Gemini Embedding 2 chuyển sang đa phương thức: BibiGPT tận dụng tối đa tìm kiếm video & audio trong 2026
Gemini Embedding 2 chuyển sang đa phương thức: BibiGPT tận dụng tối đa tìm kiếm video & audio trong 2026
Tính đến 2026-04-29. Tất cả thông tin từ Google Gemini API Changelog chính thức.
Gemini Embedding 2 đạt GA vào 2026-04-22, mở rộng từ chỉ-text sang text/image/video/audio/PDF — tất cả chia sẻ cùng một không gian vector. Điều đó có nghĩa một truy vấn text duy nhất giờ có thể truy hồi xuyên qua khung video, đoạn audio và screenshot PDF mà không cần ba pipeline riêng. Đây chính xác là vấn đề tồn tại lâu nay “tôi nhớ video có nói điều này nhưng nó không có trong tóm tắt” mà BibiGPT đã giải quyết cho người dùng. Dưới đây: thực sự đã thay đổi gì, và quy trình ba bước của BibiGPT để khai thác khả năng mới ngay hôm nay.
Bối cảnh: 18 tháng từ embedding đơn phương thức sang đa phương thức
Google đã thăng hạng Gemini Embedding 2 từ preview lên GA vào 2026-04-22, kèm theo bản cập nhật API changelog. Kết hợp với thông báo chính thức, đây là dòng thời gian:
- 2024-08: Thế hệ đầu
text-embedding-004ra mắt, chỉ-text - 2025-09: Gemini Embedding 1 (text đa ngôn ngữ) GA, 100+ ngôn ngữ
- 2026-02: Gemini Embedding 2 vào preview, đa phương thức được preview
- 2026-04-22: Phát hành GA, hỗ trợ tự nhiên 5 phương thức trong cùng không gian vector
Đây là lần đầu tiên Google đặt embedding image/video/audio/PDF trong cùng một API và cùng không gian vector với text. Làm tìm kiếm video kiểu cũ nghĩa là ASR sang text, rồi vision model caption khung hình, rồi hai vector store hòa giải bằng reranker — ba pipeline, ba chiến lược chunk, ba dòng chi phí, và recall không bao giờ thực sự khớp. Gemini Embedding 2 gộp tất cả thành một lệnh gọi API.
Phân tích sâu: ba lớp tác động
Kỹ thuật: truy hồi xuyên phương thức trở thành vấn đề model, không phải vấn đề pipeline
Công sức kỹ thuật trong truy hồi video cũ là về “cách căn chỉnh video thành đơn vị có thể tìm kiếm.” Gemini Embedding 2 đẩy điều đó xuống lớp model:
| Phương pháp cũ | Gemini Embedding 2 |
|---|---|
| ASR → tóm tắt LLM → embedding text | Embed trực tiếp các đoạn audio |
| Vision model caption → embedding text | Embed trực tiếp các keyframe |
| Ba vector store riêng | Một không gian vector chung |
| Recall xuyên phương thức cần reranker | Cosine similarity tự nhiên có thể so sánh |
Tác động thực tế: độ trễ P95 cho “người dùng gõ một câu để tìm video” giảm từ phút xuống giây, và bạn không còn cần chép lời trước khi có thể bắt đầu truy hồi.
Thị trường: nhà cung cấp RAG đối mặt cửa sổ “viết lại đáy stack”
Trong 2025 hầu hết các nền tảng RAG vẫn giữ index text và image riêng. Gemini Embedding 2 làm cho “vector store đa phương thức tự nhiên” trở thành điều bắt buộc trong vòng sáu tháng. Nhà cung cấp làm đúng embedding đa phương thức trước sẽ giữ cửa sổ 12-18 tháng trên các sản phẩm truy hồi nội dung; những kẻ chậm chân sẽ buộc phải viết lại stack truy hồi trong nửa cuối 2026. Tốc độ trông giống hệt cách mọi sản phẩm phải gắn LLM sau GPT-4 năm 2023.
Hệ sinh thái: giá trị đuôi dài của các nền tảng nội dung được mở khóa
YouTube, Bilibili, mạng podcast đã tích lũy một thập kỷ video. Tổn thất giá trị lớn nhất không phải “không ai xem” mà là không ai có thể tìm kiếm chính xác. Gemini Embedding 2 lần đầu tiên làm cho “tôi nhớ một creator đã nhắc đến X khoảng phút 20” có thể truy hồi được. Đối với creator, traffic ngủ trên video cũ quay trở lại; đối với người tiêu dùng, “xem để học” không còn thụ động và trở thành dẫn dắt bởi truy vấn.
Điều này có ý nghĩa gì với người dùng BibiGPT
Cho creator: Khám phá lại video cũ
Chi tiết chưa bao giờ vào tóm tắt của bạn trở nên có thể tìm kiếm. Sau khi import một video vào BibiGPT, Tìm kiếm sâu toàn cục đã tấn công vào bản chép lời thô; xếp lớp embedding đa phương thức lên trên thêm truy hồi cấp khung — biểu đồ bạn đã hiển thị nhưng chưa bao giờ kể.
Cho sinh viên & nhà nghiên cứu: Đồ thị kiến thức xuyên video
Mười video khóa học, năm podcast, ba PDF handout — trước đây bạn đánh index riêng và hòa giải bằng tay. Quy trình Tóm tắt Collection + Collection AI Chat trong BibiGPT đã được xây quanh truy hồi xuyên nội dung. Embedding đa phương thức biến “tìm bài giảng nơi sơ đồ đó xuất hiện” từ xa xỉ thành thường lệ.
Cho doanh nghiệp: Tài sản video nội bộ trở nên có thể truy vấn
Ghi âm cuộc họp, video đào tạo, demo sản phẩm — về mặt lịch sử là kho hàng chết. Embedding đa phương thức + xử lý hàng loạt của BibiGPT có nghĩa cơ sở kiến thức nội bộ cuối cùng có thể bao trùm tài liệu, video và audio trong một tìm kiếm.
Quy trình BibiGPT: Tận dụng tối đa Gemini Embedding 2 trong ba bước
Bước 1: Nạp — Để BibiGPT tự chép lời & trích xuất keyframe
Dán link YouTube/Bilibili vào BibiGPT. Hệ thống tự chép lời, kéo keyframe và tạo tóm tắt có cấu trúc. Bước này xé một video dài thành đơn vị có thể tìm kiếm nhỏ nhất.
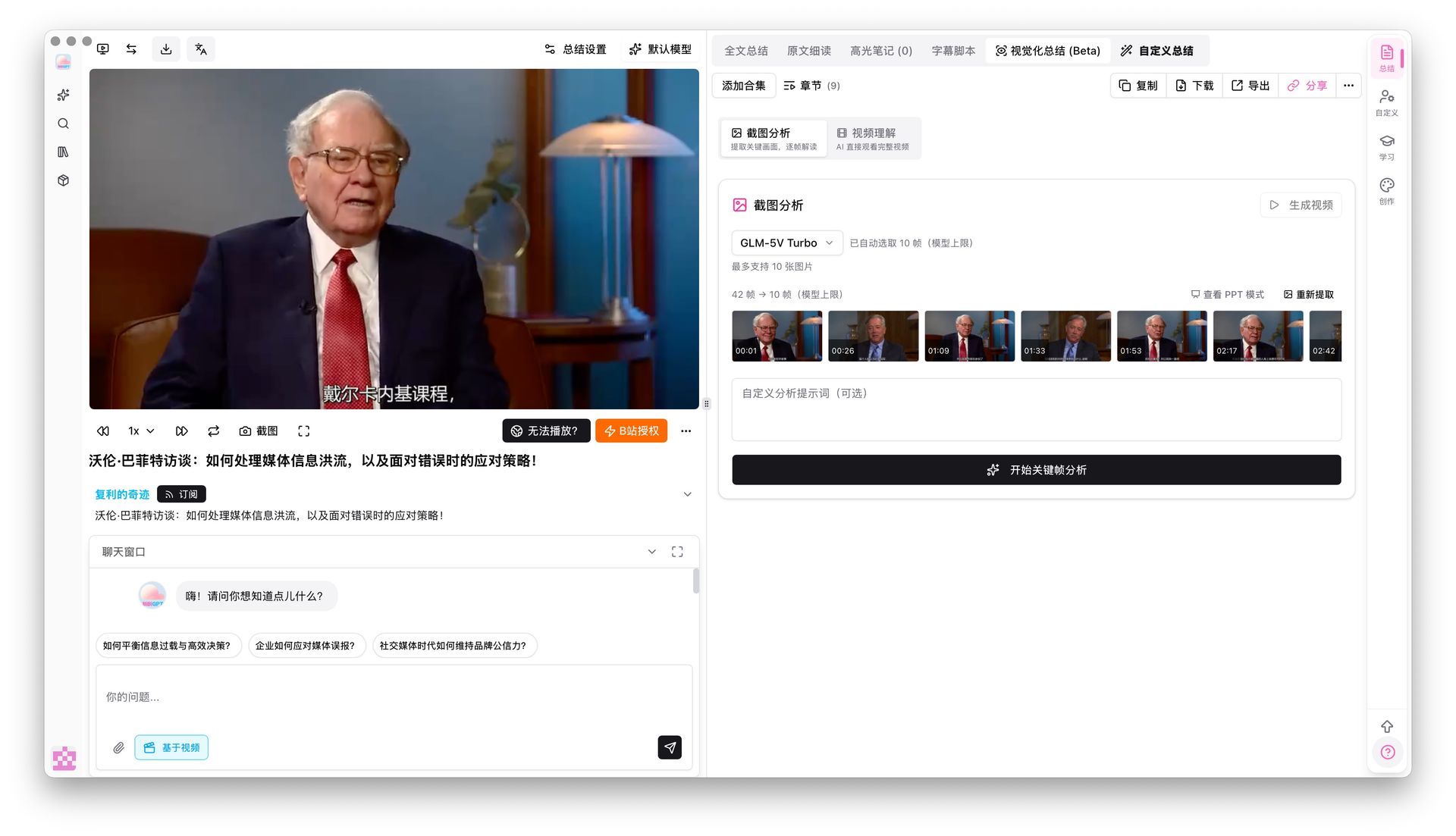
Phân tích screenshot keyframe đã hỗ trợ sáu vision model bao gồm Gemini 3.0 Flash và Qwen3.5 Omni Plus. Chúng hiểu biểu đồ, code block và nội dung slide trong khung — chính xác loại đầu vào mà embedding đa phương thức được thiết kế cho.
Bước 2: Tìm — Tìm kiếm sâu toàn cục + Collection AI Chat
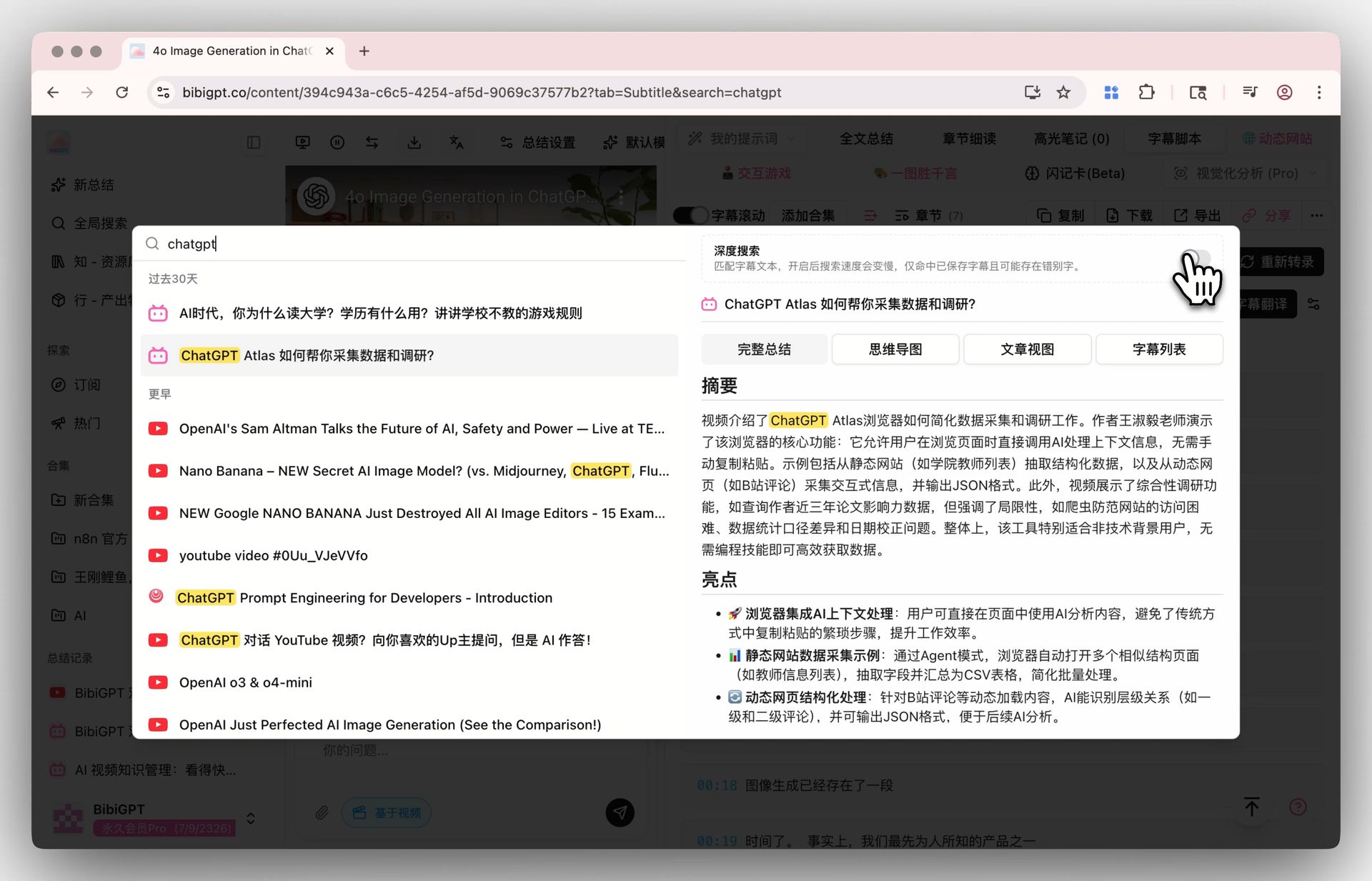
Bật toggle tìm kiếm sâu trong Tìm kiếm toàn cục và keyword của bạn tấn công vào bản chép lời thô, không chỉ tóm tắt AI. Kết hợp với Tóm tắt Collection để hợp nhất nhiều video thành một tổng quan có cấu trúc.
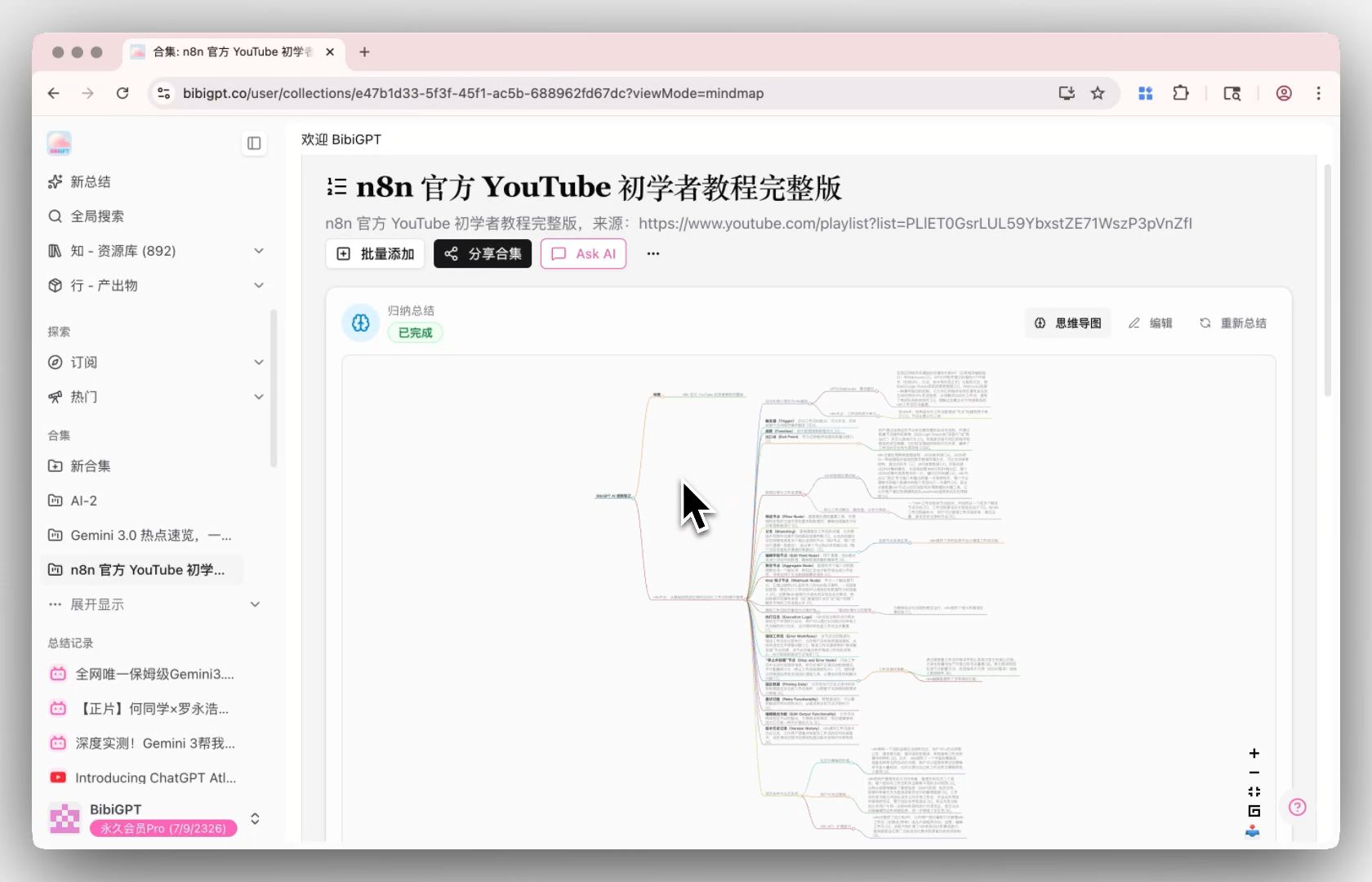
Bước 3: Hỏi — Hỏi đáp xuyên video trong Collection AI Chat
Collection AI Chat biến nhiều video thành một cơ sở kiến thức hội thoại — hỏi đáp xuyên video, so sánh, tích hợp. “Trong 10 bài giảng này, các giảng viên bất đồng ở đâu về attention của Transformer?” trước đây mất một buổi chiều lật bản chép lời. Giờ chỉ một prompt.
Quy trình đầy đủ:
- Dán một loạt link video vào BibiGPT, để nó tự chép lời + trích xuất keyframe
- Thêm video vào Collection, nhấn “Tóm tắt ngay”
- Hỏi bất cứ điều gì trong Collection AI Chat — câu trả lời tích hợp xuyên video
Đây thực chất là “RAG đa phương thức, đóng gói cho người dùng cuối.” Bạn không chạm vào vector store, không viết logic chunk — bạn chỉ dán link.
Điều gì xảy ra trong sáu tháng tới
- Nền tảng RAG bên thứ ba tăng tốc áp dụng: Mong đợi một làn sóng ra mắt “vector store đa phương thức tự nhiên” trong nửa cuối 2026, tất cả xây trên Gemini Embedding 2 + reranker độc quyền
- Phân chia thế hệ rõ rệt trong công cụ tìm kiếm video: Sản phẩm vẫn dựa vào ASR + embedding text đối mặt cuộc tấn công downgrade; chi phí migration là viết lại toàn bộ pipeline
- Nội dung đuôi dài được định giá lại: YouTube, Bilibili, host podcast có thể bắt đầu thu phí “embedding license” với nhà cung cấp RAG — một dòng kinh doanh không tồn tại trong kỷ nguyên chỉ-text
FAQ
Q1: Tôi đã có thể tìm kiếm bản chép lời trong BibiGPT — embedding đa phương thức thêm gì?
A: Tìm kiếm bản chép lời chỉ chạm “những gì được nói.” Embedding đa phương thức chạm “những gì được hiển thị” — biểu đồ chưa bao giờ được kể, một đoạn nhạc nền, công thức trên slide. Đối với video nặng học tập hay kỹ thuật, mật độ thông tin trên màn hình thường vượt qua những gì caption mang. Truy hồi đa phương thức làm nổi giá trị ẩn đó.
Q2: API Gemini Embedding 2 có đắt không? Người dùng BibiGPT có cần key riêng không?
A: Google định giá Gemini Embedding 2 cùng tier với text-embedding-1 theo changelog, tính theo token. BibiGPT đã tích hợp Gemini model vào bộ chọn model. Người dùng thông thường không cần BYOK — truy hồi đa phương thức được xử lý phía server; người dùng thấy kết quả tìm kiếm.
Q3: Điều này khác gì so với tự cuốn Pinecone/Qdrant + embedding OpenAI?
A: Ba lớp: (1) bạn không vận hành vector store, (2) bạn không xây pipeline chunk video + keyframe, (3) bạn không ghép ba API nhà cung cấp thành kết quả xuyên phương thức. BibiGPT đóng gói cả ba thành một sản phẩm — đầu vào là URL, đầu ra là tóm tắt + có thể tìm kiếm + sẵn sàng chat. DIY khoảng 2-3 tuần kỹ thuật; BibiGPT là sẵn sàng dùng ngay.
Q4: Truy hồi đa phương thức chính xác đến mức nào?
A: Theo ghi chú phát hành Google Gemini API Changelog, Gemini Embedding 2 cải thiện benchmark truy hồi xuyên phương thức khoảng 27% so với thế hệ trước. Test nội bộ BibiGPT cho thấy truy hồi liên kết “khung + bản chép lời” tăng top-3 recall ~35% so với chỉ-bản-chép-lời — gain mạnh nhất trên hướng dẫn kỹ thuật, bài giảng và demo sản phẩm.
Q5: Tôi có cần xử lý lại video cũ trong BibiGPT để có tìm kiếm đa phương thức không?
A: Không. Trích xuất keyframe và vector hóa chạy async trong nền. Nội dung cũ tự động cuộn vào index mới khi stack truy hồi nâng cấp. Người dùng hiện tại thực sự chạm index mới trước video mới, vì vậy người dùng lâu năm hưởng lợi trước.
Bắt đầu
- Đã trên BibiGPT → mở Tìm kiếm toàn cục và thử truy vấn fuzzy-recall
- Mới ở đây → Dùng thử BibiGPT — dán bất kỳ link YouTube
- Người dùng nội dung nặng → xếp chồng Tóm tắt Collection + Collection AI Chat để biến truy hồi xuyên video thành thói quen hàng ngày
BibiGPT Team