DeepSeek-V4 มาแล้ว! BibiGPT เปิดตัว 4 โมเดลใหม่ + 1M Context ในวันแรก สรุปวิดีโอและพอดแคสต์ AI ยกระดับ
DeepSeek-V4 มาแล้ว! BibiGPT เปิดตัว 4 โมเดลใหม่ + 1M Context ในวันแรก สรุปวิดีโอและพอดแคสต์ AI ยกระดับ
วันนี้ (24 เมษายน 2026) DeepSeek-V4 Preview เปิดตัวอย่างเป็นทางการและเปิดซอร์สเต็มรูปแบบ 1M context ตอนนี้เป็นค่าเริ่มต้น และความสามารถ agent ปิดช่องว่างกับ Sonnet 4.5 BibiGPT ทำการรวมในวันเดียวกันเสร็จสิ้น และ DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash, และ V4 Flash Thinking ตอนนี้เลือกได้โดยตรงในตัวเลือกโมเดล พร้อมสำหรับสารคดีเต็มเรื่อง การสัมภาษณ์สองชั่วโมง หรือพอดแคสต์ทั้งซีซัน
เรารันโมเดลผ่านสถานการณ์จริงไม่กี่อันทันที บทความนี้คือโน้ตลงมือทำที่แชร์พร้อมกัน สำหรับใครก็ตามที่ทำงานกับเนื้อหาประเภทเดียวกัน
สารบัญ
- มีอะไรใหม่ใน DeepSeek-V4
- โมเดล DeepSeek V4 สี่ตัวที่ใช้งานได้แล้วใน BibiGPT
- สลับเป็น DeepSeek V4 ใน 3 ขั้นตอน
- ลงมือ: สรุปวิดีโอเปิดตัวของ DeepSeek เองด้วย V4 Pro
- สถานการณ์ที่การสลับเป็น V4 ใช้ได้โดยตรง
- ยุค AI: สิ่งที่ขาดแคลนไม่ใช่โมเดล แต่เป็นความเร็วในการบริโภคเนื้อหา
- FAQ
มีอะไรใหม่ใน DeepSeek-V4
DeepSeek-V4 ขยับสามปุ่มหลักพร้อมกัน แต่ละอันสมควรได้โน้ตแยก
ประการแรก 1M context กลายเป็นค่าเริ่มต้นในบริการอย่างเป็นทางการของ DeepSeek ทั้งหมด กลไกความสนใจใหม่บีบอัดตามมิติโทเคนและรวมกับ DSA (DeepSeek Sparse Attention) เพื่อลดต้นทุนหน่วยความจำและการคำนวณ ในแง่ปฏิบัติ การป้อนคำบรรยายหนึ่งชั่วโมงไม่ต้องใช้กิจวัตร “แบ่งและเย็บ” อีกต่อไป โมเดลอ่านมันเป็นองค์รวมต่อเนื่อง
ประการที่สอง ความสามารถ agent ก้าวขึ้นอย่างชัดเจน จากการวัดของ DeepSeek เอง V4-Pro นำหน้าโมเดลโอเพ่นซอร์สทั้งหมดด้านโค้ดดิ้งแบบ Agentic และให้คุณภาพใกล้เคียง Opus 4.6 non-thinking พวกเขาใช้มันเป็นโมเดลโค้ดดิ้งภายในเริ่มต้นแล้ว สำหรับผู้ใช้ทั่วไป สิ่งนี้แปลเป็นการจัดโครงสร้างข้อความยาวที่เชื่อถือได้มากขึ้น การแบ่งบท การสกัดประเด็นหลัก การสร้างมายด์แมป โดยมีเสถียรภาพดีขึ้นอย่างเห็นได้ชัด
ประการที่สาม Pro และ Flash เสริมกัน Pro (1.6T params / 49B active / 33T pre-training tokens) มุ่งโมเดลปิดซอร์สชั้นนำ Flash (284B / 13B / 32T) เป็นตัวเลือกประหยัด ทั้งสองรองรับโหมด thinking และ non-thinking และโหมด thinking รองรับการปรับ reasoning_effort Flash สำหรับงานง่าย Pro สำหรับงานหนัก ทั้งคู่รู้สึกแน่น

ประกาศต้นฉบับ (เป็นภาษาจีน) อยู่ที่นี่: DeepSeek-V4 Preview: ยุค Million-Token เข้าสู่กระแสหลัก Model weights มีให้ที่ Hugging Face DeepSeek V4 collection (Pro / Pro-Base / Flash / Flash-Base สี่ repos) รายงานเทคนิคอยู่ใน DeepSeek_V4.pdf
โมเดล DeepSeek V4 สี่ตัวที่ใช้งานได้แล้วใน BibiGPT
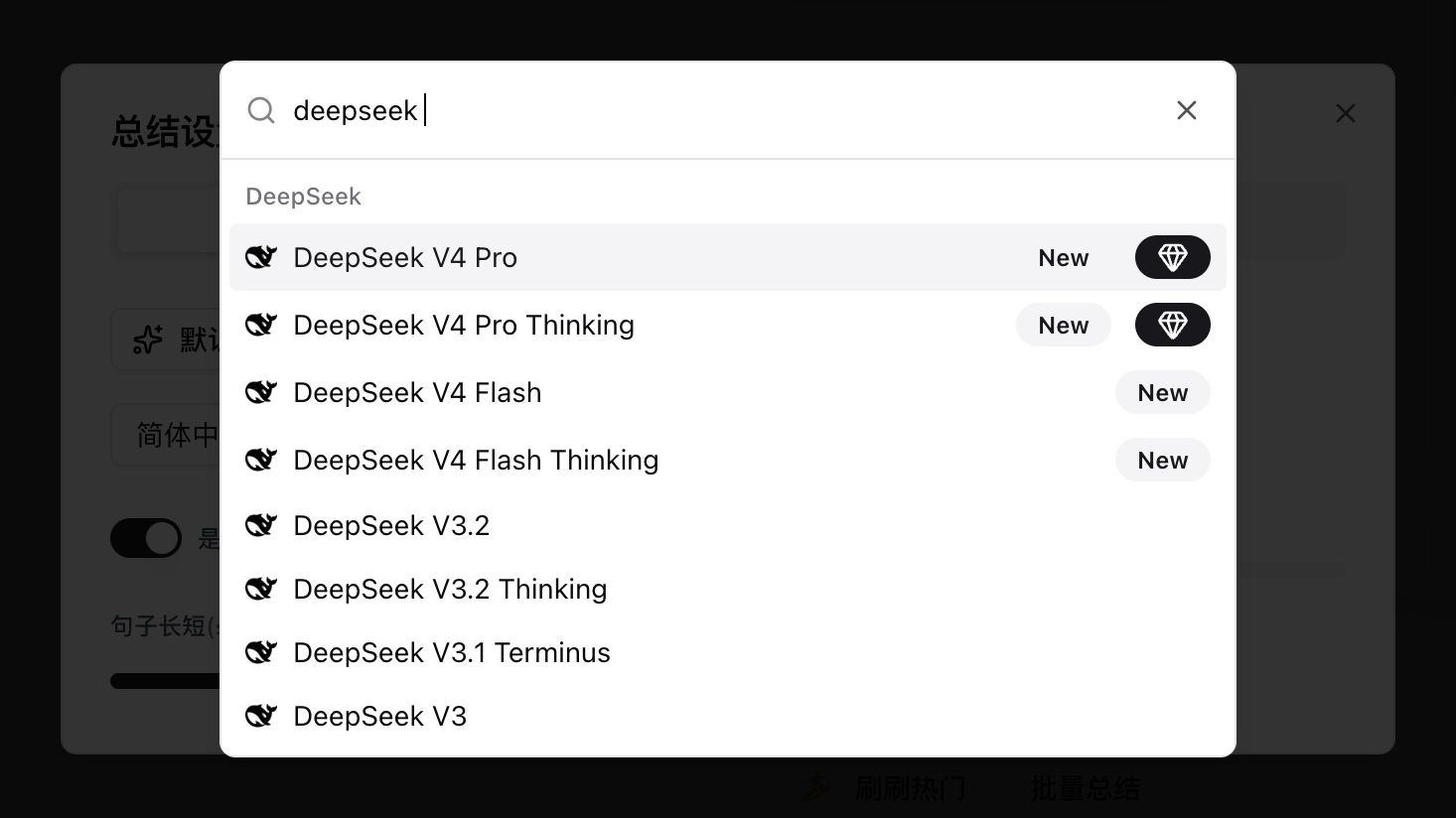
เปิดการตั้งค่าสรุปวิดีโอหรือเสียงใดๆ พิมพ์ deepseek ในตัวเลือกโมเดล แล้วคุณจะเห็นรายการใหม่สี่รายการที่แท็ก New:
| โมเดล | กรณีใช้งาน | Thinking |
|---|---|---|
| DeepSeek V4 Pro | คุณภาพระดับสูงสุดสำหรับเนื้อหายาวเชิงตรรกะหนัก | Non-thinking |
| DeepSeek V4 Pro Thinking | V4 Pro พร้อมการให้เหตุผลชัดเจน agent และการวิเคราะห์เชิงลึก | Thinking |
| DeepSeek V4 Flash | ประหยัด ดีสำหรับเนื้อหาสั้นและสบายๆ | Non-thinking |
| DeepSeek V4 Flash Thinking | Flash พร้อมการให้เหตุผล สมดุลความเร็วและความลึก | Thinking |
เลือกอันไหน? กฎการตัดสินใจง่ายๆ:
- เนื้อหายาวกว่า (เกินหนึ่งชั่วโมง พอดแคสต์เต็มซีซัน การสัมภาษณ์ยาว) → Pro หรือ Pro Thinking สำหรับการให้เหตุผลที่ลึกกว่าทั่วทั้งชิ้น
- เนื้อหาสั้นกว่า (ต่ำกว่า 30 นาที ประชุม vlog รายวัน) → Flash เร็วและประหยัดกว่า
- ต้องการให้โมเดลให้เหตุผลทีละขั้น เปรียบเทียบมุมมอง ลึกกว่า → เลือกตัวแปร Thinking
- ต้องการแค่สรุปสะอาด ไม่มีการติดตามการให้เหตุผล → เลือกตัวแปร non-thinking
ถ้าคุณไม่อยากเปรียบเทียบอย่างละเอียด เริ่มต้นด้วย V4 Pro Thinking ให้ผลลัพธ์สม่ำเสมอในสถานการณ์เนื้อหายาวส่วนใหญ่
สลับเป็น DeepSeek V4 ใน 3 ขั้นตอน
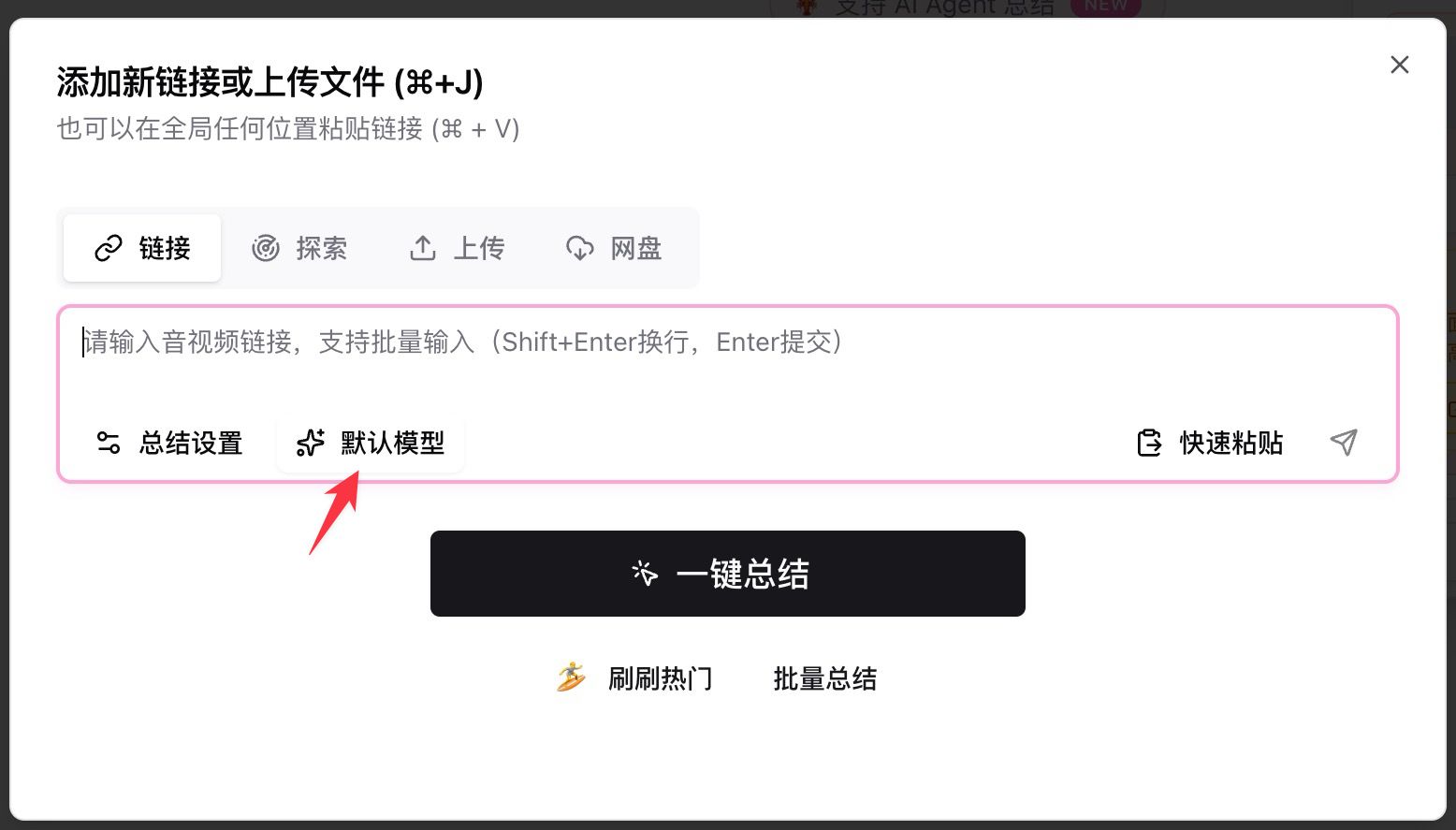
- เปิด BibiGPT วางลิงก์ YouTube / พอดแคสต์ / ไฟล์ในเครื่องในกล่องอินพุต
- คลิก Default Model ใต้กล่องอินพุต พิมพ์
deepseekในแถบค้นหา - เลือกอันใดอันหนึ่งจากสี่รายการ New แล้วกดปุ่มสรุป
การเลือกนี้คงอยู่ข้ามเซสชัน ผู้ใช้ขั้นสูงสามารถ ปักหมุด V4 Pro Thinking เป็นการสรุปแบบกำหนดเองเริ่มต้น เพื่อให้วิดีโอในอนาคตทุกอันรันผ่านมันโดยอัตโนมัติ
อยากสัมผัสคุณภาพการสรุปของ BibiGPT ก่อนเปลี่ยนโมเดล? วางลิงก์ใดๆ ในวิดเจ็ตด้านล่าง:
ลงมือ: สรุปวิดีโอเปิดตัวของ DeepSeek เองด้วย V4 Pro
สิ่งแรกที่เราทำคือรัน V4 Pro บนวิดีโอเปิดตัวของ DeepSeek เอง มันยาวประมาณนาทีครึ่ง และเมื่อเปิดโหมด thinking โมเดลแยกมันออกเป็นเจ็ดบทที่มีโครงสร้าง แต่ละบทมีสรุปของตัวเอง ไฮไลต์ การสะท้อน และการวิจารณ์เชิงวิจารณ์
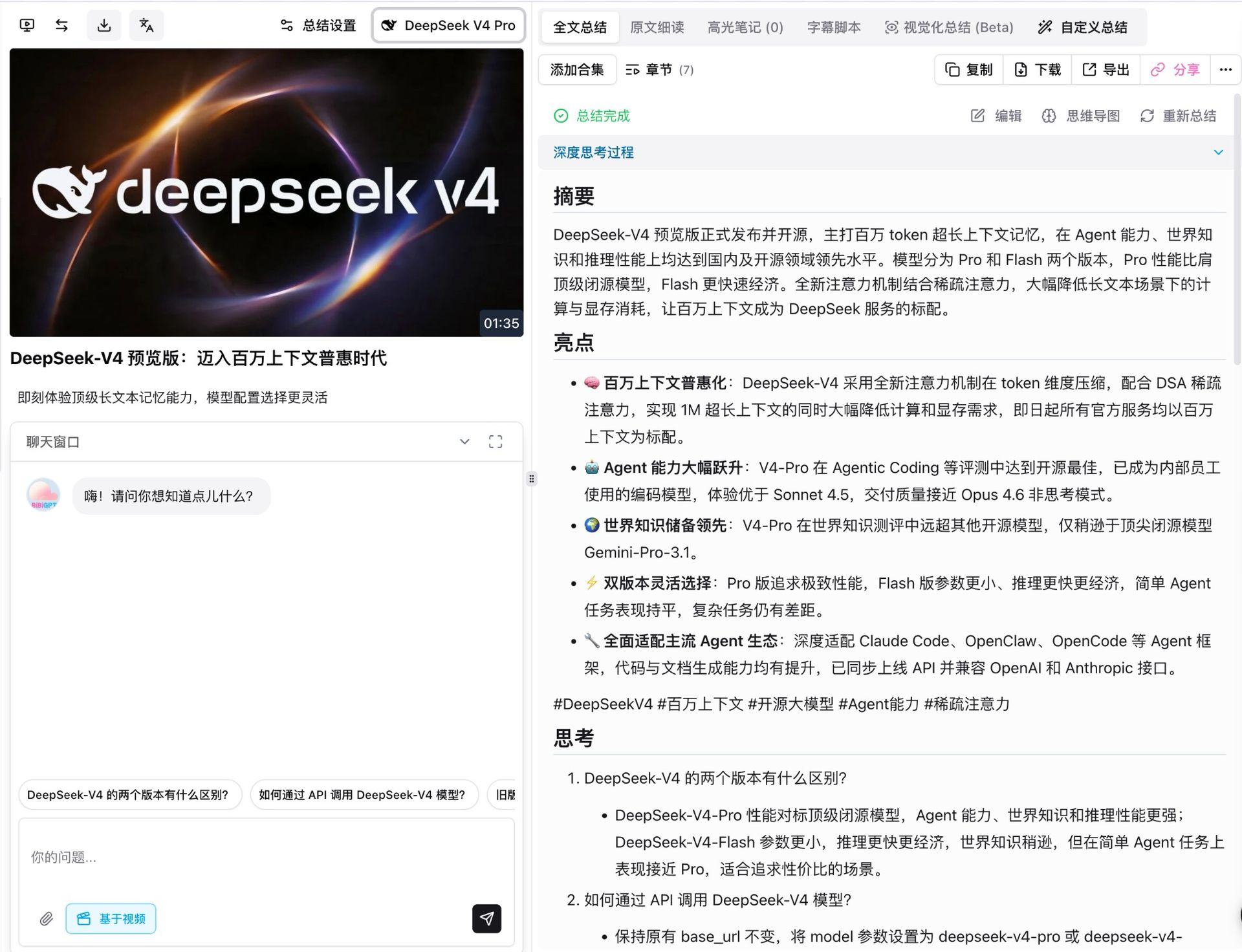
รายละเอียดสองสามอย่างที่ควรชี้ให้เห็น:
- ครอบคลุมข้อเท็จจริงเต็ม: ข้ออ้างหลักทั้งห้าจากการเปิดตัว (1M context เป็นค่าเริ่มต้น การก้าวกระโดด agent การนำหน้าด้านความรู้โลก ความยืดหยุ่นสองระดับ ความเข้ากันได้กับระบบนิเวศ agent) มาอย่างถูกต้อง รวมถึงตัวเลขพารามิเตอร์
- ทุกข้อสรุปสืบย้อนได้: ทุกจุดเชื่อมโยงกลับไปยัง timestamp วิดีโอที่คลิกได้ กระโดดตรงไปยังช่วงเวลาที่เกี่ยวข้อง
- คำถามติดตามปรากฏโดยอัตโนมัติ: ใต้สรุป โมเดลแนะนำส่วนขยายเช่น “ความแตกต่างระหว่าง V4 สองระดับคืออะไร” และ “ฉันจะเรียกผ่าน API ได้อย่างไร” พร้อมสำหรับการดำดิ่งลึกแบบแตะเดียว
การปรับปรุงที่นี่ส่วนใหญ่มาจาก การให้เหตุผลที่ลึกขึ้นของโหมด thinking Long context เป็นเส้นทางเริ่มต้นในโมเดลหลักทั้งหมดใน BibiGPT แล้ว และการมาถึงของ V4 นำการรวม “การให้เหตุผลเชิงลึก + เสถียรภาพสำเนาเสียงเต็ม” เข้าสู่ระดับโอเพ่นซอร์สด้วยคุณภาพชั้นหนึ่ง
สถานการณ์ที่การสลับเป็น V4 ใช้ได้โดยตรง
โมเดลโอเพ่นซอร์สลดราคาต่อเนื่อง คุณอาจถาม: ฉันใช้เว็บไซต์ DeepSeek หรือ API โดยตรงไม่ได้หรือ? ทำไมต้องผ่าน BibiGPT?
มันลงเอยที่สถานการณ์ เว็บไซต์ DeepSeek เป็นกล่องแชททั่วไป คุณยังต้องดาวน์โหลดวิดีโอ ถอดเสียง วาง และคิดวิธี prompt BibiGPT ทำสิ่งหนึ่งมาหลายปี: ทำให้วิดีโอและพอดแคสต์ยาวบริโภคง่ายเหมือนการอ่านบทความ V4 เป็นความสามารถใหม่สุดที่เพิ่มลงในสแต็กนั้น สิ่งที่ทำให้ “วางลิงก์ ได้ความเข้าใจจริง” ทำงานได้คือชั้นสินค้าที่เราปรับแต่งรอบโมเดล
ภายใน BibiGPT ความสามารถต่อไปนี้ ติดตามโดยตรงตามโมเดลที่คุณเลือกเป็น “Default Model” ของคุณ กล่าวคือ เมื่อคุณสลับเป็น DeepSeek V4 ฟีเจอร์เหล่านี้รันบน V4
📝 สรุปวิดีโอ (Default + Custom Prompt)
สิ่งที่คุณใช้บ่อยที่สุด การกด “Summarize” หลังจากวางลิงก์ รันบนโมเดลใดก็ตามที่คุณเลือก custom prompt ที่บันทึกไว้ (เช่น “Counterintuitive Analyst”, “Critical Thinking” หรือ “Investment Analyst”) ผ่านโมเดลเดียวกันด้วย สลับเป็น DeepSeek V4 Pro Thinking รันวิดีโอเดียวกันใหม่ด้วย prompt เดียวกัน คุณจะได้การเปรียบเทียบเคียงข้างกันโดยตรงเรื่องความลึกและโครงสร้างการให้เหตุผล นี่เป็นสถานการณ์หนึ่งที่เรากำลังสำรวจอยู่ รันบนเนื้อหาของคุณเองและดูว่าผลลัพธ์ตรงกับความคาดหวังของคุณดีกว่าหรือไม่
🎯 AI Video Chat พร้อมการสืบย้อนแหล่งที่มา
หน้าต่างแชทใต้หน้ารายละเอียดวิดีโอก็ติดตามโมเดลเริ่มต้น ทุกคำตอบมี timestamp ที่คลิกได้ “เขาพูดประเด็นตรงข้ามที่ 1:12:30” แตะเดียวคุณกระโดดไปที่นั่น เมื่อคุณสลับเป็น V4 แล้ว เลือกการสัมภาษณ์ 1+ ชั่วโมงและถามคำถามติดตามไม่กี่รอบ นี่คือสถานการณ์ที่ความแตกต่างระหว่างโมเดลปรากฏเร็ว และคุ้มค่าการรันด้วยตัวเอง
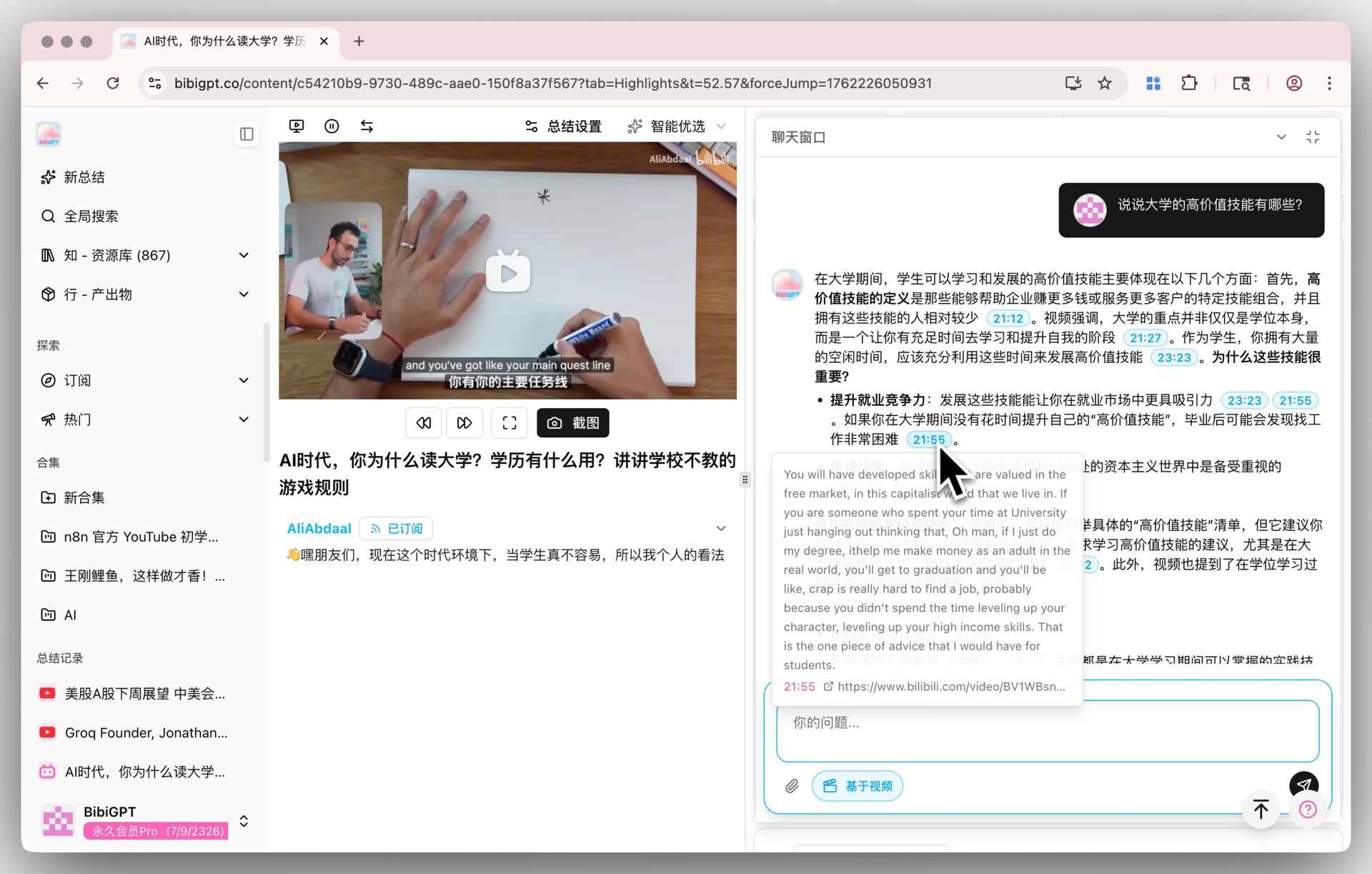
🔖 AI Highlight Notes
การสกัดคลิปไฮไลต์จากวิดีโอด้วย timestamp จัดกลุ่มตามหัวข้อ ก็รันบนโมเดลเริ่มต้น ถ้าคุณสร้างโน้ตไฮไลต์สำหรับวิดีโอบางอันบนโมเดลอื่นแล้ว รันใหม่บน V4 และเปรียบเทียบว่าคลิปไหนถูกทำเครื่องหมายเป็นไฮไลต์และหัวข้อจัดกลุ่มอย่างไร ความแตกต่างมีนัยสำคัญบนเนื้อหาของคุณหรือไม่ ตัดสินง่ายที่สุดด้วยการทำเอง
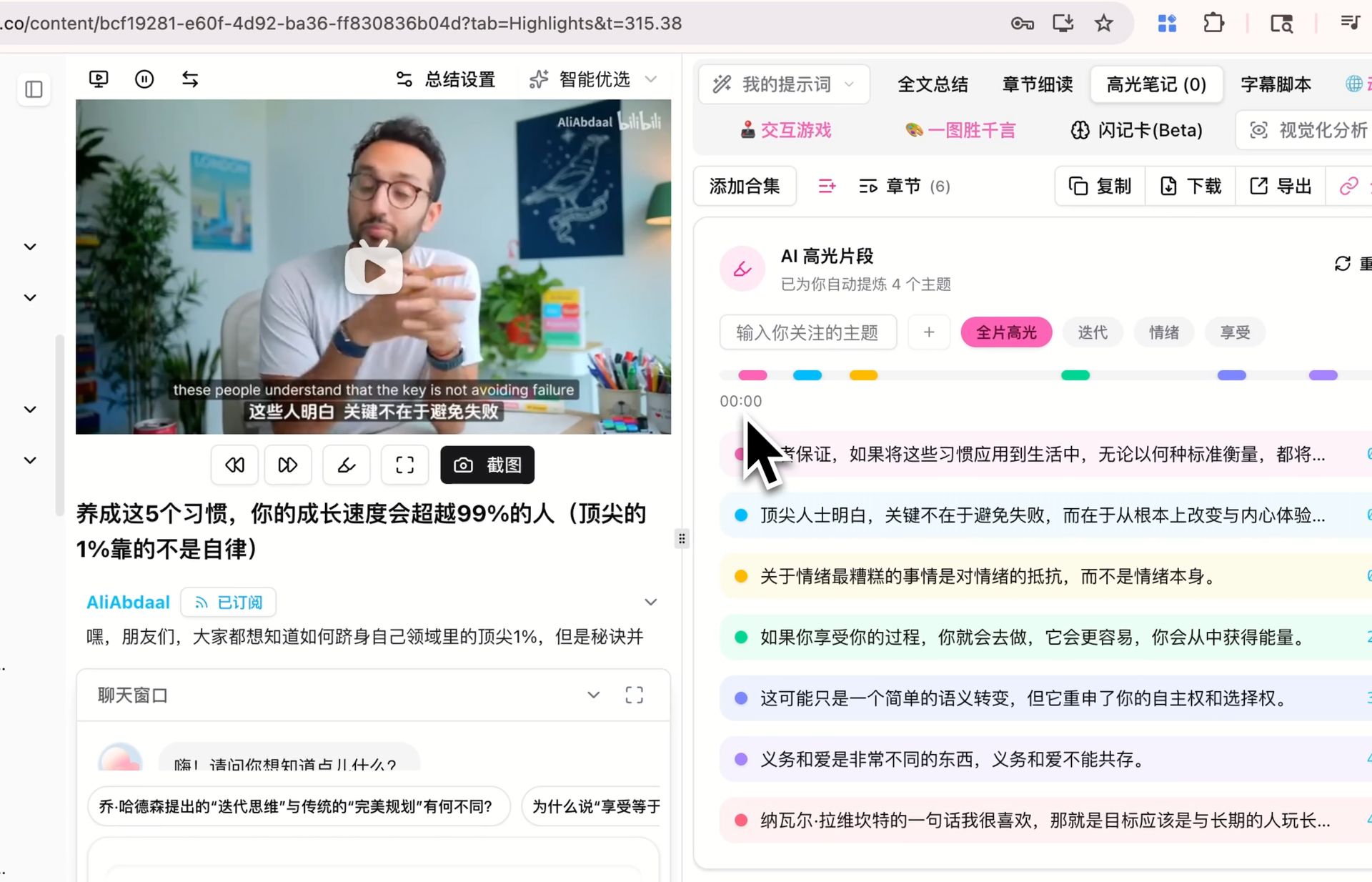
ทั้งสามเป็นสถานการณ์ที่เรากำลังประเมินอยู่ ผลลัพธ์แตกต่างกันตามเนื้อหา prompt และภาษา และมุมมองที่เชื่อถือได้ที่สุดคือมุมมองที่คุณสร้างขึ้นหลังจากรันไม่กี่ครั้งภายในเวิร์กโฟลว์ของคุณ
อีกสองสามพื้นที่ใช้โมเดลเฉพาะ การวิเคราะห์เนื้อหาภาพรันบนโมเดลภาพ และวิดีโอเป็นบทความประกอบภาพใช้ pipeline แบบคงที่ ดังนั้นมันไม่ตอบสนองต่อการสลับโมเดลเริ่มต้นและไม่เป็นส่วนหนึ่งของการเปรียบเทียบข้างต้น
BibiGPT ให้บริการ ผู้ใช้ 1M+ และสร้าง สรุป AI 5M+ ถึงปัจจุบัน ขนาดนั้นช่วยให้เราจับคู่โมเดลใหม่ทุกอันกับสถานการณ์โลกแห่งความเป็นจริงได้อย่างรวดเร็ว แทนที่จะอยู่ที่ชั้นการเปรียบเทียบเบนช์มาร์ก
ยุค AI: สิ่งที่ขาดแคลนไม่ใช่โมเดล แต่เป็นความเร็วในการบริโภคเนื้อหา
ในปี 2026 โมเดล AI เป็นเหมือนน้ำไหล DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 ทั้งหมดอยู่ในระยะเอื้อมถึง โมเดลไม่ขาดแคลนอีกต่อไป
อะไรขาดแคลน? ความเร็วที่คุณเปลี่ยนข้อมูลเป็นความคิดเห็น และความคิดเห็นเป็นการกระทำ
เสียงและวิดีโอเป็นรูปแบบที่ความหนาแน่นต่ำสุดและใช้เวลาบริโภคยาวสุดบนอินเทอร์เน็ต การสัมภาษณ์สองชั่วโมงถอดเสียงคือ 8,000 คำ แต่วิทยานิพนธ์จริงอาจเป็น 300 พอดแคสต์ซีซันยาว 30 ชั่วโมงให้คำพูดที่ทนทานบางที 20 อัน เป็นเวลาหลายปีที่กลเดียวคือเล่น 1.5x หรือ 2x แลกความสนใจกับความหนาแน่น ด้วยโมเดลล่าสุด คณิตศาสตร์พลิก:
- ไม่มีการฟังแบบ passive อีกต่อไป แค่ถามคำถามที่คุณสนใจ โมเดลดึงคำตอบจากสำเนาเสียง
- ไม่ต้องดูจบก่อนตัดสิน อ่านสรุปก่อน แล้วตัดสินใจว่าสมควรหนึ่งชั่วโมงหรือไม่
- ไม่มีการพลิกวิดีโอทีละอัน ค้นหาทั่วทั้งหมด “ใครในจำนวน 100 ครีเอเตอร์ที่ฉันติดตามได้พูดเรื่องนี้”
BibiGPT ทำสิ่งหนึ่ง: เสียบโมเดลที่ดีที่สุดที่มีเข้าไปในรูปแบบที่ใหญ่ที่สุดแต่บริโภคยากที่สุด เสียงและวิดีโอ เพื่อให้ใครก็บีบอัดวิดีโอสองชั่วโมงเป็นการอ่านความหนาแน่นสูง 15 นาที DeepSeek V4 เพิ่มตัวเลือกที่เชื่อถือได้อีกหนึ่งให้กับสแต็กนั้น
FAQ
Q1: ความแตกต่างระหว่าง DeepSeek V4 Pro และ V4 Pro Thinking คืออะไร?
ความแตกต่างหลักคือว่าการให้เหตุผลชัดเจนหรือไม่ Non-thinking มี latency ต่ำกว่าด้วยเอาต์พุตสั้นกว่า ดีสำหรับสรุปสะอาด โหมด Thinking สร้างห่วงโซ่การให้เหตุผลก่อน ดีกว่าสำหรับตรรกะหลายขั้น การเปรียบเทียบข้ามบท หรือการวิเคราะห์ข้อโต้แย้ง คุณปรับความลึกด้วย reasoning_effort=high/max การให้เหตุผลลึกขึ้น เอาต์พุตช้าลง
Q2: ฉันควรเลือก V4 Pro หรือ V4 Flash?
คิดในแง่ “ความยาว × ความซับซ้อนการให้เหตุผล” เกินหนึ่งชั่วโมงหรือการให้เหตุผลหลายขั้น → Pro ต่ำกว่าสามสิบนาทีและสรุปสะอาดพอ → Flash เมื่อสงสัย เริ่มต้นด้วย Flash และสลับเป็น Pro ถ้ามันไม่พอ BibiGPT แคชสำเนาเสียงดังนั้นการสรุปใหม่ข้ามขั้นตอนการถอดเสียงทั้งหมด
Q3: ทำไมต้องผ่าน BibiGPT แทนที่จะใช้เว็บไซต์ DeepSeek โดยตรง?
เว็บไซต์ DeepSeek เป็นกล่องแชททั่วไป คุณยังต้องดาวน์โหลด ถอดเสียง วาง และ prompt ด้วยตัวเอง BibiGPT จัดการ pipeline ต้นน้ำ (การ parsing ลิงก์ 30+ แพลตฟอร์ม การถอดเสียง การวิเคราะห์ภาพ การจัดเรียง timestamp) และ DeepSeek V4 ต้องครอบคลุมแค่ขั้นตอนเข้าใจและสร้างสุดท้าย อินพุตเดียวกัน และคุณยังได้มายด์แมป โน้ตไฮไลต์ บทความประกอบภาพ และการส่งออกที่มีโครงสร้างโดยไม่ต้องประกอบเพิ่มเติม
Q4: DeepSeek V4 จัดการวิดีโอยาวแค่ไหนได้?
V4 Pro และ Flash ทั้งคู่มี 1M token context ประมาณ 1.5 ล้านอักษรจีน หรือบทสนทนามากกว่า 20 ชั่วโมง พอสำหรับพอดแคสต์เต็มซีซัน BibiGPT ตัดสินใจอัตโนมัติระหว่างการสรุปแบบ single-pass และ chunk-then-consolidate ตาม context ที่มีประสิทธิภาพของโมเดล
Q5: น้ำหนัก DeepSeek V4 เปิดซอร์สหรือไม่?
เปิดซอร์สเต็มรูปแบบ น้ำหนักอยู่บน Hugging Face deepseek-ai/deepseek-v4 และ ModelScope รายงานเทคนิคอยู่ใน DeepSeek_V4.pdf นักวิจัยและผู้โฮสต์เองคว้าได้โดยตรง
ลอง V4 ตอนนี้
วิธีตรงที่สุดในการสัมผัส V4: เลือกวิดีโอยาวที่คุณตั้งใจจะดูจริง การบรรยาย ตอนพอดแคสต์ สารคดี อะไรก็ได้ และรันผ่าน DeepSeek V4 Pro Thinking ดูว่า V4 จัดการสิ่งที่คุณสนใจจริงอย่างไร
เริ่มต้นการเรียนรู้ AI อย่างมีประสิทธิภาพของคุณตอนนี้:
- 🌐 เว็บไซต์ทางการ: https://bibigpt.co/th/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 ดาวน์โหลด Mobile: https://aitodo.co/app
- 💻 ดาวน์โหลด Desktop: https://aitodo.co/download/desktop
- ✨ เรียนรู้ฟีเจอร์เพิ่มเติม: https://aitodo.co/features
BibiGPT Team