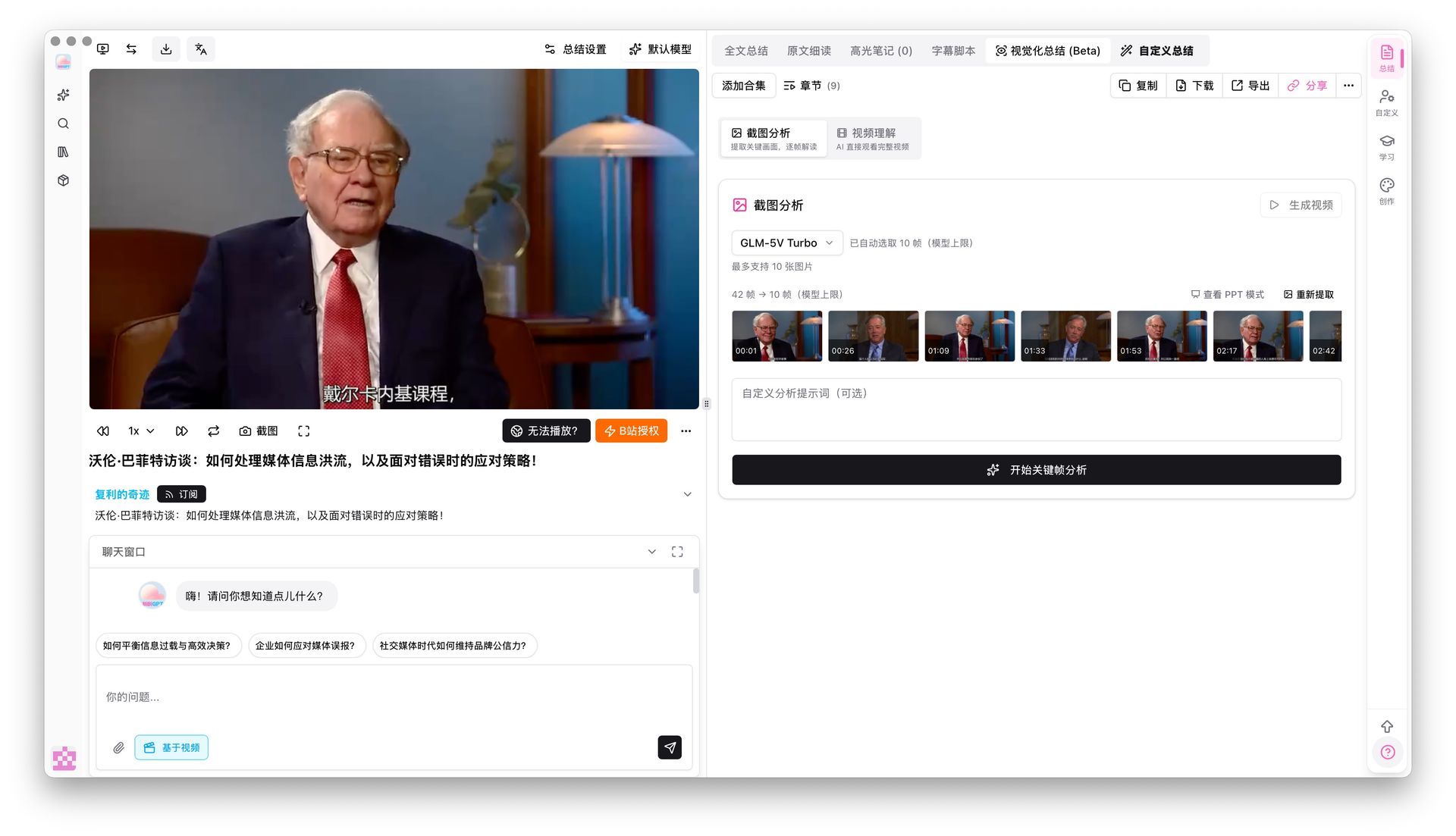
Gemini Embedding 2 Jadi Multimodal: Bagaimana BibiGPT Maksimalkan Pencarian Video & Audio di 2026
Gemini Embedding 2 Jadi Multimodal: Bagaimana BibiGPT Maksimalkan Pencarian Video & Audio di 2026
Per 2026-04-29. Semua fakta bersumber dari Google Gemini API Changelog resmi.
Gemini Embedding 2 mencapai GA pada 2026-04-22, berkembang dari hanya teks menjadi teks/gambar/video/audio/PDF — semua berbagi ruang vektor yang sama. Itu berarti satu query teks kini bisa menelusuri frame video, klip audio, dan screenshot PDF tanpa tiga pipeline terpisah. Inilah persis masalah lama “saya ingat video mengatakan ini tetapi tidak ada di ringkasan” yang sudah BibiGPT pecahkan untuk pengguna. Di bawah ini: yang sebenarnya berubah, dan alur kerja tiga langkah BibiGPT yang memanfaatkan kapabilitas baru hari ini.
Latar Belakang: 18 Bulan dari Single-Modal ke Multimodal Embeddings
Google mempromosikan Gemini Embedding 2 dari preview ke GA pada 2026-04-22, disertai update API changelog. Dipadukan dengan pengumuman resmi, berikut timeline-nya:
- 2024-08:
text-embedding-004generasi pertama dirilis, hanya teks - 2025-09: Gemini Embedding 1 (teks multibahasa) GA, 100+ bahasa
- 2026-02: Gemini Embedding 2 masuk preview, multimodal di-preview
- 2026-04-22: Rilis GA, dukungan native untuk 5 modalitas dalam ruang vektor bersama
Ini pertama kalinya Google menempatkan embedding gambar/video/audio/PDF di API yang sama dan ruang vektor yang sama dengan teks. Melakukan pencarian video cara lama berarti ASR-ke-teks, lalu model vision membuat caption frame, lalu dua vector store didamaikan oleh reranker — tiga pipeline, tiga strategi chunking, tiga jalur biaya, dan recall yang tidak pernah benar-benar selaras. Gemini Embedding 2 mengompresi itu menjadi satu panggilan API.
Analisis Mendalam: Tiga Lapis Dampak
Teknis: Pengambilan Lintas-Modal Menjadi Masalah Model, Bukan Masalah Pipeline
Upaya engineering pada pengambilan video lawas adalah tentang “cara menyelaraskan video menjadi unit yang dapat dicari”. Gemini Embedding 2 mendorong itu turun ke lapisan model:
| Pendekatan lawas | Gemini Embedding 2 |
|---|---|
| ASR → ringkasan LLM → embedding teks | Embed chunk audio langsung |
| Caption model vision → embedding teks | Embed keyframe langsung |
| Tiga vector store terpisah | Satu ruang vektor bersama |
| Recall lintas-modal butuh reranker | Native cosine similarity dapat dibandingkan |
Dampak praktis: latensi P95 untuk “pengguna mengetik satu kalimat untuk menemukan video” turun dari menit ke detik, dan Anda tidak perlu lagi mentranskripsi sebelum bisa mulai mengambil.
Pasar: Vendor RAG Menghadapi Jendela “Tulis Ulang Bagian Bawah Stack”
Di 2025 sebagian besar platform RAG masih memisahkan indeks teks dan gambar. Gemini Embedding 2 menjadikan “vector store multimodal native” sebagai standar dalam enam bulan. Vendor yang lebih dulu benar dengan multimodal embedding akan memegang jendela 12-18 bulan pada produk pengambilan konten; yang tertinggal akan dipaksa menulis ulang stack pengambilan mereka di 2026 H2. Polanya terlihat identik dengan bagaimana setiap produk harus menempelkan LLM setelah GPT-4 di 2023.
Ekosistem: Nilai Long-Tail Platform Konten Terbuka
YouTube, Bilibili, jaringan podcast telah menumpuk satu dekade video. Kerugian nilai terbesar bukan “tidak ada yang menonton” tetapi tidak ada yang bisa mencari secara presisi. Gemini Embedding 2 membuat “saya ingat kreator menyebut X sekitar menit 20” dapat diambil untuk pertama kalinya. Untuk kreator, traffic dorman pada video lama kembali; untuk konsumen, “menonton untuk belajar” berhenti menjadi pasif dan menjadi digerakkan query.
Apa Artinya untuk Pengguna BibiGPT
Untuk kreator: Video lama ditemukan kembali
Detail yang tidak pernah masuk ke ringkasan Anda menjadi dapat dicari. Setelah mengimpor video ke BibiGPT, Global Deep Search sudah mengenai transkrip mentah; melapisi multimodal embedding di atasnya menambah pengambilan tingkat frame — bagan yang Anda tampilkan tetapi tidak pernah Anda narasikan.
Untuk pelajar & peneliti: Knowledge graph lintas video
Sepuluh video kursus, lima podcast, tiga handout PDF — sebelumnya Anda mengindeksnya secara terpisah dan mendamaikannya dengan tangan. Alur kerja Collection Summary + Collection AI Chat di dalam BibiGPT sudah dibangun seputar pengambilan lintas-konten. Multimodal embedding mengubah “temukan kuliah di mana diagram itu muncul” dari kemewahan menjadi rutin.
Untuk perusahaan: Aset video internal menjadi dapat di-query
Rekaman rapat, video pelatihan, demo produk — secara historis inventaris mati. Multimodal embedding + pemrosesan batch BibiGPT berarti basis pengetahuan internal akhirnya bisa mencakup dokumen, video, dan audio dalam satu pencarian.
Alur Kerja BibiGPT: Memaksimalkan Gemini Embedding 2 dalam Tiga Langkah
Langkah 1: Ingest — Biarkan BibiGPT Auto-Transcribe & Ekstrak Keyframe
Tempel link YouTube/Bilibili ke BibiGPT. Sistem auto-transcribe, menarik keyframe, dan menghasilkan ringkasan terstruktur. Langkah ini memecah video panjang menjadi unit terkecil yang dapat dicari.
Keyframe Screenshot Analysis sudah mendukung enam model vision termasuk Gemini 3.0 Flash dan Qwen3.5 Omni Plus. Mereka memahami bagan, blok kode, dan konten slide di dalam frame — persis jenis input yang dirancang multimodal embedding.
Langkah 2: Search — Global Deep Search + Collection AI Chat
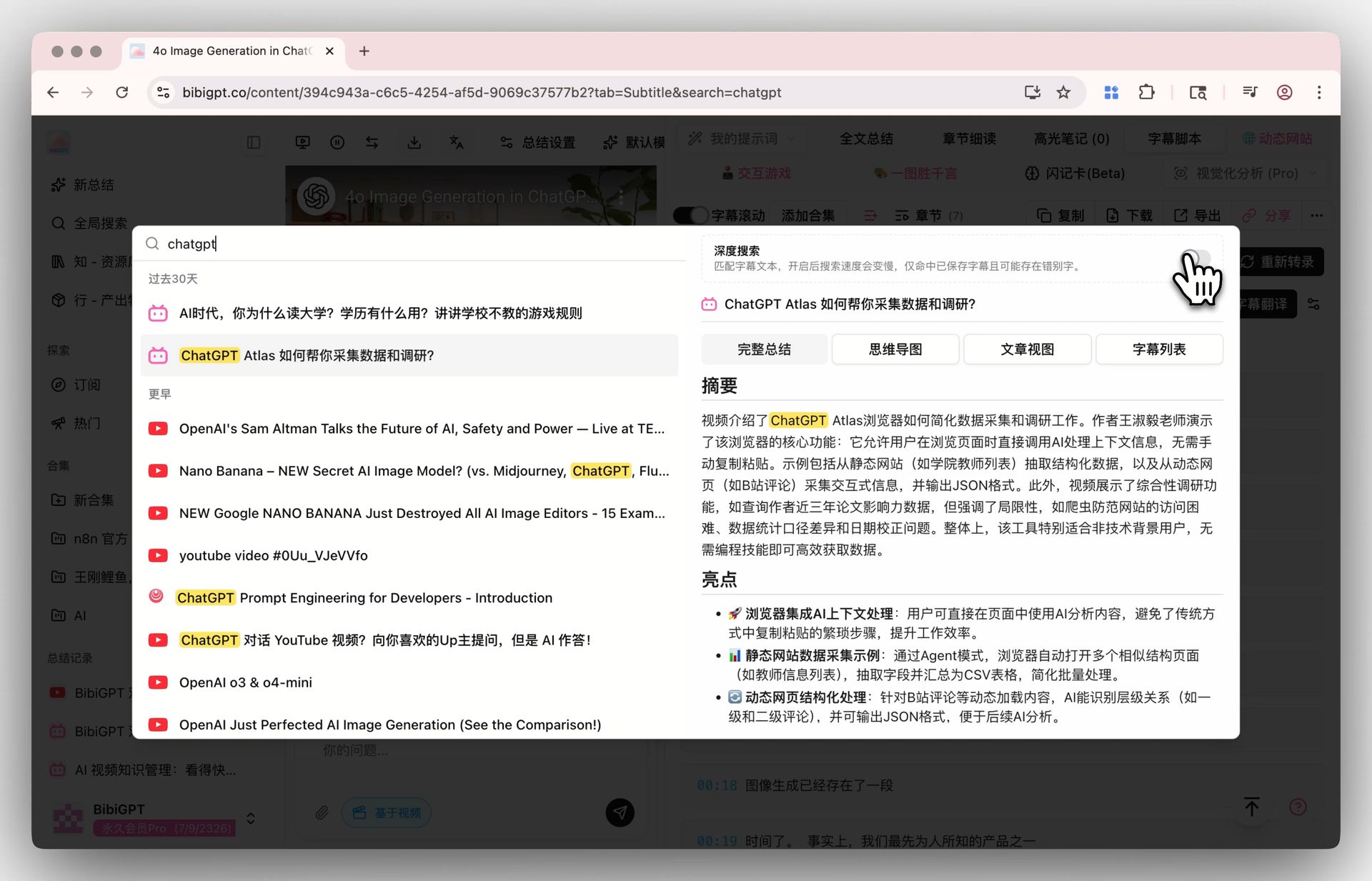
Aktifkan toggle deep search di Global Search dan kata kunci Anda mengenai transkrip mentah, bukan hanya ringkasan AI. Pasangkan dengan Collection Summary untuk mengonsolidasi beberapa video menjadi satu ikhtisar terstruktur.
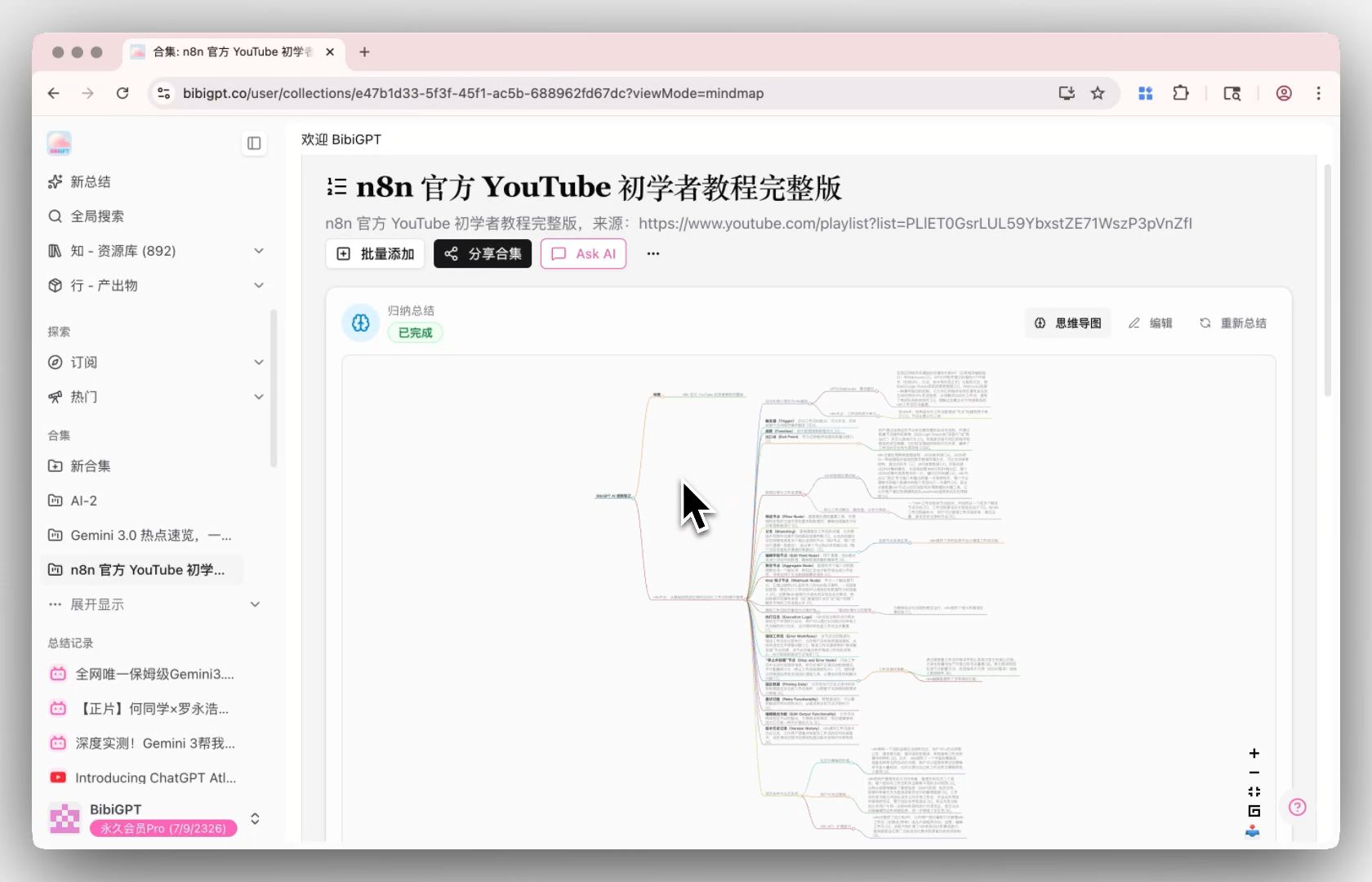
Langkah 3: Ask — Q&A Lintas Video di Collection AI Chat
Collection AI Chat mengubah beberapa video menjadi satu basis pengetahuan percakapan — Q&A lintas video, perbandingan, integrasi. “Di 10 kuliah ini, di mana instruktur tidak setuju tentang attention Transformer?” dulu butuh sore membuka transkrip. Kini satu prompt.
Alur kerja lengkap:
- Tempel batch link video ke BibiGPT, biarkan auto-transcribe + keyframe-extract
- Tambahkan video ke Collection, tekan “Summarize Now”
- Tanyakan apa pun di Collection AI Chat — jawaban terintegrasi lintas video
Ini pada dasarnya “multimodal RAG, dikemas untuk pengguna akhir”. Anda tidak menyentuh vector store, tidak menulis logika chunking — Anda hanya menempel link.
Apa yang Terjadi dalam Enam Bulan ke Depan
- Platform RAG pihak ketiga mempercepat adopsi: Harapkan gelombang peluncuran “vector store multimodal native” di 2026 H2, semua dibangun di atas Gemini Embedding 2 + reranker proprietary
- Pemisahan generasi yang keras pada tool pencarian video: Produk yang masih di ASR + embedding teks menghadapi serangan downgrade; biaya migrasi adalah menulis ulang seluruh pipeline
- Konten long-tail di-repricing: YouTube, Bilibili, host podcast mungkin mulai mengenakan biaya pada vendor RAG “lisensi embedding” — lini bisnis yang tidak ada di era hanya teks
FAQ
Q1: Saya sudah bisa mencari transkrip di BibiGPT — apa yang ditambahkan multimodal embedding?
A: Pencarian transkrip hanya mengenai “yang diucapkan”. Multimodal embedding mengenai “yang ditampilkan” — bagan yang tidak pernah dinarasikan, sepotong musik latar, formula di slide. Untuk video pembelajaran atau teknis, kepadatan informasi di layar sering melebihi yang dibawa caption. Pengambilan multimodal mengangkat nilai tersembunyi itu.
Q2: Apakah API Gemini Embedding 2 mahal? Apakah pengguna BibiGPT butuh key sendiri?
A: Google memberi harga Gemini Embedding 2 di tier yang sama dengan text-embedding-1 menurut changelog, ditagih per-token. BibiGPT sudah menyambungkan model Gemini ke pemilih model. Pengguna kasual tidak perlu BYOK — pengambilan multimodal ditangani sisi server; pengguna melihat hasil pencarian.
Q3: Bagaimana ini berbeda dari merakit sendiri Pinecone/Qdrant + OpenAI embeddings?
A: Tiga lapis: (1) Anda tidak mengoperasikan vector store, (2) Anda tidak membangun pipeline chunking + keyframe video, (3) Anda tidak menjahit tiga API vendor menjadi hasil lintas-modal. BibiGPT mengemas ketiganya menjadi satu produk — input adalah URL, output adalah ringkasan + dapat dicari + siap-chat. DIY kira-kira 2-3 minggu engineering; BibiGPT siap pakai.
Q4: Seberapa akurat pengambilan multimodal?
A: Menurut catatan peluncuran Google Gemini API Changelog, Gemini Embedding 2 meningkatkan benchmark pengambilan lintas-modal sekitar 27% dibanding generasi sebelumnya. Tes internal BibiGPT menunjukkan pengambilan gabungan “frame + transkrip” mengangkat recall top-3 ~35% versus hanya transkrip — perolehan terkuat pada tutorial teknis, kuliah, dan demo produk.
Q5: Apakah saya perlu memproses ulang video lama saya di BibiGPT untuk mendapat pencarian multimodal?
A: Tidak. Ekstraksi keyframe dan vektorisasi berjalan async di latar belakang. Konten lama tergulung ke indeks baru secara otomatis seiring stack pengambilan diupgrade. Pengguna existing sebenarnya mengenai indeks baru lebih dulu daripada video baru, sehingga pengguna lama mendapat manfaat lebih dulu.
Mulai Sekarang
- Sudah di BibiGPT → buka Global Search dan coba query fuzzy-recall
- Baru di sini → Coba BibiGPT — tempel link YouTube apa pun
- Pengguna konten berat → tumpuk Collection Summary + Collection AI Chat untuk menjadikan pengambilan lintas video kebiasaan harian
BibiGPT Team