Gemini Embedding 2 多模態來了:BibiGPT 影片音訊檢索如何把它用滿
Gemini Embedding 2 多模態來了:BibiGPT 影片音訊檢索如何把它用滿
截至 2026 年 4 月 29 日,本文事實基於 Google Gemini API Changelog 公開資訊整理。
Gemini Embedding 2 在 2026-04-22 GA,最大變化是把「嵌入」從純文字擴展到文字/圖像/影片/音訊/PDF 五種模態,且共享同一向量空間。 這意味著您可以用一句話在影片畫面、音訊片段、PDF 截圖之間做跨模態檢索——這正是 BibiGPT 長期以來想給使用者解決的「我記得影片裡講過這個,可摘要裡沒寫」問題。這篇文章先講清楚 Embedding 2 到底變了什麼,再給出在 BibiGPT 裡把它用滿的三步工作流。
事件背景:從單模態到多模態嵌入的 18 個月
Google 2026-04-22 把 Gemini Embedding 2 從 preview 推到 GA,同一天更新了 API changelog。結合官方公告,時間線如下:
- 2024-08:第一代
text-embedding-004上線,僅支援純文字 - 2025-09:Gemini Embedding 1(多語言文字)GA,支援 100+ 語言
- 2026-02:Gemini Embedding 2 進入 preview,首次預告多模態
- 2026-04-22:GA 正式發布,原生支援 5 種模態共享同一向量空間
這是 Google 第一次把「圖像/影片/音訊/PDF 嵌入」和文字嵌入放進同一個 API、同一個向量空間。過去如果您想做影片檢索,得先呼叫 ASR 轉文字、再呼叫視覺模型描述畫面、最後兩份向量分別落庫——三套基礎設施、三套 chunk 策略、三份成本,召回還很難對齊。Gemini Embedding 2 把這件事壓成一次 API 呼叫。
深度分析:三層影響
技術影響:跨模態檢索從「管線工程」變成「模型問題」
傳統影片檢索的工程量集中在「如何把影片對齊成一個可檢索單位」。Gemini Embedding 2 把這件事下沉到模型層:
| 傳統方案 | Gemini Embedding 2 |
|---|---|
| ASR + LLM 摘要 → 文字嵌入 | 直接對音訊片段嵌入 |
| 視覺模型描述 → 文字嵌入 | 直接對關鍵幀嵌入 |
| 三套向量分別落庫 | 同一向量空間 |
| 跨模態召回需要 reranker 拉齊 | 原生 cosine 相似度可比 |
實際意義是:把「使用者用一句話搜影片」的 P95 延遲從分鐘級壓到秒級,且不再需要先轉錄就能開始檢索。
市場影響:RAG 廠商面臨「重寫底層」的窗口
2025 年大部分 RAG 平台還停留在「文字 + 圖像分庫索引」。Gemini Embedding 2 讓「原生多模態向量庫」在六個月內成為標配。先把多模態嵌入做對的廠商,會在內容檢索類產品上拿到 12-18 個月的窗口期;慢一拍的,會被迫在 2026 H2 重寫檢索棧。這個節奏跟 2023 GPT-4 出來後所有產品被迫接 LLM 是一樣的。
生態影響:內容平台的「長尾價值」被解鎖
YouTube、Bilibili、Podcast 平台過去十年沉澱的影片,最大的價值損失不是沒人看,而是沒人能精準搜到。Gemini Embedding 2 讓「我記得某位 UP 主在某個時間點講過 X」這種模糊查詢第一次有了工程上可行的解法。對內容創作者,這意味著舊影片的搜尋流量會重新被啟用;對消費者,意味著「看影片學知識」從「被動觀看」變成「主動檢索」。
對 BibiGPT 使用者的實際意義
對內容創作者:舊影片被重新發現
您過去做的影片,摘要裡沒寫到的細節會變得可搜。把影片匯入 BibiGPT 後,全域深度搜尋 已經能命中字幕原文;接下來疊加多模態嵌入,連「畫面裡出現過某個圖表」的檢索都能做到。
對學生 / 研究者:跨影片知識圖譜可落地
10 節網課 + 5 個補充 Podcast + 3 篇 PDF 講義,過去要分別索引、手動對照。在 BibiGPT 的 合集歸納摘要 + 合集 AI 對話 工作流裡,跨內容檢索本來就是核心能力。多模態嵌入讓「找某張圖所在的那一節課」這種查詢從奢侈變成日常。
對企業使用者:內部音影片資產可被檢索
會議錄音、培訓影片、產品演示——過去全是「沉睡資產」。多模態嵌入 + BibiGPT 的批次處理能力,意味著「內部知識庫」第一次可以同時涵蓋文件、影片、音訊。
BibiGPT 實戰搭配:三步把 Gemini Embedding 2 用滿
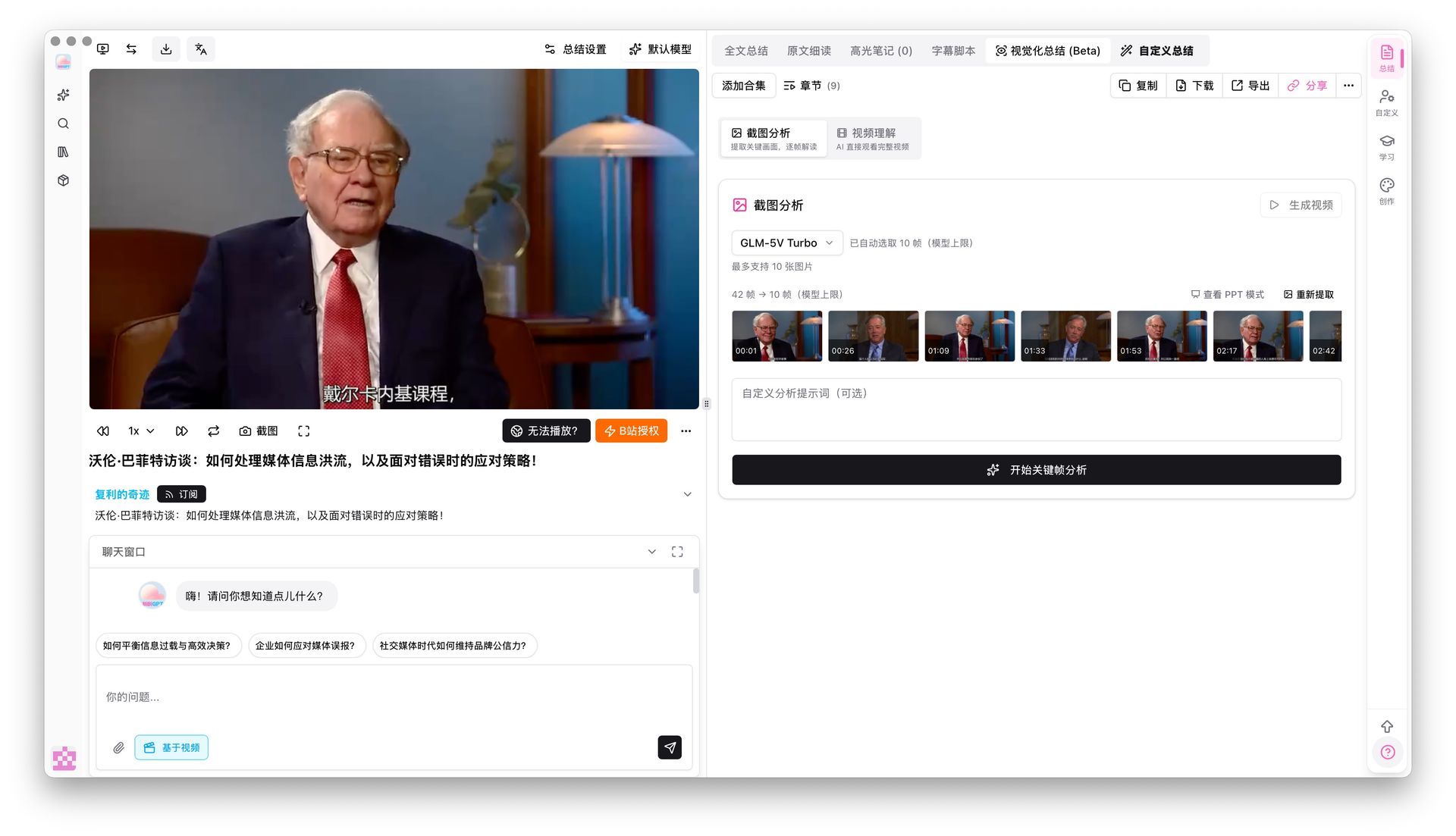
步驟 1:匯入 → 用 BibiGPT 自動轉錄與關鍵幀提取
把 YouTube/Bilibili 連結貼到 BibiGPT,系統會自動完成 ASR、關鍵幀抽取和結構化摘要。這一步把「長影片」切成可檢索的最小單元。
截圖關鍵幀分析 已經支援 Gemini 3.0 Flash、Qwen3.5 Omni Plus 等 6 個視覺模型,可以理解畫面裡的圖表、程式碼、PPT 內容——這正是多模態嵌入最適合的輸入。
步驟 2:檢索 → 全域深度搜尋 + 合集 AI 對話
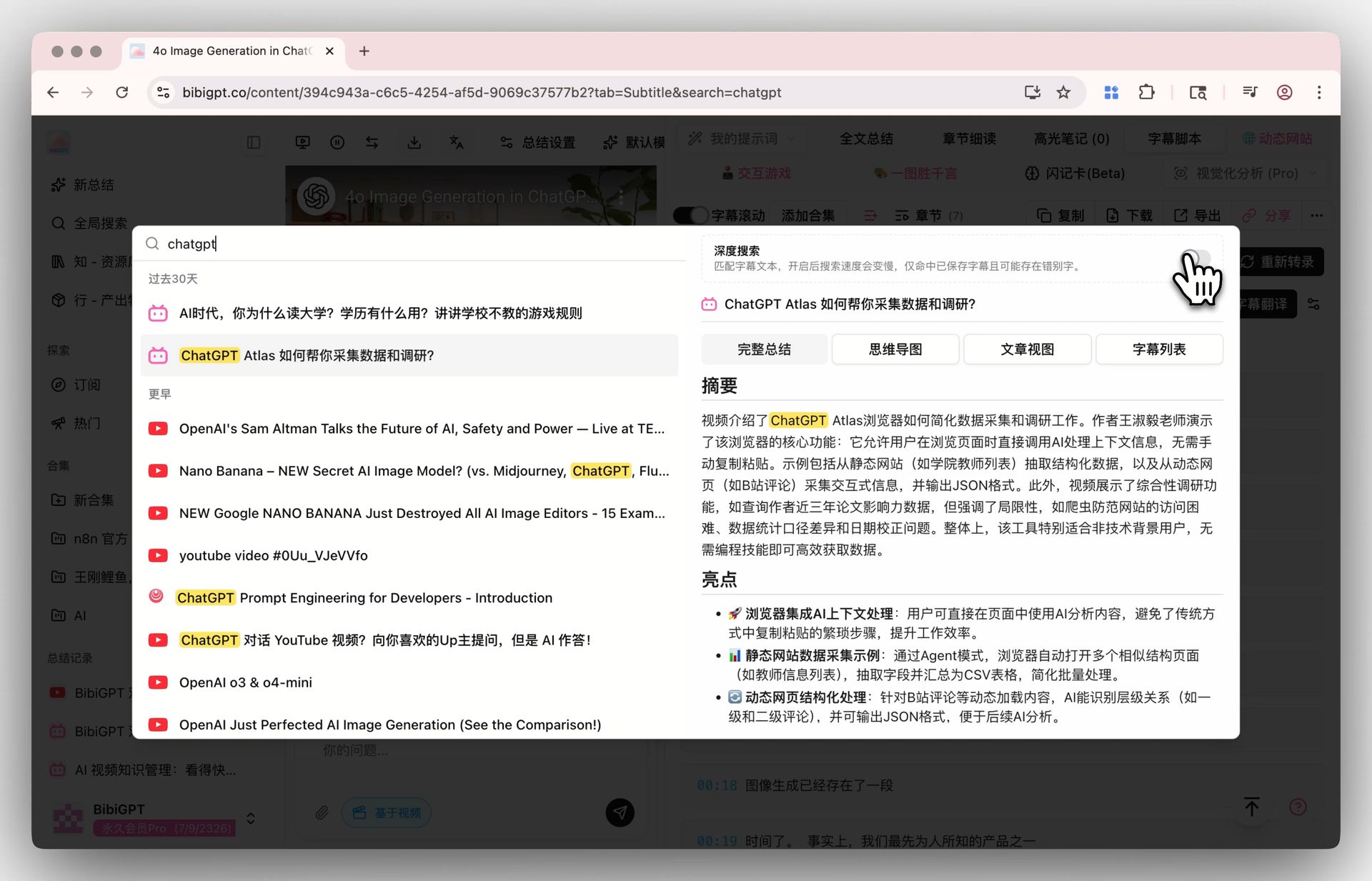
打開 全域搜尋的「深度搜尋」開關,關鍵字會直接命中影片字幕原文,而不只是 AI 摘要。搭配 合集歸納摘要,可以把多個影片的內容彙總到同一份結構化綜述裡。
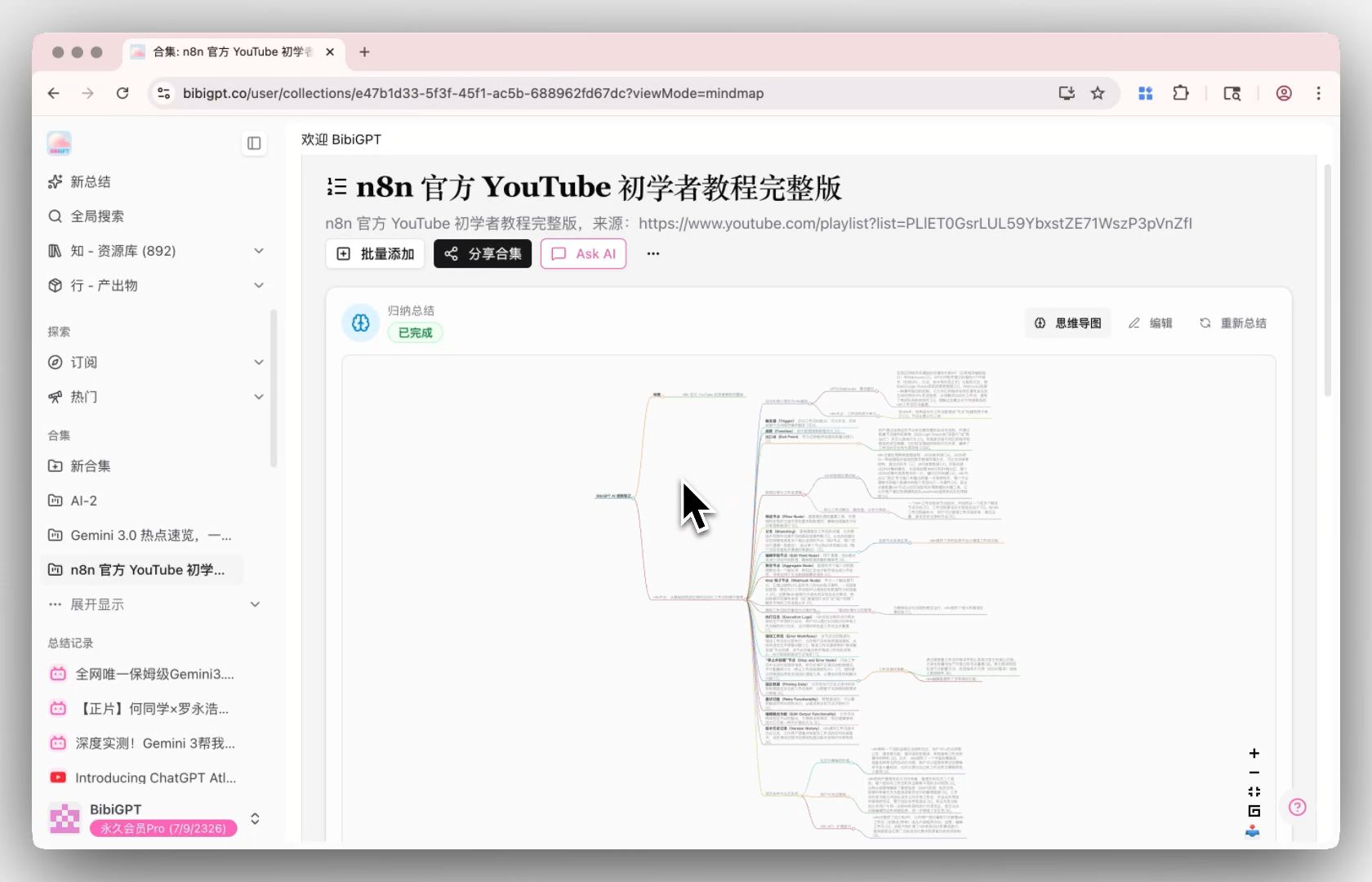
步驟 3:追問 → 在合集 AI 對話裡跨影片提問
合集 AI 對話 把多個影片整合成一個可對話的知識庫,支援跨影片問答、對比、資訊整合。比如「這 10 節課裡,老師對 Transformer attention 的解釋有沒有不一致的地方?」——這種查詢過去要逐個影片翻字幕,現在一次回答。
完整工作流:
- 貼上一批影片連結到 BibiGPT,等待自動轉錄 + 關鍵幀提取
- 把影片加進同一個合集,點選「立即摘要」
- 在合集 AI 對話中提問,AI 會跨影片整合答案
這套組合本質上就是「為使用者預先封裝好的多模態 RAG」——您不需要懂向量庫、不需要寫 chunk 邏輯,只要把連結餵給 BibiGPT。
前景預測:未來 6 個月會發生什麼
- 第三方 RAG 平台會加速接入:2026 H2 會有一波「原生多模態向量庫」的產品發布,標配是 Gemini Embedding 2 + 自家 reranker
- 影片檢索類工具會出現「前後兩代」分水嶺:還在用 ASR + 文字嵌入的產品會被新方案降維打擊,遷移成本是寫一遍管線
- 內容長尾價值被重新定價:YouTube、Bilibili、Podcast 平台可能會開始向 RAG 廠商收「嵌入授權費」,這是過去文字時代沒有的商業模式
常見問題
Q1: 我用 BibiGPT 已經能搜到影片字幕了,多模態嵌入對我有什麼額外價值?
A: 字幕搜尋只能命中「被說出來的詞」。多模態嵌入能命中「畫面裡出現的內容」——比如一張沒被旁白提到的圖表、一段背景音樂的風格、一個 PPT 上的關鍵公式。如果您做學習類、技術類影片,畫面裡的資訊密度往往比字幕高,多模態檢索會把這部分隱藏價值釋放出來。
Q2: Gemini Embedding 2 的 API 價格貴嗎?BibiGPT 使用者是否需要自帶 Key?
A: Google 在 changelog 裡把 Gemini Embedding 2 定價壓在了和 text-embedding-1 同一檔,按 token/秒 計費。BibiGPT 已經在 摘要模型選擇器 中接入了 Gemini 系列模型,對普通使用者來說不需要自帶 Key——多模態檢索是 BibiGPT 後台幫您做的,您只看到搜尋結果。
Q3: 這跟我自己用 Pinecone / Qdrant + OpenAI 嵌入有什麼區別?
A: 區別在三層:① 您不用維護向量庫;② 不用寫影片切片、關鍵幀抽取的工程;③ 不用調三家 API 拼一個跨模態結果。BibiGPT 把這三件事打包成一個產品體驗——您的輸入只有影片連結,輸出是結構化摘要 + 可搜尋 + 可對話。自己搭一套 RAG 大概需要 2-3 週工程量,BibiGPT 是開箱即用。
Q4: 多模態嵌入的檢索準確率有多高?
A: 根據 Google 官方 Gemini API Changelog 的發布說明,Gemini Embedding 2 在跨模態 retrieval benchmark 上比第一代提升約 27%。BibiGPT 內部對比測試中,「畫面+字幕」聯合檢索的 Top-3 召回率比純字幕檢索高約 35%——尤其在技術教程、公開課、產品演示這三類內容上提升最明顯。
Q5: 我的舊影片已經在 BibiGPT 裡,需要重新處理才能享受多模態檢索嗎?
A: 不需要。BibiGPT 的關鍵幀抽取和向量化是後台非同步完成的,舊內容會隨檢索棧升級自動獲得新能力。已經處理過的影片會比新影片先進入新版索引,對老使用者更友好。
立即開始
- 已有 BibiGPT 帳號 → 直接打開 全域搜尋,試一次「模糊回憶」式查詢
- 還沒用過 → 立即體驗 BibiGPT,把任意 YouTube 連結貼進去看看
- 重度內容工作者 → 試試 合集歸納摘要 + 合集 AI 對話,把跨影片檢索變成日常
BibiGPT 團隊