¡Llegó DeepSeek-V4! BibiGPT lanza cuatro modelos nuevos + contexto 1M el primer día — los resúmenes IA de video y podcast suben de nivel
¡Llegó DeepSeek-V4! BibiGPT lanza cuatro modelos nuevos + contexto 1M el primer día — los resúmenes IA de video y podcast suben de nivel
Hoy (24 de abril de 2026) DeepSeek-V4 Preview se lanzó oficialmente y se hizo totalmente open source — el contexto 1M ya es el default y la capacidad de agente cerró la brecha con Sonnet 4.5. BibiGPT completó la integración el mismo día y DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash y V4 Flash Thinking ya son seleccionables directo en el selector de modelo, listos para un documental completo, una entrevista de dos horas o una temporada entera de podcast.
Pasamos los modelos por unos cuantos escenarios reales de inmediato. Este post es una nota práctica compartida al mismo tiempo, para cualquiera que trabaje con el mismo tipo de contenido.
Tabla de contenidos
- Qué hay nuevo en DeepSeek-V4
- Los cuatro modelos DeepSeek V4 ahora vivos en BibiGPT
- Cambia a DeepSeek V4 en tres pasos
- Hands-on: resumir el video de lanzamiento del propio DeepSeek con V4 Pro
- Escenarios donde cambiar a V4 aplica directo
- La era IA: lo escaso no son los modelos, sino qué tan rápido consumes contenido
- FAQ
Qué hay nuevo en DeepSeek-V4
DeepSeek-V4 mueve tres diales clave a la vez. Cada uno merece nota aparte.
Primero, el contexto 1M se vuelve default en los servicios oficiales de DeepSeek. El nuevo mecanismo de atención comprime en la dimensión de tokens y se combina con DSA (DeepSeek Sparse Attention) para reducir costo de memoria y cómputo. En términos prácticos, alimentar una hora de subtítulos ya no exige la rutina de “trocear y coser” — el modelo lo lee como un cuerpo continuo.
Segundo, la capacidad de agente da un salto claro. Por la propia medición de DeepSeek, V4-Pro lidera todos los modelos open source en Agentic Coding y entrega calidad cercana a Opus 4.6 non-thinking; ya lo usan como modelo interno default de coding. Para los usuarios cotidianos, esto se traduce en una estructuración de texto largo más confiable — capítulos, extracción de puntos clave, generación de mapa mental — con estabilidad notablemente mejor.
Tercero, Pro y Flash se complementan. Pro (1.6T params / 49B activos / 33T tokens de pre-training) apunta a los modelos cerrados top; Flash (284B / 13B / 32T) es la opción cost-efficient. Ambos soportan modos thinking y non-thinking, y el modo thinking soporta tuning de reasoning_effort. Flash para tareas simples, Pro para las pesadas — ambos se sienten sólidos.

El anuncio original (en chino) está acá: DeepSeek-V4 Preview: la era del millón de tokens se vuelve mainstream. Los pesos del modelo están en la colección Hugging Face DeepSeek V4 (Pro / Pro-Base / Flash / Flash-Base, cuatro repos); el reporte técnico está en DeepSeek_V4.pdf.
Los cuatro modelos DeepSeek V4 ahora vivos en BibiGPT
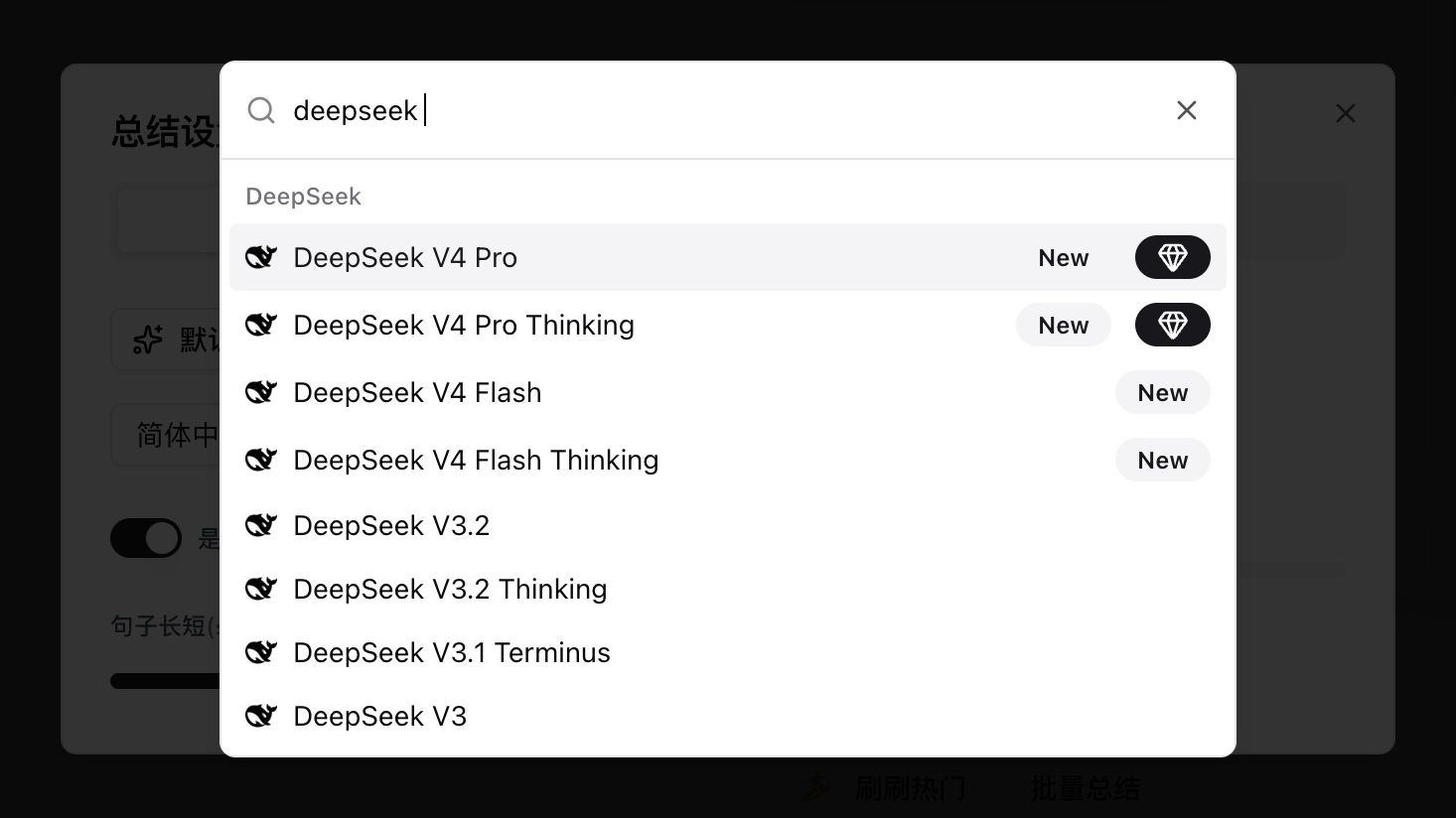
Abre cualquier configuración de resumen de video o audio, escribe deepseek en el selector de modelo y verás cuatro entradas nuevas etiquetadas New:
| Modelo | Caso de uso | Thinking |
|---|---|---|
| DeepSeek V4 Pro | Calidad top-tier para contenido largo y de lógica pesada | Non-thinking |
| DeepSeek V4 Pro Thinking | V4 Pro con razonamiento explícito — agente y análisis profundo | Thinking |
| DeepSeek V4 Flash | Cost-efficient, ideal para contenido corto y casual | Non-thinking |
| DeepSeek V4 Flash Thinking | Flash con razonamiento, balanceando velocidad y profundidad | Thinking |
¿Cuál elegir? Una regla simple de decisión:
- Contenido más largo (sobre una hora, temporadas completas de podcast, entrevistas largas) → Pro o Pro Thinking para razonamiento más profundo en toda la pieza
- Contenido más corto (bajo 30 minutos, reuniones, vlogs diarios) → Flash, más rápido y económico
- Quieres que el modelo razone paso a paso, compare puntos de vista, vaya más profundo → elige una variante Thinking
- Solo necesitas un resumen limpio, sin traza de razonamiento → elige una variante non-thinking
Si no quieres comparar con cuidado, empieza con V4 Pro Thinking — entrega resultados consistentes en la mayoría de escenarios de contenido largo.
Cambia a DeepSeek V4 en tres pasos
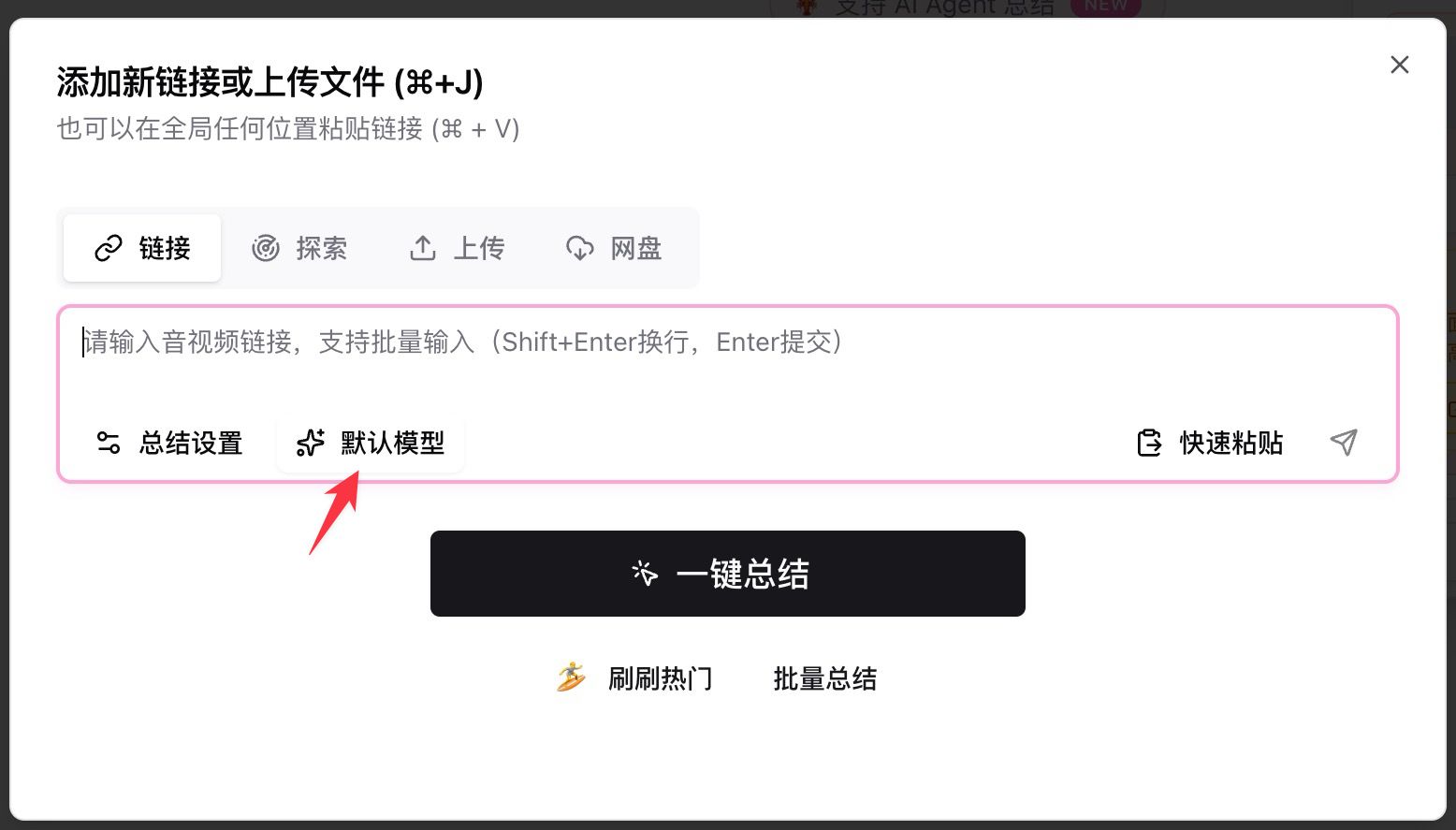
- Abre BibiGPT, pega un enlace de YouTube / podcast / archivo local en el input
- Haz clic en Default Model debajo del input, escribe
deepseeken la barra de búsqueda - Elige cualquiera de las cuatro entradas New y dale al botón de resumir
La selección persiste entre sesiones. Los power users pueden fijar V4 Pro Thinking como el default custom summary, así cada video futuro pasa por él automáticamente.
¿Quieres sentir la calidad de resumen de BibiGPT antes de cambiar de modelo? Tira cualquier enlace en el widget de abajo:
Hands-on: resumir el video de lanzamiento del propio DeepSeek con V4 Pro
Lo primero que hicimos fue correr V4 Pro sobre el propio video de lanzamiento de DeepSeek. Dura alrededor de un minuto y medio, y con thinking mode activado, el modelo lo dividió en siete capítulos estructurados, cada uno con su propio resumen, highlights, reflexión y revisión crítica.
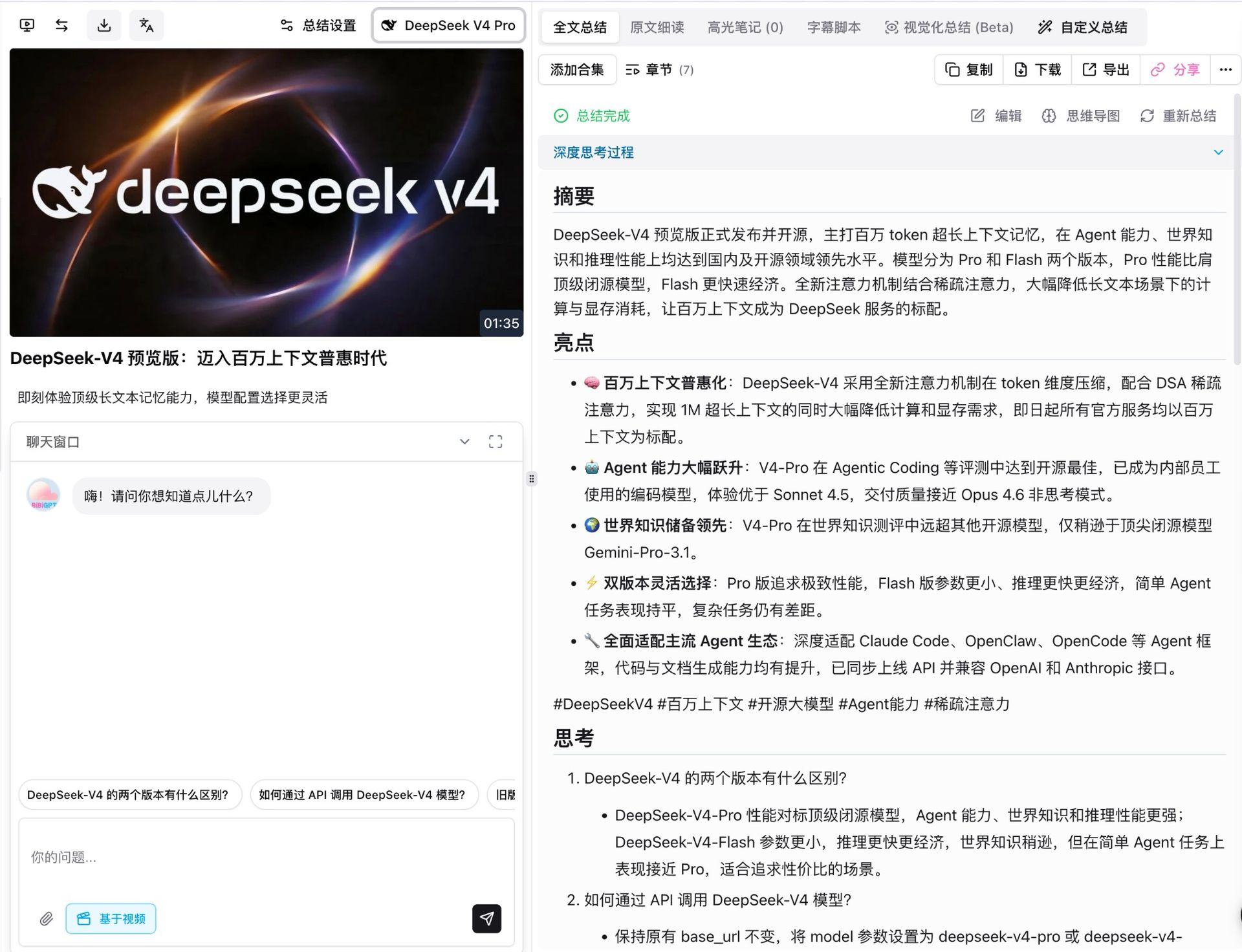
Algunos detalles que vale la pena destacar:
- Cobertura completa de hechos: las cinco afirmaciones titulares del release (contexto 1M como default, salto de agente, liderazgo en world-knowledge, flexibilidad de doble-tier, compatibilidad de ecosistema de agente) salieron con precisión, incluyendo los números de parámetros
- Cada conclusión es trazable: cada punto enlaza de vuelta a un timestamp clickeable del video, saltando directo al momento relevante
- Las preguntas de seguimiento aparecen automáticamente: bajo el resumen el modelo sugiere extensiones como “cuál es la diferencia entre los dos tiers de V4” y “cómo los llamo desde la API”, listas para una zambullida profunda en un tap
La mejora aquí viene principalmente del razonamiento más profundo del thinking mode. El long context ya es una ruta default en los modelos mayores de BibiGPT, y la llegada de V4 lleva esa combinación “razonamiento profundo + estabilidad de transcripción completa” al tier open source con calidad first-rate.
Escenarios donde cambiar a V4 aplica directo
Los modelos open source siguen cayendo. Podrías preguntar: ¿no puedo usar el sitio web de DeepSeek o la API directamente? ¿Por qué pasar por BibiGPT?
Se reduce al escenario. El sitio de DeepSeek es un chatbox genérico — todavía tienes que descargar el video, transcribir, pegar y averiguar cómo hacer prompt. BibiGPT ha estado haciendo una cosa por años: hacer videos largos y podcasts tan fáciles de consumir como leer un artículo. V4 es la capacidad más nueva añadida a ese stack; lo que de verdad hace que “pega un enlace, obtén comprensión real” funcione es la capa de producto que hemos refinado alrededor del modelo.
Dentro de BibiGPT, las siguientes capacidades siguen directo el modelo que elijas como tu “Default Model” — en otras palabras, una vez que cambias a DeepSeek V4, estas funciones corren con V4.
📝 Resúmenes de video (Default + Custom Prompt)
Lo que más usas — darle a “Summarize” tras pegar un enlace — corre con el modelo que tengas seleccionado. Cualquier prompt personalizado guardado (cosas como “Counterintuitive Analyst”, “Critical Thinking” o “Investment Analyst”) va por el mismo modelo. Cambia a DeepSeek V4 Pro Thinking, vuelve a correr el mismo video con el mismo prompt y obtienes una comparación side-by-side directa en profundidad de razonamiento y estructura. Este es uno de los escenarios que estamos explorando nosotros mismos — córrelo sobre tu propio contenido y mira si el resultado encaja mejor con tus expectativas.
🎯 AI Video Chat con trazabilidad de fuente
La ventana de chat debajo de la página de detalle del video también sigue el modelo default. Cada respuesta carga un timestamp clickeable — “hizo el punto opuesto en 1:12:30”, un tap y saltas allá. Una vez que has cambiado a V4, elige una entrevista de 1+ hora y haz unas cuantas rondas de preguntas de seguimiento — este es un escenario donde las diferencias entre modelos tienden a aparecer rápido y vale una pasada de primera mano.
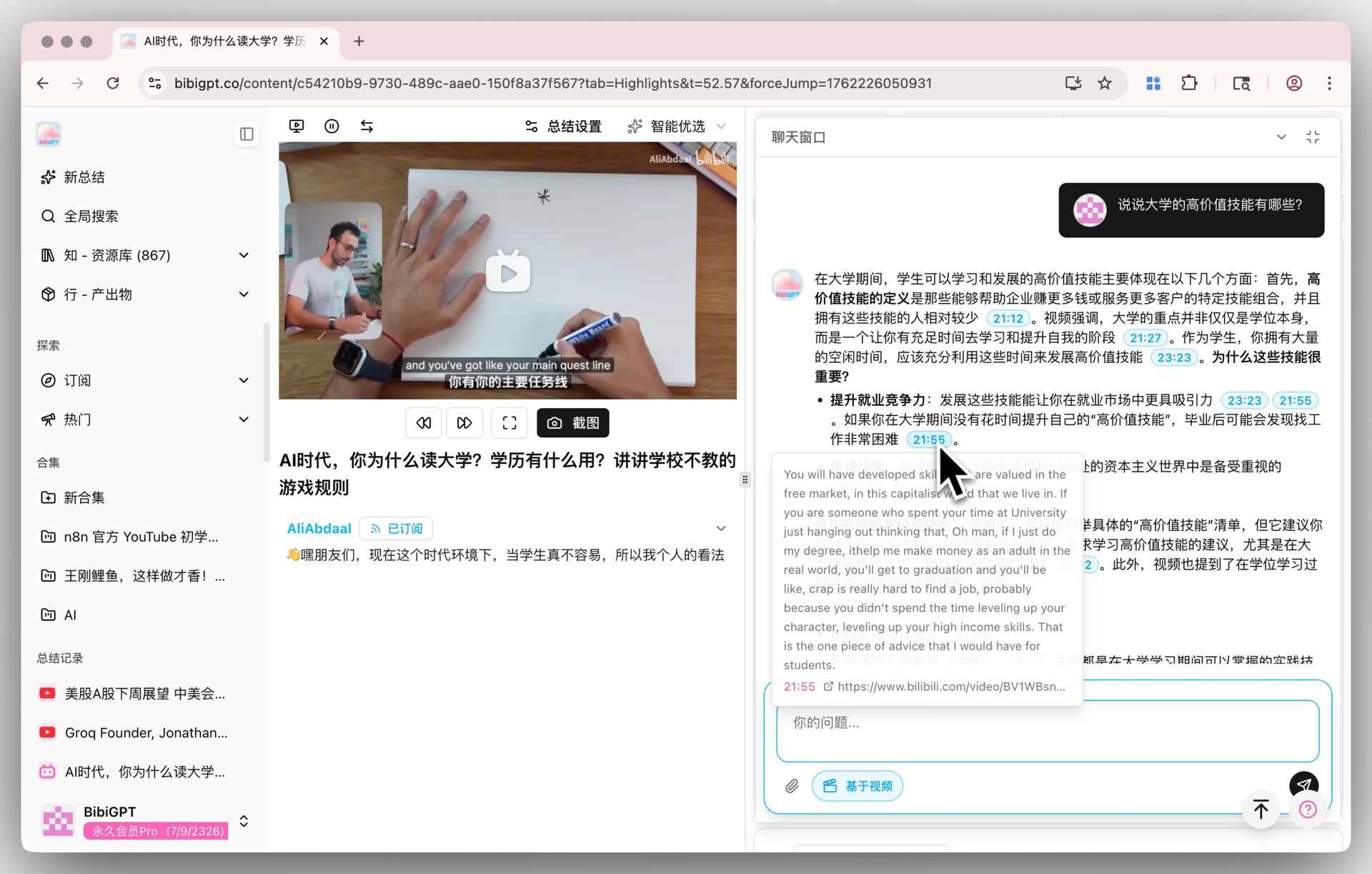
🔖 AI Highlight Notes
Extraer los clips destacados de un video con timestamps — agrupados por tema — también corre con el modelo default. Si ya generaste highlight notes para algún video con otro modelo, vuelve a correrlas con V4 y compara qué clips quedan marcados como destacados y cómo se agrupan los temas. Si la diferencia es significativa sobre tu contenido es más fácil de juzgar haciéndolo tú.
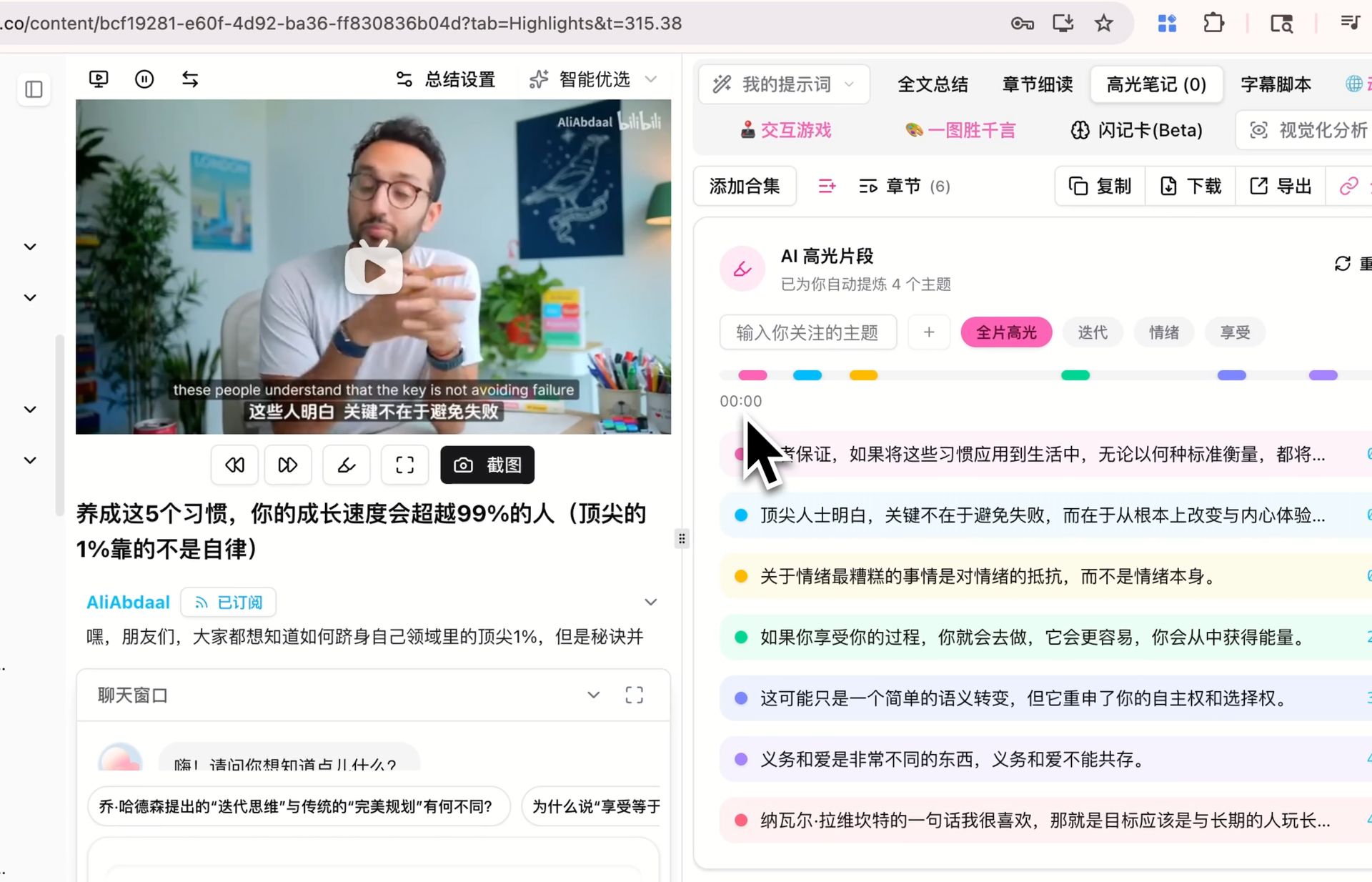
Los tres son escenarios que seguimos evaluando nosotros mismos — los resultados varían según contenido, prompt e idioma, y la lectura más confiable es la que te formas tras unas cuantas pasadas dentro de tu propio flujo.
Hay un par de áreas que usan modelos dedicados — el análisis de contenido visual corre con un modelo de visión, y el video-a-artículo-ilustrado usa un pipeline fijo — así que no responden al cambio de default-model y no son parte de la comparación de arriba.
BibiGPT ha servido 1M+ usuarios y generado 5M+ resúmenes IA hasta la fecha. Esa escala nos ayuda a mapear cada modelo nuevo a escenarios del mundo real rápido, en vez de quedarnos en la capa de comparación de benchmarks.
La era IA: lo escaso no son los modelos, sino qué tan rápido consumes contenido
En 2026, los modelos IA son esencialmente como agua corriente — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 están todos al alcance. Los modelos ya no son escasos.
¿Qué es escaso? Qué tan rápido conviertes información en opiniones, y opiniones en acción.
Audio y video son el formato de menor densidad y mayor tiempo de consumo en internet. Una entrevista de dos horas transcrita son 8.000 palabras, pero la tesis real puede ser 300. Una temporada de podcast de 30 horas rinde quizás 20 quotes duraderas. Por años el único truco fue 1.5x o 2x de playback — cambiar atención por densidad. Con los últimos modelos, la matemática se invierte:
- Se acabó escuchar pasivo, solo haz las preguntas que te importan — el modelo saca las respuestas de la transcripción
- No hace falta terminar antes de juzgar, lee primero el resumen, luego decide si merece la hora
- Se acabó pasar de un video a otro, busca a través de todos — “quién entre los 100 creadores que sigo ha hablado de este tema”
BibiGPT hace una cosa: enchufa el mejor modelo disponible al formato más grande pero más difícil de consumir — audio y video — para que cualquiera pueda comprimir dos horas de video en quince minutos de lectura de alta densidad. DeepSeek V4 suma una opción confiable más a ese stack.
FAQ
Q1: ¿Cuál es la diferencia entre DeepSeek V4 Pro y V4 Pro Thinking?
La diferencia central es si el razonamiento es explícito. Non-thinking tiene menor latencia con salida más corta, bueno para un resumen limpio. El modo thinking genera primero una cadena de razonamiento — mejor para lógica multi-paso, comparación cross-capítulo o análisis de argumento. Puedes ajustar profundidad con reasoning_effort=high/max; razonamiento más profundo, salida más lenta.
Q2: ¿Elijo V4 Pro o V4 Flash?
Piensa en términos de “longitud × complejidad de razonamiento”. Sobre una hora o razonamiento multi-paso → Pro. Bajo treinta minutos y un resumen limpio basta → Flash. En la duda, empieza con Flash y cambia a Pro si se queda corto — BibiGPT cachea la transcripción, así que volver a resumir salta el paso de transcripción por completo.
Q3: ¿Por qué pasar por BibiGPT en vez de usar el sitio de DeepSeek directamente?
El sitio de DeepSeek es un chatbox genérico — todavía tienes que descargar, transcribir, pegar y hacer prompt tú. BibiGPT maneja el pipeline upstream (parseo de enlaces de 30+ plataformas, transcripción, análisis visual, alineación de timestamps), y DeepSeek V4 solo necesita cubrir el paso final de entender-y-generar. Mismo input, y adicionalmente obtienes mapas mentales, highlight notes, artículos ilustrados y exports estructurados sin ningún ensamblado extra.
Q4: ¿Qué tan largo puede manejar un video DeepSeek V4?
V4 Pro y Flash tienen 1M tokens de contexto — aproximadamente 1.5 millones de caracteres chinos, o más de 20 horas de diálogo — suficiente para una temporada completa de podcast. BibiGPT decide automáticamente entre resumen de una pasada y trocear-y-consolidar según el contexto efectivo del modelo.
Q5: ¿Los pesos de DeepSeek V4 son open source?
Totalmente open source. Los pesos están en Hugging Face deepseek-ai/deepseek-v4 y ModelScope; el reporte técnico está en DeepSeek_V4.pdf. Investigadores y self-hosters pueden agarrarlos directo.
Prueba V4 ya
La forma más directa de sentir V4: elige un video largo que querías ver de verdad — una clase, un episodio de podcast, un documental, lo que sea — y pásalo por DeepSeek V4 Pro Thinking. Mira cómo V4 maneja algo que de verdad te importa.
Empieza tu viaje de aprendizaje IA eficiente ya:
- 🌐 Sitio oficial: https://bibigpt.co/es/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 Descarga móvil: https://aitodo.co/app
- 💻 Descarga desktop: https://aitodo.co/download/desktop
- ✨ Conoce más funciones: https://aitodo.co/features
BibiGPT Team