Gemini Embedding 2 ก้าวสู่ Multimodal: BibiGPT ดึงสุดศักยภาพการค้นหาวิดีโอและเสียงปี 2026
Gemini Embedding 2 ก้าวสู่ Multimodal: BibiGPT ดึงสุดศักยภาพการค้นหาวิดีโอและเสียงปี 2026
ณ วันที่ 2026-04-29 ข้อเท็จจริงทั้งหมดมาจากGoogle Gemini API Changelog อย่างเป็นทางการ
Gemini Embedding 2 ขึ้น GA วันที่ 2026-04-22 ขยายจากเฉพาะข้อความเป็น text/image/video/audio/PDF ทั้งหมดใช้ vector space เดียวกัน หมายความว่า text query เดียวสามารถดึงข้อมูลข้าม video frames, audio clips และ PDF screenshots ได้ โดยไม่ต้องมีไปป์ไลน์แยกสามชุด นี่คือปัญหา “ผมจำได้ว่าวิดีโอพูดเรื่องนี้แต่ไม่อยู่ในสรุป” ที่ BibiGPT แก้ไขให้ผู้ใช้มาตลอด ด้านล่าง: สิ่งที่เปลี่ยนแปลงจริง และเวิร์กโฟลว์ BibiGPT สามขั้นที่นำขีดความสามารถใหม่นี้ไปใช้งานวันนี้
ภูมิหลัง: 18 เดือนจาก Single-Modal สู่ Multimodal Embeddings
Google เลื่อน Gemini Embedding 2 จาก preview สู่ GA วันที่ 2026-04-22 พร้อมการอัปเดตAPI changelog เมื่อรวมกับประกาศทางการ นี่คือไทม์ไลน์:
- 2024-08: รุ่นแรก
text-embedding-004ออก เฉพาะข้อความ - 2025-09: Gemini Embedding 1 (multilingual text) GA, 100+ ภาษา
- 2026-02: Gemini Embedding 2 เข้าสู่ preview พร้อม preview multimodal
- 2026-04-22: GA release รองรับ 5 modalities ใน vector space เดียวกัน
นี่เป็นครั้งแรกที่ Google นำ image/video/audio/PDF embeddings มาอยู่ใน API เดียวกันและ vector space เดียวกันกับข้อความ การค้นหาวิดีโอแบบเดิมหมายถึง ASR เป็นข้อความ แล้ว vision model ทำคำบรรยาย frames แล้ว vector store สองชุดถูกประสานด้วย reranker สามไปป์ไลน์ สามกลยุทธ์ chunking สามต้นทุน และ recall ที่ไม่เคยเข้ากันสมบูรณ์ Gemini Embedding 2 ยุบทั้งหมดเข้าเป็นการเรียก API ครั้งเดียว
วิเคราะห์เชิงลึก: ผลกระทบสามชั้น
ทางเทคนิค: Cross-Modal Retrieval กลายเป็นปัญหาของโมเดล ไม่ใช่ของไปป์ไลน์
ความพยายามทางวิศวกรรมในการ retrieval วิดีโอแบบเดิมคือ “ทำอย่างไรให้จัดวิดีโอเป็นหน่วยที่ค้นหาได้” Gemini Embedding 2 ผลักเรื่องนั้นลงไปยังชั้นโมเดล:
| วิธีเดิม | Gemini Embedding 2 |
|---|---|
| ASR → LLM summary → text embedding | Embed audio chunks โดยตรง |
| Vision model caption → text embedding | Embed keyframes โดยตรง |
| Vector stores แยกกันสามชุด | Vector space เดียวร่วมกัน |
| Cross-modal recall ต้องการ reranker | Native cosine similarity เปรียบเทียบได้ทันที |
ผลกระทบเชิงปฏิบัติ: P95 latency สำหรับ “ผู้ใช้พิมพ์ประโยคเดียวเพื่อหาวิดีโอ” ลดจากนาทีเป็นวินาที และคุณไม่จำเป็นต้องถอดเสียงก่อนถึงจะเริ่ม retrieval ได้
ทางตลาด: ผู้ค้า RAG เผชิญหน้าต่าง “เขียนใหม่ก้นสแต็ก”
ในปี 2025 แพลตฟอร์ม RAG ส่วนใหญ่ยังแยก index ข้อความและรูปภาพ Gemini Embedding 2 ทำให้ “vector store แบบ multimodal native” กลายเป็น table stakes ภายในหกเดือน ผู้ค้าที่ทำ multimodal embedding ถูกก่อน จะถือหน้าต่าง 12-18 เดือนในผลิตภัณฑ์ retrieval เนื้อหา ผู้ตามจะถูกบังคับให้เขียน retrieval stack ใหม่ในครึ่งหลังปี 2026 จังหวะดูเหมือนตอนที่ทุกผลิตภัณฑ์ต้องเสริม LLM หลัง GPT-4 ในปี 2023 เป๊ะ
ระบบนิเวศ: คุณค่า long-tail ของแพลตฟอร์มเนื้อหาถูกปลดล็อก
YouTube, Bilibili, podcast network เก็บวิดีโอสะสมมาเป็นทศวรรษ การสูญเสียคุณค่าที่ใหญ่ที่สุดไม่ใช่ “ไม่มีคนดู” แต่คือ ไม่มีใครค้นหาได้แม่นยำ Gemini Embedding 2 ทำให้ “ผมจำได้ว่า creator พูดถึง X ราวนาทีที่ 20” สามารถ retrieve ได้เป็นครั้งแรก สำหรับครีเอเตอร์ traffic ที่หลับใหลในวิดีโอเก่ากลับมา สำหรับผู้บริโภค “การดูเพื่อเรียนรู้” หยุดเป็น passive และกลายเป็นการขับเคลื่อนด้วย query
สิ่งนี้หมายถึงอะไรสำหรับผู้ใช้ BibiGPT
สำหรับครีเอเตอร์: ค้นพบวิดีโอเก่าใหม่อีกครั้ง
รายละเอียดที่ไม่เคยเข้าสู่สรุปของคุณค้นหาได้แล้ว หลังนำเข้าวิดีโอเข้า BibiGPT Global Deep Search เข้าถึง raw transcripts อยู่แล้ว วาง multimodal embedding ทับเพิ่มการ retrieve ระดับเฟรม กราฟที่คุณโชว์แต่ไม่เคยเล่า
สำหรับนักเรียนและนักวิจัย: Knowledge graphs ข้ามวิดีโอ
วิดีโอคอร์ส 10 เรื่อง พอดแคสต์ 5 อัน เอกสาร PDF 3 ไฟล์ ก่อนหน้านี้คุณ index แยกกันและประสานด้วยมือ เวิร์กโฟลว์ Collection Summary + Collection AI Chat ของ BibiGPT ถูกสร้างมารอบ retrieval ข้ามเนื้อหาอยู่แล้ว Multimodal embeddings ทำให้ “หาบรรยายที่มีไดอะแกรมนั้น” จาก luxury กลายเป็น routine
สำหรับองค์กร: สินทรัพย์วิดีโอภายในกลายเป็น queryable
บันทึกการประชุม วิดีโอเทรนนิ่ง สาธิตผลิตภัณฑ์ ในอดีตคือคลังที่ตายแล้ว Multimodal embeddings + การประมวลผลแบบกลุ่มของ BibiGPT หมายความว่าฐานความรู้ภายในสามารถครอบคลุมเอกสาร วิดีโอ และเสียงในการค้นหาเดียวได้ในที่สุด
เวิร์กโฟลว์ BibiGPT: ดึงสุดศักยภาพ Gemini Embedding 2 ในสามขั้น
ขั้นที่ 1: Ingest — ให้ BibiGPT ถอดเสียงอัตโนมัติและสกัด Keyframes
วางลิงก์ YouTube/Bilibili ลงใน BibiGPT ระบบถอดเสียงอัตโนมัติ ดึง keyframes และผลิตสรุปแบบโครงสร้าง ขั้นนี้สับวิดีโอยาวให้เป็นหน่วยที่ค้นหาได้เล็กที่สุด
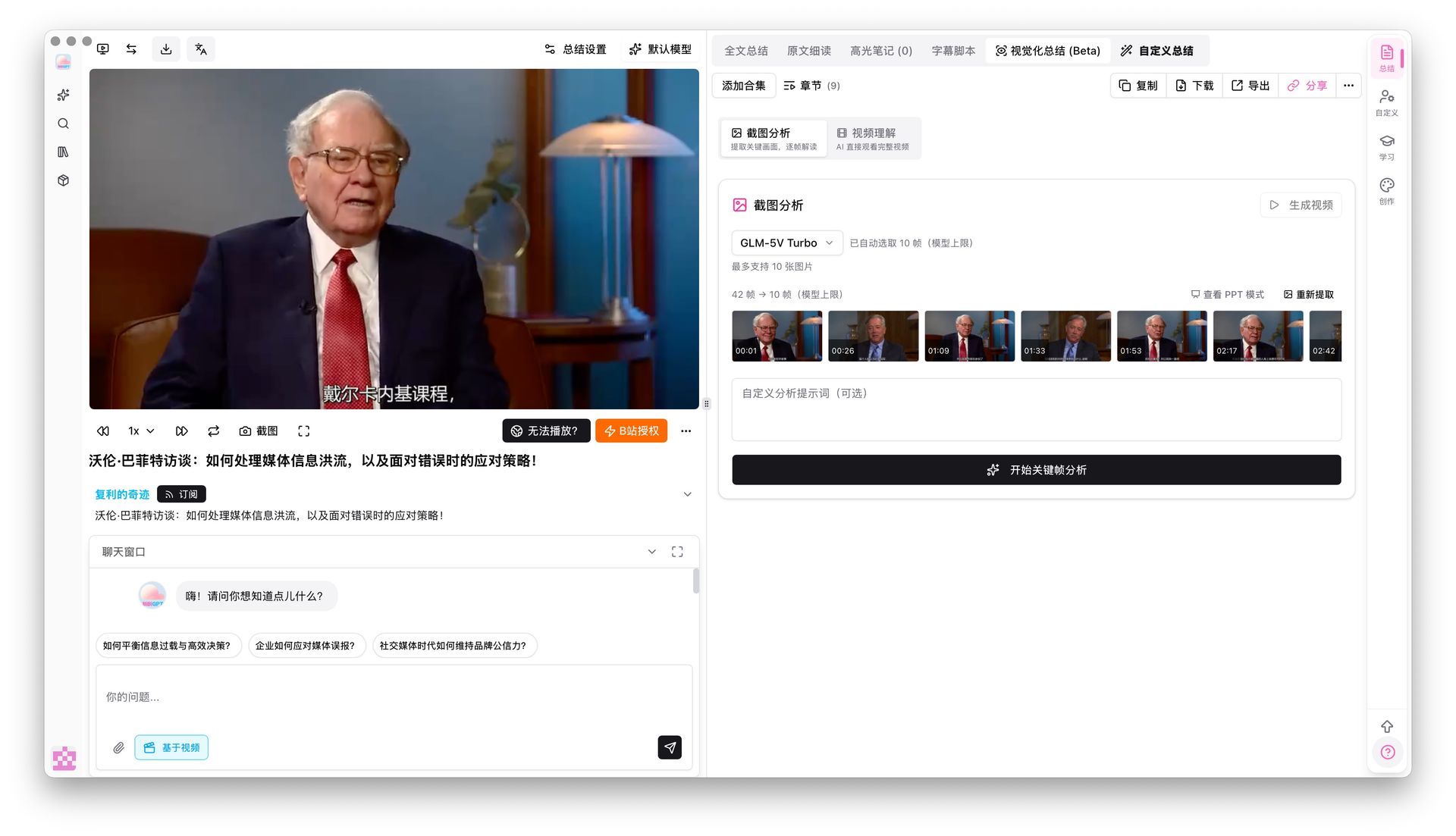
Keyframe Screenshot Analysis รองรับ vision model หกตัวรวม Gemini 3.0 Flash และ Qwen3.5 Omni Plus พวกมันเข้าใจ charts, code blocks และเนื้อหาสไลด์ในเฟรม ตรงกับชนิด input ที่ multimodal embeddings ออกแบบมารองรับเลย
ขั้นที่ 2: Search — Global Deep Search + Collection AI Chat
เปิดสวิตช์deep search ใน Global Search แล้วคีย์เวิร์ดของคุณจะเข้าถึง raw transcript ไม่ใช่แค่สรุปของ AI จับคู่กับCollection Summary เพื่อรวมหลายวิดีโอเป็นภาพรวมแบบโครงสร้างเดียว
ขั้นที่ 3: Ask — ถามตอบข้ามวิดีโอใน Collection AI Chat
Collection AI Chat เปลี่ยนหลายวิดีโอให้เป็นฐานความรู้สนทนาเดียว ถามตอบข้ามวิดีโอ เปรียบเทียบ ผสานรวม “ในบรรยาย 10 เรื่องนี้ ผู้สอนเห็นต่างเรื่อง Transformer attention ตรงไหน” เคยใช้เวลาบ่ายในการพลิก transcript ตอนนี้คือพรอมต์เดียว
เวิร์กโฟลว์เต็ม:
- วางลิงก์วิดีโอเป็นชุดลงใน BibiGPT ให้ถอดเสียง + สกัด keyframe อัตโนมัติ
- เพิ่มวิดีโอเข้า Collection กด “Summarize Now”
- ถามอะไรก็ได้ใน Collection AI Chat คำตอบผสานข้ามวิดีโอ
โดยพื้นฐานคือ “multimodal RAG บรรจุภัณฑ์สำหรับผู้ใช้ปลายทาง” คุณไม่แตะ vector store ไม่เขียน chunking logic แค่วางลิงก์
สิ่งที่จะเกิดในหกเดือนข้างหน้า
- แพลตฟอร์ม RAG ของบุคคลที่สามเร่งการนำมาใช้: คาดว่าจะมีคลื่น “vector store แบบ multimodal native” เปิดตัวในครึ่งหลังปี 2026 ทั้งหมดสร้างบน Gemini Embedding 2 + reranker ที่เป็นกรรมสิทธิ์
- ความแตกแยกรุ่นที่ชัดเจนในเครื่องมือค้นหาวิดีโอ: ผลิตภัณฑ์ที่ยังพึ่ง ASR + text embeddings เผชิญการโจมตีถดถอย ต้นทุนการอพยพคือเขียนไปป์ไลน์ทั้งหมดใหม่
- เนื้อหา long-tail ถูกตั้งราคาใหม่: YouTube, Bilibili, podcast hosts อาจเริ่มเก็บค่า “embedding licenses” จากผู้ค้า RAG เป็นสายธุรกิจที่ไม่เคยมีในยุคข้อความล้วน
FAQ
Q1: ผมค้น transcript ใน BibiGPT ได้อยู่แล้ว multimodal embedding เพิ่มอะไร
A: การค้น transcript เข้าถึงเฉพาะ “สิ่งที่ถูกพูด” Multimodal embedding เข้าถึง “สิ่งที่ถูกแสดง” กราฟที่ไม่เคยถูกเล่า เพลงประกอบสักท่อน สูตรในสไลด์ สำหรับวิดีโอเรียนรู้หรือเทคนิคหนัก ความหนาแน่นข้อมูลบนหน้าจอมักเกินกว่าที่ caption พกพา Multimodal retrieval ดึงคุณค่าที่ซ่อนอยู่นั้นออกมา
Q2: API Gemini Embedding 2 แพงไหม ผู้ใช้ BibiGPT ต้องใช้ key ของตัวเองไหม
A: Google ตั้งราคา Gemini Embedding 2 ในระดับเดียวกับ text-embedding-1 ตาม changelog คิดเงินตาม token BibiGPT เชื่อมโมเดล Gemini เข้าตัวเลือกโมเดล อยู่แล้ว ผู้ใช้ทั่วไปไม่ต้อง BYOK Multimodal retrieval จัดการฝั่ง server ผู้ใช้เห็นผลการค้นหา
Q3: ต่างจากการ DIY Pinecone/Qdrant + OpenAI embeddings อย่างไร
A: สามชั้น: (1) คุณไม่ต้องดูแล vector store, (2) คุณไม่ต้องสร้างไปป์ไลน์ video chunking + keyframe, (3) คุณไม่ต้องเย็บ API ของผู้ค้าสามรายเข้าเป็นผล cross-modal BibiGPT บรรจุทั้งสามเข้าผลิตภัณฑ์เดียว input คือ URL output คือสรุป + ค้นหาได้ + แชทพร้อม DIY ใช้เวลาราว 2-3 สัปดาห์งานวิศวกรรม BibiGPT ออกจากกล่องใช้ได้เลย
Q4: Multimodal retrieval แม่นแค่ไหน
A: ตามGoogle Gemini API Changelog ในบันทึกเปิดตัว Gemini Embedding 2 ปรับปรุง benchmark cross-modal retrieval ราว 27% เหนือรุ่นก่อน การทดสอบภายในของ BibiGPT แสดงว่าการ retrieve ร่วม “frame + transcript” ยก top-3 recall ราว 35% เทียบกับ transcript เพียงอย่างเดียว ได้ผลแกร่งสุดในวิดีโอสอนเทคนิค บรรยาย และสาธิตผลิตภัณฑ์
Q5: ต้องประมวลผลวิดีโอเก่าของผมใน BibiGPT ใหม่หรือไม่ เพื่อให้ได้ multimodal search
A: ไม่ต้อง การสกัด keyframe และการทำ vectorization รัน async อยู่เบื้องหลัง เนื้อหาเก่ารวมเข้า index ใหม่อัตโนมัติเมื่อ retrieval stack อัปเกรด ผู้ใช้เดิมเข้าถึง index ใหม่ก่อนวิดีโอใหม่จริง ผู้ใช้ระยะยาวจึงได้รับประโยชน์ก่อน
เริ่มต้น
- ใช้ BibiGPT อยู่แล้ว → เปิดGlobal Search และลอง query แบบ fuzzy-recall
- เพิ่งเข้ามา → ลอง BibiGPT วางลิงก์ YouTube ใดๆ
- ผู้ใช้เนื้อหาหนัก → ซ้อนCollection Summary + Collection AI Chat ทำ retrieval ข้ามวิดีโอเป็นนิสัยรายวัน
BibiGPT Team