपिसोड, डॉक्यूमेंट्री, जो भी — और इसे DeepSeek V4 Pro Thinking से चलाएँ। देखें V4 कैसे कुछ ऐसी चीज़ हैंडल करता है जिसकी आप वास्तव में परवाह करते हैं।
अभी अपनी AI एफ़िशिएंट लर्निंग यात्रा शुरू करें:
- 🌐 Official Website: https://bibigpt.co/hi/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team