DeepSeek-V4 Is Here! BibiGPT Ships Four New Models + 1M Context on Day One — AI Video & Podcast Summarizing Just Leveled Up
DeepSeek-V4 Is Here! BibiGPT Ships Four New Models + 1M Context on Day One — AI Video & Podcast Summarizing Just Leveled Up
Today (April 24, 2026) DeepSeek-V4 Preview officially launched and went fully open-source — 1M context is now the default, and agent capability has closed the gap with Sonnet 4.5. BibiGPT has completed same-day integration, and DeepSeek V4 Pro, V4 Pro Thinking, V4 Flash, and V4 Flash Thinking are now selectable directly in the model picker, ready for a full-length documentary, a two-hour interview, or an entire podcast season.
We ran the models through a few real scenarios right away. This post is a hands-on note shared at the same time, for anyone working with the same kind of content.
Table of Contents
- What’s new in DeepSeek-V4
- The four DeepSeek V4 models now live in BibiGPT
- Switch to DeepSeek V4 in three steps
- Hands-on: summarizing DeepSeek’s own launch video with V4 Pro
- Scenarios where switching to V4 applies directly
- The AI era: what is scarce is not models, but how fast you consume content
- FAQ
What’s new in DeepSeek-V4
DeepSeek-V4 moves three key dials at once. Each deserves a separate note.
First, 1M context becomes the default across DeepSeek’s official services. The new attention mechanism compresses along the token dimension and combines with DSA (DeepSeek Sparse Attention) to cut memory and compute cost. In practical terms, feeding in an hour of subtitles no longer requires the “chunk-and-stitch” routine — the model reads it as one continuous body.
Second, agent capability takes a clear step up. By DeepSeek’s own measurement, V4-Pro leads all open-source models on Agentic Coding and delivers quality close to Opus 4.6 non-thinking; they already use it as the default internal coding model. For everyday users, this translates into more reliable long-text structuring — chaptering, key-point extraction, mindmap generation — with noticeably better stability.
Third, Pro and Flash complement each other. Pro (1.6T params / 49B active / 33T pre-training tokens) targets top closed-source models; Flash (284B / 13B / 32T) is the cost-efficient option. Both support thinking and non-thinking modes, and thinking mode supports reasoning_effort tuning. Flash for simple tasks, Pro for heavy ones — both feel solid.

The original announcement (in Chinese) is here: DeepSeek-V4 Preview: the Million-Token Era Goes Mainstream. Model weights are available on the Hugging Face DeepSeek V4 collection (Pro / Pro-Base / Flash / Flash-Base, four repos); the technical report is in DeepSeek_V4.pdf.
The four DeepSeek V4 models now live in BibiGPT
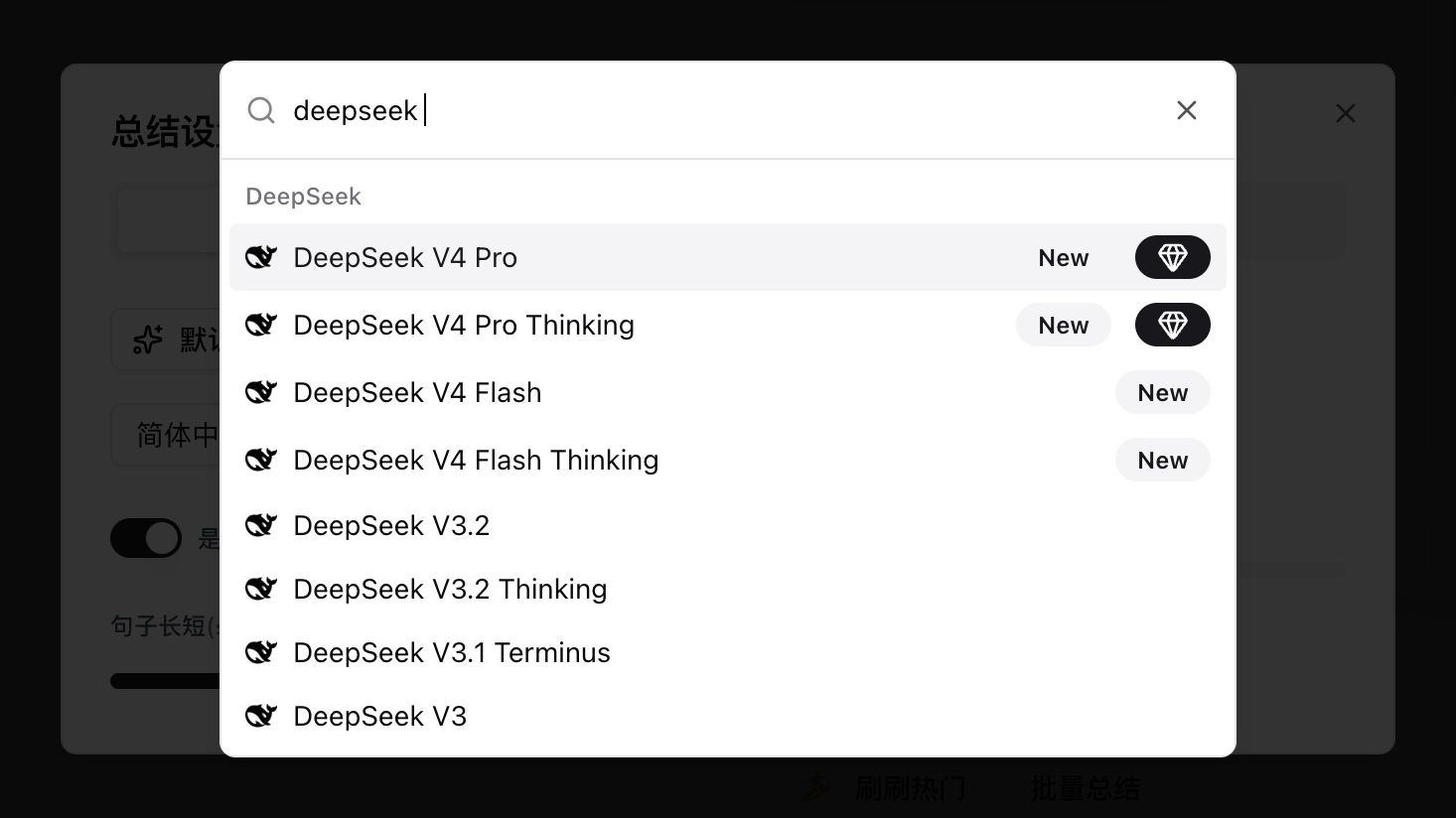
Open any video or audio summary settings, type deepseek in the model picker, and you will see four new entries tagged New:
| Model | Use case | Thinking |
|---|---|---|
| DeepSeek V4 Pro | Top-tier quality for long, logic-heavy content | Non-thinking |
| DeepSeek V4 Pro Thinking | V4 Pro with explicit reasoning — agent and deep analysis | Thinking |
| DeepSeek V4 Flash | Cost-efficient, great for short and casual content | Non-thinking |
| DeepSeek V4 Flash Thinking | Flash with reasoning, balancing speed and depth | Thinking |
Which one to pick? A simple decision rule:
- Longer content (over an hour, full podcast seasons, long interviews) → Pro or Pro Thinking for deeper reasoning across the whole piece
- Shorter content (under 30 minutes, meetings, daily vlogs) → Flash, faster and more economical
- Want the model to reason step by step, compare viewpoints, go deeper → pick a Thinking variant
- Just need a clean summary, no reasoning trace → pick a non-thinking variant
If you don’t want to compare carefully, start with V4 Pro Thinking — it delivers consistent results across most long-content scenarios.
Switch to DeepSeek V4 in three steps
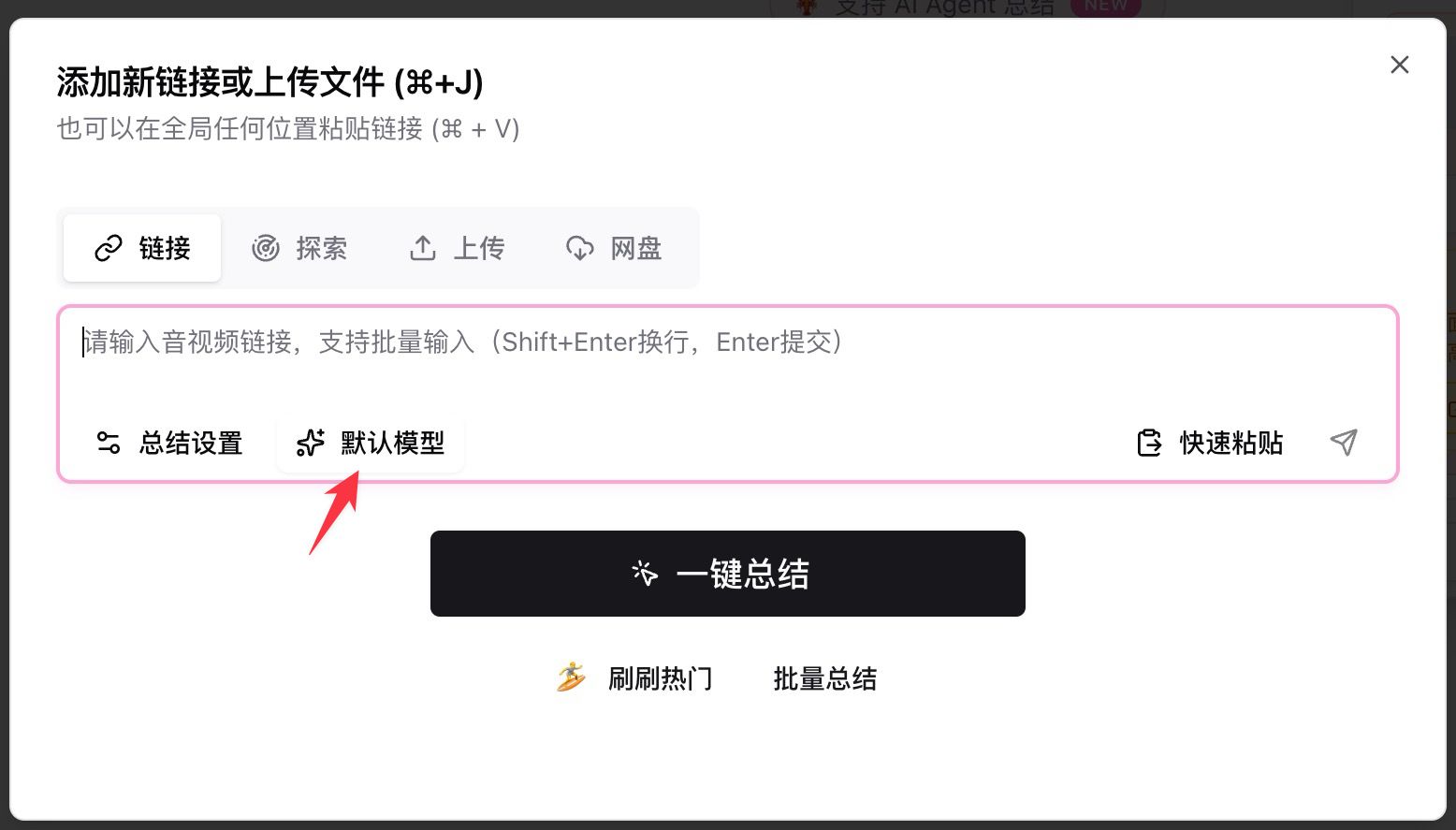
- Open BibiGPT, paste a YouTube / podcast / local file link into the input box
- Click Default Model below the input, type
deepseekin the search bar - Pick any of the four New entries and hit the summarize button
The selection persists across sessions. Power users can pin V4 Pro Thinking as the default custom summary, so every future video runs through it automatically.
Want to feel BibiGPT’s summary quality before changing models? Drop any link into the widget below:
Hands-on: summarizing DeepSeek’s own launch video with V4 Pro
The first thing we did was run V4 Pro on DeepSeek’s own launch video. It is about a minute and a half, and with thinking mode on, the model split it into seven structured chapters, each with its own summary, highlights, reflection, and critical review.
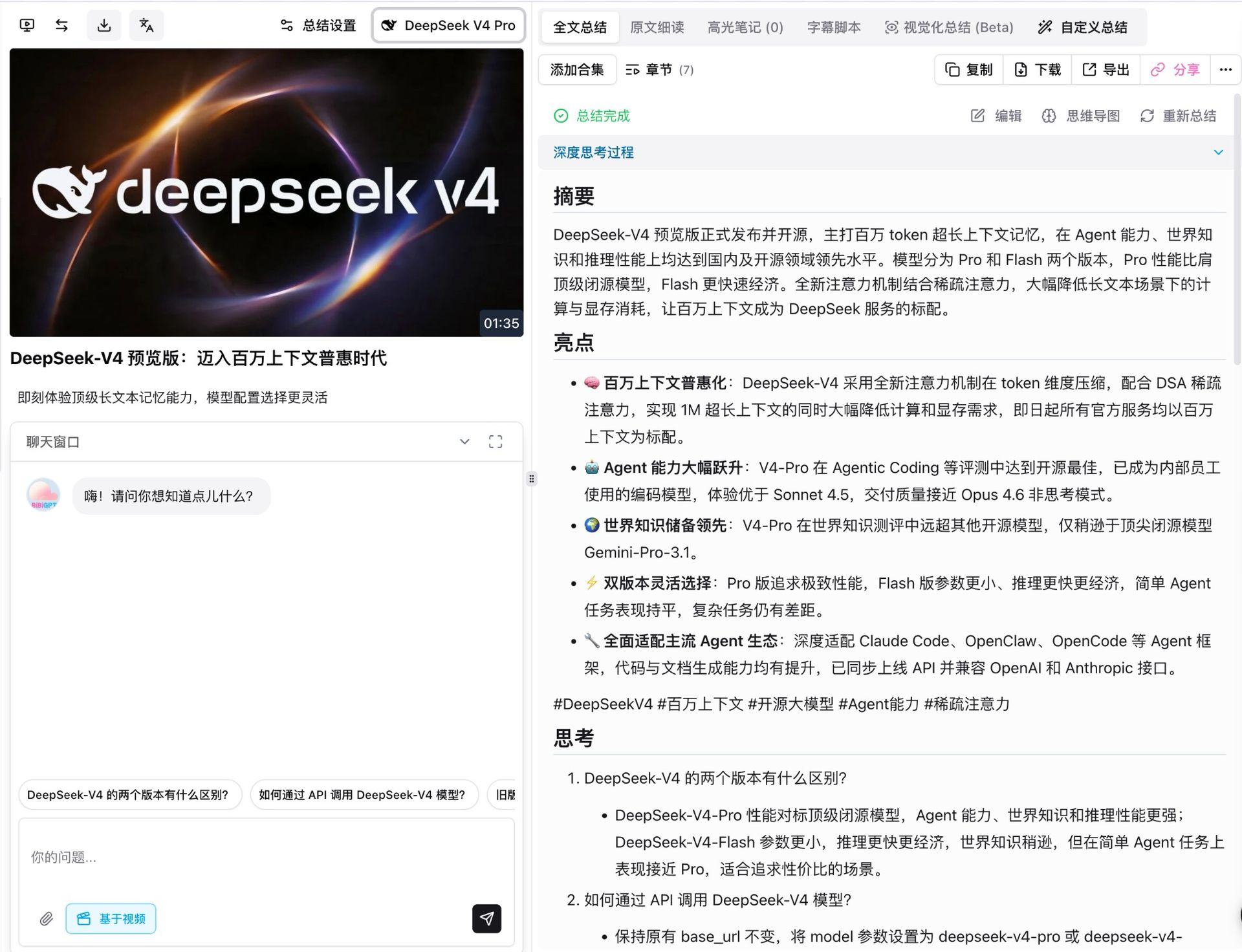
A few details worth calling out:
- Full fact coverage: all five headline claims from the release (1M context as default, agent leap, world-knowledge lead, dual-tier flexibility, agent-ecosystem compatibility) came through accurately, including the parameter numbers
- Every conclusion is traceable: each point links back to a clickable video timestamp, jumping straight to the relevant moment
- Follow-up questions appear automatically: under the summary the model suggests extensions like “what is the difference between the two V4 tiers” and “how do I call them through the API,” ready for a one-tap deep dive
The improvement here mainly comes from thinking mode’s deeper reasoning. Long context is already a default path across the major models in BibiGPT, and V4’s arrival brings that “deep reasoning + full-transcript stability” combination into the open-source tier at first-rate quality.
Scenarios where switching to V4 applies directly
Open-source models keep dropping. You could ask: can’t I just use the DeepSeek website or the API directly? Why route through BibiGPT?
It comes down to the scenario. The DeepSeek website is a generic chatbox — you still need to download the video, transcribe, paste, and figure out how to prompt. BibiGPT has been doing one thing for years: making long videos and podcasts as easy to consume as reading an article. V4 is the newest capability added to that stack; what actually makes “paste a link, get real understanding” work is the product layer we have been refining around the model.
Inside BibiGPT, the following capabilities directly follow the model you select as your “Default Model” — in other words, once you switch to DeepSeek V4, these features are running on V4.
📝 Video Summaries (Default + Custom Prompt)
The thing you use most often — hitting “Summarize” after pasting a link — runs on whichever model you have selected. Any saved custom prompts (things like “Counterintuitive Analyst”, “Critical Thinking”, or “Investment Analyst”) go through the same model as well. Switch to DeepSeek V4 Pro Thinking, re-run the same video with the same prompt, and you get a direct side-by-side comparison on reasoning depth and structure. This is one of the scenarios we are still exploring ourselves — run it on your own content and see whether the result fits your expectations better.
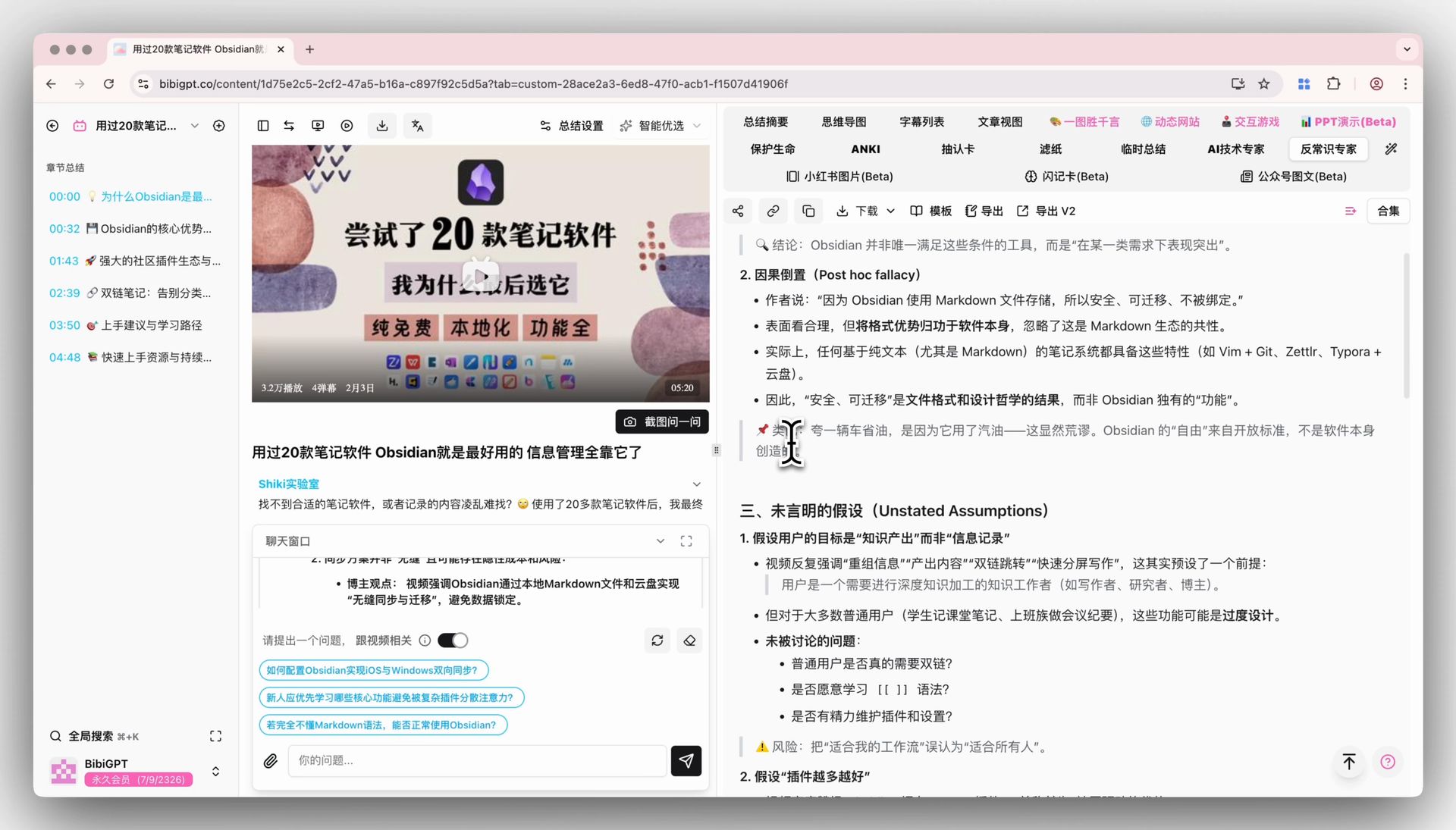
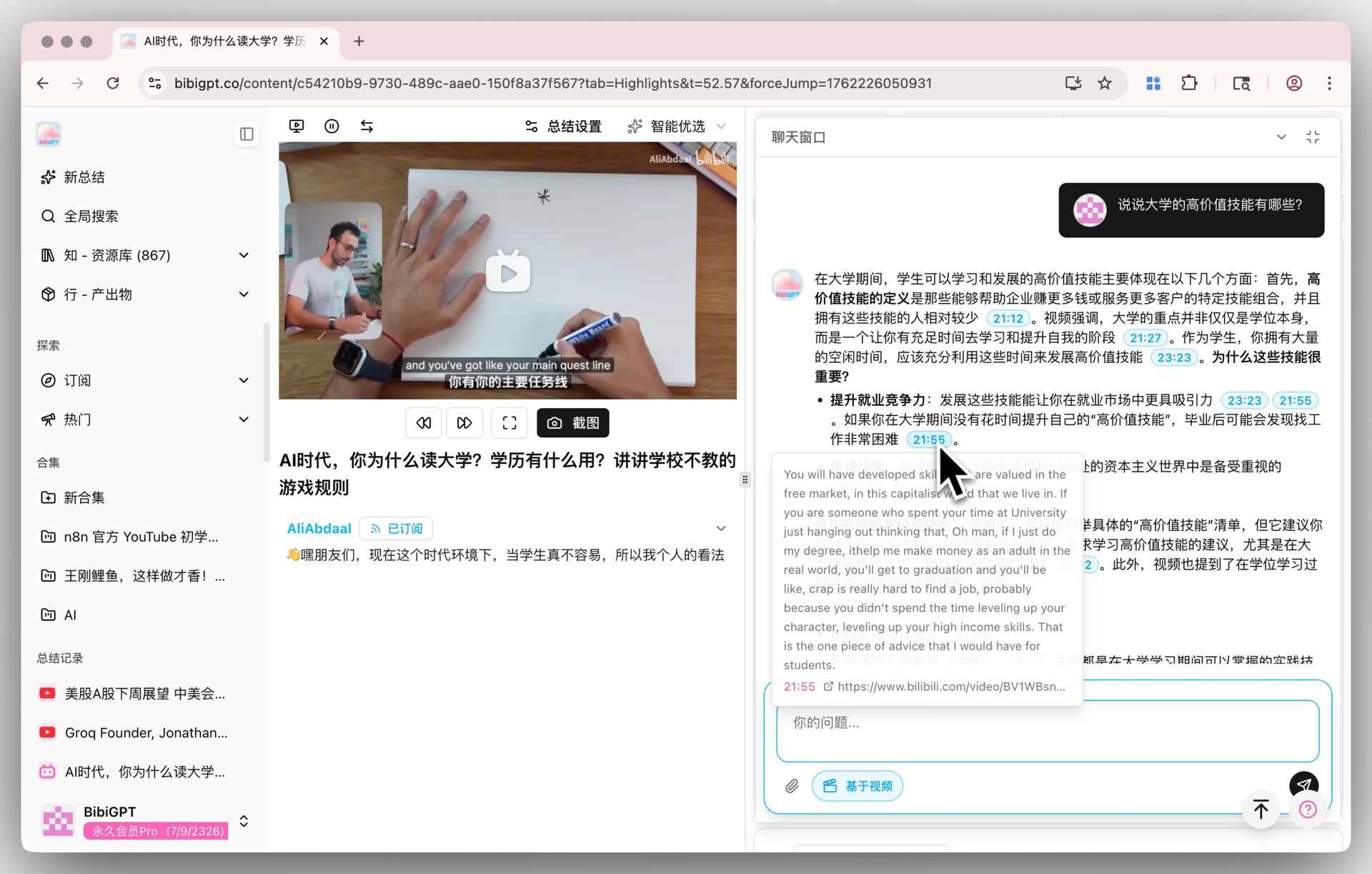
🎯 AI Video Chat with Source Tracing
The chat window below the video detail page also follows the default model. Every answer carries a clickable timestamp — “he made the opposite point at 1:12:30”, one tap and you jump there. Once you have switched to V4, pick a 1+ hour interview and ask a few rounds of follow-up questions — this is a scenario where differences between models tend to show up quickly, and it’s worth a firsthand run.
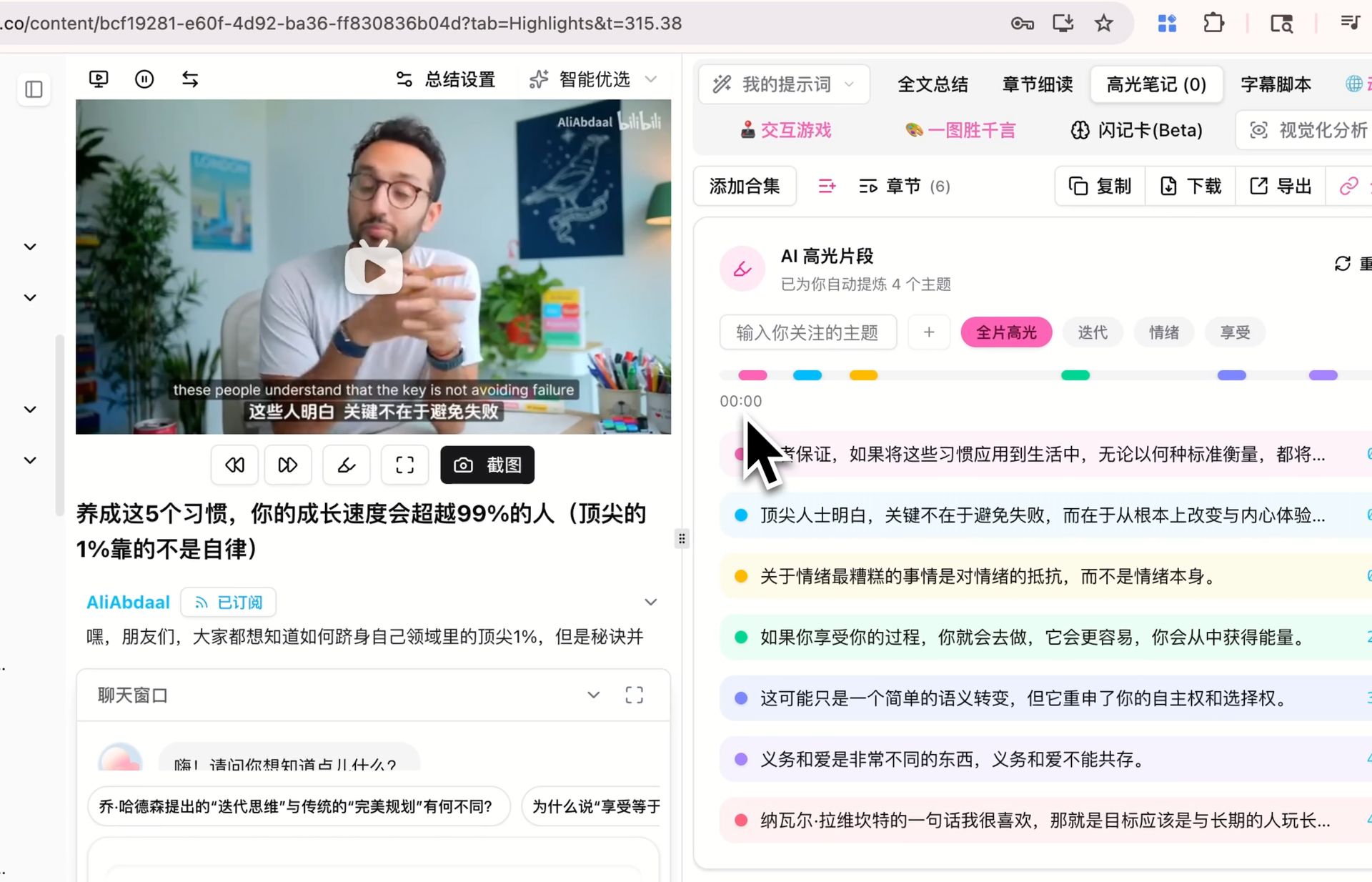
🔖 AI Highlight Notes
Extracting the highlight clips from a video with timestamps — grouped by topic — also runs on the default model. If you have already generated highlight notes for some video on another model, re-run them on V4 and compare which clips get marked as highlights and how the topics cluster. Whether the difference is meaningful on your content is easiest to judge by doing it yourself.
All three are scenarios we are still evaluating ourselves — results vary across different content, prompts, and languages, and the most reliable take is the one you form after a few runs inside your own workflow.
A couple of other areas use dedicated models — visual content analysis runs on a vision model, and video-to-illustrated-article uses a fixed pipeline — so they do not respond to the default-model switch and are not part of the comparison above.
BibiGPT has served 1M+ users and generated 5M+ AI summaries to date. That scale helps us map every new model onto real-world scenarios quickly, instead of staying at the benchmark-comparison layer.
The AI era: what is scarce is not models, but how fast you consume content
In 2026, AI models are essentially like running water — DeepSeek V4, Gemini 3.1 Pro, Claude Opus 4.6 are all within reach. Models are no longer scarce.
What is scarce? How fast you turn information into opinions, and opinions into action.
Audio and video are the lowest-density, longest-to-consume format on the internet. A two-hour interview transcribed is 8,000 words, but the real thesis might be 300. A 30-hour podcast season yields maybe 20 durable quotes. For years the only trick was 1.5x or 2x playback — trading attention for density. With the latest models, the math flips:
- No more passive listening, just ask the questions you care about — the model pulls the answers from the transcript
- No need to finish before judging, read the summary first, then decide if it deserves the hour
- No more flipping one video at a time, search across all of them — “who among the 100 creators I follow has talked about this topic”
BibiGPT does one thing: plug the best available model into the biggest but hardest-to-consume format — audio and video — so anyone can compress two hours of video into fifteen minutes of high-density reading. DeepSeek V4 adds one more reliable option to that stack.
FAQ
Q1: What is the difference between DeepSeek V4 Pro and V4 Pro Thinking?
The core difference is whether reasoning is explicit. Non-thinking is lower latency with shorter output, good for a clean summary. Thinking mode generates a reasoning chain first — better for multi-step logic, cross-chapter comparison, or argument analysis. You can tune depth with reasoning_effort=high/max; deeper reasoning, slower output.
Q2: Should I pick V4 Pro or V4 Flash?
Think in terms of “length × reasoning complexity.” Over an hour or multi-step reasoning → Pro. Under thirty minutes and a clean summary is enough → Flash. When in doubt, start with Flash and switch to Pro if it falls short — BibiGPT caches the transcript so re-summarizing skips the transcription step entirely.
Q3: Why go through BibiGPT instead of using the DeepSeek website directly?
The DeepSeek website is a generic chatbox — you still need to download, transcribe, paste, and prompt yourself. BibiGPT handles the upstream pipeline (30+ platform link parsing, transcription, visual analysis, timestamp alignment), and DeepSeek V4 only needs to cover the final understand-and-generate step. Same input, and you additionally get mindmaps, highlight notes, illustrated articles, and structured exports without any extra assembly.
Q4: How long a video can DeepSeek V4 handle?
V4 Pro and Flash both have 1M token context — roughly 1.5 million Chinese characters, or over 20 hours of dialogue — enough for a full podcast season. BibiGPT automatically decides between single-pass summarization and chunk-then-consolidate based on the model’s effective context.
Q5: Are the DeepSeek V4 weights open-source?
Fully open-source. Weights are on Hugging Face deepseek-ai/deepseek-v4 and ModelScope; the technical report is in DeepSeek_V4.pdf. Researchers and self-hosters can grab them directly.
Try V4 now
The most direct way to feel V4: pick a long video you’ve been meaning to actually watch — a lecture, a podcast episode, a documentary, whatever — and run it through DeepSeek V4 Pro Thinking. See how V4 handles something you actually care about.
Start your AI efficient learning journey now:
- 🌐 Official Website: https://bibigpt.co/en/desktop?utm_source=growth-pages&utm_medium=blog-inline-cta&utm_campaign=bibigpt-integrates-deepseek-v4-1m-context
- 📱 Mobile Download: https://aitodo.co/app
- 💻 Desktop Download: https://aitodo.co/download/desktop
- ✨ Learn More Features: https://aitodo.co/features
BibiGPT Team