Gemini Embedding 2 wird multimodal: Wie BibiGPT Video- und Audio-Suche 2026 ausreizt
Gemini Embedding 2 wird multimodal: Wie BibiGPT Video- und Audio-Suche 2026 ausreizt
Stand 29.04.2026. Alle Fakten basieren auf dem offiziellen Google Gemini API Changelog.
Gemini Embedding 2 erreichte am 22.04.2026 GA und erweitert sich von reinem Text auf Text/Bild/Video/Audio/PDF — alle teilen denselben Vektorraum. Das bedeutet, eine einzige Textanfrage kann jetzt über Videoframes, Audioclips und PDF-Screenshots hinweg abrufen, ohne drei separate Pipelines. Das ist genau das langjährige Problem „Ich erinnere mich, dass das Video das gesagt hat, aber es ist nicht in der Zusammenfassung“, das BibiGPT für Nutzer löst. Im Folgenden: was sich tatsächlich geändert hat und der drei-Schritte-BibiGPT-Workflow, der die neue Fähigkeit heute zur Anwendung bringt.
Hintergrund: 18 Monate von Single-Modal zu multimodalen Embeddings
Google hat Gemini Embedding 2 am 22.04.2026 von Preview auf GA hochgestuft, begleitet von einem API-Changelog-Update. Kombiniert mit der offiziellen Ankündigung ergibt sich folgender Zeitstrahl:
- 08.2024: Erste Generation
text-embedding-004ausgeliefert, nur Text - 09.2025: Gemini Embedding 1 (mehrsprachiger Text) GA, 100+ Sprachen
- 02.2026: Gemini Embedding 2 in Preview, multimodal angekündigt
- 22.04.2026: GA-Veröffentlichung, native Unterstützung für 5 Modalitäten in einem gemeinsamen Vektorraum
Das ist das erste Mal, dass Google Bild-/Video-/Audio-/PDF-Embeddings in dieselbe API und denselben Vektorraum wie Text gesteckt hat. Videosuche im alten Stil bedeutete ASR-zu-Text, dann Vision-Modell zur Caption-Erstellung von Frames, dann zwei Vektor-Stores, abgeglichen durch einen Reranker — drei Pipelines, drei Chunking-Strategien, drei Kostenpositionen, und ein Recall, der nie ganz übereinstimmte. Gemini Embedding 2 fasst das in einen einzigen API-Aufruf zusammen.
Tiefenanalyse: Drei Wirkungsebenen
Technisch: Cross-Modal Retrieval wird ein Modell-Problem, kein Pipeline-Problem
Der Engineering-Aufwand bei klassischer Video-Retrieval ging um „wie man Video in eine durchsuchbare Einheit ausrichtet“. Gemini Embedding 2 schiebt das in die Modellebene:
| Klassischer Ansatz | Gemini Embedding 2 |
|---|---|
| ASR → LLM-Zusammenfassung → Text-Embedding | Audio-Chunks direkt einbetten |
| Vision-Modell-Caption → Text-Embedding | Keyframes direkt einbetten |
| Drei separate Vektor-Stores | Ein gemeinsamer Vektorraum |
| Cross-Modal-Recall braucht Reranker | Native Cosinus-Ähnlichkeit ist vergleichbar |
Praktische Auswirkung: P95-Latenz für „Nutzer tippt einen Satz, um ein Video zu finden“ sinkt von Minuten auf Sekunden, und Sie müssen nicht mehr transkribieren, bevor Sie mit dem Abrufen beginnen können.
Markt: RAG-Anbieter stehen vor einem „Stack-Boden neu schreiben“-Fenster
2025 hielten die meisten RAG-Plattformen Text- und Bild-Indizes noch getrennt. Gemini Embedding 2 macht „nativ multimodalen Vektor-Store“ innerhalb von sechs Monaten zur Pflicht. Anbieter, die multimodales Embedding zuerst richtig hinbekommen, halten ein 12-18-monatiges Fenster bei Content-Retrieval-Produkten; die Nachzügler werden gezwungen sein, ihren Retrieval-Stack im 2. Halbjahr 2026 neu zu schreiben. Das Tempo wirkt identisch zu der Art, wie jedes Produkt nach GPT-4 in 2023 LLMs nachrüsten musste.
Ökosystem: Der Long-Tail-Wert von Content-Plattformen wird freigeschaltet
YouTube, Bilibili, Podcast-Netzwerke haben ein Jahrzehnt Video angehäuft. Der größte Wertverlust ist nicht „niemand schaut“, sondern niemand kann präzise suchen. Gemini Embedding 2 macht „Ich erinnere mich, dass ein Creator X um Minute 20 erwähnte“ zum ersten Mal abrufbar. Für Creators kommt der schlummernde Traffic auf alten Videos zurück; für Konsumenten hört „Ansehen zum Lernen“ auf, passiv zu sein, und wird abfragegetrieben.
Was das für BibiGPT-Nutzer bedeutet
Für Creators: Alte Videos wiederentdeckt
Details, die nie in Ihre Zusammenfassung gelangten, werden durchsuchbar. Nach dem Importieren eines Videos in BibiGPT trifft die Globale Tiefensuche bereits Roh-Transkripte; das Aufschichten von multimodalem Embedding fügt Frame-Level-Retrieval hinzu — das Diagramm, das Sie zeigten, aber nie erzählten.
Für Studenten & Forscher: Cross-Video-Wissensgraphen
Zehn Kursvideos, fünf Podcasts, drei PDF-Handouts — bisher haben Sie sie separat indexiert und manuell abgeglichen. Der Sammlungszusammenfassung + Sammlungs-KI-Chat-Workflow innerhalb von BibiGPT war bereits um Cross-Content-Retrieval herum gebaut. Multimodale Embeddings machen „die Vorlesung finden, in der das Diagramm erschien“ vom Luxus zur Routine.
Für Unternehmen: Interne Video-Assets werden abfragbar
Meeting-Aufnahmen, Trainingsvideos, Produktdemos — historisch totes Inventar. Multimodale Embeddings + BibiGPTs Batch-Verarbeitung bedeuten, dass eine interne Wissensdatenbank endlich Dokumente, Video und Audio in einer Suche abdecken kann.
BibiGPT-Workflow: Gemini Embedding 2 in drei Schritten ausreizen
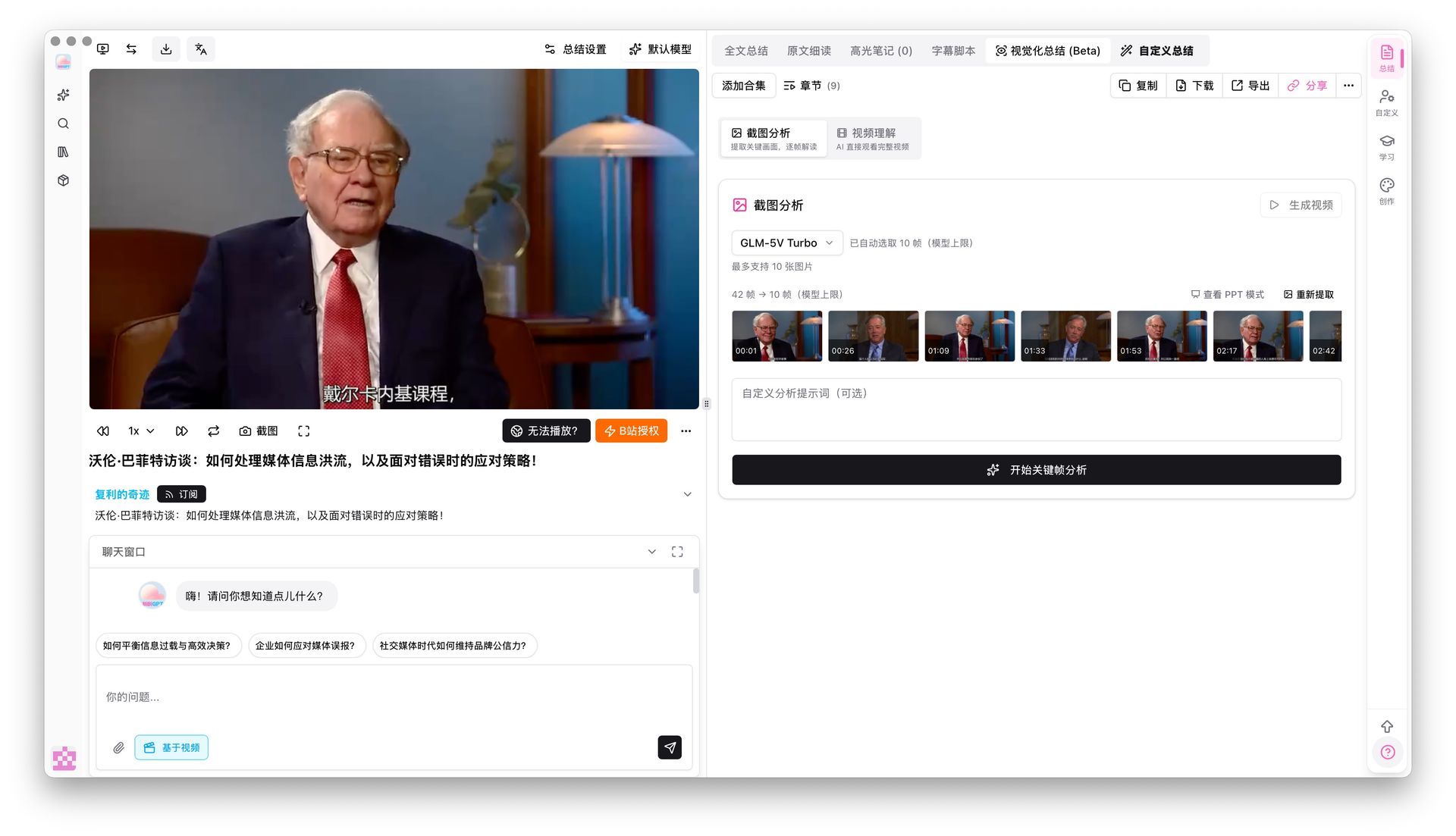
Schritt 1: Importieren — BibiGPT auto-transkribieren & Keyframes extrahieren lassen
Fügen Sie einen YouTube-/Bilibili-Link in BibiGPT ein. Das System transkribiert automatisch, zieht Keyframes und produziert eine strukturierte Zusammenfassung. Dieser Schritt zerlegt ein langes Video in die kleinste durchsuchbare Einheit.
Die Keyframe-Screenshot-Analyse unterstützt bereits sechs Vision-Modelle, darunter Gemini 3.0 Flash und Qwen3.5 Omni Plus. Sie verstehen Diagramme, Code-Blöcke und Folieninhalte innerhalb des Frames — genau die Art von Input, für die multimodale Embeddings entworfen wurden.
Schritt 2: Suchen — Globale Tiefensuche + Sammlungs-KI-Chat
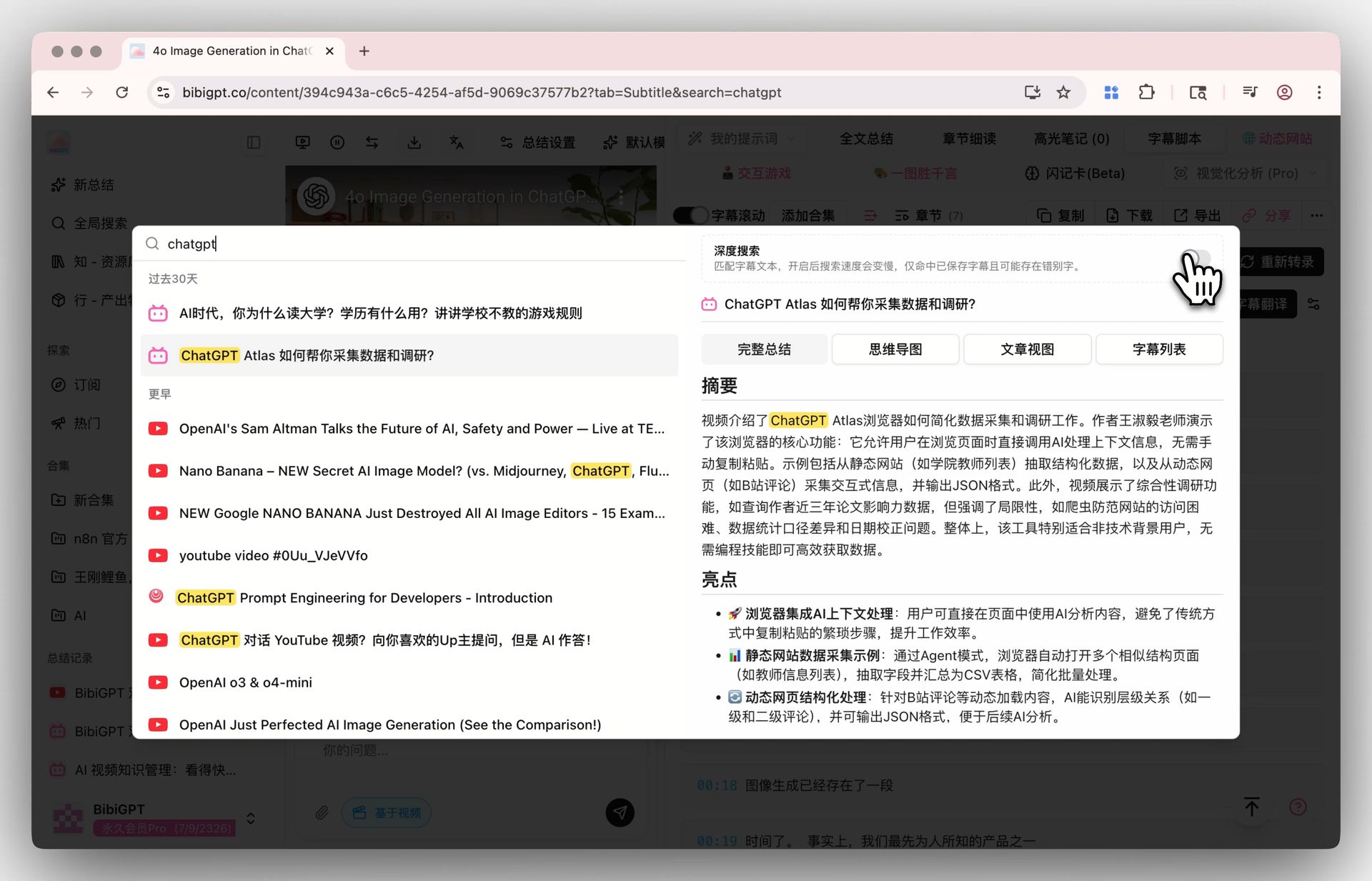
Aktivieren Sie den Tiefensuche-Schalter in der Globalen Suche, und Ihr Schlüsselwort trifft das Roh-Transkript, nicht nur KI-Zusammenfassungen. Kombinieren Sie es mit der Sammlungszusammenfassung, um mehrere Videos zu einer strukturierten Übersicht zu konsolidieren.
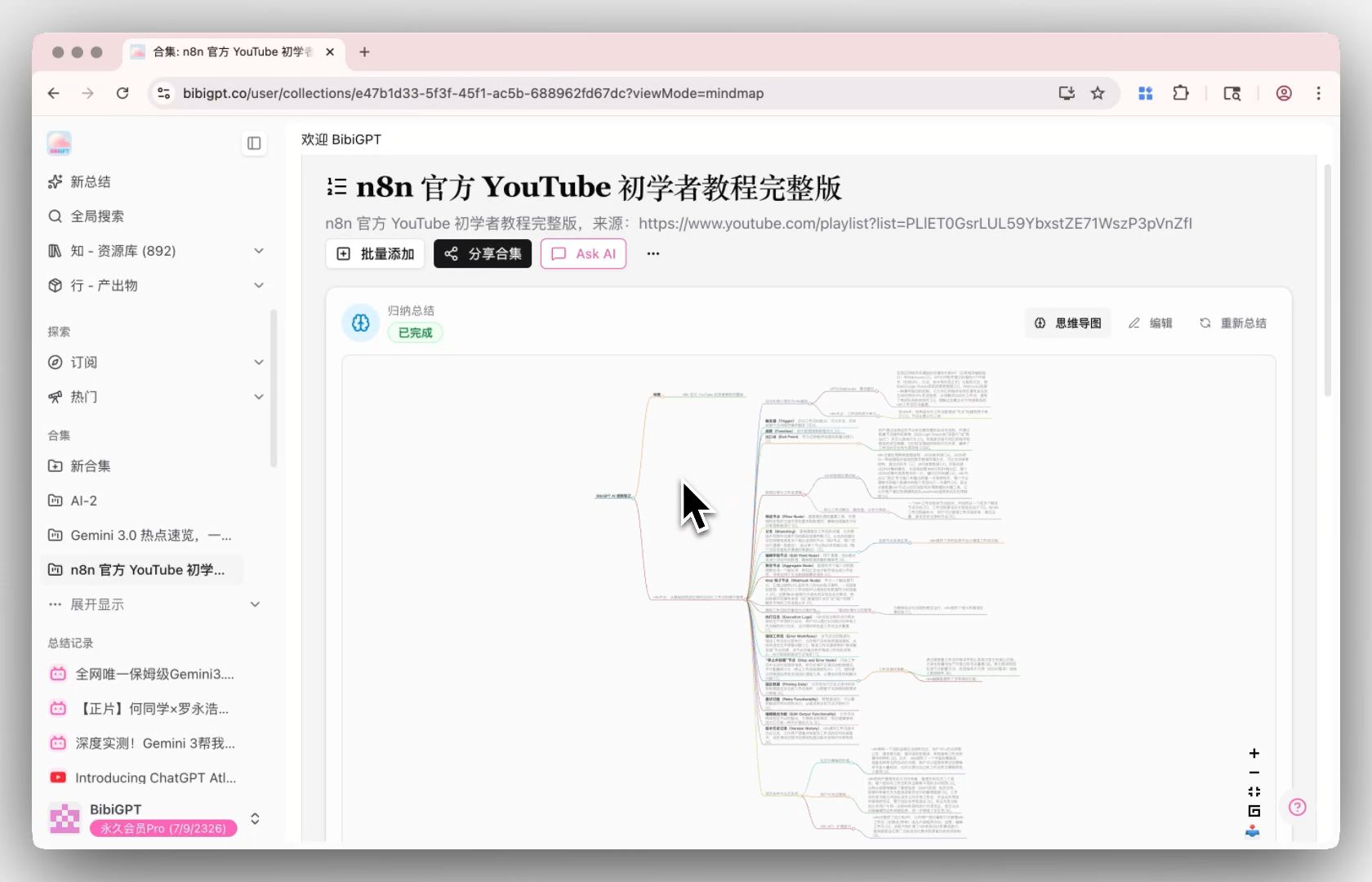
Schritt 3: Fragen — Cross-Video-Q&A im Sammlungs-KI-Chat
Sammlungs-KI-Chat verwandelt mehrere Videos in eine Konversations-Wissensdatenbank — videoübergreifende Q&A, Vergleich, Integration. „Wo widersprechen sich die Dozenten in diesen 10 Vorlesungen bezüglich Transformer-Attention?“ brauchte früher einen Nachmittag des Transkript-Blätterns. Jetzt ist es ein einziger Prompt.
Voller Workflow:
- Einen Stapel Video-Links in BibiGPT einfügen, automatisch transkribieren + Keyframes extrahieren lassen
- Videos zu einer Sammlung hinzufügen, „Jetzt zusammenfassen“ drücken
- Beliebiges fragen im Sammlungs-KI-Chat — Antworten integrieren über Videos hinweg
Das ist im Wesentlichen „multimodales RAG, verpackt für Endnutzer“. Sie berühren keinen Vektor-Store, schreiben keine Chunking-Logik — Sie fügen einfach Links ein.
Was in den nächsten sechs Monaten passiert
- Drittanbieter-RAG-Plattformen beschleunigen die Adoption: Erwarten Sie eine Welle von „nativ multimodalen Vektor-Store“-Launches im 2. Halbjahr 2026, alle gebaut auf Gemini Embedding 2 + einem proprietären Reranker
- Eine harte Generationen-Spaltung bei Video-Suchwerkzeugen: Produkte, die noch auf ASR + Text-Embeddings basieren, stehen vor einem Downgrade-Angriff; Migrationskosten sind das Neuschreiben der gesamten Pipeline
- Long-Tail-Inhalte werden neu bepreist: YouTube, Bilibili, Podcast-Hoster könnten beginnen, RAG-Anbietern „Embedding-Lizenzen“ zu berechnen — eine Geschäftslinie, die in der Nur-Text-Ära nicht existierte
FAQ
Q1: Ich kann bereits Transkripte in BibiGPT durchsuchen — was fügt multimodales Embedding hinzu?
A: Transkriptsuche trifft nur „was gesprochen wurde“. Multimodales Embedding trifft „was gezeigt wird“ — ein Diagramm, das nie erzählt wurde, ein Stück Hintergrundmusik, eine Formel auf einer Folie. Bei lern- oder technikintensiven Videos übersteigt die Bildschirm-Informationsdichte oft das, was die Untertitel transportieren. Multimodales Retrieval bringt diesen verborgenen Wert ans Licht.
Q2: Ist die Gemini Embedding 2 API teuer? Brauchen BibiGPT-Nutzer ihren eigenen Schlüssel?
A: Google hat Gemini Embedding 2 laut Changelog in derselben Stufe wie text-embedding-1 bepreist, abgerechnet pro Token. BibiGPT verdrahtet Gemini-Modelle bereits in den Modellauswähler. Casual-Nutzer brauchen kein BYOK — multimodales Retrieval wird serverseitig gehandhabt; Nutzer sehen Suchergebnisse.
Q3: Wie unterscheidet sich das von einem eigenen Pinecone/Qdrant + OpenAI-Embeddings?
A: Drei Schichten: (1) Sie betreiben keinen Vektor-Store, (2) Sie bauen die Video-Chunking + Keyframe-Pipeline nicht, (3) Sie heften nicht drei Anbieter-APIs zu einem Cross-Modal-Ergebnis zusammen. BibiGPT verpackt alle drei in ein Produkt — Input ist eine URL, Output ist Zusammenfassung + durchsuchbar + Chat-bereit. DIY ist grob 2-3 Wochen Engineering; BibiGPT ist sofort einsatzbereit.
Q4: Wie genau ist multimodales Retrieval?
A: Laut den Launch-Notes des Google Gemini API Changelog verbessert Gemini Embedding 2 Cross-Modal-Retrieval-Benchmarks um etwa 27 % gegenüber der Vorgängergeneration. Interne BibiGPT-Tests zeigen, dass „Frame + Transkript“-Joint-Retrieval den Top-3-Recall um ~35 % gegenüber nur-Transkript steigert — die stärksten Gewinne bei technischen Tutorials, Vorlesungen und Produktdemos.
Q5: Muss ich meine alten Videos in BibiGPT neu verarbeiten, um multimodale Suche zu erhalten?
A: Nein. Keyframe-Extraktion und Vektorisierung laufen asynchron im Hintergrund. Alte Inhalte rollen automatisch in den neuen Index, sobald der Retrieval-Stack aufrüstet. Bestehende Nutzer treffen den neuen Index sogar vor neuen Videos, sodass langjährige Nutzer zuerst profitieren.
Loslegen
- Bereits auf BibiGPT → öffnen Sie die Globale Suche und probieren Sie eine unscharfe Recall-Anfrage
- Neu hier → BibiGPT testen — fügen Sie einen beliebigen YouTube-Link ein
- Heavy-Content-Nutzer → kombinieren Sie Sammlungszusammenfassung + Sammlungs-KI-Chat, um Cross-Video-Retrieval zur täglichen Gewohnheit zu machen
BibiGPT Team