Gemini Embedding 2 devient multimodal : comment BibiGPT pousse la recherche vidéo et audio en 2026
Gemini Embedding 2 devient multimodal : comment BibiGPT pousse la recherche vidéo et audio en 2026
Au 2026-04-29. Tous les faits sourcés via le changelog officiel Google Gemini API.
Gemini Embedding 2 a atteint la GA le 2026-04-22, passant du texte seul au texte/image/vidéo/audio/PDF — tous partageant le même espace vectoriel. Cela signifie qu’une seule requête textuelle peut désormais récupérer à travers les images vidéo, les clips audio et les captures PDF sans trois pipelines séparés. C’est exactement le problème historique « je me souviens que la vidéo a dit ça mais ce n’est pas dans le résumé » que BibiGPT résout pour ses utilisateurs. Ci-dessous : ce qui a changé concrètement, et le workflow BibiGPT en trois étapes pour mettre cette nouvelle capacité au travail dès aujourd’hui.
Contexte : 18 mois de l’embedding monomodal au multimodal
Google a fait passer Gemini Embedding 2 de la preview à la GA le 2026-04-22, accompagné d’une mise à jour du changelog API. Combiné à l’annonce officielle, voici la timeline :
- 2024-08 : Première génération
text-embedding-004, texte seul - 2025-09 : Gemini Embedding 1 (texte multilingue) GA, 100+ langues
- 2026-02 : Gemini Embedding 2 entre en preview, multimodal en avant-première
- 2026-04-22 : Sortie GA, prise en charge native de 5 modalités dans un espace vectoriel partagé
C’est la première fois que Google place les embeddings image/vidéo/audio/PDF dans la même API et le même espace vectoriel que le texte. Faire de la recherche vidéo à l’ancienne signifiait ASR vers texte, puis un modèle vision pour légender les frames, puis deux stores vectoriels réconciliés par un reranker — trois pipelines, trois stratégies de découpage, trois lignes de coût, et un rappel qui ne s’alignait jamais vraiment. Gemini Embedding 2 condense cela en un seul appel API.
Analyse approfondie : trois couches d’impact
Technique : la récupération inter-modale devient un problème de modèle, pas de pipeline
L’effort d’ingénierie dans la récupération vidéo héritée portait sur « comment aligner la vidéo en une unité interrogeable ». Gemini Embedding 2 pousse cela vers la couche modèle :
| Approche héritée | Gemini Embedding 2 |
|---|---|
| ASR → résumé LLM → embedding texte | Embedder les morceaux audio directement |
| Légende par modèle vision → embedding texte | Embedder les images-clés directement |
| Trois stores vectoriels séparés | Un espace vectoriel partagé |
| Rappel inter-modal nécessite un reranker | La similarité cosinus native est comparable |
Impact pratique : la latence P95 pour « l’utilisateur tape une phrase pour trouver une vidéo » chute de minutes à secondes, et vous n’avez plus besoin de transcrire avant de pouvoir commencer à récupérer.
Marché : les éditeurs RAG font face à une fenêtre de « réécrire le bas de la stack »
En 2025, la plupart des plateformes RAG gardaient encore les index texte et image séparés. Gemini Embedding 2 fait du « store vectoriel nativement multimodal » un standard de la table dans les six mois. Les éditeurs qui font bien le multimodal en premier tiendront une fenêtre de 12-18 mois sur les produits de récupération de contenu ; les retardataires seront forcés de réécrire leur stack de récupération au S2 2026. Le rythme ressemble exactement à la façon dont chaque produit a dû boulonner les LLM après GPT-4 en 2023.
Écosystème : la valeur long-tail des plateformes de contenu se débloque
YouTube, Bilibili, les réseaux de podcasts ont accumulé une décennie de vidéo. La plus grande perte de valeur n’est pas « personne ne regarde » mais personne ne peut chercher précisément. Gemini Embedding 2 rend « je me souviens qu’un créateur a mentionné X vers la minute 20 » récupérable pour la première fois. Pour les créateurs, le trafic dormant sur les vieilles vidéos revient ; pour les consommateurs, « regarder pour apprendre » cesse d’être passif et devient piloté par requête.
Ce que cela signifie pour les utilisateurs BibiGPT
Pour les créateurs : les vieilles vidéos redécouvertes
Les détails qui n’ont jamais fait partie de votre résumé deviennent interrogeables. Après import d’une vidéo dans BibiGPT, la recherche approfondie globale frappe déjà les transcriptions brutes ; superposer l’embedding multimodal ajoute la récupération au niveau image — le graphique que vous avez montré mais jamais commenté.
Pour les étudiants et chercheurs : graphes de connaissance inter-vidéos
Dix vidéos de cours, cinq podcasts, trois polycopiés PDF — auparavant vous les indexiez séparément et les réconciliiez à la main. Le workflow résumé sur collection + chat IA sur collection dans BibiGPT était déjà construit autour de la récupération inter-contenus. Les embeddings multimodaux transforment « trouver la conférence où ce diagramme est apparu » de luxe en routine.
Pour les entreprises : les actifs vidéo internes deviennent interrogeables
Enregistrements de réunions, vidéos de formation, démos produit — historiquement de l’inventaire mort. Les embeddings multimodaux + le traitement par lot de BibiGPT signifient qu’une base de connaissances interne peut enfin couvrir documents, vidéo et audio dans une seule recherche.
Workflow BibiGPT : pousser Gemini Embedding 2 au max en trois étapes
Étape 1 : Ingérer — laisser BibiGPT auto-transcrire et extraire les images-clés
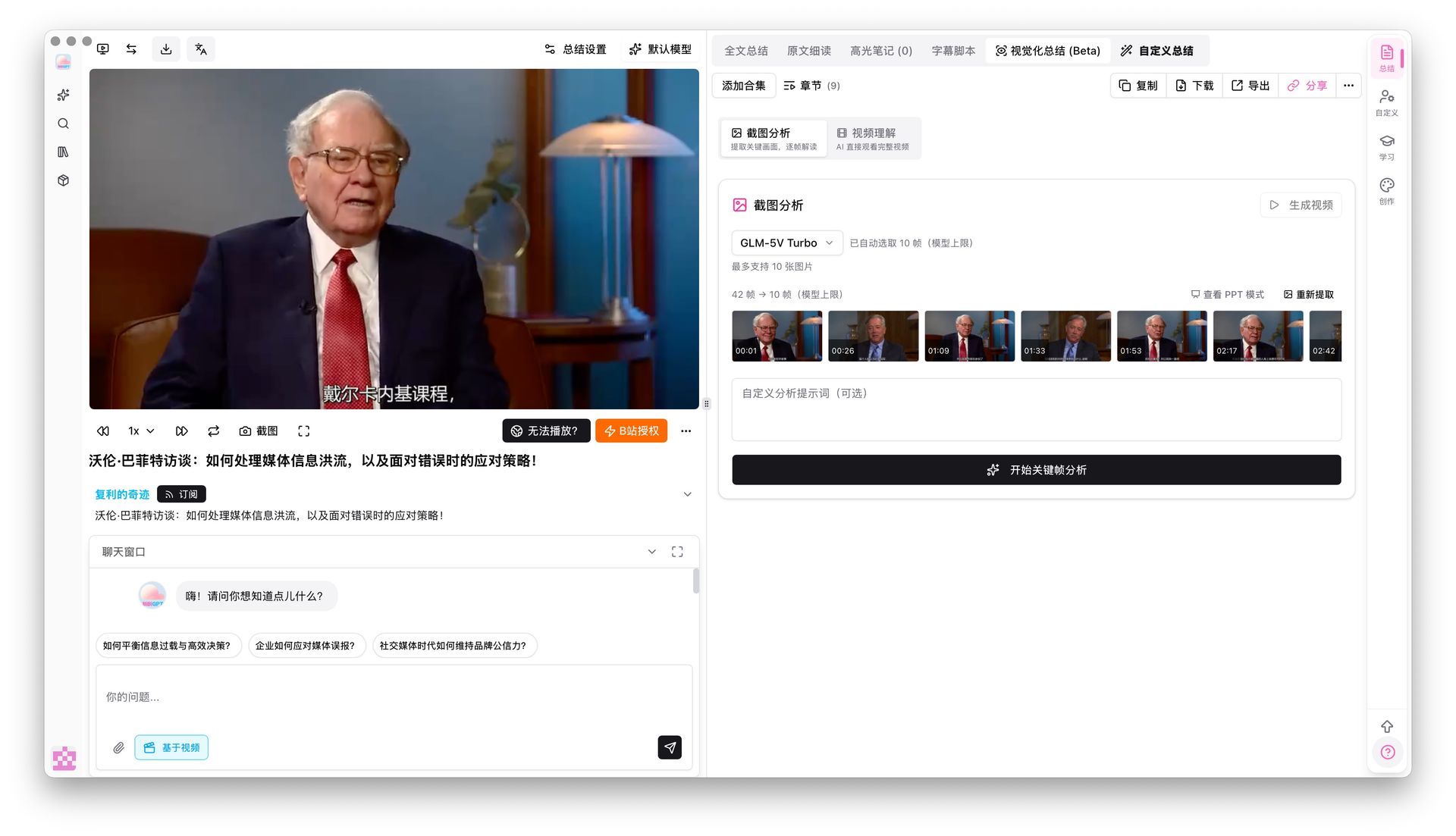
Collez un lien YouTube/Bilibili dans BibiGPT. Le système auto-transcrit, extrait les images-clés et produit un résumé structuré. Cette étape déchiquette une longue vidéo en la plus petite unité interrogeable.
L’analyse de capture d’image-clé prend déjà en charge six modèles vision dont Gemini 3.0 Flash et Qwen3.5 Omni Plus. Ils comprennent les graphiques, blocs de code et contenus de slide à l’intérieur de la frame — exactement le type d’entrée pour lequel les embeddings multimodaux ont été conçus.
Étape 2 : Chercher — recherche approfondie globale + chat IA sur collection
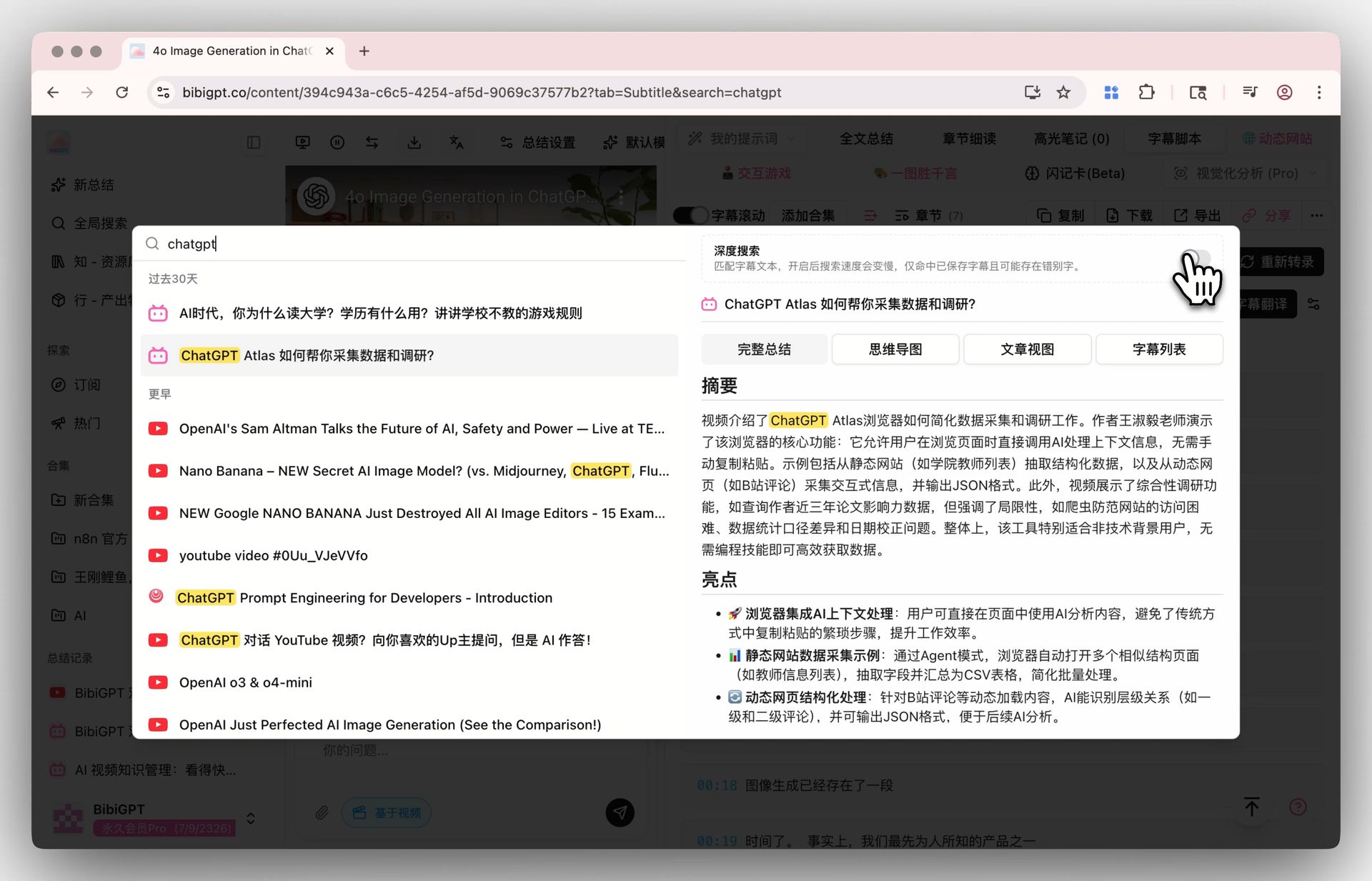
Activez la bascule de recherche approfondie dans la recherche globale et votre mot-clé frappe la transcription brute, pas seulement les résumés IA. Couplez avec le résumé sur collection pour consolider plusieurs vidéos en une vue d’ensemble structurée.
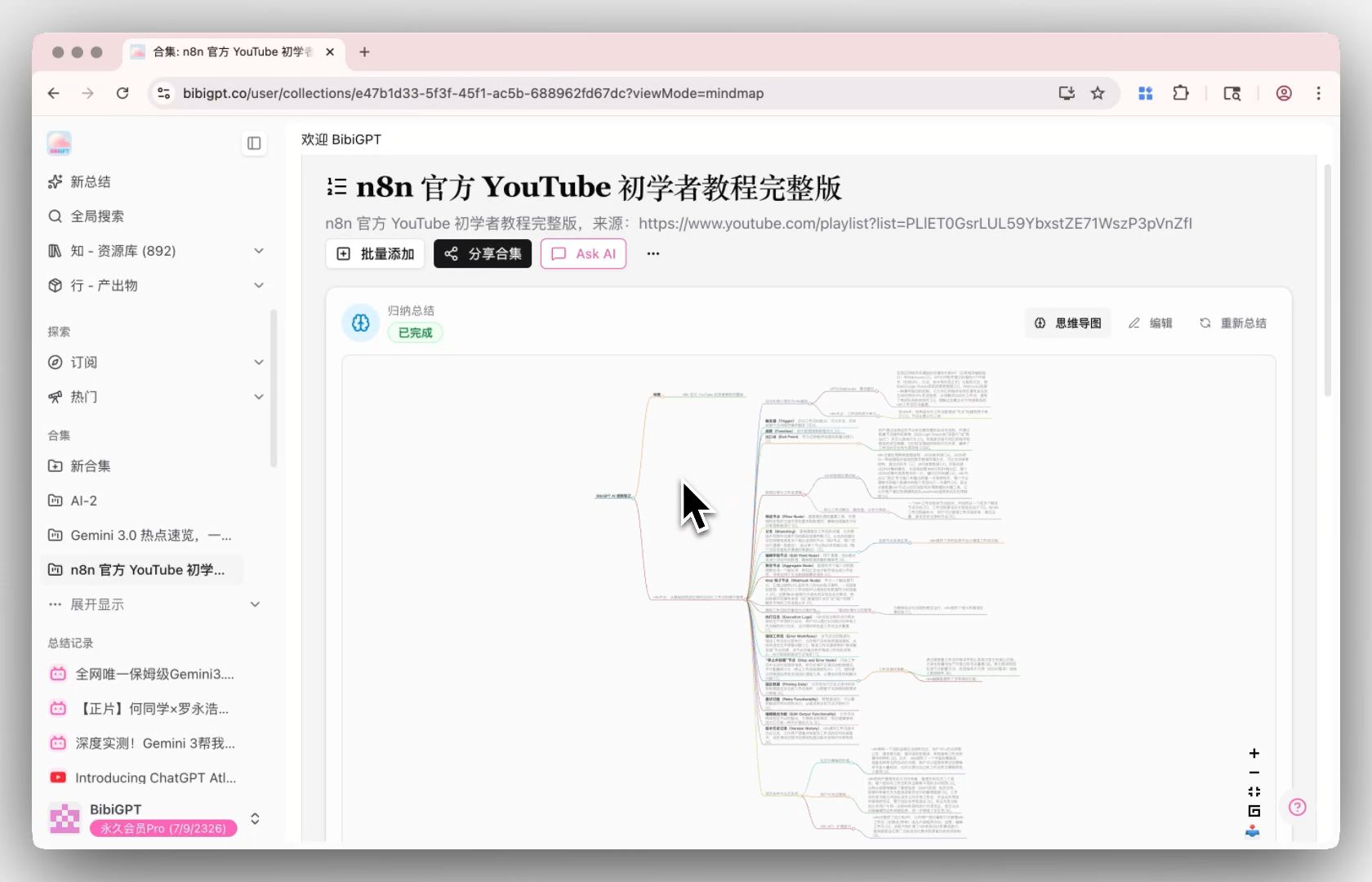
Étape 3 : Demander — Q&R inter-vidéos dans le chat IA sur collection
Le chat IA sur collection transforme plusieurs vidéos en une base de connaissances conversationnelle — Q&R inter-vidéos, comparaison, intégration. « À travers ces 10 conférences, où les instructeurs sont-ils en désaccord sur l’attention Transformer ? » prenait avant un après-midi de feuilletage de transcriptions. Maintenant c’est un seul prompt.
Workflow complet :
- Collez un lot de liens vidéo dans BibiGPT, laissez-le auto-transcrire + extraire les images-clés
- Ajoutez les vidéos à une collection, cliquez « Résumer maintenant »
- Demandez n’importe quoi dans le chat IA sur collection — les réponses s’intègrent à travers les vidéos
C’est essentiellement « du RAG multimodal, packagé pour l’utilisateur final ». Vous ne touchez pas à un store vectoriel, vous n’écrivez pas de logique de découpage — vous collez juste des liens.
Ce qui se passe dans les six prochains mois
- Les plateformes RAG tierces accélèrent l’adoption : attendez-vous à une vague de lancements « store vectoriel nativement multimodal » au S2 2026, tous bâtis sur Gemini Embedding 2 + un reranker propriétaire
- Une fracture générationnelle dure dans les outils de recherche vidéo : les produits encore sur ASR + embeddings texte font face à une attaque de déclassement ; le coût de migration est de réécrire tout le pipeline
- Le contenu long-tail est revalorisé : YouTube, Bilibili, les hébergeurs de podcasts pourraient commencer à facturer aux éditeurs RAG des « licences d’embedding » — une ligne d’affaires qui n’existait pas à l’ère du texte seul
FAQ
Q1 : Je peux déjà chercher dans les transcriptions BibiGPT — qu’apporte l’embedding multimodal ?
R : La recherche dans la transcription ne frappe que « ce qui a été dit ». L’embedding multimodal frappe « ce qui est montré » — un graphique jamais commenté, un fond musical, une formule sur une slide. Pour les vidéos lourdes en apprentissage ou en technique, la densité d’information à l’écran dépasse souvent ce que portent les sous-titres. La récupération multimodale fait remonter cette valeur cachée.
Q2 : L’API Gemini Embedding 2 est-elle chère ? Les utilisateurs BibiGPT ont-ils besoin de leur propre clé ?
R : Google a tarifé Gemini Embedding 2 dans le même tier que text-embedding-1 selon le changelog, facturé au token. BibiGPT câble déjà les modèles Gemini dans le sélecteur de modèles. Les utilisateurs occasionnels n’ont pas besoin d’apporter leur clé — la récupération multimodale est gérée côté serveur ; les utilisateurs voient les résultats de recherche.
Q3 : En quoi est-ce différent de monter mon propre Pinecone/Qdrant + embeddings OpenAI ?
R : Trois couches : (1) vous n’opérez pas de store vectoriel, (2) vous ne construisez pas le pipeline de découpage vidéo + extraction d’images-clés, (3) vous ne cousez pas trois API d’éditeurs en un résultat inter-modal. BibiGPT package les trois en un produit — l’entrée est une URL, la sortie est résumé + interrogeable + prêt pour le chat. Le DIY représente environ 2-3 semaines d’ingénierie ; BibiGPT est prêt à l’emploi.
Q4 : Quelle est la précision de la récupération multimodale ?
R : Selon les notes de lancement du changelog Google Gemini API, Gemini Embedding 2 améliore les benchmarks de récupération inter-modale d’environ 27 % par rapport à la génération précédente. Les tests internes BibiGPT montrent que la récupération conjointe « image + transcription » lève le rappel top-3 d’environ 35 % par rapport à la transcription seule — gains les plus forts sur les tutoriels techniques, conférences et démos produit.
Q5 : Dois-je retraiter mes anciennes vidéos dans BibiGPT pour obtenir la recherche multimodale ?
R : Non. L’extraction d’images-clés et la vectorisation tournent en arrière-plan en async. Le contenu ancien rentre dans le nouvel index automatiquement à mesure que la stack de récupération s’améliore. Les utilisateurs existants frappent en fait le nouvel index avant les nouvelles vidéos, donc les utilisateurs de longue date en bénéficient en premier.
Démarrer
- Déjà sur BibiGPT → ouvrez la recherche globale et essayez une requête à rappel flou
- Nouveau ici → Essayez BibiGPT — collez n’importe quel lien YouTube
- Utilisateur intensif → empilez résumé sur collection + chat IA sur collection pour faire de la récupération inter-vidéos une habitude quotidienne
BibiGPT Team