DeepSeek-V4 đã đến! BibiGPT ra mắt bốn mô hình mới + 1M context ngay ngày đầu — Tóm tắt video & podcast bằng AI vừa lên cấp
DeepSeek-V4 đã đến! BibiGPT ra mắt bốn mô hình mới + 1M context ngay ngày đầu — Tóm tắt video & podcast bằng AI vừa lên cấp
Hôm nay (24/04/2026) DeepSeek-V4 Preview chính thức ra mắt và mã nguồn mở hoàn toàn — 1M context giờ là mặc định, và năng lực agent đã thu hẹp khoảng cách với Sonnet 4.5. BibiGPT đã hoàn tất tích hợp ngay trong ngày, và DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash, và V4 Flash Thinking giờ có thể chọn trực tiếp trong trình chọn mô hình, sẵn sàng cho phim tài liệu dài kỳ, phỏng vấn hai giờ, hoặc cả mùa podcast.
Chúng tôi đã chạy các mô hình qua một vài bối cảnh thực tế ngay lập tức. Bài viết này là ghi chú hands-on chia sẻ cùng lúc, dành cho ai làm việc với cùng loại nội dung.
Mục lục
- Có gì mới trong DeepSeek-V4
- Bốn mô hình DeepSeek V4 giờ đã có trong BibiGPT
- Chuyển sang DeepSeek V4 trong ba bước
- Hands-on: tóm tắt video ra mắt của chính DeepSeek bằng V4 Pro
- Bối cảnh chuyển sang V4 áp dụng trực tiếp
- Kỷ nguyên AI: cái khan hiếm không phải mô hình, mà là tốc độ tiêu thụ nội dung
- FAQ
Có gì mới trong DeepSeek-V4
DeepSeek-V4 dịch chuyển ba núm quan trọng cùng lúc. Mỗi cái xứng đáng một ghi chú riêng.
Thứ nhất, 1M context trở thành mặc định trên toàn dịch vụ chính thức của DeepSeek. Cơ chế attention mới nén theo chiều token và kết hợp với DSA (DeepSeek Sparse Attention) để cắt giảm chi phí bộ nhớ và tính toán. Trên thực tế, đưa vào một giờ phụ đề không còn cần thao tác “chia nhỏ và ghép lại” — mô hình đọc nó như một khối liên tục.
Thứ hai, năng lực agent có một bước tiến rõ rệt. Theo đo lường của chính DeepSeek, V4-Pro dẫn đầu mọi mô hình mã nguồn mở về Agentic Coding và đạt chất lượng gần Opus 4.6 non-thinking; họ đã dùng nó làm mô hình lập trình mặc định nội bộ. Đối với người dùng hằng ngày, điều này chuyển thành cấu trúc hóa văn bản dài đáng tin cậy hơn — chia chương, trích điểm chính, sinh sơ đồ tư duy — với độ ổn định tốt hơn rõ rệt.
Thứ ba, Pro và Flash bổ sung cho nhau. Pro (1.6T params / 49B active / 33T tokens tiền huấn luyện) nhắm tới các mô hình closed-source hàng đầu; Flash (284B / 13B / 32T) là lựa chọn tiết kiệm chi phí. Cả hai hỗ trợ chế độ thinking và non-thinking, và chế độ thinking hỗ trợ điều chỉnh reasoning_effort. Flash cho tác vụ đơn giản, Pro cho tác vụ nặng — cả hai đều cảm giác chắc chắn.

Thông báo gốc (tiếng Trung) ở đây: DeepSeek-V4 Preview: the Million-Token Era Goes Mainstream. Trọng số mô hình có sẵn trên bộ sưu tập Hugging Face DeepSeek V4 (Pro / Pro-Base / Flash / Flash-Base, bốn repo); báo cáo kỹ thuật ở DeepSeek_V4.pdf.
Bốn mô hình DeepSeek V4 giờ đã có trong BibiGPT
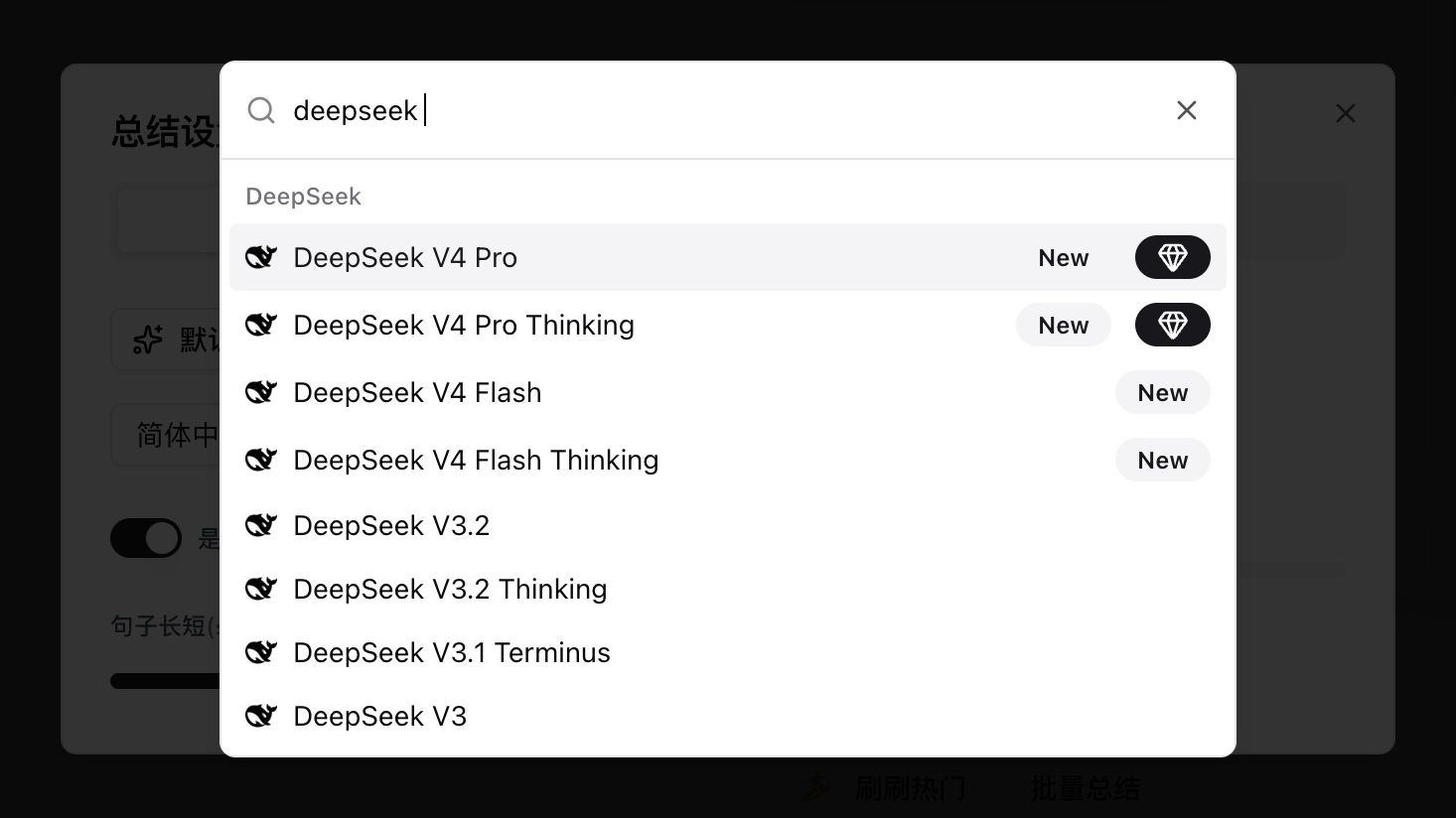
Mở bất kỳ cài đặt tóm tắt video hoặc audio nào, gõ deepseek trong trình chọn mô hình, và bạn sẽ thấy bốn mục mới được gắn nhãn New:
| Mô hình | Trường hợp sử dụng | Thinking |
|---|---|---|
| DeepSeek V4 Pro | Chất lượng đỉnh cho nội dung dài, nặng logic | Non-thinking |
| DeepSeek V4 Pro Thinking | V4 Pro với suy luận tường minh — agent và phân tích sâu | Thinking |
| DeepSeek V4 Flash | Tiết kiệm chi phí, tuyệt cho nội dung ngắn và thường ngày | Non-thinking |
| DeepSeek V4 Flash Thinking | Flash với suy luận, cân bằng tốc độ và độ sâu | Thinking |
Chọn cái nào? Một quy tắc quyết định đơn giản:
- Nội dung dài hơn (trên một giờ, cả mùa podcast, phỏng vấn dài) → Pro hoặc Pro Thinking để suy luận sâu hơn xuyên suốt cả tác phẩm
- Nội dung ngắn hơn (dưới 30 phút, cuộc họp, vlog hằng ngày) → Flash, nhanh hơn và tiết kiệm hơn
- Muốn mô hình suy luận từng bước, so sánh quan điểm, đào sâu hơn → chọn biến thể Thinking
- Chỉ cần tóm tắt sạch, không cần dấu vết suy luận → chọn biến thể non-thinking
Nếu bạn không muốn so sánh kỹ, hãy bắt đầu với V4 Pro Thinking — nó cho kết quả nhất quán trên hầu hết các bối cảnh nội dung dài.
Chuyển sang DeepSeek V4 trong ba bước
- Mở BibiGPT, dán một liên kết YouTube / podcast / tệp cục bộ vào hộp nhập
- Nhấp Default Model bên dưới hộp nhập, gõ
deepseektrong thanh tìm kiếm - Chọn bất kỳ trong bốn mục New và nhấn nút tóm tắt
Lựa chọn được lưu xuyên suốt các phiên. Người dùng nâng cao có thể ghim V4 Pro Thinking làm tóm tắt tùy chỉnh mặc định, để mọi video trong tương lai tự động chạy qua nó.
Muốn cảm nhận chất lượng tóm tắt của BibiGPT trước khi đổi mô hình? Thả bất kỳ liên kết nào vào widget bên dưới:
Hands-on: tóm tắt video ra mắt của chính DeepSeek bằng V4 Pro
Việc đầu tiên chúng tôi làm là chạy V4 Pro trên video ra mắt của chính DeepSeek. Nó dài khoảng một phút rưỡi, và với chế độ thinking bật, mô hình chia nó thành bảy chương có cấu trúc, mỗi chương có tóm tắt, điểm nhấn, suy ngẫm và đánh giá phản biện riêng.
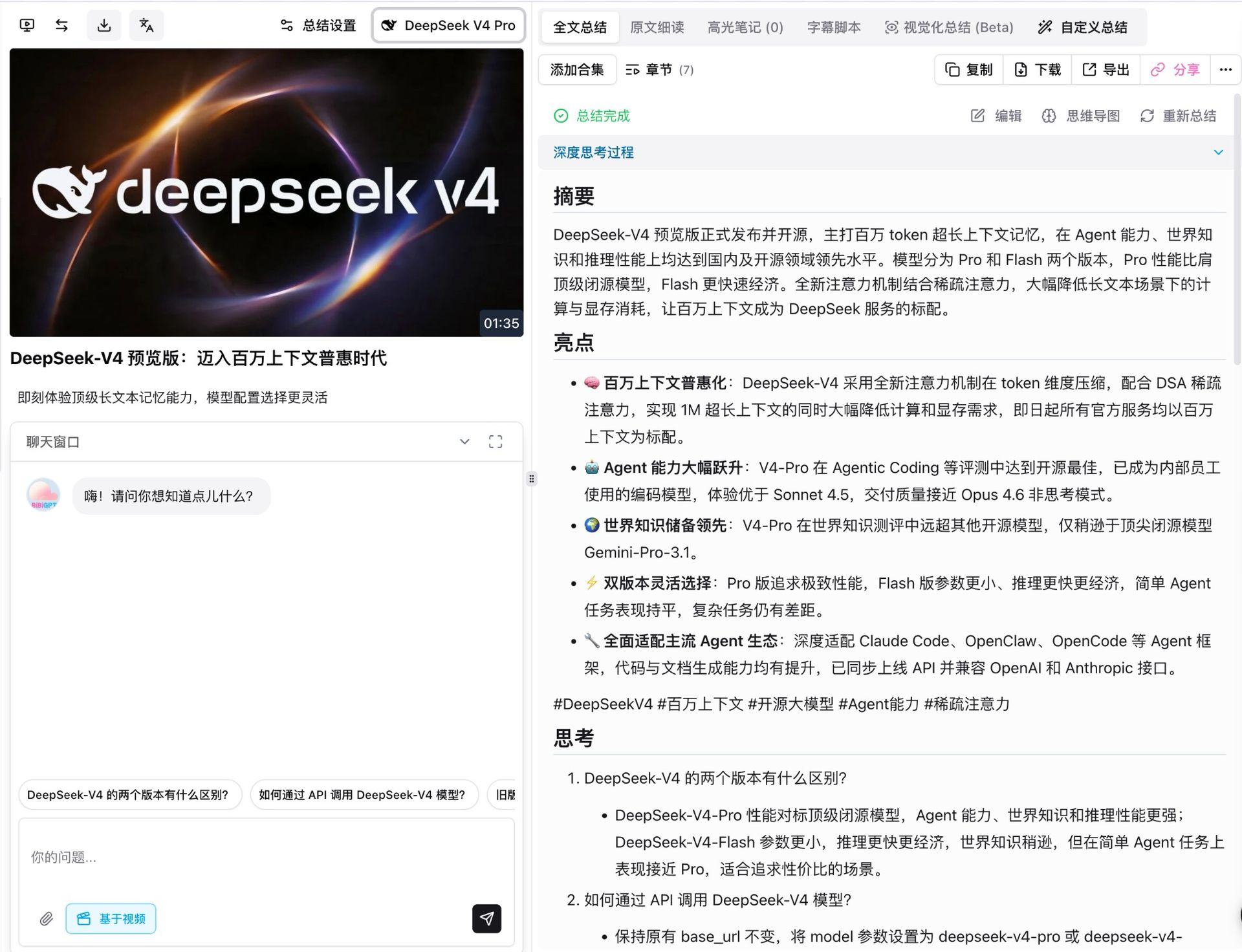
Một vài chi tiết đáng nêu:
- Bao phủ sự kiện đầy đủ: cả năm tuyên bố tiêu đề từ bản phát hành (1M context mặc định, bước nhảy agent, dẫn đầu kiến thức thế giới, linh hoạt hai cấp, tương thích hệ sinh thái agent) đều được truyền tải chính xác, bao gồm cả các con số tham số
- Mọi kết luận đều truy nguyên được: mỗi điểm liên kết ngược về một mốc thời gian video có thể nhấp, nhảy thẳng đến khoảnh khắc liên quan
- Câu hỏi tiếp theo xuất hiện tự động: dưới phần tóm tắt, mô hình đề xuất các phần mở rộng như “khác biệt giữa hai cấp V4 là gì” và “làm thế nào để gọi qua API,” sẵn sàng cho một lần đào sâu một chạm
Cải tiến ở đây chủ yếu đến từ suy luận sâu hơn của chế độ thinking. Long context đã là đường mặc định trên các mô hình lớn trong BibiGPT, và sự xuất hiện của V4 đưa tổ hợp “suy luận sâu + ổn định toàn phụ đề” vào tầng mã nguồn mở với chất lượng hạng nhất.
Bối cảnh chuyển sang V4 áp dụng trực tiếp
Mô hình mã nguồn mở liên tục ra mắt. Bạn có thể hỏi: chẳng phải tôi có thể dùng trang web DeepSeek hoặc API trực tiếp sao? Tại sao phải đi qua BibiGPT?
Tất cả phụ thuộc vào bối cảnh. Trang web DeepSeek là chatbox chung — bạn vẫn cần tải video xuống, chuyển giọng, dán, và tìm cách prompt. BibiGPT đã làm một việc trong nhiều năm: làm cho video và podcast dài dễ tiêu thụ như đọc một bài báo. V4 là năng lực mới nhất được thêm vào stack đó; cái thực sự khiến “dán liên kết, hiểu thật” hoạt động là tầng sản phẩm chúng tôi đã tinh chỉnh quanh mô hình.
Bên trong BibiGPT, các năng lực sau đây bám trực tiếp theo mô hình bạn chọn làm “Default Model” — nói cách khác, một khi bạn chuyển sang DeepSeek V4, các tính năng này đang chạy trên V4.
📝 Tóm tắt video (Mặc định + Custom Prompt)
Cái bạn dùng thường xuyên nhất — nhấn “Summarize” sau khi dán liên kết — chạy trên bất kỳ mô hình nào bạn đã chọn. Bất kỳ custom prompt nào đã lưu (như “Counterintuitive Analyst”, “Critical Thinking”, hoặc “Investment Analyst”) cũng đi qua cùng mô hình. Chuyển sang DeepSeek V4 Pro Thinking, chạy lại cùng video với cùng prompt, và bạn được so sánh trực tiếp side-by-side về độ sâu suy luận và cấu trúc. Đây là một trong các bối cảnh chúng tôi vẫn đang khám phá — chạy nó trên nội dung của chính bạn và xem kết quả có hợp với kỳ vọng hơn không.
🎯 AI Video Chat với truy nguyên nguồn
Cửa sổ chat bên dưới trang chi tiết video cũng theo mô hình mặc định. Mọi câu trả lời mang theo một mốc thời gian có thể nhấp — “anh ấy đã đưa ra quan điểm ngược lại lúc 1:12:30”, một chạm và bạn nhảy đến đó. Một khi đã chuyển sang V4, hãy chọn một cuộc phỏng vấn 1+ giờ và đặt vài vòng câu hỏi tiếp theo — đây là bối cảnh mà sự khác biệt giữa các mô hình thường lộ ra nhanh, và đáng chạy thử trực tiếp.
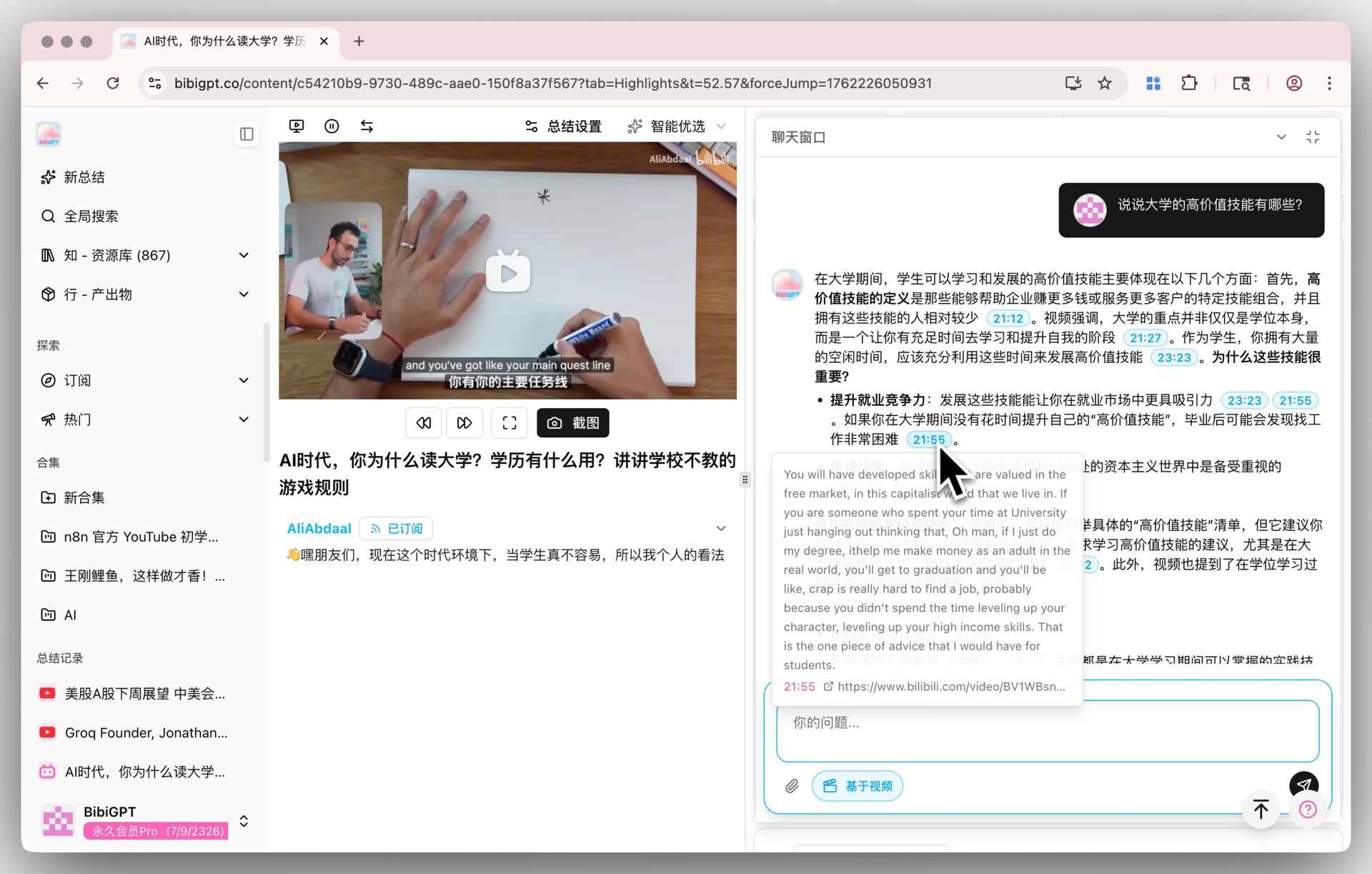
🔖 AI Highlight Notes
Trích các đoạn highlight từ video với mốc thời gian — nhóm theo chủ đề — cũng chạy trên mô hình mặc định. Nếu bạn đã sinh ghi chú highlight cho video nào đó trên mô hình khác, hãy chạy lại trên V4 và so sánh đoạn nào được đánh dấu là highlight và chủ đề được phân nhóm thế nào. Sự khác biệt có ý nghĩa hay không trên nội dung của bạn dễ phán đoán nhất bằng cách tự làm.
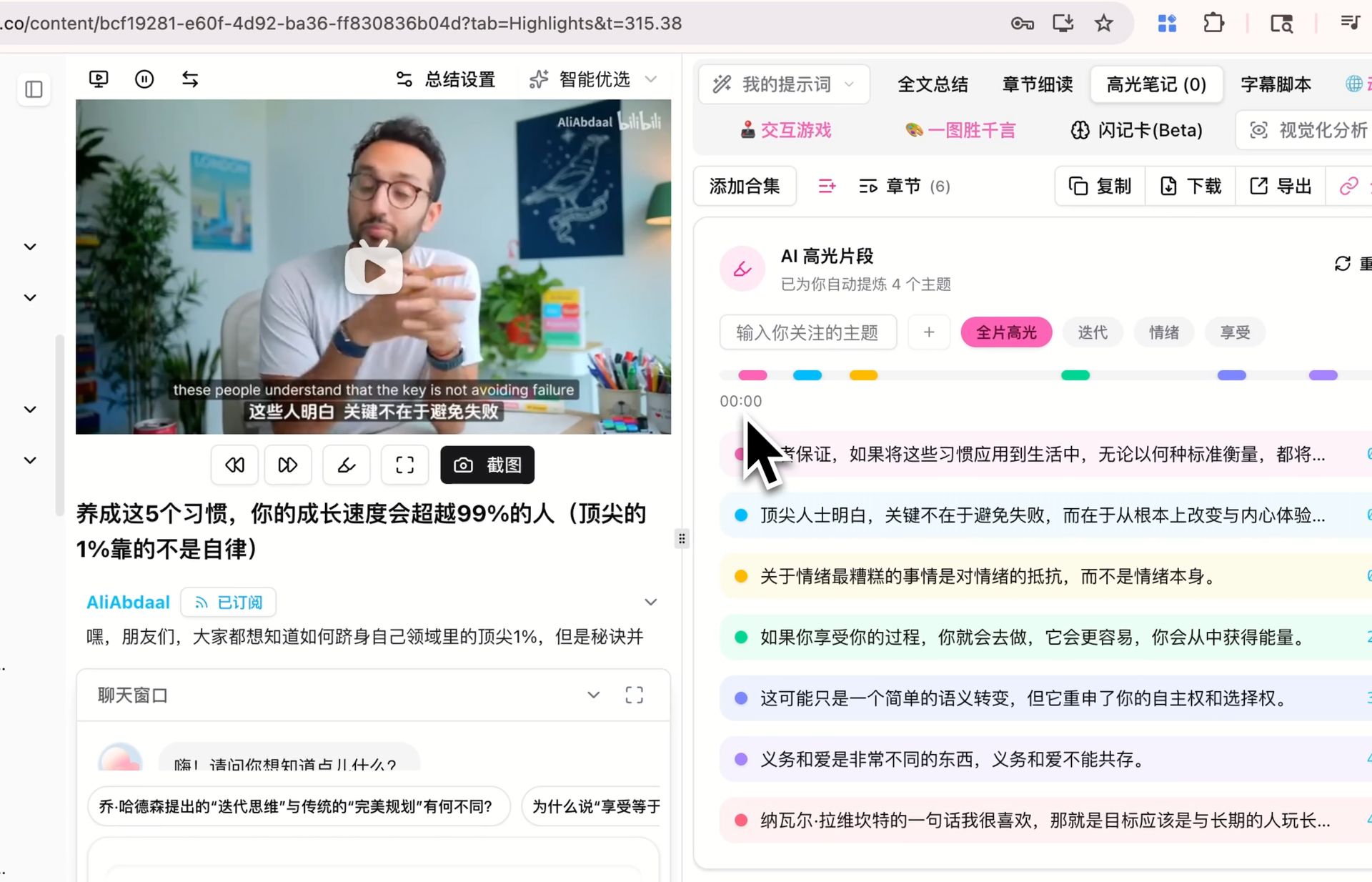
Cả ba đều là bối cảnh chúng tôi vẫn đang đánh giá — kết quả khác nhau qua các nội dung, prompt và ngôn ngữ khác nhau, và đánh giá đáng tin cậy nhất là cái bạn hình thành sau vài lần chạy bên trong quy trình của chính bạn.
Một vài lĩnh vực khác dùng mô hình chuyên biệt — phân tích nội dung trực quan chạy trên mô hình thị giác, và video-to-illustrated-article dùng pipeline cố định — nên chúng không phản ứng với chuyển đổi mô hình mặc định và không nằm trong so sánh trên.
BibiGPT đã phục vụ 1M+ người dùng và sinh ra 5M+ tóm tắt AI đến nay. Quy mô đó giúp chúng tôi ánh xạ mọi mô hình mới vào bối cảnh thực tế nhanh chóng, thay vì dừng lại ở tầng so sánh benchmark.
Kỷ nguyên AI: cái khan hiếm không phải mô hình, mà là tốc độ tiêu thụ nội dung
Năm 2026, mô hình AI về cơ bản như nước máy — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 đều trong tầm tay. Mô hình không còn khan hiếm.
Cái gì khan hiếm? Tốc độ bạn biến thông tin thành quan điểm, và quan điểm thành hành động.
Audio và video là định dạng mật độ thấp nhất, lâu tiêu thụ nhất trên internet. Một cuộc phỏng vấn hai giờ chuyển giọng ra 8.000 từ, nhưng luận điểm thực có thể chỉ 300. Một mùa podcast 30 giờ cho ra có lẽ 20 trích dẫn lâu bền. Trong nhiều năm thủ thuật duy nhất là phát 1.5x hoặc 2x — đánh đổi sự chú ý lấy mật độ. Với các mô hình mới nhất, bài toán đảo ngược:
- Không còn nghe thụ động, chỉ cần hỏi câu bạn quan tâm — mô hình kéo câu trả lời từ bản phụ đề
- Không cần xem hết trước khi phán đoán, đọc tóm tắt trước, rồi quyết định liệu nó có đáng một giờ
- Không còn lật từng video một, tìm kiếm xuyên tất cả — “trong số 100 creator tôi theo dõi, ai đã nói về chủ đề này”
BibiGPT làm một việc: gắn mô hình tốt nhất hiện có vào định dạng lớn nhất nhưng khó tiêu thụ nhất — audio và video — để bất kỳ ai cũng có thể nén hai giờ video thành mười lăm phút đọc mật độ cao. DeepSeek V4 thêm một tùy chọn đáng tin cậy nữa vào stack đó.
FAQ
Q1: Khác biệt giữa DeepSeek V4 Pro và V4 Pro Thinking là gì?
Khác biệt cốt lõi là liệu suy luận có tường minh không. Non-thinking có độ trễ thấp hơn với đầu ra ngắn hơn, tốt cho tóm tắt sạch. Chế độ Thinking sinh chuỗi suy luận trước — tốt hơn cho logic nhiều bước, so sánh đa chương, hoặc phân tích lập luận. Bạn có thể điều chỉnh độ sâu với reasoning_effort=high/max; suy luận sâu hơn, đầu ra chậm hơn.
Q2: Tôi nên chọn V4 Pro hay V4 Flash?
Suy nghĩ theo “độ dài × độ phức tạp suy luận.” Trên một giờ hoặc suy luận nhiều bước → Pro. Dưới ba mươi phút và tóm tắt sạch là đủ → Flash. Khi nghi ngờ, bắt đầu với Flash và chuyển sang Pro nếu nó không đủ — BibiGPT cache phụ đề nên tóm tắt lại bỏ qua bước chuyển giọng hoàn toàn.
Q3: Tại sao đi qua BibiGPT thay vì dùng trang web DeepSeek trực tiếp?
Trang web DeepSeek là chatbox chung — bạn vẫn cần tải xuống, chuyển giọng, dán, và prompt thủ công. BibiGPT xử lý pipeline thượng nguồn (parse liên kết 30+ nền tảng, chuyển giọng, phân tích trực quan, căn chỉnh mốc thời gian), và DeepSeek V4 chỉ cần phụ trách bước hiểu-và-sinh cuối cùng. Cùng đầu vào, và bạn còn được sơ đồ tư duy, ghi chú highlight, bài viết minh họa, và xuất khẩu có cấu trúc mà không cần lắp ráp thêm.
Q4: Video dài cỡ nào DeepSeek V4 có thể xử lý?
V4 Pro và Flash đều có 1M token context — tương đương khoảng 1,5 triệu ký tự tiếng Trung, hoặc trên 20 giờ đối thoại — đủ cho cả mùa podcast. BibiGPT tự động quyết định giữa tóm tắt một lượt và chia-rồi-hợp nhất dựa trên context hiệu dụng của mô hình.
Q5: Trọng số DeepSeek V4 có mã nguồn mở không?
Mã nguồn mở hoàn toàn. Trọng số trên Hugging Face deepseek-ai/deepseek-v4 và ModelScope; báo cáo kỹ thuật ở DeepSeek_V4.pdf. Nhà nghiên cứu và self-hoster có thể lấy trực tiếp.
Thử V4 ngay
Cách trực tiếp nhất để cảm nhận V4: chọn một video dài bạn đã muốn thực sự xem — một bài giảng, một tập podcast, một phim tài liệu, bất cứ gì — và chạy nó qua DeepSeek V4 Pro Thinking. Xem V4 xử lý cái bạn thực sự quan tâm như thế nào.
Bắt đầu hành trình học AI hiệu quả ngay bây giờ:
- 🌐 Trang web chính thức: https://bibigpt.co/vi/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 Tải ứng dụng di động: https://aitodo.co/app
- 💻 Tải bản desktop: https://aitodo.co/download/desktop
- ✨ Khám phá thêm tính năng: https://aitodo.co/features
BibiGPT Team