Gemini Embedding 2 diventa multimodale: come BibiGPT massimizza la ricerca video e audio nel 2026
Gemini Embedding 2 diventa multimodale: come BibiGPT massimizza la ricerca video e audio nel 2026
Al 29-04-2026. Tutti i fatti sono basati sul Google Gemini API Changelog ufficiale.
Gemini Embedding 2 ha raggiunto la GA il 22-04-2026, espandendosi da solo testo a testo / immagine / video / audio / PDF — tutti che condividono lo stesso spazio vettoriale. Questo significa che una singola query testuale può ora recuperare attraverso frame video, clip audio e screenshot PDF senza tre pipeline separate. Questo è esattamente il problema di lunga data “ricordo che il video lo dice ma non è nel riassunto” che BibiGPT sta risolvendo per gli utenti. Sotto: cosa è effettivamente cambiato, e il workflow BibiGPT in tre step che mette in pratica la nuova capacità oggi.
Contesto: 18 mesi dagli embedding monomodali a quelli multimodali
Google ha promosso Gemini Embedding 2 da preview a GA il 22-04-2026, accompagnato da un aggiornamento dell’API changelog. Combinato con l’annuncio ufficiale, ecco la cronologia:
- 08-2024: prima generazione
text-embedding-004, solo testo - 09-2025: Gemini Embedding 1 (testo multilingue) GA, oltre 100 lingue
- 02-2026: Gemini Embedding 2 entra in preview, multimodale in anteprima
- 22-04-2026: rilascio GA, supporto nativo per 5 modalità in uno spazio vettoriale condiviso
Questa è la prima volta che Google mette gli embedding di immagine / video / audio / PDF nella stessa API e nello stesso spazio vettoriale del testo. Fare ricerca video alla vecchia maniera significava ASR-su-testo, poi un modello visivo per descrivere i frame, poi due vector store riconciliati da un reranker — tre pipeline, tre strategie di chunking, tre voci di costo, e un recall che non era mai del tutto allineato. Gemini Embedding 2 collassa tutto in una chiamata API.
Analisi approfondita: tre livelli di impatto
Tecnico: il retrieval cross-modale diventa un problema di modello, non di pipeline
Lo sforzo ingegneristico nel retrieval video legacy era su “come allineare il video in un’unità ricercabile”. Gemini Embedding 2 spinge questo verso il basso nel livello modello:
| Approccio legacy | Gemini Embedding 2 |
|---|---|
| ASR → riassunto LLM → embedding testuale | Embedding diretto dei chunk audio |
| Caption modello visivo → embedding testuale | Embedding diretto dei keyframe |
| Tre vector store separati | Uno spazio vettoriale condiviso |
| Recall cross-modale richiede un reranker | La cosine similarity nativa è confrontabile |
Impatto pratico: la latenza P95 per “l’utente digita una frase per trovare un video” scende da minuti a secondi, e non hai più bisogno di trascrivere prima di poter iniziare il retrieval.
Mercato: i vendor RAG affrontano una finestra di “riscrivere il fondo dello stack”
Nel 2025 la maggior parte delle piattaforme RAG mantenevano ancora indici testo e immagine separati. Gemini Embedding 2 rende il “vector store nativamente multimodale” un requisito tavola entro sei mesi. I vendor che ottengono per primi un buon embedding multimodale terranno una finestra di 12-18 mesi sui prodotti di retrieval di contenuti; i ritardatari saranno costretti a riscrivere il loro stack di retrieval nel 2026 H2. Il ritmo sembra identico a come ogni prodotto dovette aggiungere LLM dopo GPT-4 nel 2023.
Ecosistema: il valore long-tail delle piattaforme di contenuti viene sbloccato
YouTube, Bilibili, le reti podcast hanno accumulato un decennio di video. La più grande perdita di valore non è “nessuno guarda” ma nessuno può cercare con precisione. Gemini Embedding 2 rende per la prima volta recuperabile “ricordo che un creator ha menzionato X intorno al minuto 20”. Per i creator, il traffico dormiente sui vecchi video torna; per i consumatori, “guardare per imparare” smette di essere passivo e diventa guidato dalla query.
Cosa significa questo per gli utenti BibiGPT
Per i creator: vecchi video riscoperti
Dettagli che non sono mai entrati nel tuo riassunto diventano ricercabili. Dopo aver importato un video in BibiGPT, Global Deep Search già colpisce le trascrizioni grezze; sovrapporre l’embedding multimodale aggiunge il retrieval a livello frame — il grafico che hai mostrato ma mai narrato.
Per studenti e ricercatori: knowledge graph cross-video
Dieci video di corso, cinque podcast, tre handout PDF — prima li indicizzavi separatamente e li riconciliavi a mano. Il workflow Collection Summary + Collection AI Chat dentro BibiGPT era già costruito attorno al retrieval cross-content. Gli embedding multimodali trasformano “trova la lezione dove appariva quel diagramma” da lusso a routine.
Per le aziende: gli asset video interni diventano interrogabili
Registrazioni di riunioni, video di formazione, demo prodotto — storicamente inventario morto. Embedding multimodali + l’elaborazione in batch di BibiGPT significano che una base di conoscenza interna può finalmente coprire documenti, video e audio in una singola ricerca.
Workflow BibiGPT: massimizzare Gemini Embedding 2 in tre step
Step 1: ingestione — lascia che BibiGPT trascriva ed estragga keyframe automaticamente
Incolla un link YouTube / Bilibili in BibiGPT. Il sistema trascrive automaticamente, estrae keyframe e produce un riassunto strutturato. Questo step frammenta un video lungo nella più piccola unità ricercabile.
Keyframe Screenshot Analysis supporta già sei modelli visivi inclusi Gemini 3.0 Flash e Qwen3.5 Omni Plus. Capiscono grafici, blocchi di codice e contenuti di slide all’interno del frame — esattamente il tipo di input per cui sono stati progettati gli embedding multimodali.
Step 2: ricerca — Global Deep Search + Collection AI Chat
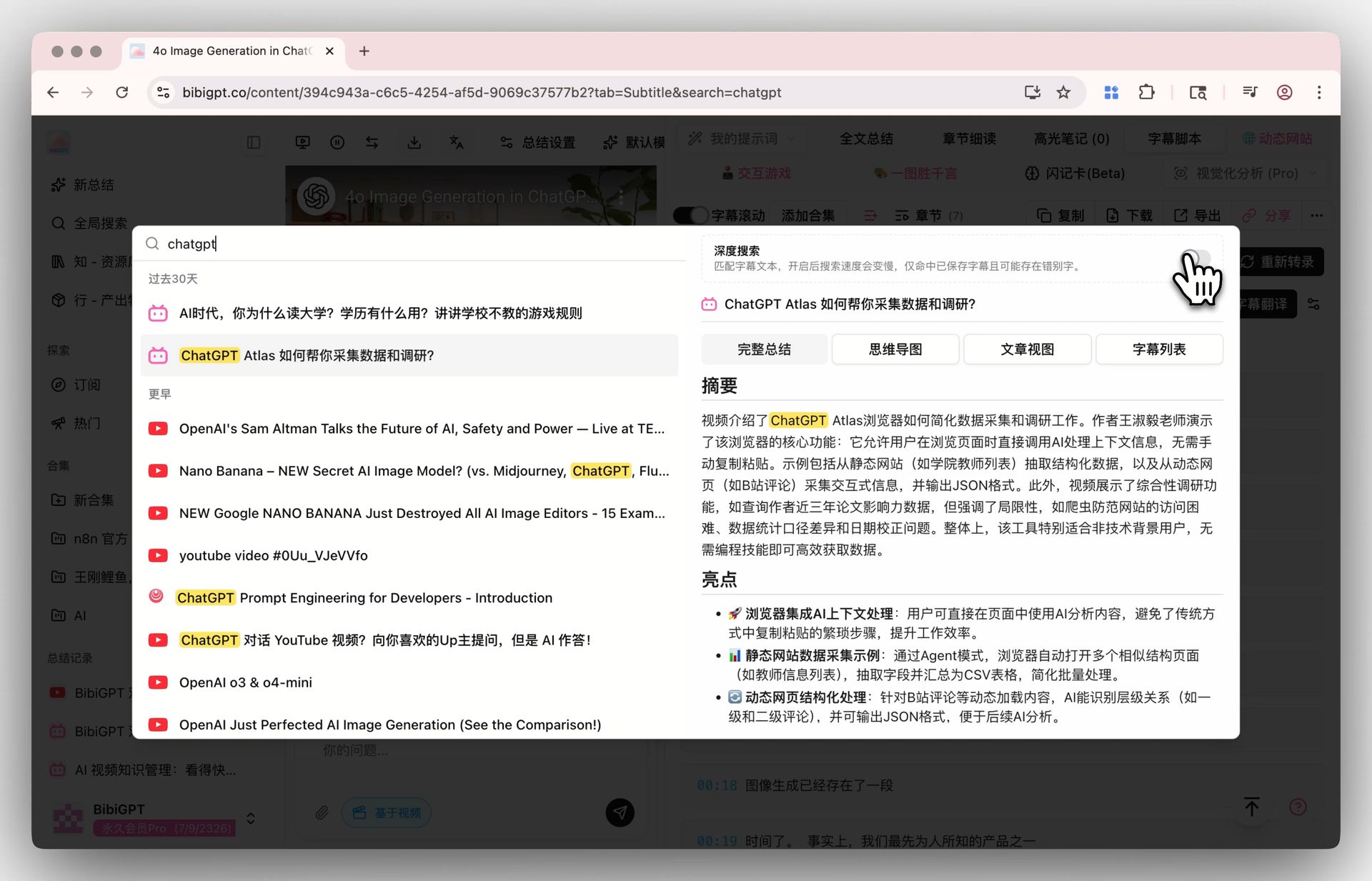
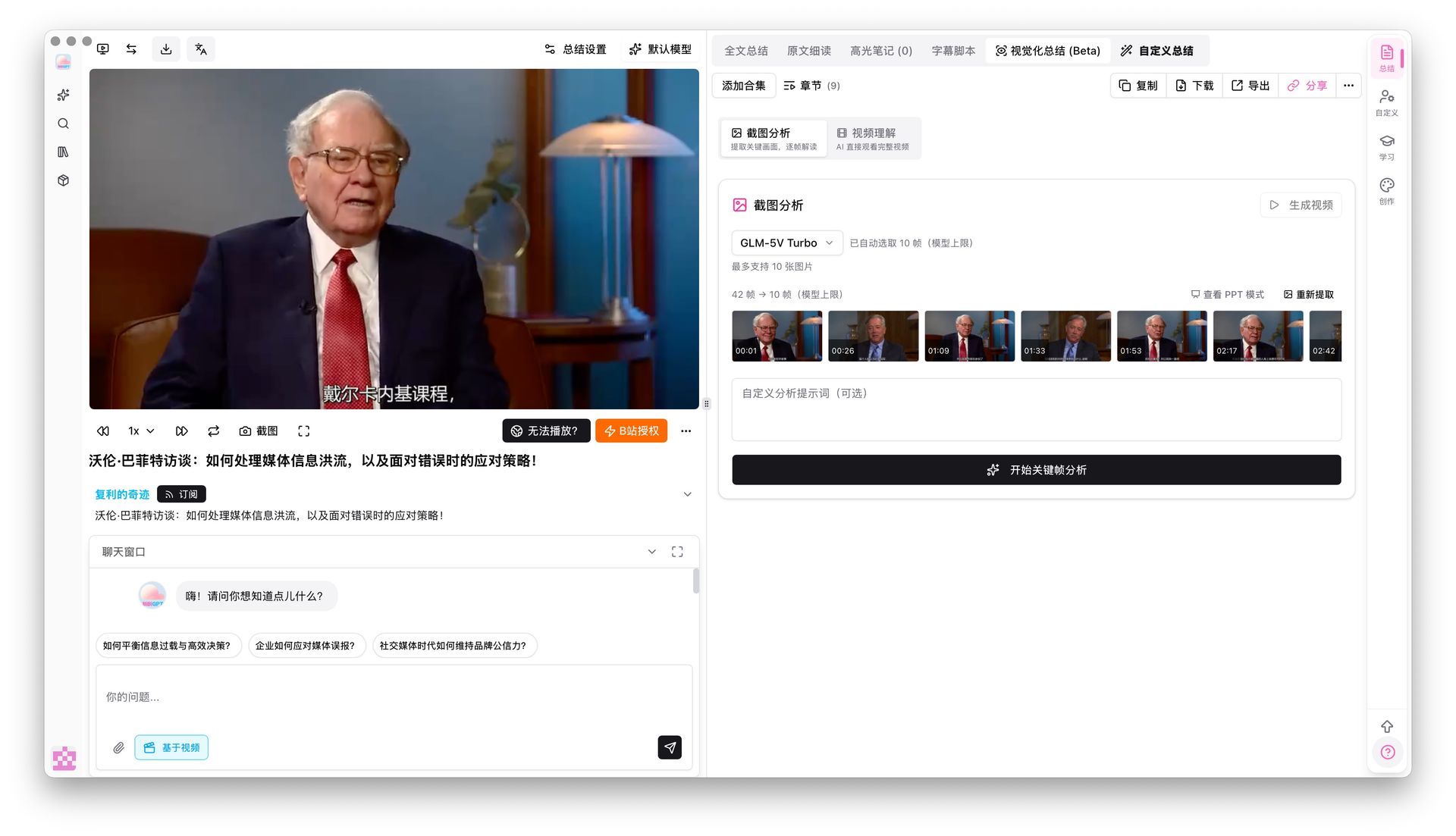
Attiva il toggle deep search in Global Search e la tua keyword colpisce la trascrizione grezza, non solo i riassunti AI. Abbinalo con Collection Summary per consolidare più video in una panoramica strutturata.
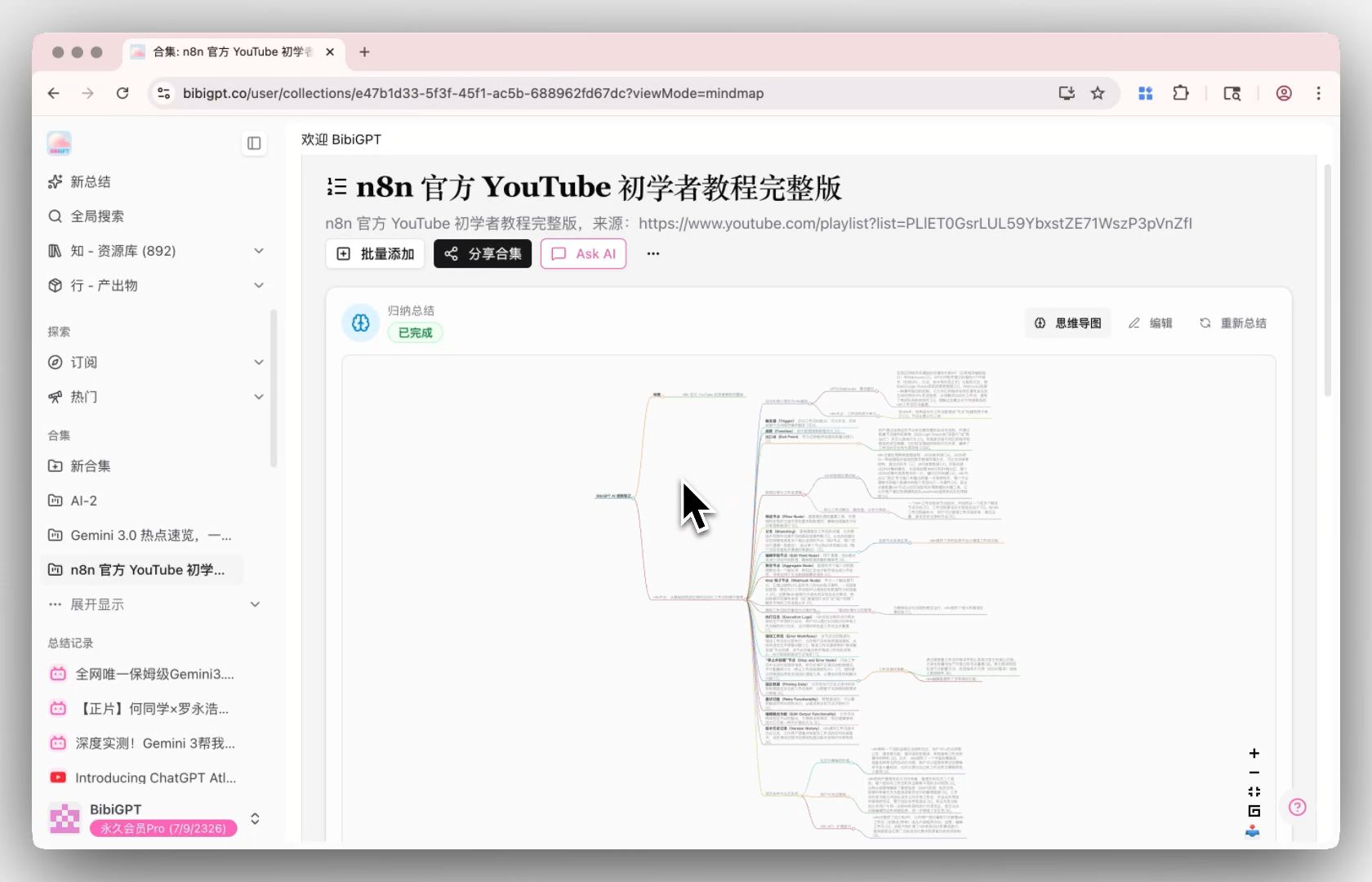
Step 3: chiedi — Q&A cross-video in Collection AI Chat
Collection AI Chat trasforma più video in un’unica base di conoscenza conversazionale — Q&A cross-video, confronto, integrazione. “In queste 10 lezioni, dove gli istruttori sono in disaccordo sull’attention dei Transformer?” prima richiedeva un pomeriggio di consultazione delle trascrizioni. Ora è un solo prompt.
Workflow completo:
- Incolla un batch di link video in BibiGPT, lascia che trascriva automaticamente + estragga keyframe
- Aggiungi i video a una Collection, premi “Riassumi ora”
- Chiedi qualsiasi cosa in Collection AI Chat — le risposte si integrano cross-video
Questo è essenzialmente “RAG multimodale, impacchettato per utenti finali”. Non tocchi un vector store, non scrivi logica di chunking — incolli solo i link.
Cosa accade nei prossimi sei mesi
- Le piattaforme RAG terze parti accelerano l’adozione: aspettati un’ondata di lanci “vector store nativamente multimodali” nel 2026 H2, tutti costruiti su Gemini Embedding 2 + un reranker proprietario
- Una netta divisione generazionale negli strumenti di ricerca video: i prodotti ancora su ASR + embedding testuali affrontano un attacco al ribasso; il costo di migrazione è riscrivere l’intera pipeline
- I contenuti long-tail vengono ri-prezzati: YouTube, Bilibili, gli host di podcast potrebbero iniziare a far pagare ai vendor RAG “licenze di embedding” — una linea di business che non esisteva nell’era solo testo
FAQ
Q1: Posso già cercare nelle trascrizioni in BibiGPT — cosa aggiunge l’embedding multimodale?
A: La ricerca su trascrizione colpisce solo “ciò che è stato detto”. L’embedding multimodale colpisce “ciò che è mostrato” — un grafico mai narrato, un brano di musica di sottofondo, una formula su una slide. Per video di apprendimento o tecnici, la densità informativa a schermo spesso supera quella dei sottotitoli. Il retrieval multimodale fa emergere quel valore nascosto.
Q2: L’API Gemini Embedding 2 è costosa? Gli utenti BibiGPT hanno bisogno della propria chiave?
A: Google ha prezzato Gemini Embedding 2 nello stesso tier di text-embedding-1 secondo il changelog, fatturato per token. BibiGPT collega già i modelli Gemini al model selector. Gli utenti casual non hanno bisogno di BYOK — il retrieval multimodale è gestito server-side; gli utenti vedono i risultati di ricerca.
Q3: In cosa differisce dal fare il proprio Pinecone/Qdrant + embedding OpenAI?
A: Tre livelli: (1) non operi un vector store, (2) non costruisci la pipeline di chunking video + keyframe, (3) non cucisci tre API vendor in un risultato cross-modale. BibiGPT impacchetta tutti e tre in un prodotto — input è un URL, output è riassunto + ricercabile + pronto per la chat. Il fai-da-te è circa 2-3 settimane di ingegneria; BibiGPT è out-of-the-box.
Q4: Quanto è accurato il retrieval multimodale?
A: Secondo le note di lancio del Google Gemini API Changelog, Gemini Embedding 2 migliora i benchmark di retrieval cross-modale di circa il 27% rispetto alla generazione precedente. I test interni BibiGPT mostrano che il retrieval congiunto “frame + trascrizione” alza il recall top-3 di ~35% rispetto al solo trascrizione — i guadagni più forti su tutorial tecnici, lezioni e demo prodotto.
Q5: Devo rielaborare i miei vecchi video in BibiGPT per ottenere la ricerca multimodale?
A: No. L’estrazione keyframe e la vettorizzazione girano async in background. I vecchi contenuti rotolano nel nuovo indice automaticamente man mano che lo stack di retrieval si aggiorna. Gli utenti esistenti in realtà colpiscono il nuovo indice prima dei nuovi video, quindi gli utenti di lunga data ne beneficiano per primi.
Inizia
- Già su BibiGPT → apri Global Search e prova una query a recall fuzzy
- Nuovo qui → Prova BibiGPT — incolla qualsiasi link YouTube
- Utente intensivo → impila Collection Summary + Collection AI Chat per rendere il retrieval cross-video un’abitudine quotidiana
BibiGPT Team