Gemini Embedding 2 se vuelve multimodal: cómo BibiGPT exprime la búsqueda de video y audio en 2026
Gemini Embedding 2 se vuelve multimodal: cómo BibiGPT exprime la búsqueda de video y audio en 2026
A fecha 2026-04-29. Todos los datos provienen del changelog oficial de la Google Gemini API.
Gemini Embedding 2 llegó a GA el 2026-04-22, expandiéndose de solo texto a texto/imagen/video/audio/PDF — todo compartiendo el mismo espacio vectorial. Eso significa que una sola consulta de texto ahora puede recuperar entre fotogramas de video, clips de audio y capturas de PDF sin tres pipelines separados. Este es exactamente el problema histórico de “recuerdo que el video decía esto pero no está en el resumen” que BibiGPT viene resolviendo. A continuación: qué cambió de verdad y el flujo de tres pasos de BibiGPT que pone a trabajar la nueva capacidad hoy.
Contexto: 18 meses de embeddings unimodales a multimodales
Google promovió Gemini Embedding 2 de preview a GA el 2026-04-22, acompañado de una actualización del changelog de la API. Combinado con el anuncio oficial, la línea de tiempo:
- 2024-08: Llega
text-embedding-004de primera generación, solo texto - 2025-09: Gemini Embedding 1 (texto multilingüe) GA, 100+ idiomas
- 2026-02: Gemini Embedding 2 entra en preview, multimodalidad en preview
- 2026-04-22: Lanzamiento GA, soporte nativo para 5 modalidades en un espacio vectorial compartido
Es la primera vez que Google pone embeddings de imagen/video/audio/PDF en la misma API y el mismo espacio vectorial que el texto. Hacer búsqueda de video al estilo viejo significaba ASR a texto, luego un modelo de visión etiquetando fotogramas, después dos vector stores reconciliados por un reranker — tres pipelines, tres estrategias de chunking, tres líneas de costo y un recall que nunca cuadraba del todo. Gemini Embedding 2 colapsa todo eso en una llamada API.
Análisis profundo: tres capas de impacto
Técnico: la recuperación cross-modal pasa de problema de pipeline a problema de modelo
El esfuerzo de ingeniería en la recuperación de video legado giraba en torno a “cómo alinear video en una unidad buscable”. Gemini Embedding 2 empuja eso hacia abajo, a la capa del modelo:
| Enfoque legado | Gemini Embedding 2 |
|---|---|
| ASR → resumen LLM → embedding de texto | Embeddear chunks de audio directamente |
| Caption de modelo de visión → embedding de texto | Embeddear fotogramas clave directamente |
| Tres vector stores separados | Un espacio vectorial compartido |
| El recall cross-modal necesita reranker | La similitud coseno nativa es comparable |
Impacto práctico: la latencia P95 para “el usuario escribe una frase para encontrar un video” cae de minutos a segundos, y ya no necesitas transcribir antes de poder empezar a recuperar.
Mercado: los proveedores de RAG enfrentan una ventana de “reescribir el fondo del stack”
En 2025 la mayoría de plataformas RAG aún mantenían índices de texto e imagen separados. Gemini Embedding 2 convierte el “vector store nativamente multimodal” en mínimo de mercado en seis meses. Los proveedores que clavan primero el embedding multimodal mantendrán una ventana de 12-18 meses sobre productos de recuperación de contenido; los rezagados se verán forzados a reescribir su stack de recuperación en H2 de 2026. El ritmo se ve idéntico a cómo cada producto tuvo que empotrar LLMs después de GPT-4 en 2023.
Ecosistema: el valor de cola larga de las plataformas de contenido se desbloquea
YouTube, Bilibili y las redes de podcast han acumulado una década de video. La mayor pérdida de valor no es “nadie lo ve”, es nadie puede buscarlo con precisión. Gemini Embedding 2 hace que “recuerdo que un creador mencionó X cerca del minuto 20” sea recuperable por primera vez. Para creadores, el tráfico latente sobre videos viejos vuelve; para consumidores, “ver para aprender” deja de ser pasivo y se vuelve dirigido por consultas.
Qué significa esto para los usuarios de BibiGPT
Para creadores: videos viejos redescubiertos
Detalles que nunca llegaron a tu resumen se vuelven buscables. Tras importar un video a BibiGPT, Global Deep Search ya golpea las transcripciones crudas; superponer embedding multimodal añade recuperación a nivel de fotograma — el gráfico que mostraste pero nunca narraste.
Para estudiantes e investigadores: grafos de conocimiento entre videos
Diez videos de curso, cinco podcasts, tres handouts en PDF — antes los indexabas por separado y los reconciliabas a mano. El flujo de Collection Summary + Collection AI Chat dentro de BibiGPT ya estaba construido en torno a la recuperación entre contenidos. Los embeddings multimodales convierten “encuentra la clase donde apareció ese diagrama” de lujo en rutina.
Para empresas: los activos internos de video se vuelven consultables
Grabaciones de reuniones, videos de capacitación, demos de producto — históricamente inventario muerto. Embeddings multimodales + procesamiento masivo de BibiGPT significan que una base de conocimiento interna por fin puede cubrir documentos, video y audio en una sola búsqueda.
Flujo BibiGPT: exprimir Gemini Embedding 2 en tres pasos
Paso 1: Ingestar — Deja que BibiGPT auto-transcriba y extraiga fotogramas clave
Pega un enlace de YouTube/Bilibili en BibiGPT. El sistema auto-transcribe, extrae fotogramas clave y produce un resumen estructurado. Este paso trocea un video largo en la unidad buscable más pequeña.
Keyframe Screenshot Analysis ya soporta seis modelos de visión incluyendo Gemini 3.0 Flash y Qwen3.5 Omni Plus. Entienden gráficos, bloques de código y contenido de slides dentro del fotograma — exactamente el tipo de input para el que se diseñaron los embeddings multimodales.
Paso 2: Buscar — Global Deep Search + Collection AI Chat
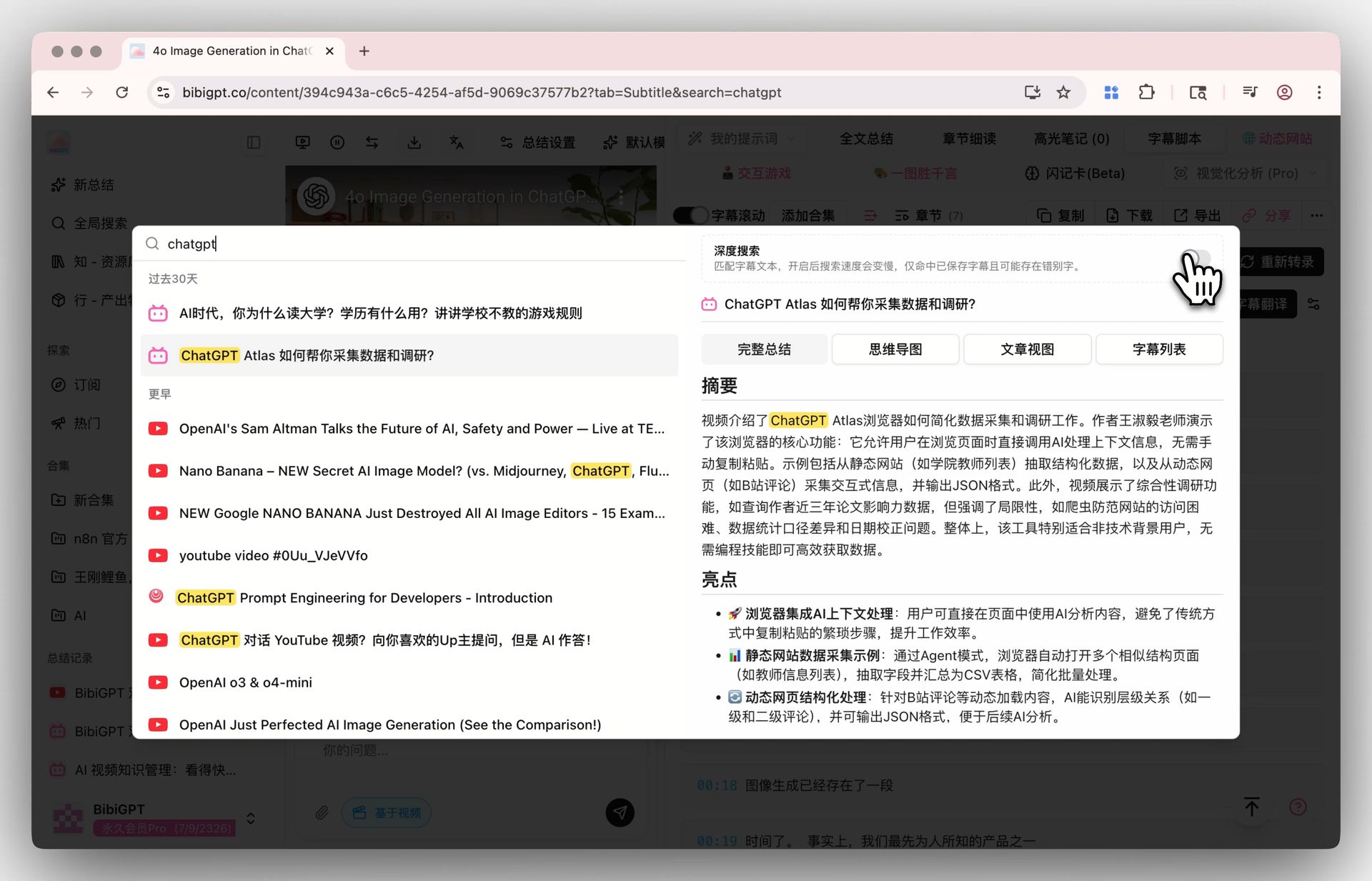
Activa el toggle de deep search en Global Search y tu palabra clave golpea la transcripción cruda, no solo los resúmenes de IA. Combínalo con Collection Summary para consolidar múltiples videos en una visión estructurada.
Paso 3: Preguntar — Q&A entre videos en Collection AI Chat
Collection AI Chat convierte múltiples videos en una base de conocimiento conversacional — Q&A entre videos, comparación, integración. “Entre estas 10 clases, ¿dónde discrepan los instructores sobre la atención en Transformers?” antes tomaba una tarde de hojear transcripciones. Ahora es un solo prompt.
Flujo completo:
- Pega un lote de enlaces de video en BibiGPT, deja que auto-transcriba + extraiga fotogramas
- Añade los videos a una Colección, pulsa “Resumir ahora”
- Pregunta lo que quieras en Collection AI Chat — las respuestas integran entre videos
Esto es esencialmente “RAG multimodal, empaquetado para usuarios finales”. No tocas un vector store, no escribes lógica de chunking — solo pegas enlaces.
Qué pasa en los próximos seis meses
- Las plataformas RAG de terceros aceleran la adopción: espera una ola de lanzamientos de “vector store nativamente multimodal” en H2 de 2026, todos construidos sobre Gemini Embedding 2 + un reranker propio
- Una división generacional dura en herramientas de búsqueda de video: los productos aún en ASR + embeddings de texto enfrentan un ataque de degradación; el costo de migración es reescribir el pipeline entero
- El contenido de cola larga se reprecia: YouTube, Bilibili, hosts de podcast podrían empezar a cobrar a los proveedores de RAG “licencias de embedding” — una línea de negocio que no existía en la era de solo texto
FAQ
Q1: Ya puedo buscar transcripciones en BibiGPT — ¿qué añade el embedding multimodal?
A: La búsqueda de transcripción solo golpea “lo que se habló”. El embedding multimodal golpea “lo que se muestra” — un gráfico nunca narrado, una pieza de música de fondo, una fórmula en una slide. Para videos de aprendizaje o técnicos, la densidad de información en pantalla suele exceder lo que llevan los subtítulos. La recuperación multimodal saca a flote ese valor oculto.
Q2: ¿Es cara la API de Gemini Embedding 2? ¿Necesitan los usuarios de BibiGPT su propia key?
A: Google fijó el precio de Gemini Embedding 2 en el mismo tier que text-embedding-1 según el changelog, facturado por token. BibiGPT ya conecta los modelos Gemini en el selector de modelo. Los usuarios casuales no necesitan BYOK — la recuperación multimodal se maneja del lado servidor; los usuarios ven los resultados de búsqueda.
Q3: ¿En qué se diferencia esto de montar mi propio Pinecone/Qdrant + embeddings de OpenAI?
A: Tres capas: (1) no operas un vector store, (2) no construyes el pipeline de chunking de video + fotogramas clave, (3) no coses tres APIs de proveedores en un resultado cross-modal. BibiGPT empaqueta las tres en un producto — input es una URL, output es resumen + buscable + listo para chat. DIY son aproximadamente 2-3 semanas de ingeniería; BibiGPT es plug and play.
Q4: ¿Qué tan precisa es la recuperación multimodal?
A: Según las notas de lanzamiento del Google Gemini API Changelog, Gemini Embedding 2 mejora los benchmarks de recuperación cross-modal en aproximadamente 27% sobre la generación previa. Pruebas internas de BibiGPT muestran que la recuperación conjunta “fotograma + transcripción” eleva el recall top-3 en ~35% frente a solo transcripción — las mayores ganancias en tutoriales técnicos, clases y demos de producto.
Q5: ¿Necesito reprocesar mis videos viejos en BibiGPT para obtener búsqueda multimodal?
A: No. La extracción de fotogramas clave y la vectorización corren async en segundo plano. El contenido viejo entra al nuevo índice automáticamente conforme el stack de recuperación se actualiza. Los usuarios existentes en realidad golpean el nuevo índice antes que los videos nuevos, así que los usuarios de larga data se benefician primero.
Empieza
- Ya estás en BibiGPT → abre Global Search y prueba una consulta de fuzzy-recall
- Recién llegado → prueba BibiGPT — pega cualquier enlace de YouTube
- Usuario intensivo de contenido → apila Collection Summary + Collection AI Chat para hacer de la recuperación entre videos un hábito diario
BibiGPT Team