DeepSeek-V4 здесь! BibiGPT в день релиза подключил 4 новые модели + 1M контекста — ИИ-краткое содержание видео и подкастов вышло на новый уровень
DeepSeek-V4 здесь! BibiGPT в день релиза подключил 4 новые модели + 1M контекста — ИИ-краткое содержание видео и подкастов вышло на новый уровень
Сегодня (24 апреля 2026) DeepSeek-V4 Preview официально запущен и полностью открыт — 1M контекста теперь по умолчанию, а агентские возможности сократили разрыв с Sonnet 4.5. BibiGPT завершил интеграцию в тот же день, и DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash и V4 Flash Thinking теперь выбираются прямо в селекторе моделей — готовы для полнометражного документального фильма, двухчасового интервью или целого сезона подкаста.
Мы сразу прогнали модели через несколько реальных сценариев. Эта статья — практический разбор, опубликованный одновременно с релизом, для всех, кто работает с подобным контентом.
Содержание
- Что нового в DeepSeek-V4
- Четыре модели DeepSeek V4, теперь живущие в BibiGPT
- Переход на DeepSeek V4 в три шага
- Практика: суммаризация собственного релизного видео DeepSeek через V4 Pro
- Сценарии, где переключение на V4 применимо напрямую
- Эра ИИ: дефицит — не модели, а скорость потребления контента
- FAQ
Что нового в DeepSeek-V4
DeepSeek-V4 крутит сразу три ключевых регулятора. Каждый заслуживает отдельной заметки.
Во-первых, 1M контекста становится умолчанием по всем официальным сервисам DeepSeek. Новый механизм внимания сжимает по измерению токенов и сочетается с DSA (DeepSeek Sparse Attention), снижая стоимость памяти и вычислений. На практике подача часа субтитров больше не требует рутины «нарезать-сшить» — модель читает это как одно непрерывное тело.
Во-вторых, агентские возможности заметно подросли. По собственным измерениям DeepSeek, V4-Pro лидирует среди всех open-source моделей на Agentic Coding и обеспечивает качество, близкое к Opus 4.6 без режима мышления; они уже используют его как основную внутреннюю модель для кодинга. Для повседневных пользователей это переводится в более надёжную структуризацию длинного текста — разбивка на главы, извлечение ключевых тезисов, генерация интеллект-карт — с заметно лучшей стабильностью.
В-третьих, Pro и Flash дополняют друг друга. Pro (1.6T параметров / 49B активных / 33T токенов предобучения) нацелен на топовые закрытые модели; Flash (284B / 13B / 32T) — экономичный вариант. Оба поддерживают режимы мышления и без него, причём режим мышления поддерживает настройку reasoning_effort. Flash для простых задач, Pro для тяжёлых — оба ощущаются солидно.

Оригинальный анонс (на китайском) здесь: DeepSeek-V4 Preview: эра миллиона токенов выходит в мейнстрим. Веса моделей доступны в коллекции Hugging Face DeepSeek V4 (Pro / Pro-Base / Flash / Flash-Base, четыре репозитория); технический отчёт — в DeepSeek_V4.pdf.
Четыре модели DeepSeek V4, теперь живущие в BibiGPT
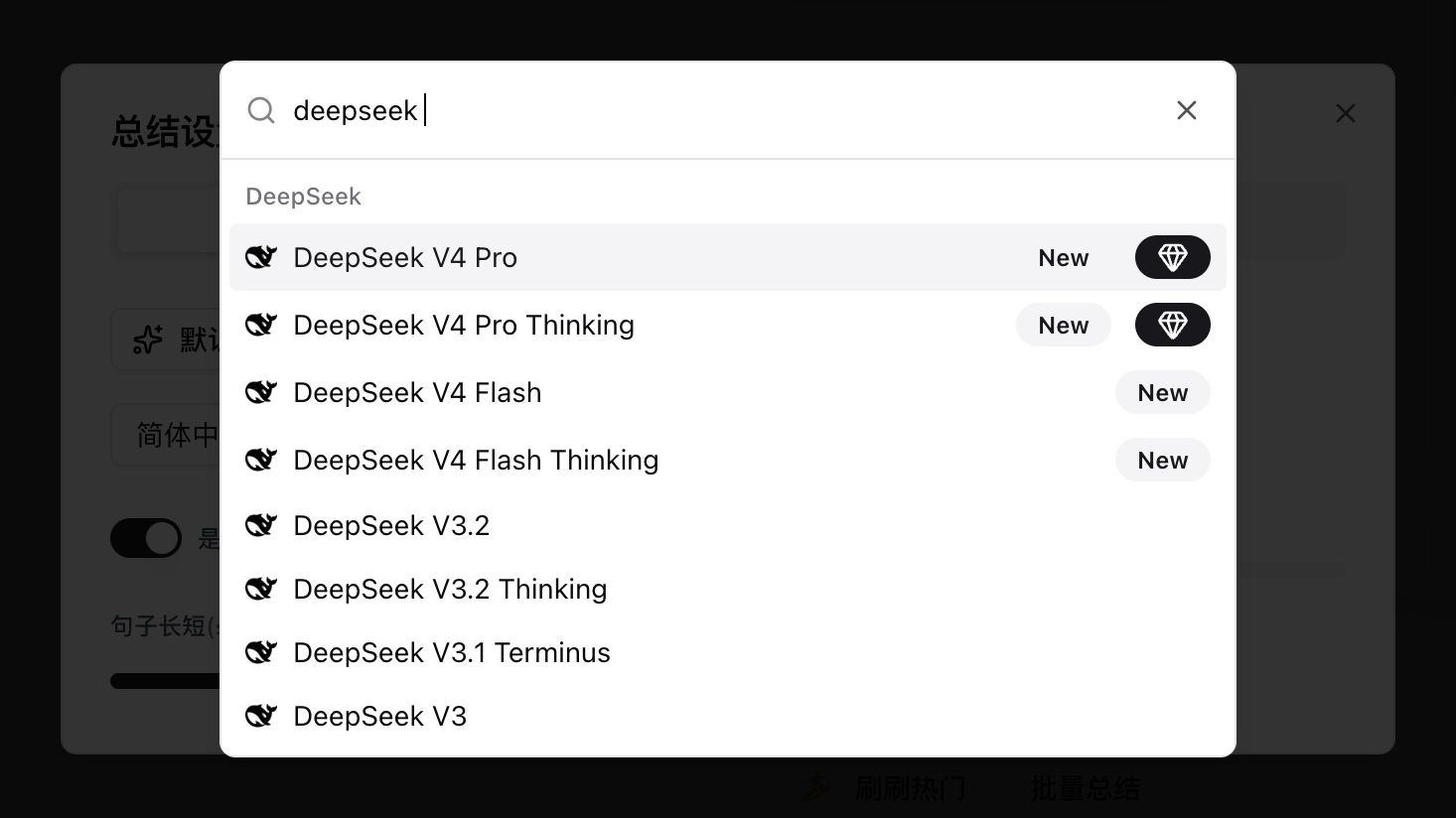
Откройте настройки любого видео- или аудио-краткого содержания, наберите deepseek в селекторе моделей — и увидите четыре новые записи с тегом New:
| Модель | Сценарий | Мышление |
|---|---|---|
| DeepSeek V4 Pro | Топовое качество для длинного, логически насыщенного контента | Без мышления |
| DeepSeek V4 Pro Thinking | V4 Pro с явным рассуждением — агент и глубокий анализ | Мышление |
| DeepSeek V4 Flash | Экономично, отлично для коротких и неформальных материалов | Без мышления |
| DeepSeek V4 Flash Thinking | Flash с рассуждением, баланс скорости и глубины | Мышление |
Какую выбрать? Простое решающее правило:
- Длинный контент (свыше часа, целые сезоны подкастов, длинные интервью) → Pro или Pro Thinking для более глубокого рассуждения по всему материалу
- Короткий контент (менее 30 минут, встречи, ежедневные влоги) → Flash, быстрее и экономичнее
- Хотите, чтобы модель рассуждала пошагово, сравнивала точки зрения, копала глубже — выбирайте вариант Thinking
- Нужен только чистый пересказ без следа рассуждений — выбирайте вариант без мышления
Если не хочется придирчиво сравнивать, начните с V4 Pro Thinking — он даёт стабильный результат в большинстве сценариев длинного контента.
Переход на DeepSeek V4 в три шага
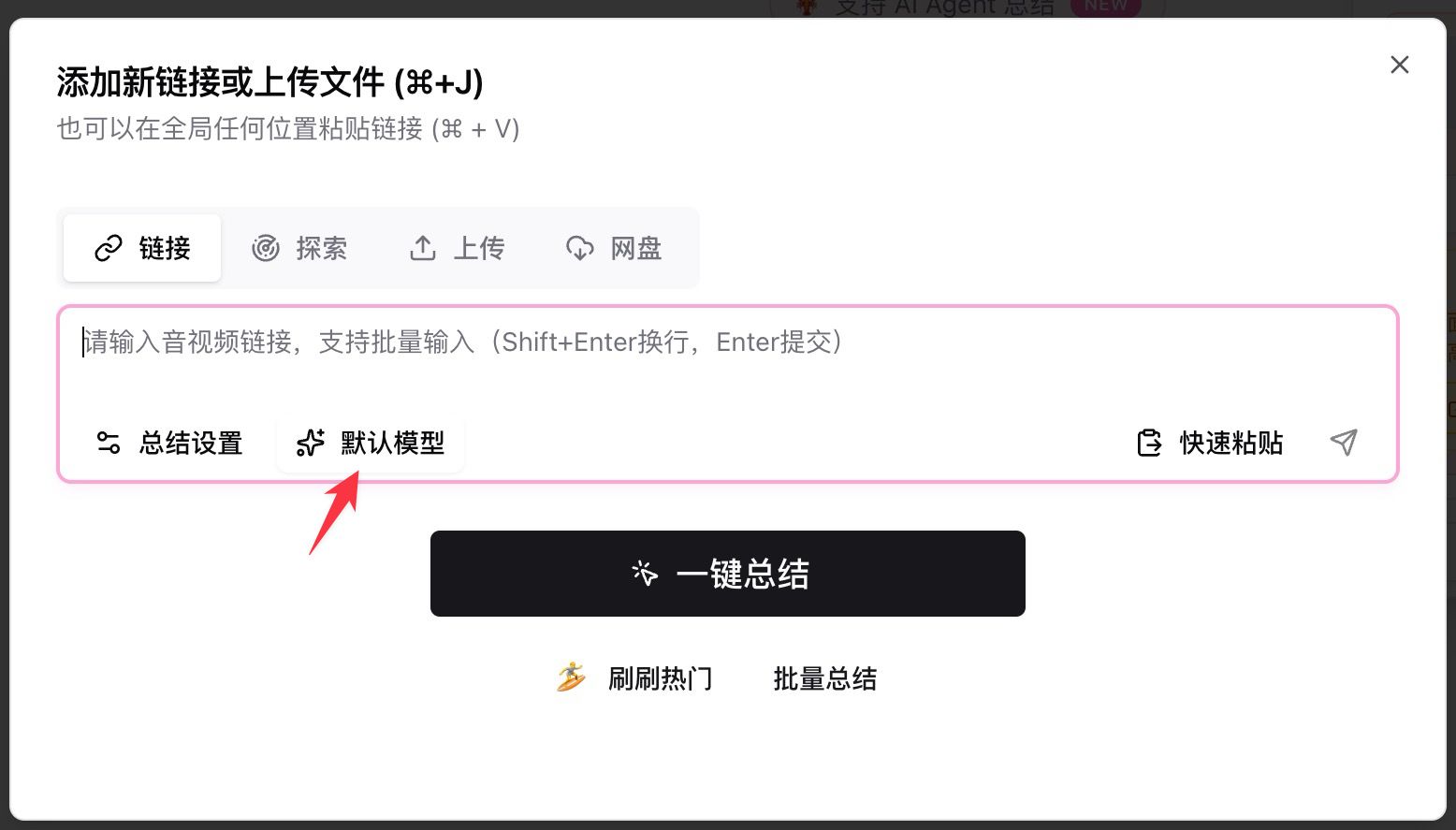
- Откройте BibiGPT, вставьте ссылку на YouTube / подкаст / локальный файл в поле ввода
- Нажмите Default Model под полем ввода, наберите
deepseekв строке поиска - Выберите любую из четырёх записей New и нажмите кнопку суммаризации
Выбор сохраняется между сессиями. Опытные пользователи могут закрепить V4 Pro Thinking как кастомное краткое содержание по умолчанию, чтобы каждое будущее видео автоматически прогонялось через него.
Хотите ощутить качество суммаризации BibiGPT до смены моделей? Бросьте любую ссылку в виджет ниже:
Практика: суммаризация собственного релизного видео DeepSeek через V4 Pro
Первое, что мы сделали — прогнали V4 Pro по собственному релизному видео DeepSeek. Длится оно около полутора минут, и с включённым режимом мышления модель разбила его на семь структурированных глав, у каждой — своё краткое содержание, выделения, рефлексия и критический разбор.
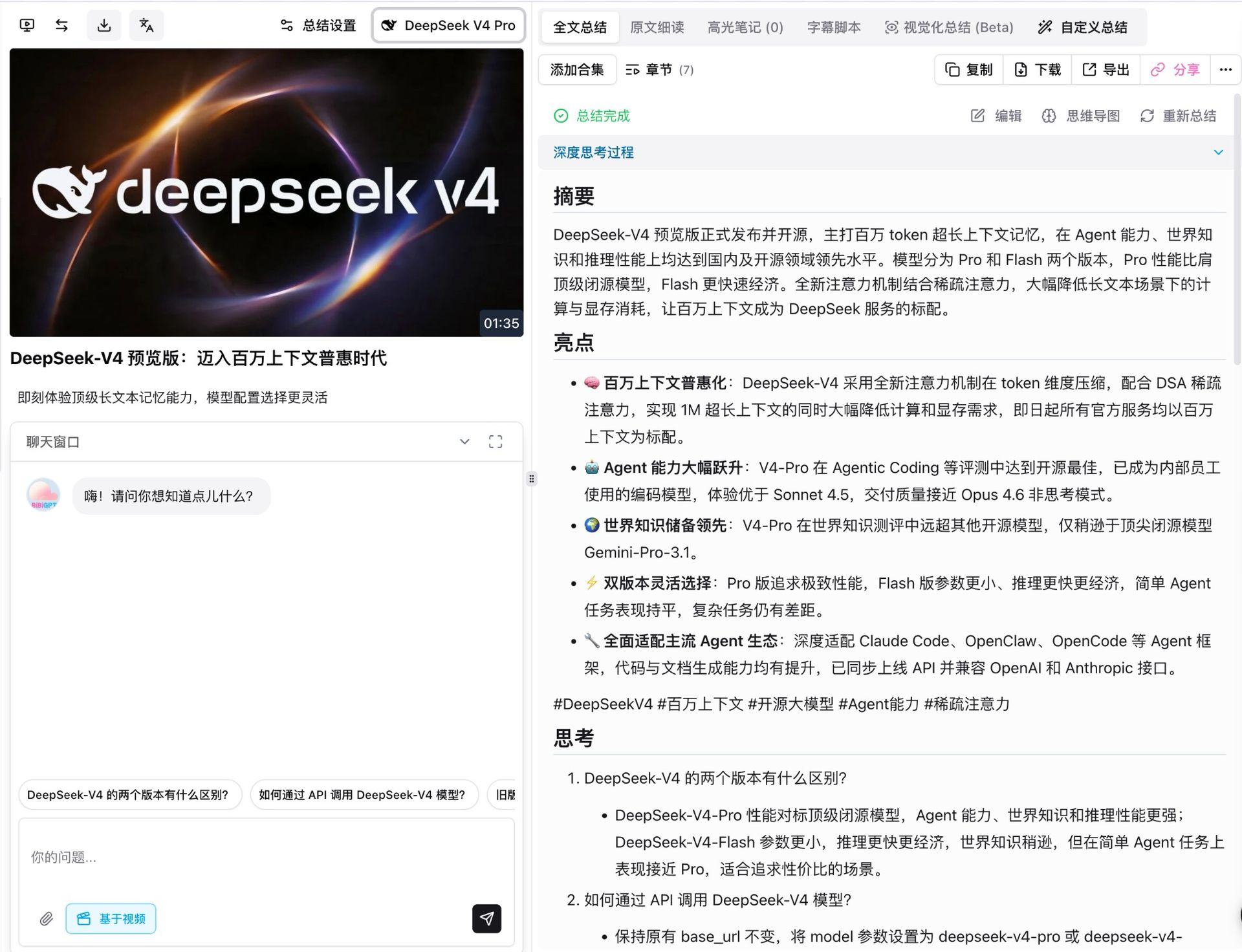
Несколько деталей, на которые стоит обратить внимание:
- Полное покрытие фактов: все пять заглавных тезисов релиза (1M контекста по умолчанию, скачок агентских возможностей, лидерство по знаниям о мире, двухуровневая гибкость, совместимость с агент-экосистемой) переданы точно, включая числа параметров
- Каждый вывод прослеживается: каждый пункт ведёт к кликабельному таймкоду видео, переходящему сразу к нужному моменту
- Уточняющие вопросы появляются автоматически: под кратким содержанием модель предлагает расширения вроде «в чём разница между двумя уровнями V4» и «как вызвать их через API», готовые для глубокого погружения в один тап
Улучшение здесь в основном идёт от более глубокого рассуждения в режиме мышления. Длинный контекст уже стал умолчанием по основным моделям в BibiGPT, и приход V4 переносит это сочетание «глубокое рассуждение + стабильность по полному транскрипту» в open-source-уровень с первоклассным качеством.
Сценарии, где переключение на V4 применимо напрямую
Open-source модели продолжают выходить. Можно спросить: разве я не могу просто использовать сайт DeepSeek или API напрямую? Зачем идти через BibiGPT?
Всё сводится к сценарию. Сайт DeepSeek — универсальный чат-бокс — Вам всё равно нужно скачать видео, транскрибировать, вставить и придумать, как промптить. BibiGPT уже годами делает одну вещь: превращает длинные видео и подкасты в нечто такое же удобное для потребления, как чтение статьи. V4 — новейшая возможность, добавленная в этот стек; то, что реально заставляет «вставил ссылку — получил настоящее понимание» работать, — это продуктовый слой, который мы дорабатываем вокруг модели.
Внутри BibiGPT следующие возможности напрямую следуют за моделью, выбранной как «Default Model» — иначе говоря, как только Вы переключитесь на DeepSeek V4, эти функции начнут работать на V4.
📝 Краткое содержание видео (по умолчанию + кастомный промпт)
То, чем Вы пользуетесь чаще всего — нажатие «Summarize» после вставки ссылки — работает на той модели, которую Вы выбрали. Любые сохранённые кастомные промпты (вроде «Контринтуитивный аналитик», «Критическое мышление» или «Инвестиционный аналитик») идут через ту же модель. Переключитесь на DeepSeek V4 Pro Thinking, перезапустите то же видео с тем же промптом — и получите прямое сравнение по глубине рассуждения и структуре. Это один из сценариев, которые мы сами всё ещё исследуем — прогоните на собственном контенте и посмотрите, лучше ли результат соответствует Вашим ожиданиям.
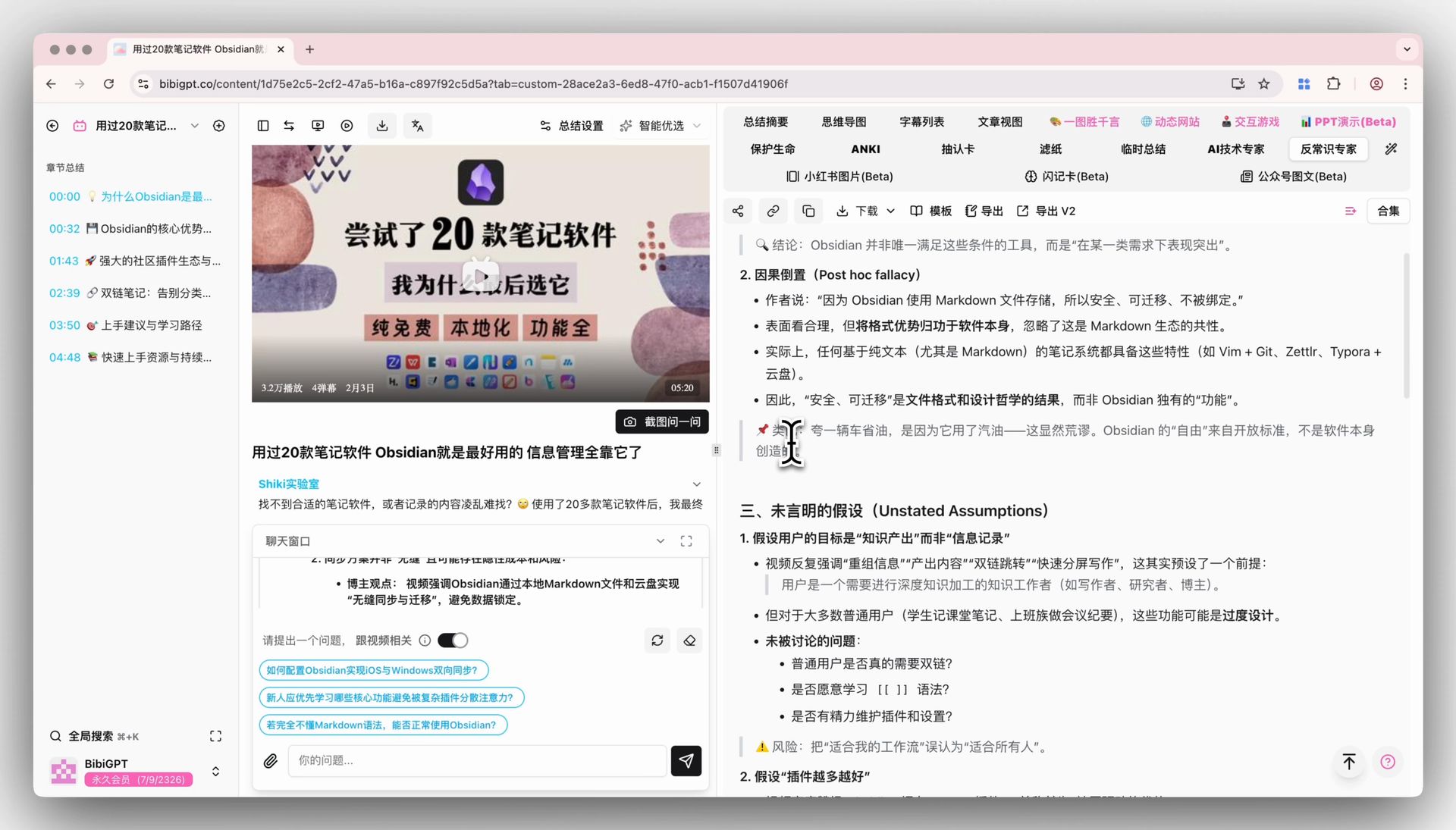
🎯 ИИ-чат с видео и прослеживанием источника
Окно чата под детальной страницей видео тоже следует за моделью по умолчанию. Каждый ответ несёт кликабельный таймкод — «он высказал противоположную точку зрения в 1:12:30», один тап и Вы там. После переключения на V4 возьмите интервью часом и более и задайте несколько раундов уточняющих вопросов — это сценарий, где различия между моделями обычно проявляются быстро, и его стоит прогнать самому.
🔖 ИИ-заметки с выделениями
Извлечение ярких фрагментов видео с таймкодами — сгруппированных по темам — тоже работает на модели по умолчанию. Если Вы уже сгенерировали заметки с выделениями для какого-то видео на другой модели, перезапустите их на V4 и сравните, какие фрагменты помечаются как ключевые и как кластеризуются темы. Является ли разница значимой на Вашем контенте — проще всего решить, попробовав самому.
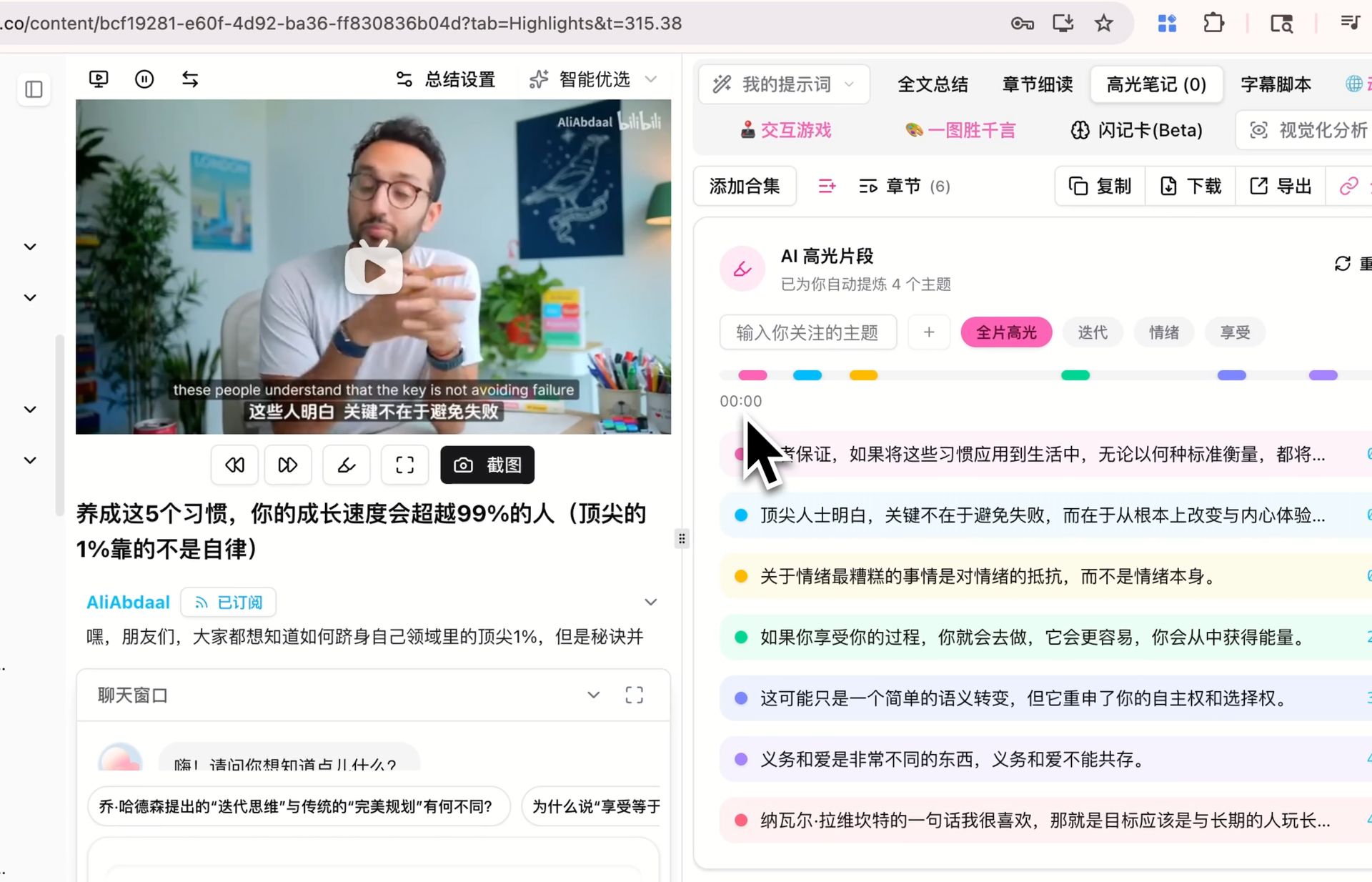
Все три — сценарии, которые мы сами всё ещё оцениваем; результаты варьируются между разным контентом, промптами и языками, и самое надёжное мнение — то, которое Вы сформируете после нескольких прогонов внутри собственного рабочего процесса.
Несколько других областей используют выделенные модели — анализ визуального контента работает на vision-модели, а видео-в-иллюстрированную-статью использует фиксированный пайплайн — поэтому они не реагируют на переключение модели по умолчанию и не входят в сравнение выше.
BibiGPT обслужил более 1 миллиона пользователей и сгенерировал более 5 миллионов ИИ-кратких содержаний к настоящему моменту. Этот масштаб помогает нам быстро отображать каждую новую модель на реальные сценарии, не оставаясь на уровне сравнения бенчмарков.
Эра ИИ: дефицит — не модели, а скорость потребления контента
В 2026 году ИИ-модели по сути как водопроводная вода — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 все в досягаемости. Модели больше не дефицит.
Что в дефиците? Скорость, с которой Вы превращаете информацию в мнения, а мнения — в действия.
Аудио и видео — самый низкоплотный, самый долгий по потреблению формат в интернете. Двухчасовое интервью в транскрипте — 8 000 слов, но реальный тезис может уместиться в 300. Сезон подкаста на 30 часов даёт, может быть, 20 устойчивых цитат. Годами единственный трюк состоял в воспроизведении на 1.5x или 2x — обмен внимания на плотность. С новейшими моделями математика переворачивается:
- Никакого пассивного слушания, просто задавайте вопросы, которые Вас волнуют — модель вытащит ответы из транскрипта
- Не нужно досматривать до конца, чтобы судить, сначала прочтите краткое содержание, потом решайте, заслуживает ли это часа
- Никакого пролистывания одного видео за раз, ищите по всем сразу — «кто из 100 авторов, на которых я подписан, говорил на эту тему»
BibiGPT делает одну вещь: подключает лучшие доступные модели к самому большому, но самому трудному для потребления формату — аудио и видео — чтобы любой мог сжать два часа видео в пятнадцать минут плотного чтения. DeepSeek V4 добавляет в этот стек ещё один надёжный вариант.
FAQ
Q1: В чём разница между DeepSeek V4 Pro и V4 Pro Thinking?
Основная разница — явность рассуждения. Без мышления — ниже задержка и короче вывод, хорошо для чистого краткого содержания. Режим мышления сначала генерирует цепочку рассуждений — лучше для многошаговой логики, межглавного сравнения или анализа аргументов. Глубину можно настроить через reasoning_effort=high/max; глубже рассуждение, медленнее вывод.
Q2: Выбрать V4 Pro или V4 Flash?
Думайте в терминах «длина × сложность рассуждения». Свыше часа или многошаговое рассуждение → Pro. До тридцати минут и достаточно чистого краткого содержания → Flash. Если сомневаетесь, начните с Flash и переключитесь на Pro, если не хватает — BibiGPT кэширует транскрипт, поэтому повторная суммаризация полностью пропускает шаг транскрипции.
Q3: Зачем идти через BibiGPT, а не использовать сайт DeepSeek напрямую?
Сайт DeepSeek — универсальный чат-бокс, Вам всё равно нужно скачать, транскрибировать, вставить и промптить. BibiGPT обрабатывает upstream-пайплайн (парсинг ссылок 30+ платформ, транскрипция, визуальный анализ, выравнивание таймкодов), а DeepSeek V4 нужно покрыть только финальный шаг понимания и генерации. Тот же ввод — и дополнительно интеллект-карты, заметки с выделениями, иллюстрированные статьи и структурированные экспорты без какой-либо дополнительной сборки.
Q4: Какой длины видео может обработать DeepSeek V4?
V4 Pro и Flash оба имеют контекст 1M токенов — примерно 1.5 миллиона китайских иероглифов или более 20 часов диалога — достаточно для целого сезона подкаста. BibiGPT автоматически решает между однопроходной суммаризацией и нарезкой-с-консолидацией, исходя из эффективного контекста модели.
Q5: Открыт ли исходный код весов DeepSeek V4?
Полностью открыт. Веса на Hugging Face deepseek-ai/deepseek-v4 и ModelScope; технический отчёт — в DeepSeek_V4.pdf. Исследователи и self-hoster могут забрать их напрямую.
Попробуйте V4 сейчас
Самый прямой способ ощутить V4: возьмите длинное видео, которое Вы давно собирались действительно посмотреть — лекцию, эпизод подкаста, документальный фильм, что угодно — и прогоните его через DeepSeek V4 Pro Thinking. Посмотрите, как V4 справляется с тем, что Вас на самом деле волнует.
Начните путь эффективного обучения с ИИ прямо сейчас:
- 🌐 Официальный сайт: https://bibigpt.co/ru/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 Скачать на мобильное: https://aitodo.co/app
- 💻 Скачать на десктоп: https://aitodo.co/download/desktop
- ✨ Узнать больше функций: https://aitodo.co/features
BibiGPT Team