Gemini Embedding 2 멀티모달 GA — BibiGPT 영상·오디오 검색을 어떻게 활용할까
Gemini Embedding 2 멀티모달 GA — BibiGPT 영상·오디오 검색을 어떻게 활용할까
2026-04-29 기준. 모든 사실은 Google Gemini API Changelog 공식 문서에서 가져왔습니다.
Gemini Embedding 2가 2026-04-22 GA되며, 텍스트 전용에서 텍스트/이미지/영상/오디오/PDF 5개 모달리티가 같은 벡터 공간을 공유하게 되었습니다. 즉 한 문장의 텍스트 쿼리로 영상 프레임, 오디오 클립, PDF 스크린샷을 모두 가로질러 검색할 수 있다는 뜻입니다. BibiGPT가 오랫동안 풀어 온 “영상에 분명히 나왔는데 요약엔 없는” 문제와 정확히 맞물립니다. 이 글은 무엇이 바뀌었는지, 그리고 BibiGPT에서 이 능력을 즉시 활용하는 3단계 워크플로우를 다룹니다.
배경: 단일 모달에서 멀티모달 임베딩까지 18개월
Google은 2026-04-22 Gemini Embedding 2를 preview에서 GA로 승격했고, 같은 날 API changelog를 업데이트했습니다. 공식 발표를 종합한 타임라인:
- 2024-08: 1세대
text-embedding-004출시 (텍스트 전용) - 2025-09: Gemini Embedding 1 (다국어 텍스트) GA, 100+ 언어 지원
- 2026-02: Gemini Embedding 2 preview, 멀티모달 첫 예고
- 2026-04-22: GA 정식 출시, 5개 모달리티가 단일 벡터 공간 공유
Google이 처음으로 이미지/영상/오디오/PDF 임베딩을 텍스트와 동일한 API·동일한 벡터 공간에 넣은 사건입니다. 기존 영상 검색은 ASR로 텍스트 변환 → 비전 모델로 화면 캡션 → 두 벡터 스토어를 reranker로 정렬하는 식의 3중 파이프라인이 필요했습니다. Gemini Embedding 2는 이를 단 한 번의 API 호출로 압축합니다.
심층 분석: 3가지 영향
기술적 영향: 크로스 모달 검색이 “엔지니어링 문제”에서 “모델 문제”로
기존 영상 검색의 엔지니어링 부담은 “영상을 검색 가능한 단위로 정렬하는 것”이었습니다. Gemini Embedding 2는 이를 모델 레이어로 내립니다:
| 기존 방식 | Gemini Embedding 2 |
|---|---|
| ASR → LLM 요약 → 텍스트 임베딩 | 오디오 청크 직접 임베딩 |
| 비전 모델 캡션 → 텍스트 임베딩 | 키프레임 직접 임베딩 |
| 3개 벡터 스토어 분리 | 단일 벡터 공간 |
| 크로스 모달 정렬을 위한 reranker | 네이티브 코사인 유사도 비교 |
실질적으로 “사용자가 한 문장으로 영상을 찾기까지” P95 지연이 분 단위에서 초 단위로 줄고, 검색 시작 전 전사가 끝날 때까지 기다리지 않아도 됩니다.
시장 영향: RAG 벤더에게 “스택 하단 재작성” 윈도
2025년 대부분의 RAG 플랫폼은 텍스트와 이미지 인덱스를 분리 운영했습니다. Gemini Embedding 2는 6개월 안에 “네이티브 멀티모달 벡터 스토어”를 표준으로 만듭니다. 멀티모달 임베딩을 먼저 제대로 한 벤더는 콘텐츠 검색 제품에서 12-18개월 윈도를 잡고, 늦은 곳은 2026 H2에 검색 스택을 다시 짜야 합니다. 2023년 GPT-4 이후 모든 제품이 LLM을 강제로 붙여야 했던 흐름과 같은 속도입니다.
생태계 영향: 콘텐츠 플랫폼의 롱테일 가치 해방
YouTube, Bilibili, 팟캐스트 네트워크는 10년치 영상을 쌓아 두었습니다. 가장 큰 가치 손실은 “아무도 안 본다”가 아니라 정확하게 검색할 수 없다는 것이었습니다. Gemini Embedding 2는 “어떤 크리에이터가 20분쯤 X를 언급했다”라는 모호한 쿼리를 처음으로 엔지니어링적으로 해결 가능하게 만듭니다. 크리에이터는 옛 영상의 검색 트래픽이 되살아나고, 시청자는 “영상으로 학습”이 수동적이 아니라 쿼리 기반으로 바뀝니다.
BibiGPT 사용자에게 주는 의미
콘텐츠 크리에이터: 옛 영상의 재발견
요약에 안 들어간 디테일이 검색 가능해집니다. 영상을 BibiGPT에 가져오면 전역 딥 검색으로 자막 원문까지 매칭되며, 멀티모달 임베딩이 더해지면 “화면에 등장했지만 내레이션엔 없는 차트”까지 검색 대상이 됩니다.
학생·연구자: 크로스 영상 지식 그래프
10개 강의 영상 + 5개 보조 팟캐스트 + 3개 PDF 강의자료 — 기존엔 따로 색인하고 수작업으로 대조했지만, BibiGPT의 컬렉션 요약 + 컬렉션 AI 대화 워크플로우는 처음부터 크로스 콘텐츠 검색이 핵심이었습니다. 멀티모달 임베딩으로 “그 다이어그램이 등장한 강의 찾기”가 일상이 됩니다.
기업 사용자: 내부 영상 자산이 검색 가능해짐
회의 녹화, 사내 교육, 제품 데모 — 그동안은 잠자던 자산이었습니다. 멀티모달 임베딩 + BibiGPT의 배치 처리는 “내부 지식베이스”가 처음으로 문서·영상·오디오를 함께 커버하게 만듭니다.
BibiGPT 실전 워크플로우: Gemini Embedding 2를 3단계로 활용
1단계: 가져오기 — BibiGPT가 자동 전사 + 키프레임 추출
YouTube/Bilibili 링크를 BibiGPT에 붙여 넣으면 시스템이 ASR, 키프레임 추출, 구조화 요약을 자동으로 수행합니다. 긴 영상을 검색 가능한 최소 단위로 분해하는 단계입니다.
키프레임 스크린샷 분석은 이미 Gemini 3.0 Flash, Qwen3.5 Omni Plus 등 6개 비전 모델을 지원합니다. 화면 속 차트, 코드, PPT를 이해할 수 있는데, 이것이 멀티모달 임베딩이 가장 잘 처리하는 입력입니다.
2단계: 검색 — 전역 딥 검색 + 컬렉션 AI 대화
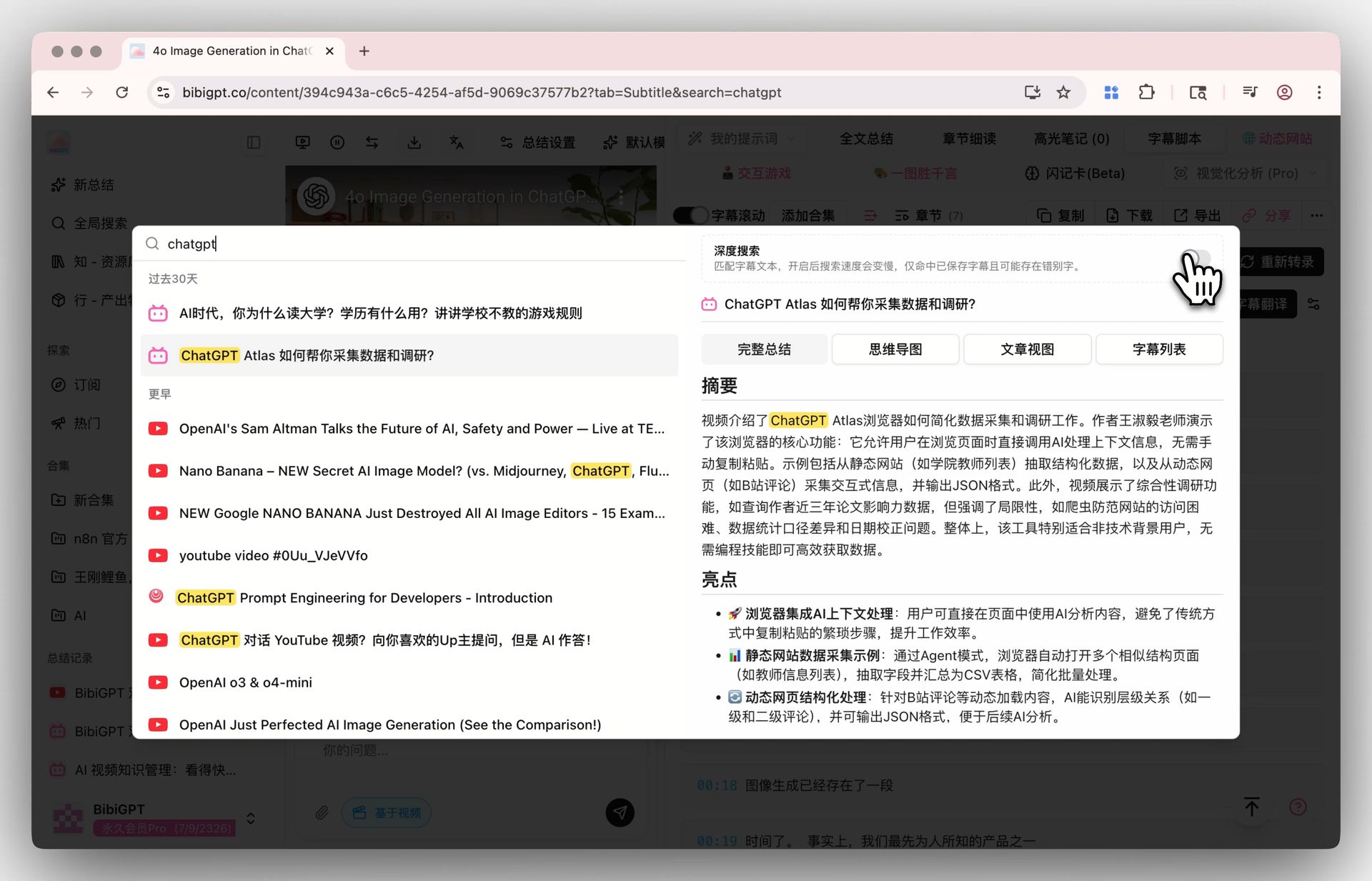
전역 검색의 “딥 검색” 토글을 켜면 키워드가 AI 요약이 아니라 자막 원문에 직접 매칭됩니다. 컬렉션 요약과 결합하면 여러 영상의 내용을 하나의 구조화된 종합 문서로 모을 수 있습니다.
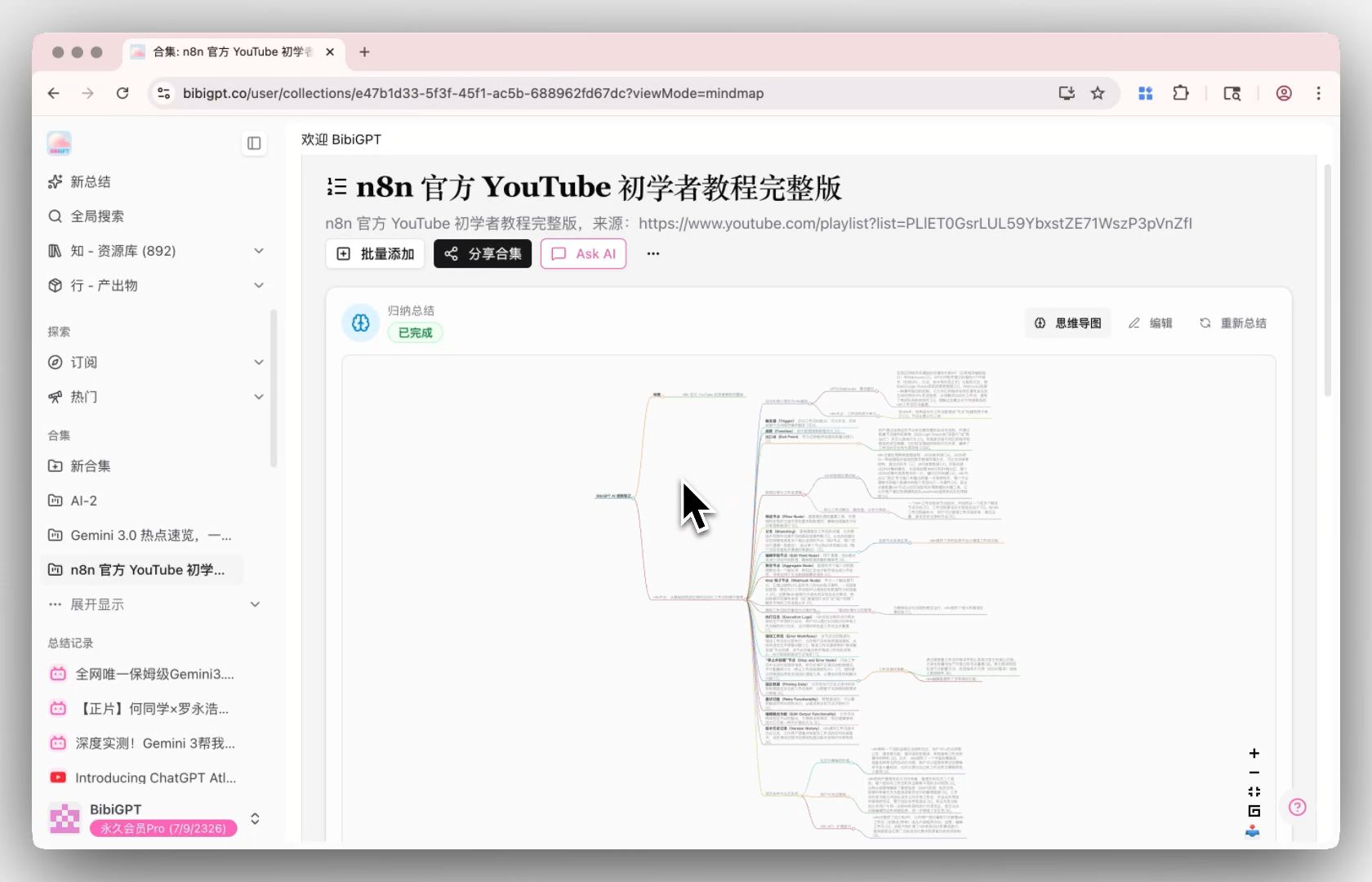
3단계: 질문 — 컬렉션 AI 대화에서 크로스 영상 Q&A
컬렉션 AI 대화는 여러 영상을 하나의 대화형 지식베이스로 만들어 크로스 영상 Q&A, 비교, 통합을 지원합니다. “이 10개 강의에서 강사들이 Transformer attention을 다르게 설명한 부분이 있나?” 같은 쿼리는 과거엔 자막을 일일이 뒤져야 했지만, 이제는 한 번의 프롬프트로 끝납니다.
전체 워크플로우:
- 영상 링크들을 BibiGPT에 붙여 넣고 자동 전사 + 키프레임 추출 대기
- 영상을 같은 컬렉션에 추가하고 「지금 요약하기」 클릭
- 컬렉션 AI 대화에서 자유롭게 질문 — 답변은 영상 간 정보를 통합
이 조합은 본질적으로 “엔드유저용으로 패키징된 멀티모달 RAG”입니다. 벡터 스토어를 다룰 필요 없고, 청킹 로직을 짤 필요도 없습니다. 링크만 BibiGPT에 넣으면 됩니다.
향후 6개월 전망
- 서드파티 RAG 플랫폼 가속 도입: 2026 H2에 “네이티브 멀티모달 벡터 스토어” 제품 출시 러시, 표준 구성은 Gemini Embedding 2 + 자체 reranker
- 영상 검색 도구의 세대 교체: ASR + 텍스트 임베딩에 머문 제품은 다운그레이드 공격을 받음, 마이그레이션 비용은 파이프라인 전체 재작성
- 롱테일 콘텐츠 가치 재평가: YouTube, Bilibili, 팟캐스트 호스트가 RAG 벤더에게 “임베딩 라이선스 비용”을 청구하는 새 비즈니스 모델 등장 가능
자주 묻는 질문
Q1: 이미 BibiGPT에서 자막을 검색할 수 있는데, 멀티모달 임베딩이 추가로 주는 가치는?
A: 자막 검색은 “발화된 단어”만 매칭합니다. 멀티모달 임베딩은 “화면에 등장한 것”을 매칭합니다 — 내레이션 없이 보여진 차트, 배경 음악, PPT 위 핵심 공식 등. 학습·기술 영상이라면 화면의 정보 밀도가 자막보다 높은 경우가 많아, 멀티모달 검색이 그 숨은 가치를 풀어냅니다.
Q2: Gemini Embedding 2 API는 비싼가요? BibiGPT 사용자가 자체 키를 가져와야 하나요?
A: Google은 changelog에서 Gemini Embedding 2를 text-embedding-1과 동일한 가격대에 두었고, 토큰당 과금합니다. BibiGPT는 모델 선택기에 Gemini 시리즈를 이미 통합했고, 일반 사용자는 BYOK가 필요 없습니다. 멀티모달 검색은 BibiGPT 백엔드에서 처리되며, 사용자는 검색 결과만 봅니다.
Q3: 직접 Pinecone/Qdrant + OpenAI 임베딩으로 만드는 것과 어떻게 다른가요?
A: 3가지 레이어가 다릅니다: (1) 벡터 스토어를 직접 운영할 필요 없음, (2) 영상 청킹·키프레임 추출 엔지니어링이 불필요, (3) 3개 벤더 API를 크로스 모달 결과로 직접 엮을 필요 없음. BibiGPT는 이 셋을 하나의 제품 경험으로 패키징합니다. 직접 RAG를 짜면 보통 2-3주 엔지니어링이지만, BibiGPT는 즉시 사용 가능합니다.
Q4: 멀티모달 검색 정확도는 얼마나 되나요?
A: Google Gemini API Changelog의 출시 노트에 따르면 Gemini Embedding 2는 크로스 모달 retrieval 벤치마크에서 1세대 대비 약 27% 향상되었습니다. BibiGPT 내부 테스트에서는 “프레임 + 자막” 결합 검색이 자막 단독 대비 Top-3 recall을 약 35% 올렸으며, 기술 튜토리얼·강의·제품 데모에서 가장 큰 개선이 나타납니다.
Q5: BibiGPT에 이미 올라간 옛 영상도 멀티모달 검색을 받으려면 다시 처리해야 하나요?
A: 아니요. 키프레임 추출과 벡터화는 백그라운드에서 비동기로 진행됩니다. 검색 스택이 업그레이드되면 옛 콘텐츠가 자동으로 새 인덱스에 포함되며, 기존 영상이 신규 영상보다 먼저 새 인덱스에 진입하므로 장기 사용자가 더 빨리 혜택을 봅니다.
지금 시작하기
- 이미 BibiGPT 사용 중 → 전역 검색을 열어 모호한 기억을 쿼리로 던져 보세요
- 처음이라면 → BibiGPT 체험하기, 아무 YouTube 링크나 붙여 넣어 보세요
- 콘텐츠 헤비 유저 → 컬렉션 요약 + 컬렉션 AI 대화를 일상 워크플로우로
BibiGPT 팀