Gemini Embedding 2 fica multimodal: como o BibiGPT maximiza a busca em vídeo e áudio em 2026
Gemini Embedding 2 fica multimodal: como o BibiGPT maximiza a busca em vídeo e áudio em 2026
Em 2026-04-29. Todos os fatos vêm do Google Gemini API Changelog oficial.
O Gemini Embedding 2 entrou em GA em 2026-04-22, expandindo de só texto para texto/imagem/vídeo/áudio/PDF — todos compartilhando o mesmo espaço vetorial. Isso significa que uma única consulta de texto agora pode recuperar entre frames de vídeo, clipes de áudio e capturas de PDF sem três pipelines separados. Esse é exatamente o problema antigo de “lembro que o vídeo disse isso, mas não está no resumo” que o BibiGPT vem resolvendo para os usuários. Abaixo: o que realmente mudou e o workflow de três passos do BibiGPT que coloca a nova capacidade para funcionar hoje.
Contexto: 18 meses de embeddings unimodais para multimodais
Google promoveu o Gemini Embedding 2 de preview para GA em 2026-04-22, acompanhado por uma atualização do API changelog. Combinado com o anúncio oficial, eis a linha do tempo:
- 2024-08: lançamento do
text-embedding-004de primeira geração, só texto - 2025-09: Gemini Embedding 1 (texto multilíngue) GA, 100+ idiomas
- 2026-02: Gemini Embedding 2 entra em preview, multimodal previewed
- 2026-04-22: lançamento GA, suporte nativo a 5 modalidades em espaço vetorial compartilhado
Esta é a primeira vez que o Google coloca embeddings de imagem/vídeo/áudio/PDF na mesma API e no mesmo espaço vetorial que texto. Fazer busca em vídeo da forma antiga significava ASR-para-texto, depois um modelo de visão legendando frames, depois dois vector stores reconciliados por um reranker — três pipelines, três estratégias de chunking, três linhas de custo, e recall que nunca casava direito. O Gemini Embedding 2 condensa isso em uma chamada de API.
Análise profunda: três camadas de impacto
Técnico: recuperação cross-modal vira problema de modelo, não de pipeline
O esforço de engenharia na recuperação de vídeo legada era sobre “como alinhar vídeo em uma unidade buscável”. O Gemini Embedding 2 empurra isso para a camada do modelo:
| Abordagem legada | Gemini Embedding 2 |
|---|---|
| ASR → resumo LLM → embedding de texto | Embed direto de chunks de áudio |
| Caption do modelo de visão → embedding de texto | Embed direto de keyframes |
| Três vector stores separados | Um espaço vetorial compartilhado |
| Recall cross-modal precisa de reranker | Similaridade de cosseno nativa é comparável |
Impacto prático: a latência P95 para “usuário digita uma frase para encontrar um vídeo” cai de minutos para segundos, e você não precisa mais transcrever antes de começar a recuperar.
Mercado: vendors RAG enfrentam uma janela de “reescrever a base do stack”
Em 2025 a maioria das plataformas RAG ainda mantinha índices de texto e imagem separados. O Gemini Embedding 2 torna “vector store nativamente multimodal” o padrão dentro de seis meses. Vendors que acertarem o embedding multimodal primeiro vão segurar uma janela de 12-18 meses em produtos de recuperação de conteúdo; os atrasados serão forçados a reescrever o stack de recuperação no segundo semestre de 2026. O ritmo parece idêntico ao de como todo produto teve que adicionar LLMs à força após o GPT-4 em 2023.
Ecossistema: o valor de cauda longa de plataformas de conteúdo é destravado
YouTube, Bilibili, redes de podcast acumularam uma década de vídeo. A maior perda de valor não é “ninguém assiste” mas ninguém consegue buscar com precisão. O Gemini Embedding 2 torna “lembro que um criador mencionou X por volta do minuto 20” recuperável pela primeira vez. Para criadores, tráfego dormente em vídeos antigos volta; para consumidores, “assistir para aprender” deixa de ser passivo e vira orientado por consulta.
O que isso significa para usuários do BibiGPT
Para criadores: vídeos antigos redescobertos
Detalhes que nunca entraram no seu resumo se tornam buscáveis. Depois de importar um vídeo no BibiGPT, a Busca Profunda Global já bate em transcrições brutas; sobrepor embedding multimodal adiciona recuperação em nível de frame — o gráfico que você mostrou mas nunca narrou.
Para estudantes e pesquisadores: grafos de conhecimento entre vídeos
Dez vídeos de curso, cinco podcasts, três PDFs de apoio — antes você indexava separado e reconciliava à mão. O workflow Resumo da Coleção + Chat de IA da Coleção dentro do BibiGPT já era construído em torno da recuperação entre conteúdos. Embeddings multimodais transformam “encontre a aula onde aquele diagrama apareceu” de luxo em rotina.
Para empresas: ativos de vídeo internos se tornam consultáveis
Gravações de reunião, vídeos de treinamento, demos de produto — historicamente estoque morto. Embeddings multimodais + processamento em lote do BibiGPT significam que uma base de conhecimento interna finalmente pode cobrir documentos, vídeo e áudio em uma busca.
Workflow BibiGPT: maximizando o Gemini Embedding 2 em três passos
Passo 1: ingestão — deixe o BibiGPT auto-transcrever e extrair keyframes
Cole um link YouTube/Bilibili no BibiGPT. O sistema auto-transcreve, extrai keyframes e produz um resumo estruturado. Este passo fragmenta um vídeo longo na menor unidade buscável.
A Análise de Captura de Keyframes já suporta seis modelos de visão, incluindo Gemini 3.0 Flash e Qwen3.5 Omni Plus. Eles entendem gráficos, blocos de código e conteúdo de slides dentro do frame — exatamente o tipo de input para o qual embeddings multimodais foram projetados.
Passo 2: busca — Busca Profunda Global + Chat de IA da Coleção
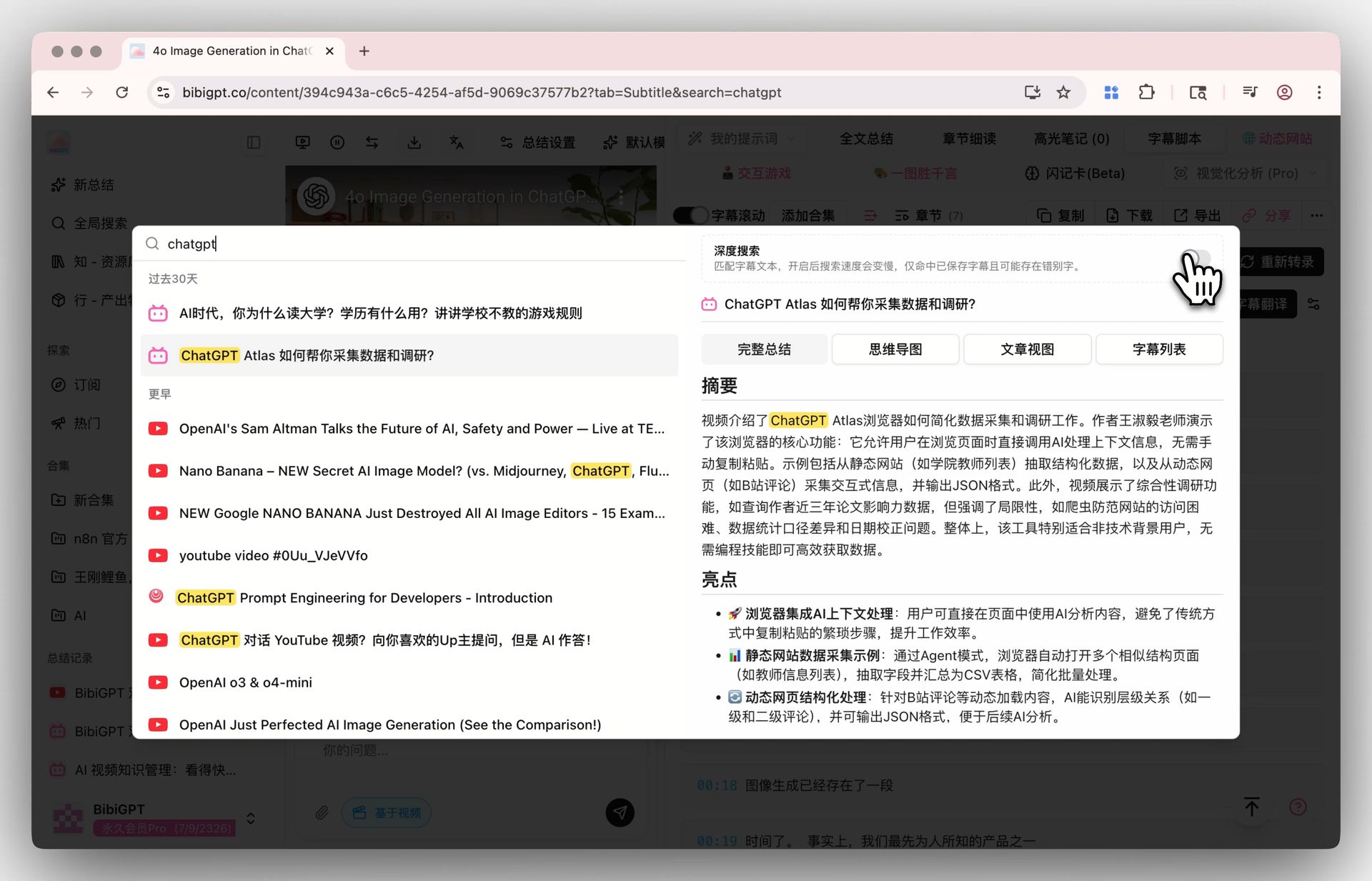
Acione o toggle de busca profunda na Busca Global e sua palavra-chave bate na transcrição bruta, não só nos resumos com IA. Combine com Resumo da Coleção para consolidar múltiplos vídeos em uma visão estruturada.
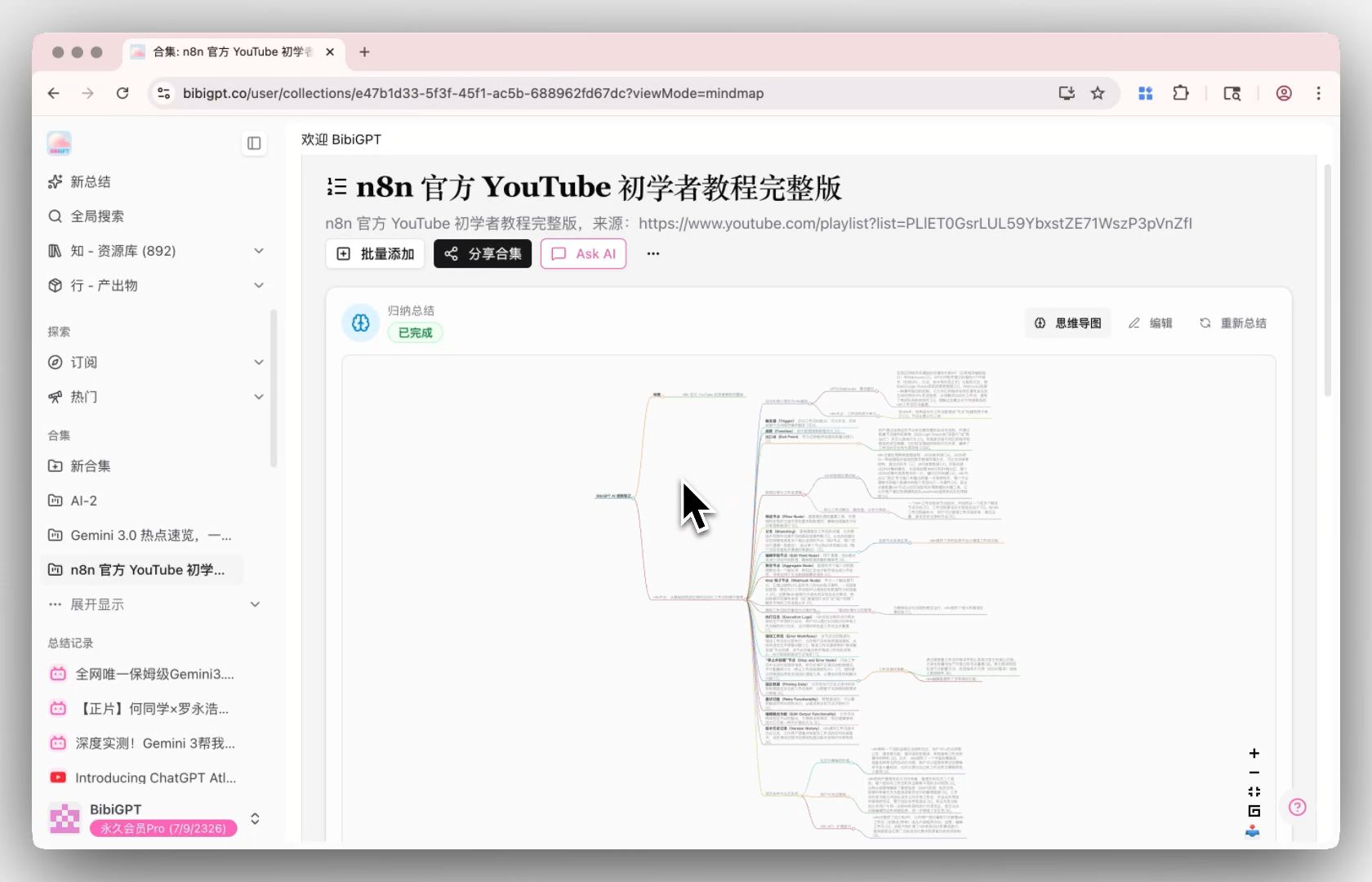
Passo 3: pergunte — perguntas entre vídeos no Chat de IA da Coleção
O Chat de IA da Coleção transforma múltiplos vídeos em uma base de conhecimento conversacional — perguntas entre vídeos, comparação, integração. “Entre estas 10 aulas, onde os instrutores discordam sobre atenção em Transformer?” antes levava uma tarde folheando transcrições. Agora é um prompt.
Workflow completo:
- Cole um lote de links de vídeo no BibiGPT, deixe-o auto-transcrever + extrair keyframes
- Adicione os vídeos a uma Coleção, clique em “Resumir Agora”
- Pergunte qualquer coisa no Chat de IA da Coleção — respostas integram entre vídeos
Isso é essencialmente “RAG multimodal, empacotado para usuário final”. Você não toca em vector store, não escreve lógica de chunking — apenas cola links.
O que acontece nos próximos seis meses
- Plataformas RAG de terceiros aceleram a adoção: espere uma onda de lançamentos de “vector store nativamente multimodal” no segundo semestre de 2026, todos construídos sobre Gemini Embedding 2 + um reranker proprietário
- Uma divisão geracional dura em ferramentas de busca em vídeo: produtos ainda em ASR + embeddings de texto enfrentam um ataque de downgrade; o custo de migração é reescrever o pipeline inteiro
- Conteúdo de cauda longa é reprecificado: YouTube, Bilibili, hosts de podcast podem começar a cobrar de vendors RAG “licenças de embedding” — uma linha de negócio que não existia na era apenas-texto
FAQ
Q1: Já posso buscar transcrições no BibiGPT — o que o embedding multimodal adiciona?
A: Busca em transcrição só bate em “o que foi falado”. Embedding multimodal bate em “o que é mostrado” — um gráfico nunca narrado, uma música de fundo, uma fórmula em um slide. Para vídeos pesados em aprendizagem ou técnica, a densidade de informação na tela frequentemente excede o que as legendas carregam. Recuperação multimodal traz à tona esse valor escondido.
Q2: A API do Gemini Embedding 2 é cara? Usuários do BibiGPT precisam ter sua própria chave?
A: O Google precificou o Gemini Embedding 2 no mesmo tier do text-embedding-1, conforme o changelog, cobrado por token. O BibiGPT já cabeia modelos Gemini no seletor de modelo. Usuários casuais não precisam de BYOK — recuperação multimodal é tratada no servidor; usuários veem resultados de busca.
Q3: Como isso difere de rolar meu próprio Pinecone/Qdrant + embeddings da OpenAI?
A: Três camadas: (1) você não opera um vector store, (2) você não constrói o pipeline de chunking de vídeo + keyframes, (3) você não costura três APIs de fornecedores em um resultado cross-modal. O BibiGPT empacota os três em um produto — input é uma URL, output é resumo + buscável + pronto para chat. DIY é cerca de 2-3 semanas de engenharia; o BibiGPT é pronto para uso.
Q4: Qual a precisão da recuperação multimodal?
A: Conforme as notas de lançamento do Google Gemini API Changelog, o Gemini Embedding 2 melhora benchmarks de recuperação cross-modal em cerca de 27% em relação à geração anterior. Testes internos do BibiGPT mostram que recuperação conjunta “frame + transcrição” eleva o recall top-3 em ~35% versus apenas transcrição — ganhos mais fortes em tutoriais técnicos, aulas e demos de produto.
Q5: Preciso reprocessar meus vídeos antigos no BibiGPT para ter busca multimodal?
A: Não. Extração de keyframes e vetorização rodam de forma assíncrona em background. Conteúdo antigo entra no novo índice automaticamente conforme o stack de recuperação é atualizado. Usuários existentes na verdade entram no novo índice antes dos vídeos novos, então usuários antigos se beneficiam primeiro.
Comece
- Já está no BibiGPT → abra a Busca Global e teste uma consulta de recall difuso
- Novo por aqui → Experimente o BibiGPT — cole qualquer link do YouTube
- Usuário intensivo de conteúdo → empilhe Resumo da Coleção + Chat de IA da Coleção para tornar a recuperação entre vídeos um hábito diário
BibiGPT Team