Gemini Embedding 2 Goes Multimodal: How BibiGPT Maxes Out Video & Audio Search in 2026
Gemini Embedding 2 Goes Multimodal: How BibiGPT Maxes Out Video & Audio Search in 2026
As of 2026-04-29. All facts sourced from the official Google Gemini API Changelog.
Gemini Embedding 2 hit GA on 2026-04-22, expanding from text-only to text/image/video/audio/PDF — all sharing the same vector space. That means a single text query can now retrieve across video frames, audio clips and PDF screenshots without three separate pipelines. This is exactly the long-standing “I remember the video said this but it’s not in the summary” problem BibiGPT has been solving for users. Below: what actually changed, and the three-step BibiGPT workflow that puts the new capability to work today.
Background: 18 Months From Single-Modal to Multimodal Embeddings
Google promoted Gemini Embedding 2 from preview to GA on 2026-04-22, accompanied by an API changelog update. Combined with the official announcement, here is the timeline:
- 2024-08: First-generation
text-embedding-004ships, text-only - 2025-09: Gemini Embedding 1 (multilingual text) GA, 100+ languages
- 2026-02: Gemini Embedding 2 enters preview, multimodal previewed
- 2026-04-22: GA release, native support for 5 modalities in a shared vector space
This is the first time Google has put image/video/audio/PDF embeddings in the same API and the same vector space as text. Doing video search the old way meant ASR-to-text, then a vision model captioning frames, then two vector stores reconciled by a reranker — three pipelines, three chunking strategies, three cost lines, and recall that never quite aligned. Gemini Embedding 2 collapses that into one API call.
Deep Analysis: Three Layers of Impact
Technical: Cross-Modal Retrieval Becomes a Model Problem, Not a Pipeline Problem
The engineering effort in legacy video retrieval was about “how to align video into a searchable unit.” Gemini Embedding 2 pushes that down into the model layer:
| Legacy approach | Gemini Embedding 2 |
|---|---|
| ASR → LLM summary → text embedding | Embed audio chunks directly |
| Vision model caption → text embedding | Embed keyframes directly |
| Three separate vector stores | One shared vector space |
| Cross-modal recall needs a reranker | Native cosine similarity is comparable |
Practical impact: P95 latency for “user types one sentence to find a video” drops from minutes to seconds, and you no longer need to transcribe before you can start retrieving.
Market: RAG Vendors Face a “Rewrite the Bottom of the Stack” Window
In 2025 most RAG platforms still kept text and image indexes separate. Gemini Embedding 2 makes “natively multimodal vector store” table stakes within six months. Vendors who get multimodal embedding right first will hold a 12-18 month window on content retrieval products; the laggards will be forced to rewrite their retrieval stack in 2026 H2. The pace looks identical to how every product had to bolt on LLMs after GPT-4 in 2023.
Ecosystem: The Long-Tail Value of Content Platforms Gets Unlocked
YouTube, Bilibili, podcast networks have stockpiled a decade of video. The largest value loss is not “no one watches” but no one can search precisely. Gemini Embedding 2 makes “I remember a creator mentioned X around minute 20” retrievable for the first time. For creators, dormant traffic on old videos comes back; for consumers, “watching to learn” stops being passive and becomes query-driven.
What This Means for BibiGPT Users
For creators: Old videos rediscovered
Details that never made it into your summary become searchable. After importing a video into BibiGPT, Global Deep Search already hits raw transcripts; layering multimodal embedding on top adds frame-level retrieval — the chart you showed but never narrated.
For students & researchers: Cross-video knowledge graphs
Ten course videos, five podcasts, three PDF handouts — previously you indexed them separately and reconciled by hand. The Collection Summary + Collection AI Chat workflow inside BibiGPT was already built around cross-content retrieval. Multimodal embeddings turn “find the lecture where that diagram appeared” from luxury into routine.
For enterprises: Internal video assets become queryable
Meeting recordings, training videos, product demos — historically dead inventory. Multimodal embeddings + BibiGPT’s batch processing mean an internal knowledge base can finally cover documents, video and audio in one search.
BibiGPT Workflow: Maxing Out Gemini Embedding 2 in Three Steps
Step 1: Ingest — Let BibiGPT Auto-Transcribe & Extract Keyframes
Paste a YouTube/Bilibili link into BibiGPT. The system auto-transcribes, pulls keyframes and produces a structured summary. This step shreds a long video into the smallest searchable unit.
Keyframe Screenshot Analysis already supports six vision models including Gemini 3.0 Flash and Qwen3.5 Omni Plus. They understand charts, code blocks and slide content inside the frame — exactly the kind of input multimodal embeddings were designed for.
Step 2: Search — Global Deep Search + Collection AI Chat
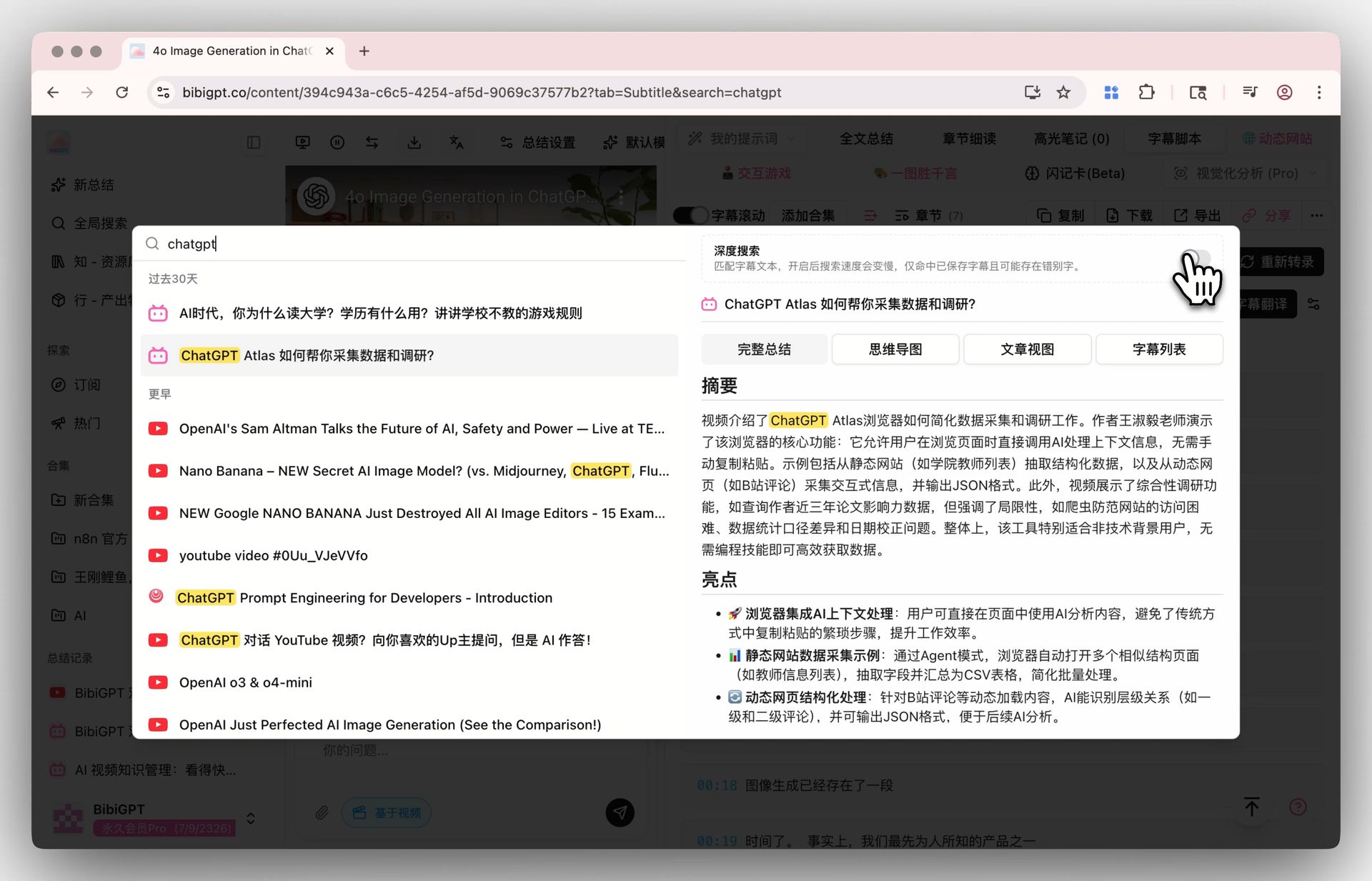
Flip the deep search toggle in Global Search and your keyword hits the raw transcript, not just AI summaries. Pair it with Collection Summary to consolidate multiple videos into one structured overview.
Step 3: Ask — Cross-Video Q&A in Collection AI Chat
Collection AI Chat turns multiple videos into one conversational knowledge base — cross-video Q&A, comparison, integration. “Across these 10 lectures, where do the instructors disagree on Transformer attention?” used to take an afternoon of transcript flipping. Now it’s one prompt.
Full workflow:
- Paste a batch of video links into BibiGPT, let it auto-transcribe + keyframe-extract
- Add the videos to a Collection, hit “Summarize Now”
- Ask anything in Collection AI Chat — answers integrate across videos
This is essentially “multimodal RAG, packaged for end users.” You don’t touch a vector store, you don’t write chunking logic — you just paste links.
What Happens in the Next Six Months
- Third-party RAG platforms accelerate adoption: Expect a wave of “natively multimodal vector store” launches in 2026 H2, all built on Gemini Embedding 2 + a proprietary reranker
- A hard generational split in video search tools: Products still on ASR + text embeddings face a downgrade attack; migration cost is rewriting the entire pipeline
- Long-tail content gets repriced: YouTube, Bilibili, podcast hosts may start charging RAG vendors “embedding licenses” — a business line that didn’t exist in the text-only era
FAQ
Q1: I can already search transcripts in BibiGPT — what does multimodal embedding add?
A: Transcript search only hits “what was spoken.” Multimodal embedding hits “what’s shown” — a chart never narrated, a piece of background music, a formula on a slide. For learning- or technical-heavy videos, the on-screen information density often exceeds what the captions carry. Multimodal retrieval surfaces that hidden value.
Q2: Is the Gemini Embedding 2 API expensive? Do BibiGPT users need their own key?
A: Google priced Gemini Embedding 2 in the same tier as text-embedding-1 per the changelog, billed per-token. BibiGPT already wires Gemini models into the model selector. Casual users don’t need to BYOK — multimodal retrieval is handled server-side; users see search results.
Q3: How is this different from rolling my own Pinecone/Qdrant + OpenAI embeddings?
A: Three layers: (1) you don’t operate a vector store, (2) you don’t build the video chunking + keyframe pipeline, (3) you don’t stitch three vendor APIs into a cross-modal result. BibiGPT packages all three into one product — input is a URL, output is summary + searchable + chat-ready. DIY is roughly 2-3 weeks of engineering; BibiGPT is out-of-the-box.
Q4: How accurate is multimodal retrieval?
A: Per the Google Gemini API Changelog launch notes, Gemini Embedding 2 improves cross-modal retrieval benchmarks by about 27% over the prior generation. Internal BibiGPT tests show “frame + transcript” joint retrieval lifts top-3 recall by ~35% versus transcript-only — strongest gains on technical tutorials, lectures and product demos.
Q5: Do I need to reprocess my old videos in BibiGPT to get multimodal search?
A: No. Keyframe extraction and vectorization run async in the background. Old content rolls into the new index automatically as the retrieval stack upgrades. Existing users actually hit the new index ahead of new videos, so long-time users benefit first.
Get Started
- Already on BibiGPT → open Global Search and try a fuzzy-recall query
- New here → Try BibiGPT — paste any YouTube link
- Heavy content user → stack Collection Summary + Collection AI Chat to make cross-video retrieval a daily habit
BibiGPT Team