DeepSeek-V4 chegou! BibiGPT lança quatro novos modelos + contexto 1M no primeiro dia — resumo de vídeo e podcast com IA acabou de subir de nível
DeepSeek-V4 chegou! BibiGPT lança quatro novos modelos + contexto 1M no primeiro dia — resumo de vídeo e podcast com IA acabou de subir de nível
Hoje (24 de abril de 2026) DeepSeek-V4 Preview foi oficialmente lançado e tornou-se totalmente open-source — contexto 1M é agora o padrão, e a capacidade de agente fechou a lacuna com Sonnet 4.5. BibiGPT concluiu a integração no mesmo dia, e DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash e V4 Flash Thinking já estão selecionáveis diretamente no seletor de modelos, prontos para um documentário completo, uma entrevista de duas horas ou uma temporada inteira de podcast.
Rodamos os modelos em alguns cenários reais imediatamente. Este post é uma nota prática compartilhada ao mesmo tempo, para quem trabalha com o mesmo tipo de conteúdo.
Sumário
- Novidades no DeepSeek-V4
- Os quatro modelos DeepSeek V4 agora ativos no BibiGPT
- Mudar para DeepSeek V4 em três passos
- Prática: resumindo o próprio vídeo de lançamento da DeepSeek com V4 Pro
- Cenários onde mudar para V4 se aplica diretamente
- A era da IA: o que é escasso não são modelos, mas a velocidade com que você consome conteúdo
- FAQ
Novidades no DeepSeek-V4
DeepSeek-V4 move três botões-chave de uma vez. Cada um merece uma nota separada.
Primeiro, contexto 1M torna-se padrão em todos os serviços oficiais da DeepSeek. O novo mecanismo de atenção comprime ao longo da dimensão de tokens e combina com DSA (DeepSeek Sparse Attention) para cortar custo de memória e computação. Em termos práticos, alimentar uma hora de legendas não exige mais a rotina de “fragmentar e costurar” — o modelo lê como um corpo contínuo.
Segundo, capacidade de agente dá um passo claro à frente. Pela própria medição da DeepSeek, V4-Pro lidera todos os modelos open-source em Agentic Coding e entrega qualidade próxima a Opus 4.6 não-pensante; eles já o usam como modelo padrão interno de codificação. Para usuários do dia a dia, isso se traduz em estruturação de texto longo mais confiável — capítulos, extração de pontos-chave, geração de mapa mental — com estabilidade notavelmente melhor.
Terceiro, Pro e Flash se complementam. Pro (1,6T params / 49B ativos / 33T tokens de pré-treino) mira modelos closed-source de topo; Flash (284B / 13B / 32T) é a opção custo-eficiente. Ambos suportam modos pensante e não-pensante, e o modo pensante suporta ajuste de reasoning_effort. Flash para tarefas simples, Pro para pesadas — ambos parecem sólidos.

O anúncio original (em chinês) está aqui: DeepSeek-V4 Preview: a era do milhão de tokens vai ao mainstream. Os pesos do modelo estão disponíveis na coleção Hugging Face DeepSeek V4 (Pro / Pro-Base / Flash / Flash-Base, quatro repositórios); o relatório técnico está em DeepSeek_V4.pdf.
Os quatro modelos DeepSeek V4 agora ativos no BibiGPT
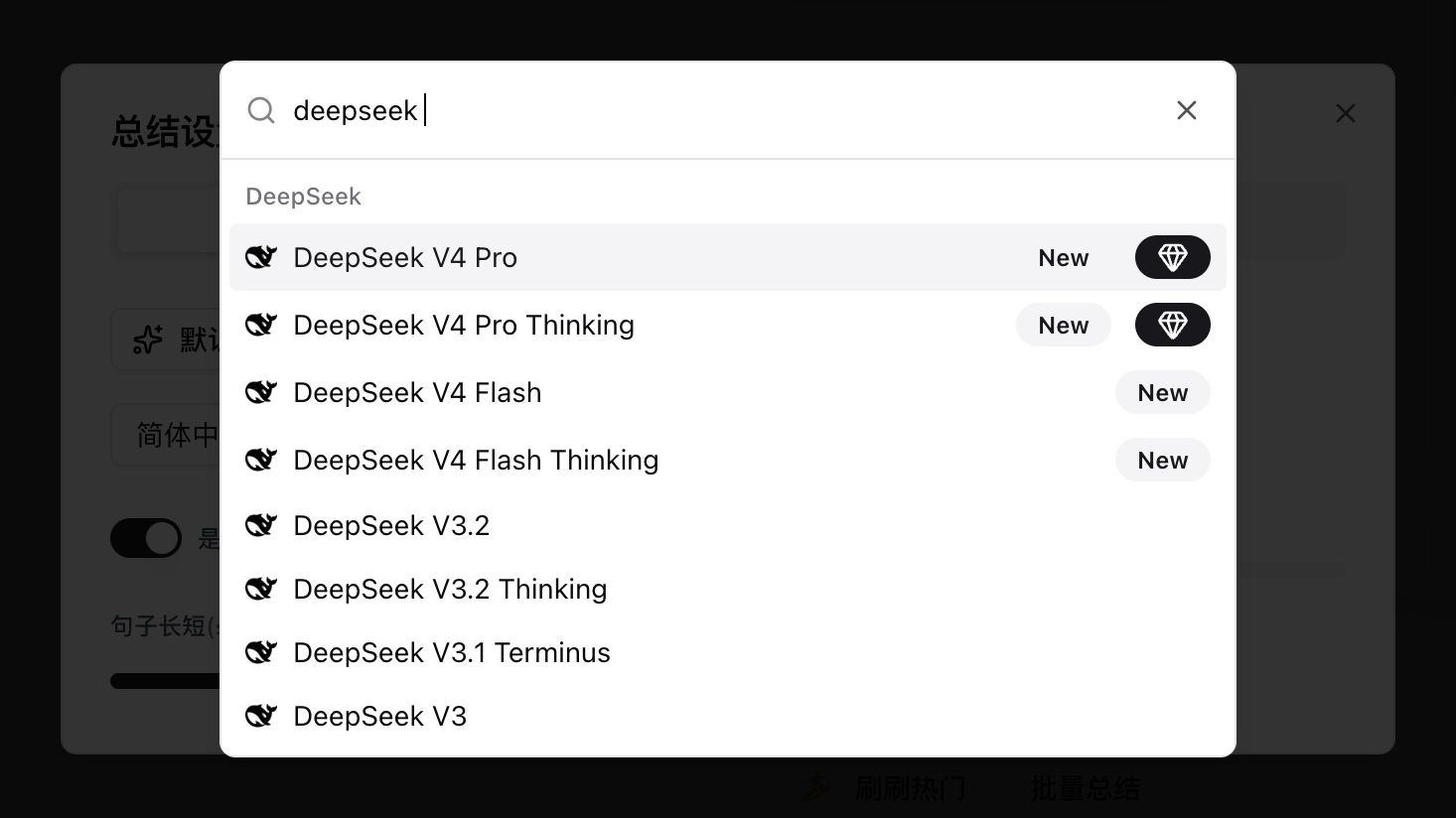
Abra qualquer configuração de resumo de vídeo ou áudio, digite deepseek no seletor de modelos, e você verá quatro novas entradas marcadas como New:
| Modelo | Caso de uso | Pensamento |
|---|---|---|
| DeepSeek V4 Pro | Qualidade de topo para conteúdo longo e logicamente pesado | Não-pensante |
| DeepSeek V4 Pro Thinking | V4 Pro com raciocínio explícito — agente e análise profunda | Pensante |
| DeepSeek V4 Flash | Custo-eficiente, ótimo para conteúdo curto e casual | Não-pensante |
| DeepSeek V4 Flash Thinking | Flash com raciocínio, equilibrando velocidade e profundidade | Pensante |
Qual escolher? Uma regra simples de decisão:
- Conteúdo mais longo (mais de uma hora, temporadas completas de podcast, entrevistas longas) → Pro ou Pro Thinking para raciocínio mais profundo em toda a peça
- Conteúdo mais curto (menos de 30 minutos, reuniões, vlogs diários) → Flash, mais rápido e econômico
- Quer que o modelo raciocine passo a passo, compare pontos de vista, vá mais fundo → escolha uma variante Thinking
- Só precisa de um resumo limpo, sem traço de raciocínio → escolha uma variante não-pensante
Se você não quer comparar com cuidado, comece com V4 Pro Thinking — entrega resultados consistentes na maioria dos cenários de conteúdo longo.
Mudar para DeepSeek V4 em três passos
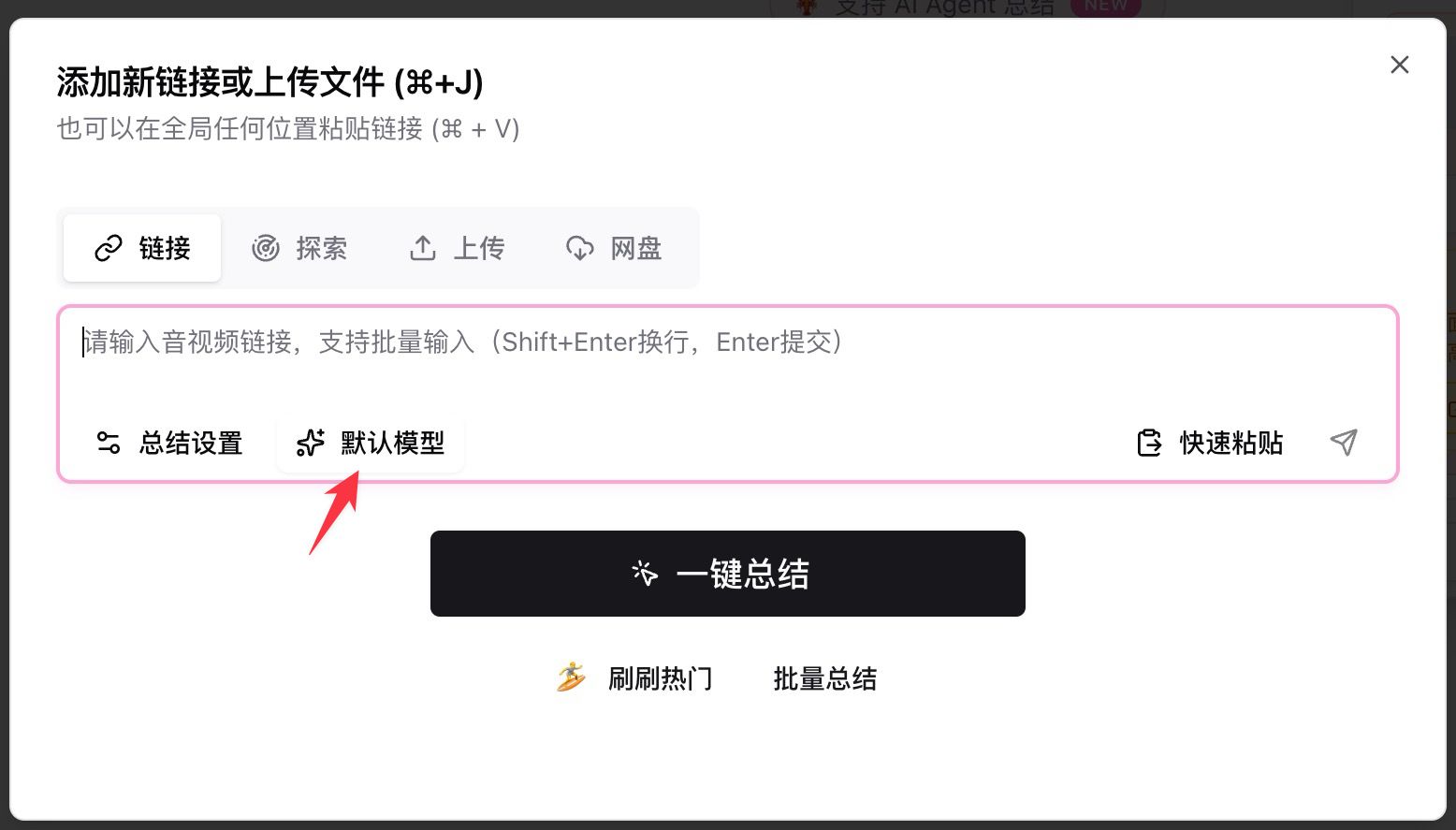
- Abra BibiGPT, cole um link de YouTube / podcast / arquivo local na caixa de entrada
- Clique em Default Model abaixo da entrada, digite
deepseekna barra de busca - Escolha qualquer uma das quatro entradas New e aperte o botão de resumir
A seleção persiste entre sessões. Power users podem fixar V4 Pro Thinking como o resumo personalizado padrão, para que cada vídeo futuro passe por ele automaticamente.
Quer sentir a qualidade de resumo do BibiGPT antes de trocar de modelo? Coloque qualquer link no widget abaixo:
Prática: resumindo o próprio vídeo de lançamento da DeepSeek com V4 Pro
A primeira coisa que fizemos foi rodar V4 Pro no próprio vídeo de lançamento da DeepSeek. Tem cerca de um minuto e meio, e com modo pensante ligado, o modelo o dividiu em sete capítulos estruturados, cada um com seu próprio resumo, destaques, reflexão e revisão crítica.
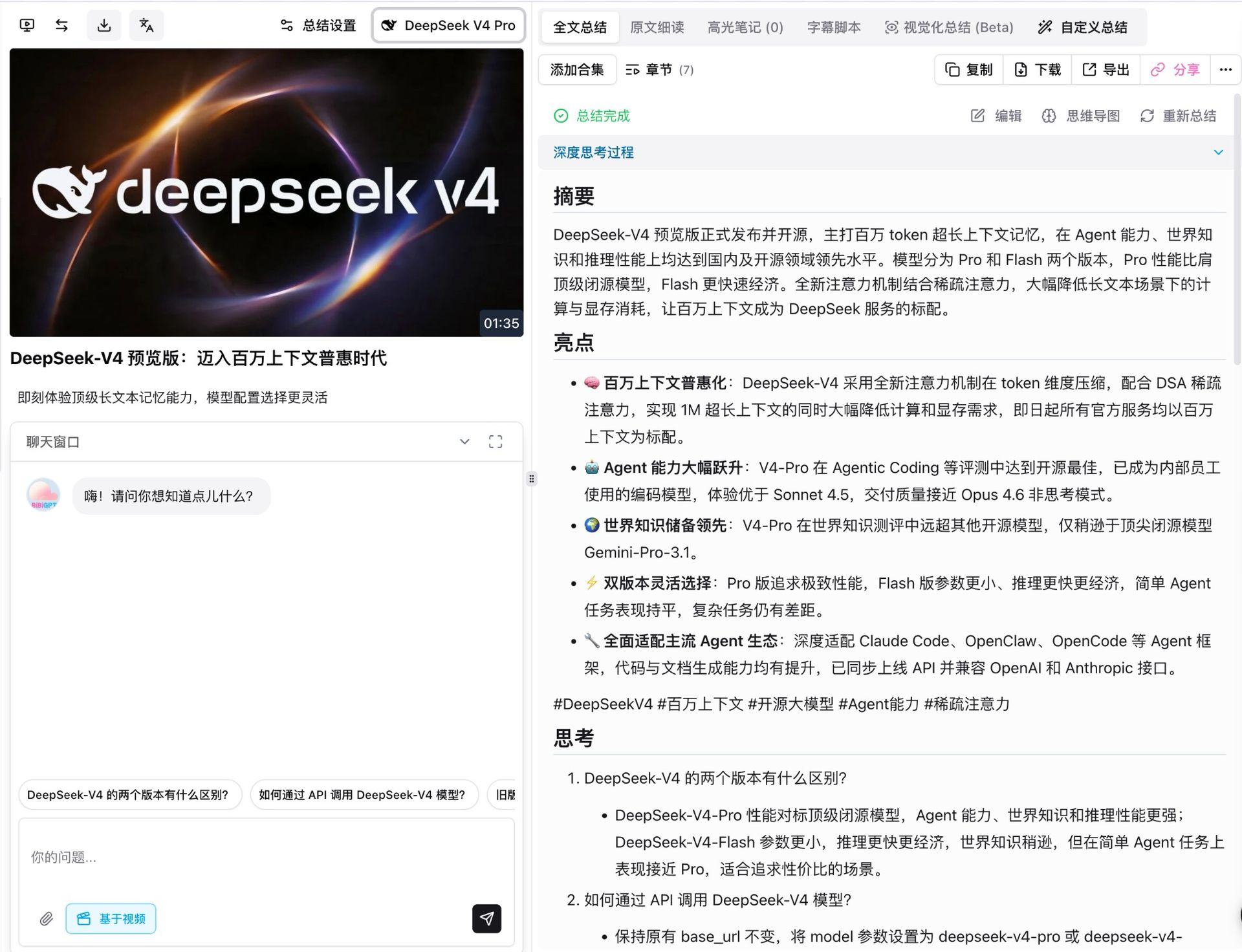
Alguns detalhes valem destacar:
- Cobertura factual completa: todas as cinco afirmações principais do lançamento (contexto 1M como padrão, salto de agente, liderança em conhecimento de mundo, flexibilidade de duas camadas, compatibilidade do ecossistema de agente) vieram com precisão, incluindo os números de parâmetros
- Toda conclusão é rastreável: cada ponto liga de volta a um timestamp clicável de vídeo, saltando direto ao momento relevante
- Perguntas de acompanhamento aparecem automaticamente: sob o resumo o modelo sugere extensões como “qual a diferença entre as duas camadas V4” e “como chamo via API”, prontas para um aprofundamento de um toque
A melhoria aqui vem principalmente do raciocínio mais profundo do modo pensante. Contexto longo já é caminho padrão entre os principais modelos no BibiGPT, e a chegada de V4 traz essa combinação “raciocínio profundo + estabilidade de transcrição completa” para a camada open-source com qualidade de primeira linha.
Cenários onde mudar para V4 se aplica diretamente
Modelos open-source continuam aparecendo. Você pode perguntar: não posso usar o site da DeepSeek ou a API diretamente? Por que rotear pelo BibiGPT?
Tudo se resume ao cenário. O site da DeepSeek é uma caixa de chat genérica — você ainda precisa baixar o vídeo, transcrever, colar e descobrir como dar prompt. BibiGPT vem fazendo uma coisa há anos: tornar vídeos longos e podcasts tão fáceis de consumir quanto ler um artigo. V4 é a capacidade mais nova adicionada a essa pilha; o que realmente faz “cole um link, obtenha entendimento real” funcionar é a camada de produto que vimos refinando ao redor do modelo.
Dentro do BibiGPT, as seguintes capacidades seguem diretamente o modelo que você seleciona como seu “Default Model” — em outras palavras, uma vez que você muda para DeepSeek V4, esses recursos rodam em V4.
📝 Resumos de vídeo (padrão + prompt personalizado)
A coisa que você usa com mais frequência — apertar “Resumir” depois de colar um link — roda em qualquer modelo que você selecionou. Quaisquer prompts personalizados salvos (coisas como “Analista Contraintuitivo”, “Pensamento Crítico” ou “Analista de Investimento”) passam pelo mesmo modelo também. Mude para DeepSeek V4 Pro Thinking, rode novamente o mesmo vídeo com o mesmo prompt, e você obtém uma comparação lado a lado direta sobre profundidade de raciocínio e estrutura. Este é um dos cenários que ainda exploramos nós mesmos — rode em seu próprio conteúdo e veja se o resultado se encaixa melhor nas suas expectativas.
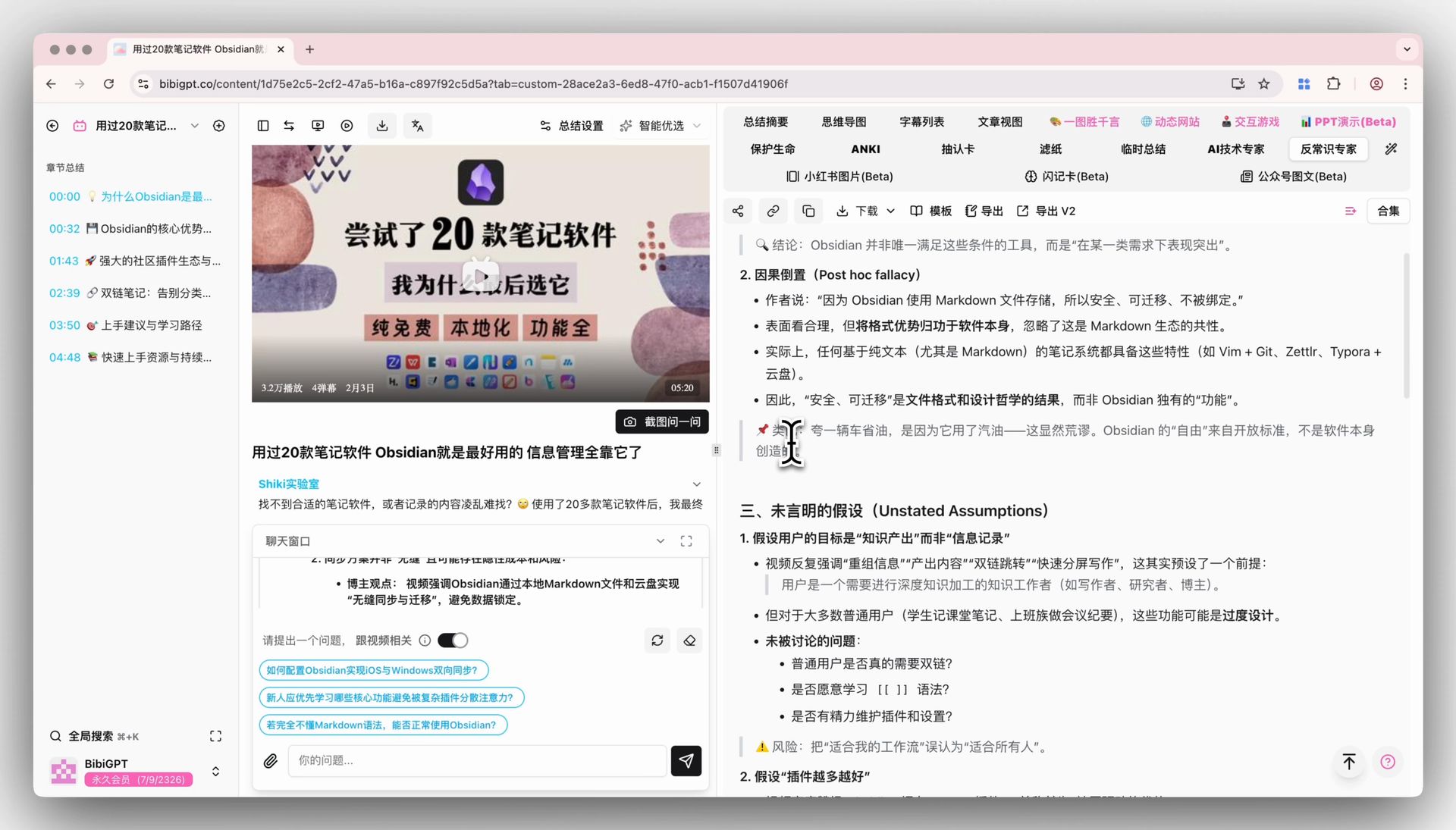
🎯 Chat de vídeo com IA com rastreamento de fonte
A janela de chat abaixo da página de detalhe do vídeo também segue o modelo padrão. Cada resposta carrega um timestamp clicável — “ele fez o ponto oposto às 1:12:30”, um toque e você salta para lá. Uma vez que mudou para V4, escolha uma entrevista de 1+ hora e faça algumas rodadas de perguntas de acompanhamento — este é um cenário onde diferenças entre modelos tendem a aparecer rapidamente, e vale a pena uma rodada em primeira mão.
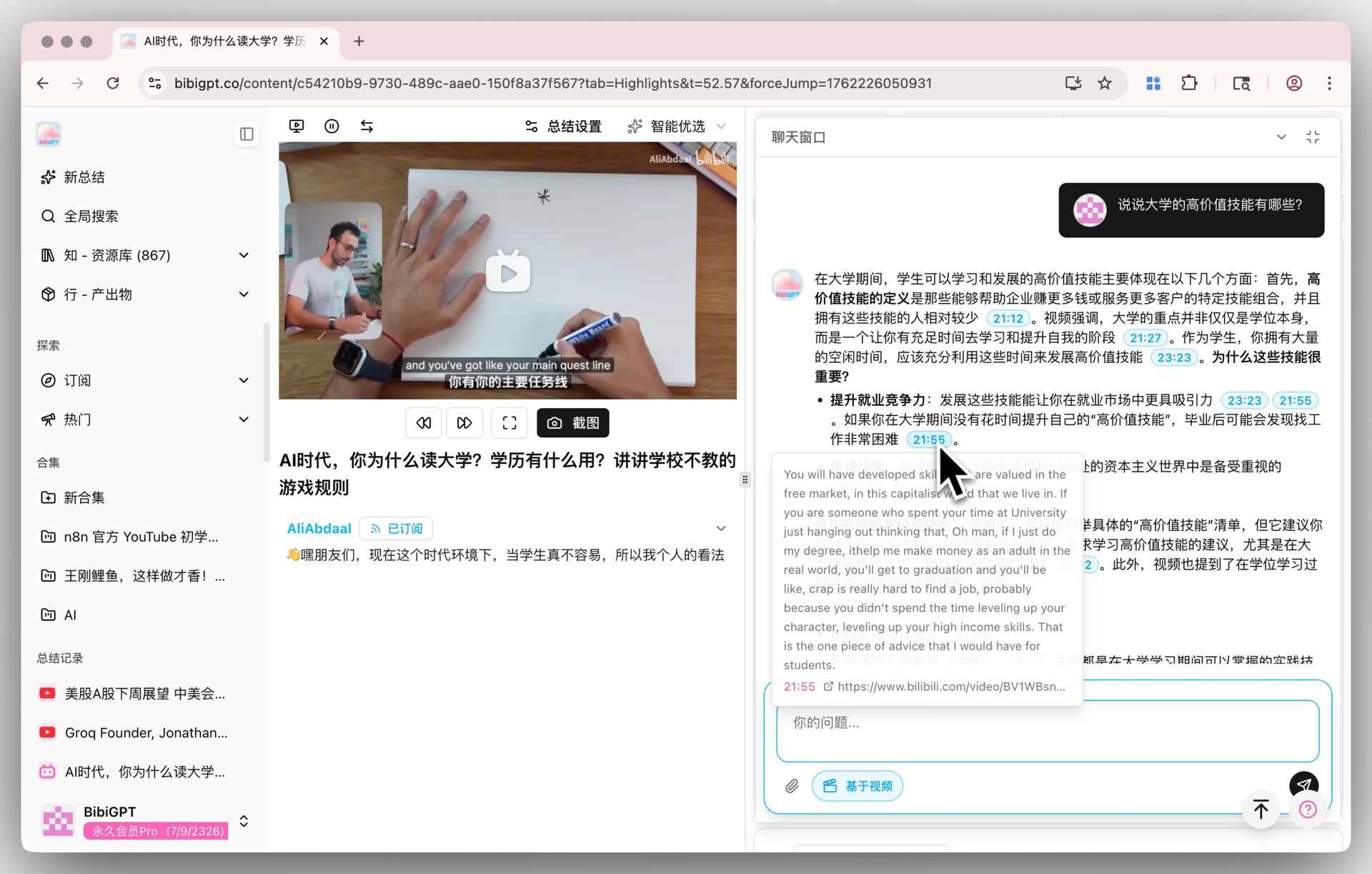
🔖 Notas de destaque com IA
Extrair os clipes de destaque de um vídeo com timestamps — agrupados por tópico — também roda no modelo padrão. Se você já gerou notas de destaque para algum vídeo em outro modelo, rode novamente em V4 e compare quais clipes são marcados como destaques e como os tópicos se agrupam. Se a diferença é significativa em seu conteúdo é mais fácil julgar fazendo você mesmo.
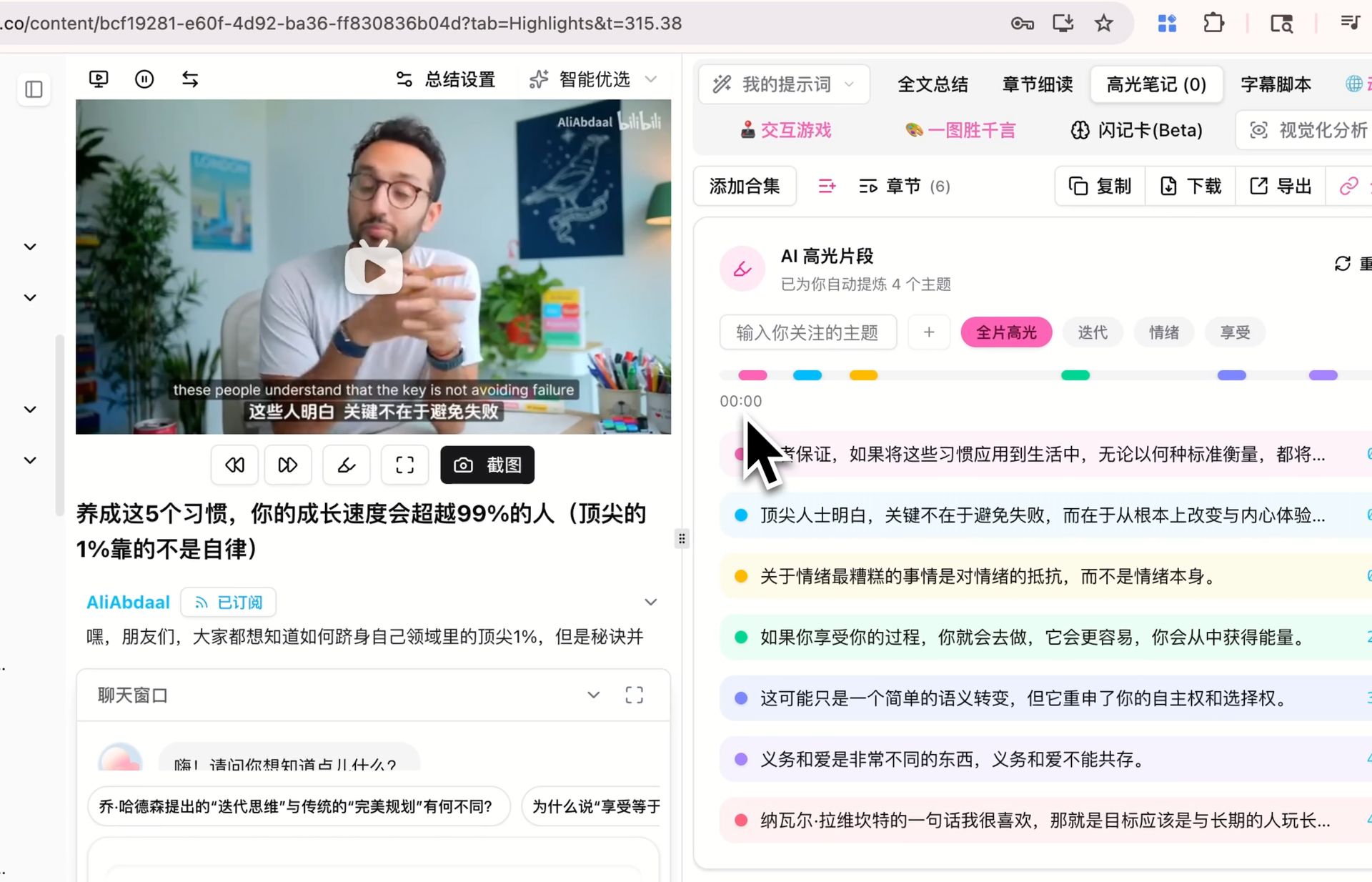
Os três são cenários que ainda avaliamos nós mesmos — resultados variam entre conteúdos, prompts e idiomas diferentes, e a leitura mais confiável é a que você forma após algumas rodadas dentro do seu próprio fluxo.
Algumas outras áreas usam modelos dedicados — análise de conteúdo visual roda em um modelo de visão, e vídeo-para-artigo-ilustrado usa um pipeline fixo — então não respondem à troca do modelo padrão e não fazem parte da comparação acima.
BibiGPT serviu mais de 1M de usuários e gerou mais de 5M de resumos com IA até hoje. Essa escala nos ajuda a mapear cada novo modelo em cenários do mundo real rapidamente, em vez de ficar na camada de comparação de benchmarks.
A era da IA: o que é escasso não são modelos, mas a velocidade com que você consome conteúdo
Em 2026, modelos de IA são essencialmente como água corrente — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 estão todos ao alcance. Modelos não são mais escassos.
O que é escasso? A velocidade com que você transforma informação em opiniões, e opiniões em ação.
Áudio e vídeo são o formato de menor densidade e mais longo de consumir na internet. Uma entrevista de duas horas transcrita são 8.000 palavras, mas a tese real pode ser 300. Uma temporada de podcast de 30 horas rende talvez 20 citações duradouras. Por anos o único truque foi reprodução em 1,5x ou 2x — trocando atenção por densidade. Com os modelos mais recentes, a matemática inverte:
- Sem mais escuta passiva, só faça as perguntas que importam para você — o modelo extrai as respostas da transcrição
- Sem precisar terminar antes de julgar, leia o resumo primeiro, depois decida se merece a hora
- Sem mais folhear um vídeo de cada vez, busque em todos eles — “quem entre os 100 criadores que sigo falou sobre este tópico”
BibiGPT faz uma coisa: conectar o melhor modelo disponível ao maior, mas mais difícil de consumir, formato — áudio e vídeo — para que qualquer um possa comprimir duas horas de vídeo em quinze minutos de leitura de alta densidade. DeepSeek V4 adiciona mais uma opção confiável a essa pilha.
FAQ
Q1: Qual a diferença entre DeepSeek V4 Pro e V4 Pro Thinking?
A diferença central é se o raciocínio é explícito. Não-pensante tem latência mais baixa com saída mais curta, bom para um resumo limpo. Modo pensante gera primeiro uma cadeia de raciocínio — melhor para lógica multi-passo, comparação entre capítulos ou análise de argumento. Você pode ajustar profundidade com reasoning_effort=high/max; raciocínio mais profundo, saída mais lenta.
Q2: Devo escolher V4 Pro ou V4 Flash?
Pense em termos de “comprimento × complexidade de raciocínio”. Acima de uma hora ou raciocínio multi-passo → Pro. Menos de trinta minutos e um resumo limpo é suficiente → Flash. Em caso de dúvida, comece com Flash e mude para Pro se ficar aquém — BibiGPT cacheia a transcrição para que re-resumir pule a etapa de transcrição inteiramente.
Q3: Por que passar pelo BibiGPT em vez de usar o site da DeepSeek diretamente?
O site da DeepSeek é uma caixa de chat genérica — você ainda precisa baixar, transcrever, colar e dar prompt sozinho. BibiGPT lida com o pipeline upstream (parsing de link de mais de 30 plataformas, transcrição, análise visual, alinhamento de timestamp), e DeepSeek V4 só precisa cobrir o passo final de entender-e-gerar. Mesma entrada, e você adicionalmente obtém mapas mentais, notas de destaque, artigos ilustrados e exportações estruturadas sem qualquer montagem extra.
Q4: Quão longo um vídeo DeepSeek V4 pode lidar?
V4 Pro e Flash ambos têm contexto de 1M tokens — aproximadamente 1,5 milhão de caracteres chineses, ou mais de 20 horas de diálogo — o suficiente para uma temporada completa de podcast. BibiGPT decide automaticamente entre resumo de uma única passagem e fragmentar-depois-consolidar com base no contexto efetivo do modelo.
Q5: Os pesos do DeepSeek V4 são open-source?
Totalmente open-source. Pesos estão em Hugging Face deepseek-ai/deepseek-v4 e ModelScope; o relatório técnico está em DeepSeek_V4.pdf. Pesquisadores e self-hosters podem pegá-los diretamente.
Experimente V4 agora
A maneira mais direta de sentir V4: escolha um vídeo longo que você queria realmente assistir — uma palestra, um episódio de podcast, um documentário, o que for — e rode pelo DeepSeek V4 Pro Thinking. Veja como V4 lida com algo com que você realmente se importa.
Comece sua jornada de aprendizado eficiente com IA agora:
- 🌐 Site oficial: https://bibigpt.co/pt/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 Download mobile: https://aitodo.co/app
- 💻 Download desktop: https://aitodo.co/download/desktop
- ✨ Conheça mais recursos: https://aitodo.co/features
BibiGPT Team