Gemini Embedding 2 マルチモーダル GA — BibiGPT で動画・音声検索を使い倒す方法
Gemini Embedding 2 マルチモーダル GA — BibiGPT で動画・音声検索を使い倒す方法
2026-04-29 時点。すべての事実は Google Gemini API Changelog 公式ドキュメントに基づきます。
Gemini Embedding 2 は 2026-04-22 に GA となり、テキスト専用からテキスト/画像/動画/音声/PDF の 5 モダリティが同一ベクトル空間を共有する仕組みに進化しました。 一文のクエリで動画フレーム・音声片・PDF スクリーンショットを横断検索できるようになり、BibiGPT が長年取り組んできた「動画で言ってたはずなのに要約に載ってない」課題と直結します。本記事では何が変わったのかを解説し、BibiGPT で今すぐ使い倒す 3 ステップワークフローを紹介します。
背景: シングルモーダルからマルチモーダル埋め込みへの 18 ヶ月
Google は 2026-04-22 に Gemini Embedding 2 を preview から GA に昇格し、同日 API changelog を更新しました。公式アナウンスを総合した時系列:
- 2024-08: 第 1 世代
text-embedding-004公開、テキスト専用 - 2025-09: Gemini Embedding 1 (多言語テキスト) GA、100+ 言語サポート
- 2026-02: Gemini Embedding 2 が preview 入り、マルチモーダルを初予告
- 2026-04-22: GA リリース、5 モダリティが共通ベクトル空間を共有
Google が画像/動画/音声/PDF の埋め込みをテキストと同じ API、同じベクトル空間に置いた初めての出来事です。従来の動画検索は ASR でテキスト化 → ビジョンモデルで画面キャプション → 2 系統のベクトルストアを reranker で揃える、という 3 重パイプラインが必要でした。Gemini Embedding 2 はこれを 1 回の API 呼び出しに圧縮します。
詳細分析: 3 つの影響レイヤー
技術的影響: クロスモーダル検索が「エンジニアリング問題」から「モデル問題」へ
従来の動画検索のエンジニアリング負荷は「動画を検索可能な単位に揃える」ことに集中していました。Gemini Embedding 2 はこれをモデル層に押し下げます:
| 従来方式 | Gemini Embedding 2 |
|---|---|
| ASR → LLM 要約 → テキスト埋め込み | 音声チャンクを直接埋め込み |
| ビジョンモデルでキャプション → テキスト埋め込み | キーフレームを直接埋め込み |
| 3 つのベクトルストアを分離管理 | 単一ベクトル空間 |
| クロスモーダル整合に reranker 必須 | ネイティブにコサイン類似度比較可能 |
実際のインパクト: 「ユーザーが一文で動画を検索する」P95 レイテンシが分単位から秒単位に短縮され、書き起こし完了を待たなくても検索を開始できる。
市場影響: RAG ベンダーに「スタック下層書き直し」のウィンドウ
2025 年時点で多くの RAG プラットフォームはテキストと画像のインデックスを分離していました。Gemini Embedding 2 は半年以内に「ネイティブマルチモーダルベクトルストア」を業界標準にします。マルチモーダル埋め込みを最初に正しく実装したベンダーはコンテンツ検索プロダクトで 12-18 ヶ月のウィンドウを得て、出遅れたベンダーは 2026 H2 に検索スタックを書き直す羽目になります。2023 年の GPT-4 リリース後にあらゆる製品が LLM を後付けで組み込んだ動きと同じスピード感です。
エコシステム影響: コンテンツプラットフォームのロングテール価値が解放
YouTube・Bilibili・ポッドキャストネットワークは 10 年分の動画資産を抱えています。最大の価値損失は「誰も見ない」ではなく 誰も精密に検索できない ことでした。Gemini Embedding 2 は「あるクリエイターが 20 分頃に X を話していた」というあいまいなクエリを初めてエンジニアリング的に解決可能にします。クリエイターは古い動画の検索流入が復活し、視聴者にとっては「動画で学ぶ」が受動的な視聴からクエリ駆動に変わります。
BibiGPT ユーザーへの実用的な意味
コンテンツ制作者: 古い動画の再発見
要約に書かれなかった詳細が検索可能になります。動画を BibiGPT に取り込めば グローバルディープ検索 で字幕原文まで命中し、マルチモーダル埋め込みが加わると「ナレーションされなかったが画面に映っていたチャート」まで検索対象になります。
学生・研究者: 動画横断の知識グラフ
10 本の講義動画 + 5 本の補完ポッドキャスト + 3 本の PDF レジュメ — 従来は別々にインデックス化して手作業で照合していました。BibiGPT の コレクション要約 + コレクション AI 対話 ワークフローはもともとクロスコンテンツ検索が中核でした。マルチモーダル埋め込みで「あの図が出てきた講義を探す」が日常になります。
法人ユーザー: 社内動画資産が検索可能に
会議録画、研修動画、製品デモ — これまでは眠った資産でした。マルチモーダル埋め込み + BibiGPT のバッチ処理で「社内ナレッジベース」がドキュメント・動画・音声を一気通貫で検索できるようになります。
BibiGPT 実戦ワークフロー: Gemini Embedding 2 を 3 ステップで使い倒す
ステップ 1: 取り込み — BibiGPT が自動で書き起こし + キーフレーム抽出
YouTube/Bilibili のリンクを BibiGPT に貼り付けると、システムが ASR・キーフレーム抽出・構造化要約を自動で行います。長尺動画を検索可能な最小単位に分解する工程です。
キーフレームスクリーンショット解析 は Gemini 3.0 Flash、Qwen3.5 Omni Plus など 6 種類のビジョンモデルに対応しています。画面内のチャート・コード・スライドを理解できる入力こそ、マルチモーダル埋め込みが最も強い領域です。
ステップ 2: 検索 — グローバルディープ検索 + コレクション AI 対話
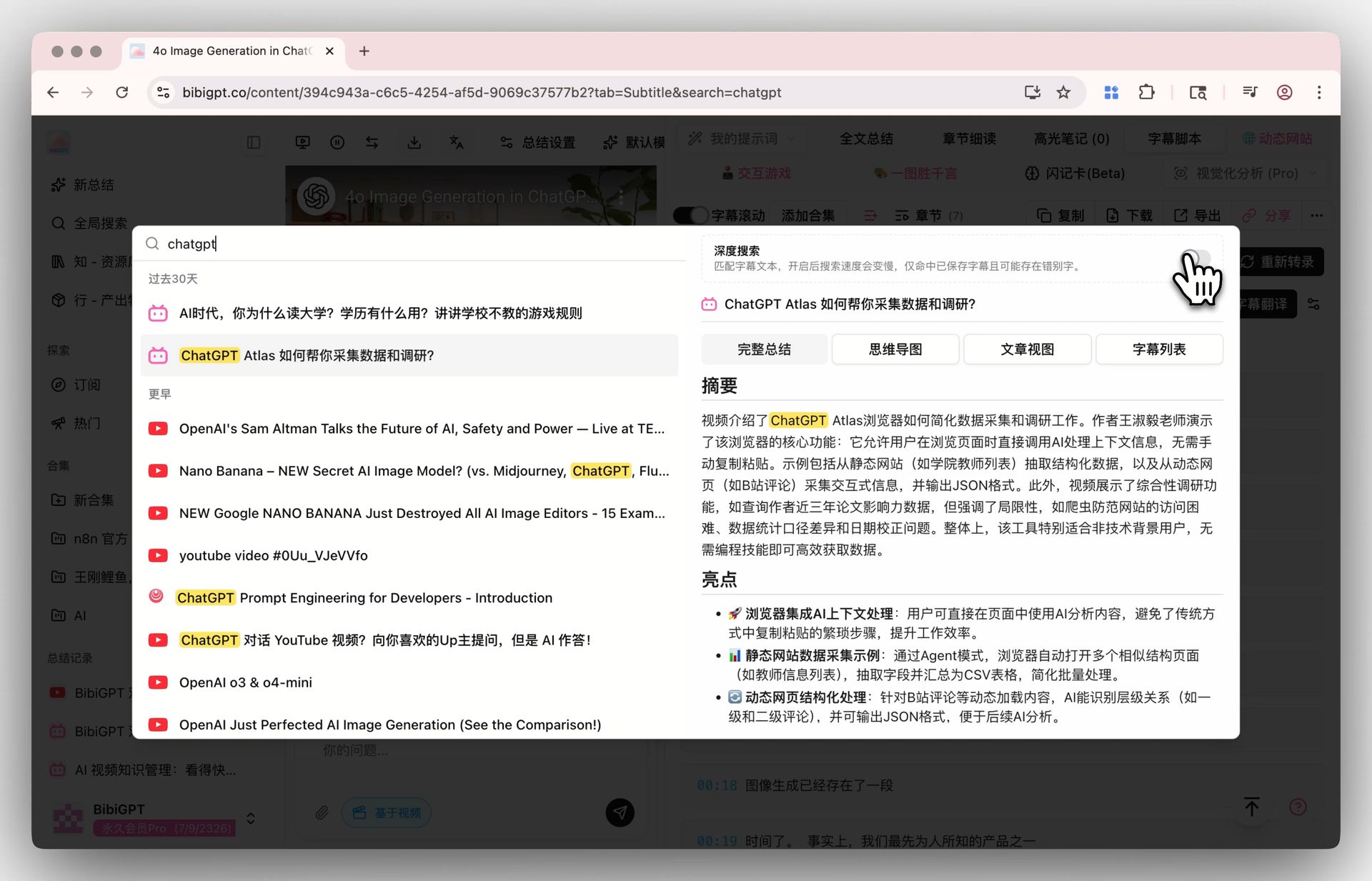
グローバル検索の “ディープ検索” トグル を ON にすると、キーワードが AI 要約ではなく字幕原文に直接ヒットします。コレクション要約 と組み合わせれば、複数動画の内容を 1 つの構造化総括にまとめられます。
ステップ 3: 質問 — コレクション AI 対話で動画横断 Q&A
コレクション AI 対話 は複数動画を 1 つの対話可能なナレッジベースに変え、動画横断の Q&A・比較・統合を支援します。「この 10 本の講義の中で、講師が Transformer attention について意見が分かれている箇所は?」のようなクエリは、過去なら半日かかったものが 1 プロンプトで完結します。
全体ワークフロー:
- 動画リンク群を BibiGPT に貼り付け、自動書き起こし + キーフレーム抽出を待つ
- 動画を同じコレクションに追加し、「今すぐ要約」をクリック
- コレクション AI 対話で自由に質問 — 回答は動画間の情報を統合
この組み合わせは本質的に「エンドユーザー向けにパッケージ化されたマルチモーダル RAG」です。ベクトルストアを触る必要も、チャンク戦略を書く必要もありません。リンクを BibiGPT に渡すだけで完結します。
今後 6 ヶ月の見通し
- サードパーティ RAG プラットフォームが採用を加速: 2026 H2 に「ネイティブマルチモーダルベクトルストア」製品リリースのラッシュ、標準構成は Gemini Embedding 2 + 自社 reranker
- 動画検索ツールに世代交代の分水嶺: ASR + テキスト埋め込みに留まる製品はダウングレード攻撃を受け、移行コストはパイプライン全面書き直し
- ロングテールコンテンツの再価格付け: YouTube・Bilibili・ポッドキャストホスティングが RAG ベンダーに「埋め込みライセンス料」を請求する新ビジネスが出現する可能性
よくある質問
Q1: すでに BibiGPT で字幕検索できますが、マルチモーダル埋め込みの追加価値は?
A: 字幕検索は「発話された単語」しかヒットしません。マルチモーダル埋め込みは「画面に表示されたもの」をヒットします — ナレーションなしで提示されたチャート、背景音楽、スライド上の重要な数式など。学習・技術系動画では字幕より画面の情報密度が高いケースが多く、マルチモーダル検索でその隠れた価値が引き出されます。
Q2: Gemini Embedding 2 API は高い? BibiGPT ユーザーは自前のキーが必要?
A: Google は changelog で Gemini Embedding 2 を text-embedding-1 と同じ価格帯に置き、トークン課金です。BibiGPT は モデルセレクター に Gemini 系列を統合済みで、一般ユーザーは BYOK 不要です。マルチモーダル検索は BibiGPT バックエンドで処理され、ユーザーには検索結果だけが見えます。
Q3: 自前で Pinecone/Qdrant + OpenAI 埋め込みを構築するのと何が違う?
A: 3 つのレイヤーで違います: (1) ベクトルストアを運用しなくていい、(2) 動画チャンク化・キーフレーム抽出のエンジニアリングが不要、(3) 3 ベンダーの API をクロスモーダル結果に縫合する作業が不要。BibiGPT はこれらを 1 つの製品体験にまとめており、入力は URL、出力は要約 + 検索可能 + 対話可能。自前 RAG 構築には通常 2-3 週間のエンジニアリングが必要ですが、BibiGPT は箱から出してすぐ使えます。
Q4: マルチモーダル検索の精度はどの程度?
A: Google Gemini API Changelog のリリースノートによれば、Gemini Embedding 2 はクロスモーダル retrieval ベンチマークで第 1 世代より約 27% 改善しています。BibiGPT 社内テストでは「フレーム + 字幕」結合検索が字幕単独より Top-3 リコールを約 35% 引き上げ、技術チュートリアル・公開講座・製品デモで最大の改善が見られます。
Q5: BibiGPT に既に登録した古い動画もマルチモーダル検索を受けるには再処理が必要?
A: 不要です。キーフレーム抽出とベクトル化はバックグラウンドで非同期処理されます。検索スタックがアップグレードされると古いコンテンツも自動で新インデックスに取り込まれ、既存動画が新規動画よりも先に新インデックスに入るため、長期ユーザーほど早く恩恵を受けます。
今すぐ始める
- すでに BibiGPT を使用中 → グローバル検索 を開いて、あいまいな記憶でクエリを投げてみる
- 初めての方 → BibiGPT を試す、任意の YouTube リンクを貼ってみてください
- ヘビーユーザー → コレクション要約 + コレクション AI 対話 を日常ワークフローに
BibiGPTチーム